📄Vision Transformers Need Registers
written by Timothee Darcet, Maxime Oquab1 Julien Mairal, and Piotr Bojanowski
Introduction
이미지를 다양한 목적을 위해 사용할 수 있는 generic features로 변환하는 문제는 오랫동안 연구되어 옴. 초기 방법은 SIFT와 같은 수작업 원칙에 의존했지만, 대규모 데이터와 딥러닝 기술이 등장하면서 end-to-end training이 가능해짐. 여전히 특정 작업에 대한 valuable annotated data를 수집하는 것은 어렵기 때문에 이러한 generic feature embedding은 중요함. 일반적으로 많은 데이터가 있는 작업을 위해 모델을 pre-train 시키고, 해당 모델의 일부를 특징 추출기로 사용하는 것이 일반적임. 이러한 접근법은 강력한 feature model을 훈련하여 downstream task를 가능하게 함
특히, DINO 알고리즘은 이미지의 의미적 레이아웃에 대한 명확안 정보를 포함하는 모델을 생성하는 것으로 나타남. 본 논문에서는 DINO의 후속작인 DINOv2가 밀집 예측 작업을 수행할 수 있는 특징을 제공하지만, 특징을 추출할 때 LOST와 호환되지 않는다는 점을 발견함. 이는 DINOv2와 DINO가 다르게 동작함을 시사하며, DINOv2의 feature map에는 이전 모델에는 없었던 artifacts가 존재한다는 것을 밝혀냄
본 논문에서는 이러한 현상을 이해하고, 이러한 artifacts를 감지하는 방법을 개발하려고 함. 이들이 출력에서 약 10개 높은 norm을 가진 token이며, 전체 시퀀스의 약 2%에 해당한다는 것을 관찰함. 또한, 이 token들은 비슷한 이웃 패치들 사이에서 나타나며, 이는 모델이 추론 중 이러한 패치에 포함된 지역 정보를 버린다는 것을 시사함. 이를 테스트하기 위해 본 논문에서는 토큰 시퀀스에 추가 토큰을 추가하고, 여러 모델을 해당 수정 사항과 함께 훈련시킴. 그 결과 성능이 향상되었으며, 겨로가적인 feature map은 더욱 매끄러워짐
Problem Formulation
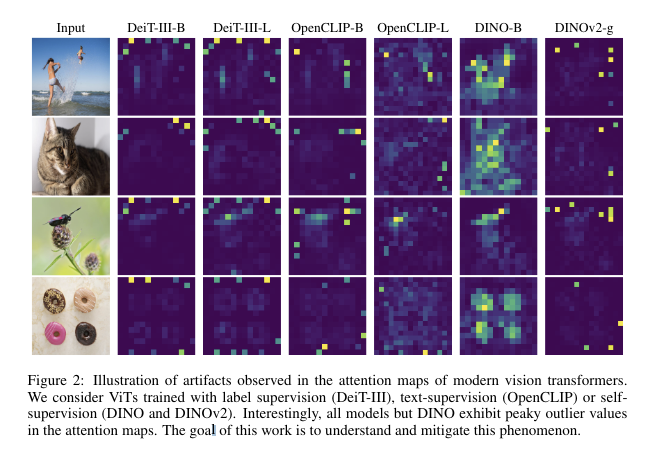
그림과 같이 현대 vision transformer는 attention map에서 artifact가 나타남.
이전에 unsupervised learning 방식의 DINO backbone은 local feature의 품질과 주의 맵의 해석 가능성으로 찬사를 받음. 그러나 DINOv2 model의 output은 좋은 local information을 제공하지만 주의 맵에서 바람직하지 않은 artifact가 나타남. 해당 섹션에서는 이러한 artifact가 왜 나타나는지 연구할 것을 제안함. 본 연구는 모든 vision transformer에서 artifact를 완화하는 것에 초점을 맞추지만 분석은 주로 DINOv2에 집중함
Artifacts in the local feature of DINOv2
-
Artifacts are high-norm outlier tokens

-
Outliers appear during the training of large models
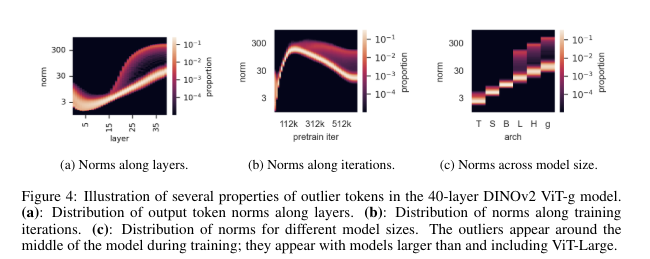
-
High-norm tokens appear where patch information is redundant
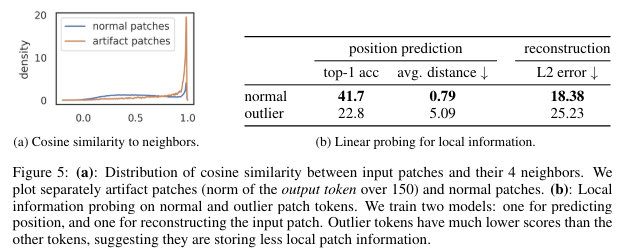
-
High-norm tokens hold little local information
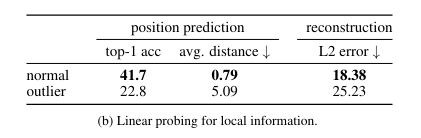
- position prediction
- pixel reconstruction
이 두 task에 대한 linear probing 성능이 낮아, local information이 artifact patch에 포함되지 않음을 알 수 있음
-
Artifacts hold global information
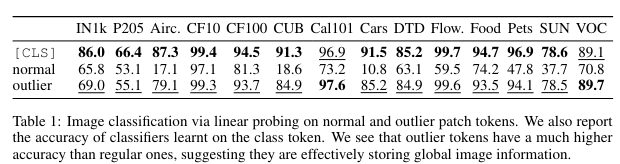
normal 패치에 비해 outlier 패치의 성능이 더 높음. 따라서 outlier patch는 local information보다 global information을 포함하고 있으며 이로 인해 인접한 patch와의 cosine similarity가 높음
Hypothesis and remediation
위에서의 관측을 통해 충분히 학습된 큰 사이즈의 모델은 중복되는 토큰이 global information을 처리할 수 있게 한다는 가설 도출. 이러한 가설은 dense prediction task에서 문재될 수 있음.
이를 해결 위해 register라는 additional token을 추가(inference에서는 사용 안함)
Experiments
Trainig algorithms and data
- DEIT-III
- simple and robust supervised training recipe for classification
with ViTs on ImageNet-1k and ImageNet-22k - run this method on the ImageNet-22k dataset, using the ViT-B settings
- simple and robust supervised training recipe for classification
- OpenCLIP
- strong training method for producing text-image aligned models, following the original CLIP work
- run the OpenCLIP method on a text-image-aligned corpus based on
Shutterstock that includes only licensed image and text data - use a ViT-B/16 image encoder, as proposed in the official repository
- DINOv2
- a self-supervised method for learning visual features, following the DINO work
- apply our changes to this method as it is the main focus of our study
- run this method on ImageNet-22k with the ViT-L configuration
- use the official repository
Evaluation of the proposed solution
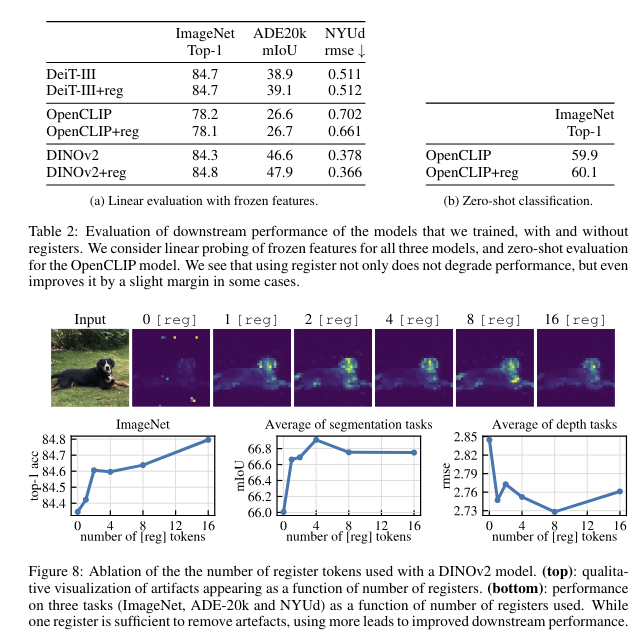
- register token을 추가하니 patch norm 크게 감소
- dense prediction 성능 향상됨
- ImageNet 성능 유지 또는 향상
- register 없는 경우 artifact 나타남
- register가 하나만 추가되더라도 dense prediction task 성능 크게 향상
Object Discovery
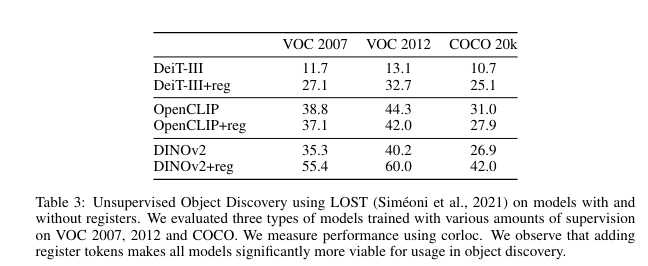
Qualitative evaluation of registers

Conclusion
본 논문에서는 DINOv2 model의 feature map에서 artifact를 발견하였고, 해당 현상이 여러 인기 있는 기존 모델에서도 나타남을 확인함. 그리고 transformer 모델의 output에서 artifact의 norm 값을 가진 토큰들과 대응됨을 관찰하여 해당 artifact를 간단히 감지하는 방법을 설명함
artifact의 위치를 연구한 결과, 모델이 자연스럽게 낮은 정보를 포함한 영역의 토큰을 재활용하고 추론을 위한 다른 역할로 재사용한다는 해석을 제안함. 이러한 해석을 바탕으로 간단한 수정 방법을 제안했는데, 입력 시퀀스에 output으로 사용되지 않는 추가적인 token을 추가하는 것임. 이를 통해 artifact가 제거되었으며, dense prediction과 객체 탐지 성능이 향상됨. 더 나아가, 본 논문에서는 제안된 솔루션이 지도학습 모델에서도 동일한 artifact를 제거함을 보여줌으로써 해당 해결책의 일반성을 확인함
