논문리뷰
1.Deep Neural Networks for YouTube Recommendations
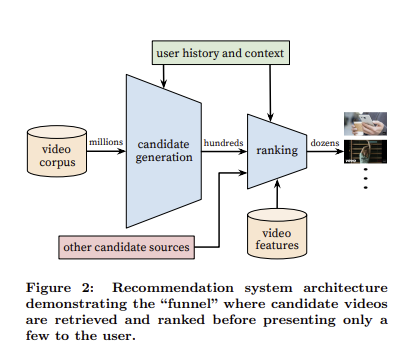
written by Paul Convington, Jay Adams, Emre Sargin유튜브는 비디오 콘텐츠를 제작하고, 공유하고, 발견하는 거대 플랫폼으로써 추천 시스템은 수십억 명의 사용자들이 수많은 영상들 중 자신에게 알맞은 영상을 찾게 해야 함.이러한 유튜브
2.Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
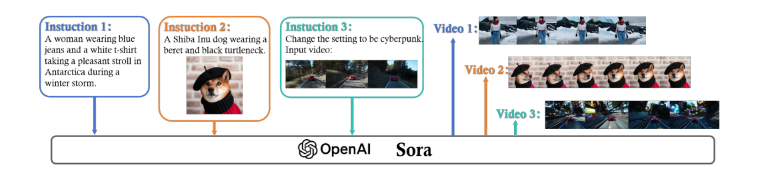
written by Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao
3.A Unified Approach to Interpreting Model Predictions
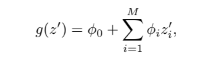
written by Scott M.Lundberg and Su-In Lee모델이 예측한 것에 대한 이유를 아는 것은 중요함, 그러나 모델이 복잡해질수록 이유를 아는 것은 더욱 어려워짐(accuracy와 interpretable의 trade-off)본 논문은 복잡한 모델
4.ArcFace: Additive Angular Margin Loss for Deep Face Recognition
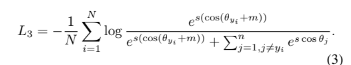
written by JianKang Deng, Jia Guo, Niannan Xue, Stefanos Zafeiriou, Imperical College London, InsightFace, and FaceSoft적절한 손실함수를 디자인하는 것은 DNN을 사용하여 대규
5.BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
written by Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang기존의 unidirectional recommendation model들은 한계점을 지니고 있음restrict th
6.DialogueRNN: An Attentive RNN for Emotion Detection in Conversations
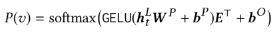
written by Navonil Majumder, Soujanya Poria, Devamanyu Hazarika, Rada Mihalcea, Alexander Gelbukh, Erik Cambriaresearch community에서 대화에서의 emotion dete
7.Relevance-CAM: Your Model Already Knows Where to Look
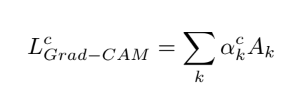
written by Jeong Ryong Lee, Sewon Kim, Inyong Park, Taejoon Eo, and Dosik HwangNN이 발전하고 적용분야가 넓어짐에 따라 모델을 설명하는(해석할 수 있는) 능력 또한 중요해짐. 컴퓨터비전 분야에서는 Class
8.Scalable Diffusion Models with Transformers

written by William Peebles and Saining Xietransformer로 인하여 머신러닝은 르네상스 시기를 겪고 있음. 그러나 다른 분야들에 비하여 이미지 생성은 transformer를 이용한 framework가 적음standard U-Net과
9.AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
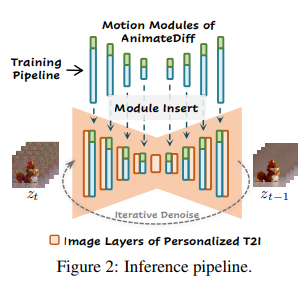
📄AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning written by Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang
10.Imagic: Text-Based Real Image Editing with Diffusion Models
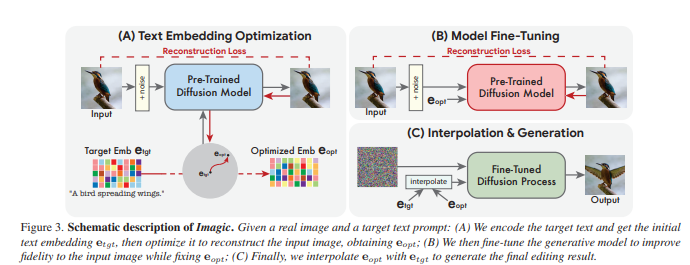
written by Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang1 Tali Dekel, Inbar Mosseri, Michal Irani이미지 처리에서 실제 사진에 비단순한 의미적 편집을 적용하는 것이 오
11.Post-training Quantization on Diffusion Models
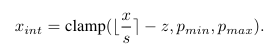
written by Yuzhang Shan, Zhihang Yuan, Bin Xie, Bingzhe Wu3, Yan Yan최근 denoising diffusion generative models는 생성 작업에서 현저한 성과를 거두었지만 노이즈 추정 네트워크의 긴 반복적
12.CatBoost: unbiased boosting with categorical features
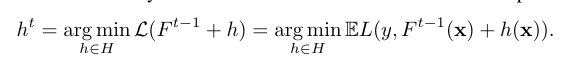
written by Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev,Anna Veronika Dorogush, Andrey Gulin본 논문에서는 gradient boosting의 기존 구현에서 발생하는 통계적 문제를 해
13.Continual Learning with Deep Generative Replay
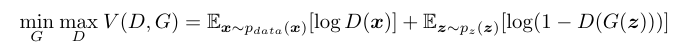
written by Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim인간과 large primates의 distinctive ablility 중 하나는 새로운 스킬을 continually하게 배우고 그 지식을 평생동안 축적
14.Playing Atari with Deep Reinforcement Learning
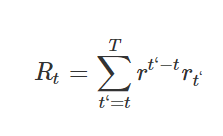
written by Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin RiedmillerVision 또는 speech와 같이
15.Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
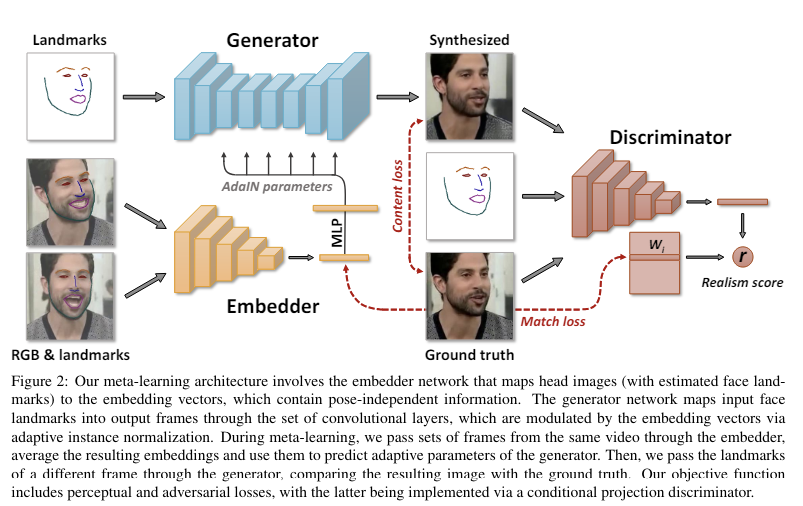
written by Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, and Victor LempitskySynthesizing realistic talking head sequences는 두 가지 이유로 인해 어렵다고 알려져 있
16.SimMIM: a Simple Framework for Masked Image Modeling
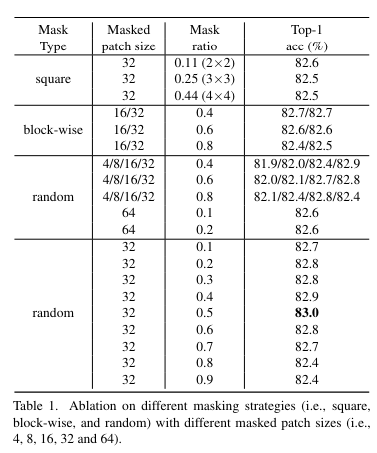
written by Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han HuMasked signal modeling은 입력 신호의 일부를 마스킹하고 이 신호를 예
17.Tabular Data: Deep Learning is Not all you need
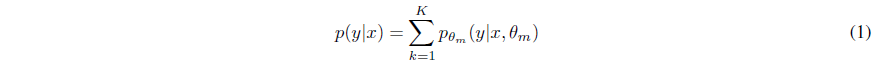
written by Ravid Shwartz-Ziv, and Amitai Armon일반적인 데이터 유형은 tabular data가 있는데, 이는 행과 열로 이루어져 있음. tabular data는 다양한 분야에서 사용되며 relational database를 기반으로
18.AutoDroid: LLM-powered Task Automation in Android
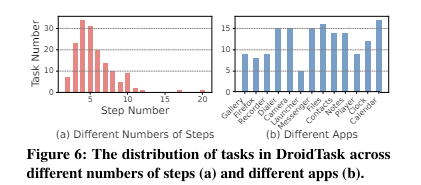
written by Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu스마트폰은 일상적인 많은
19.Vision Transformers Need Registers
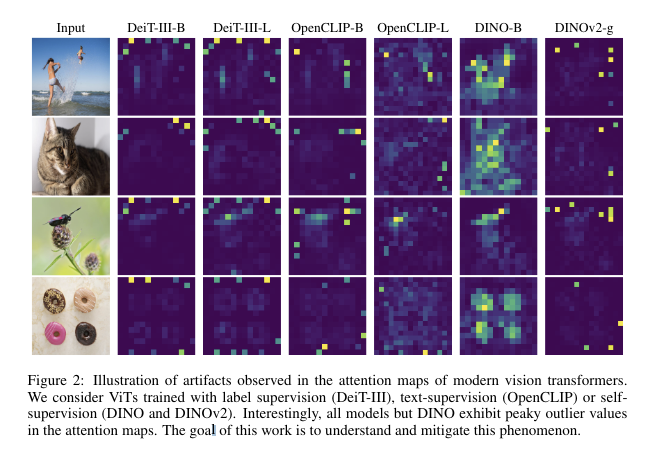
written by Timothee Darcet, Maxime Oquab1 Julien Mairal, and Piotr Bojanowski이미지를 다양한 목적을 위해 사용할 수 있는 generic features로 변환하는 문제는 오랫동안 연구되어 옴. 초기 방법은 S
20.U-Net: Convolutional Networks for Biomedical Image Segmentation
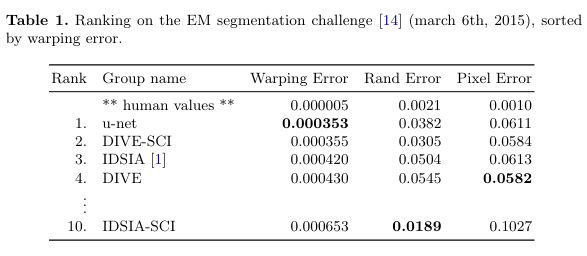
📄U-Net: Convolutional Networks for Biomedical Image Segmentation written by Olaf Ronneberger, Philipp Fischer, and Thomas Brox Introduction 지난 시간 동안
21.Deep reinforcement learning for drone navigation using sensor data
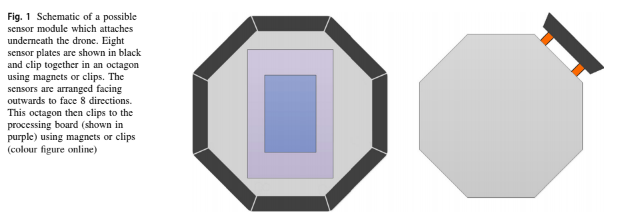
written by Victoria J. Hodge, Richard Hawkins and Rob Alexander빠르고 정확한 센서 분석은 오늘날 사회와 관련된 많은 응용 프로그램에 사용됨detection and identification of chemical leak
22.주식 + LLM + RL 논문들
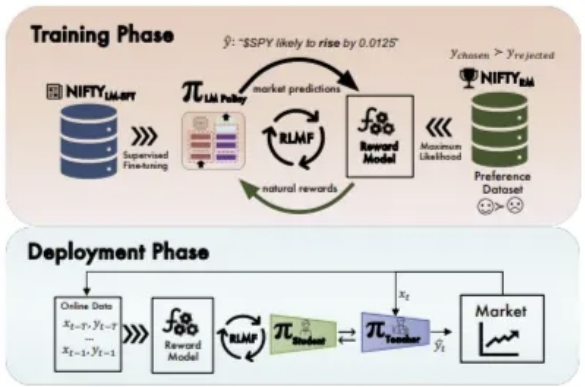
금융 시장 : 다양한 변수와 역학이 숨겨져 있거나 관측 불가능→ 예측 매우 어려움→ 신뢰할 수 있는 시장 시뮬레이션을 구축하여 random한 시장 가치 변동을 학습하는 방식이 아직 효과적으로 구현되지 X⇒ 금융 시장 예측 : one-shot learning proble
23.FinRL

FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance 논문 링크 Abstract DRL은 quantitative finance에서 효과적인 접근