Recent Trends
- 트랜스포머의 셀프어텐션으로 시퀀스 인코더, 디코더를 사용하는 방법은 NLP 의 트렌드가 됨
- 트랜스포머를 깊이 쌓은 모델 (원래는 6개였는데, 12 ~ 그 이상까지 쌓음) 을 self-supervised 를 통해 학습하는 방법은 전이 학습으로 여러 NLP 문제를 해결하고 있음 (BERT, GPT-3 등)
- 추천 시스템, 신약 개발, CV 등 다양한 분야에 사용되는 중
- 자연어 생성 문제에서 셀프 어텐션은 그리디 디코딩 (왼쪽에서 단어를 하나씩 생성) 이라는 한계점 존재
GPT-1
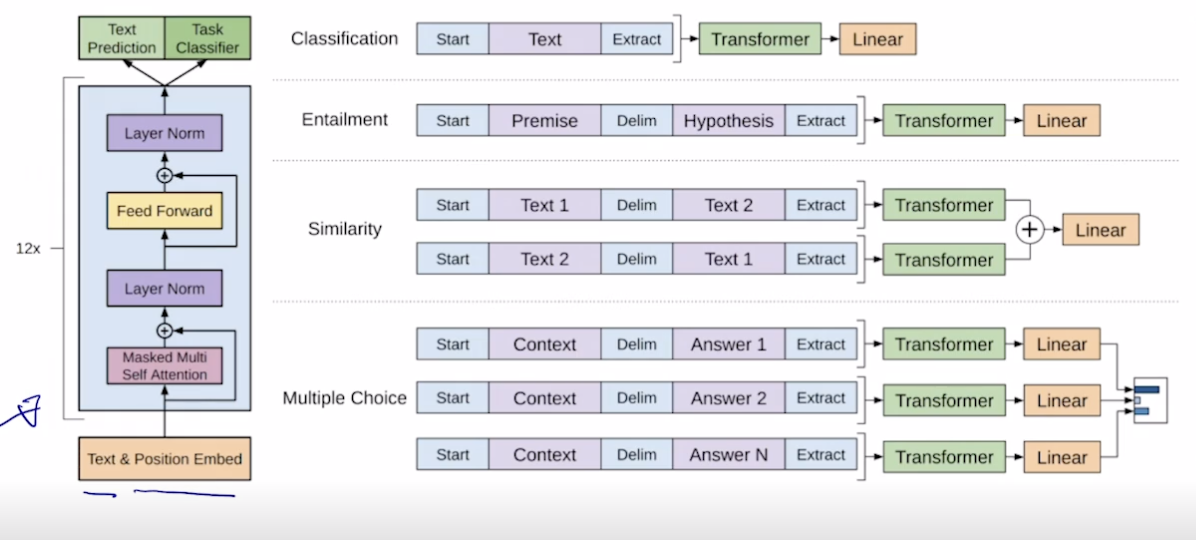
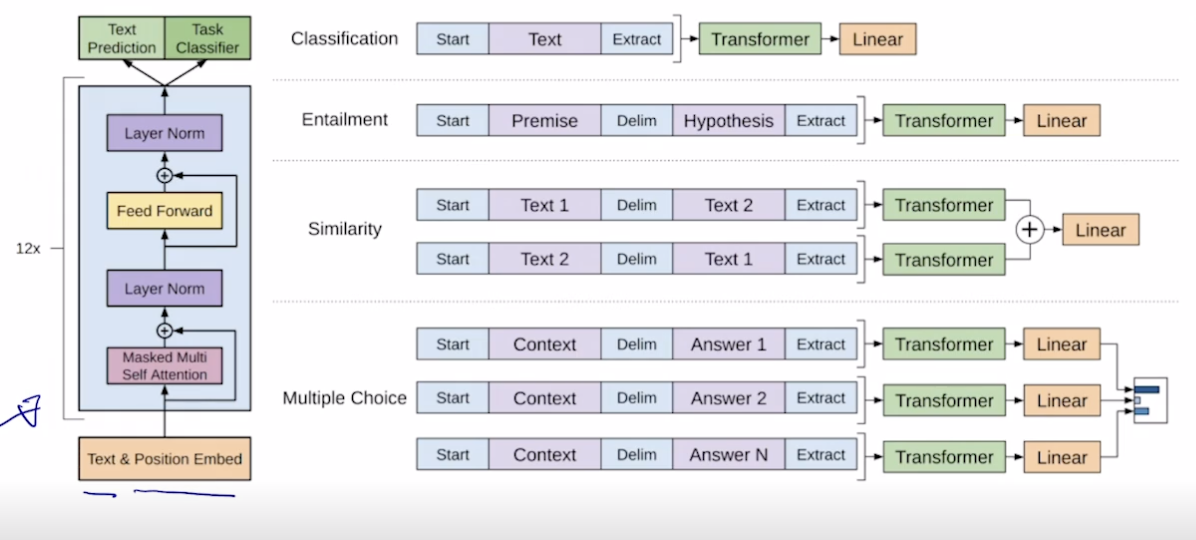
- Improving Language Understanding by Generative Pre-Training
- 다양한 스페셜 토큰을 사용해서 자연어 처리의 여러 태스크를 처리할 수 있는 통합적인 모델 제시
- 각 태스크마다 start 토큰과 extract 토큰 (+ delim 토큰) 으로 시퀀스하게 만들고 extract 를 벡터화하여 트랜스포머에 넣음
- Extract 는 처음에는 토큰이었지만 나중에는 원하는 정보를 담은 (앞의 정보들을 함축한) Query 가 담기게 됨
- 프리트레이닝 할 때는 문장의 다음 단어를 맞추는 식으로 진행됨. 그리고 마지막 맞추는 부분은 떼어내고 사용됨.
- 라벨링 되지 않은 대규모 데이터로 프리 트레이닝을 해서 얻어진 모델에 우리가 원하는 데이터를 넣고 학습시켜 원하는 결과 도출
- 마지막 Linear 전에 있는 이미 학습된 인코더와 디코더를 가져와서 새로운 목적에 맞게 끼워넣어줌.
- 프리 트레이닝 부분은 단어 간의 관계를 잘 잡아냄
- 기학습된 부분은 lr 을 작게 줘서 잘 변하지 않게 하고, 우리가 만든 마지막 단의 파라미터는 처음에 랜덤으로 세팅하여 학습을 시킴
- 프리트레이닝에 사용되는 데이터는 라벨링이 되지 않았기 때문에 다양한 목적으로 사용 가능함. 마지막에 우리가 원하는 레이어 (분류 등) 학습에 사용되는 데이터는 라벨링을 해줘야 함
BERT
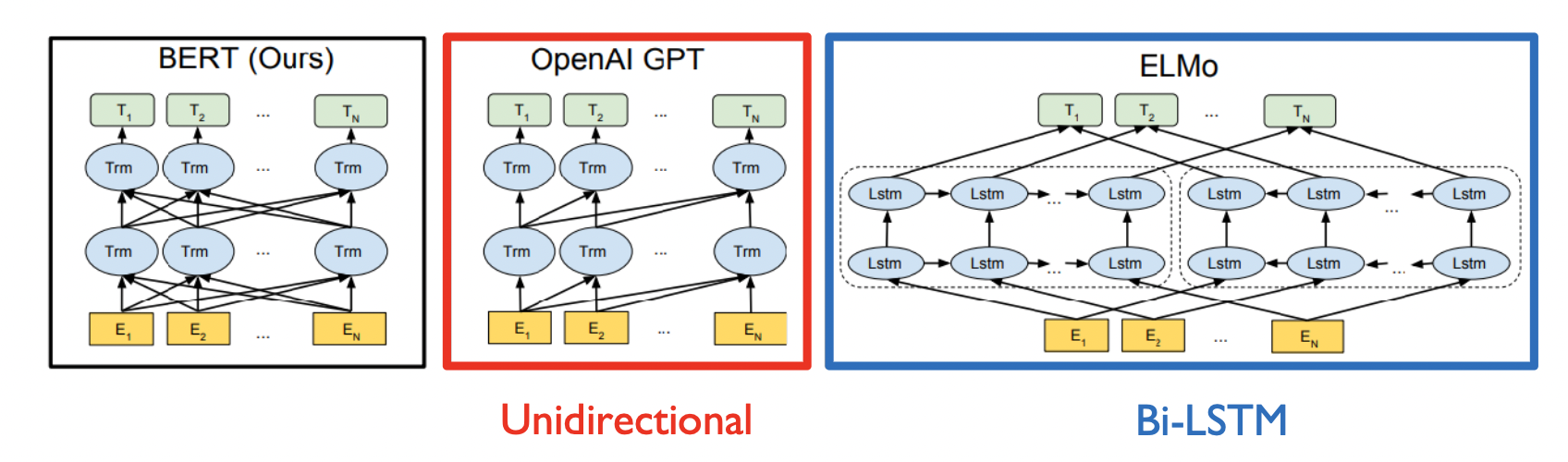
- Pre-training of Deep Bidirectional Transformers for Language Understanding
- GPT 처럼 language modeling 으로서 문장의 일부 단어를 맞추게 하는 일로 먼저 프리트레이닝을 함
- 왜 버트가 나왔을까? GPT 에서는 \<SOS> 를 보고 I 를 맞추고 I 를 보고 Study 를 맞췄음. 즉, 전 후 문맥을 안보고 앞의 단어만 보고 다음 단어를 예측했음. 이제는 앞 뒤 문맥을 다 고려하게 만들자.
- Masked Language Model (MLM) 을 프리트레이닝에 사용
- 문장에 빈 칸이 있으면 왼쪽과 오른쪽 정보를 다 이해하여 유추한다는 개념 사용
- I study math 라는 문장을 일정 확률로 각 단어를 빈칸으로 만들어 예측
- k% 확률로 입력 단어를 가리고 (마스크 치환 비율) 가려진 단어 예측
- 비율을 높이면 해당하는 마스크를 맞추는 정보가 부족해서 문제가 생김
- 비율을 낮추면 효율이 떨어지거나 학습이 느려짐
- 가장 적절한 k = 15
- 문제점 : Mask 토큰은 fine-tuning 하는 동안에는 볼 수 없음. 프리트레이닝할 때 생기는 단어간의 관계 (마스크를 고려하는) 가 실제 문제 (분류 등) 에서는 나타나지 않기 때문에 문제가 됨.
- 해결책
- 15% 단어를 맞추되, 100% 확률로 MASK 로 치환시키지 않음
- 80% 는 MASK 로 변환, 10% 는 랜덤 단어로 치환 (마스크가 아니라 이상한 단어라도 원래 단어로 잘 복원하도록 문제 난이도를 높인 것), 10% 는 원래 단어 그대로 (원래 단어는 원래 단어로 나오도록 유도)
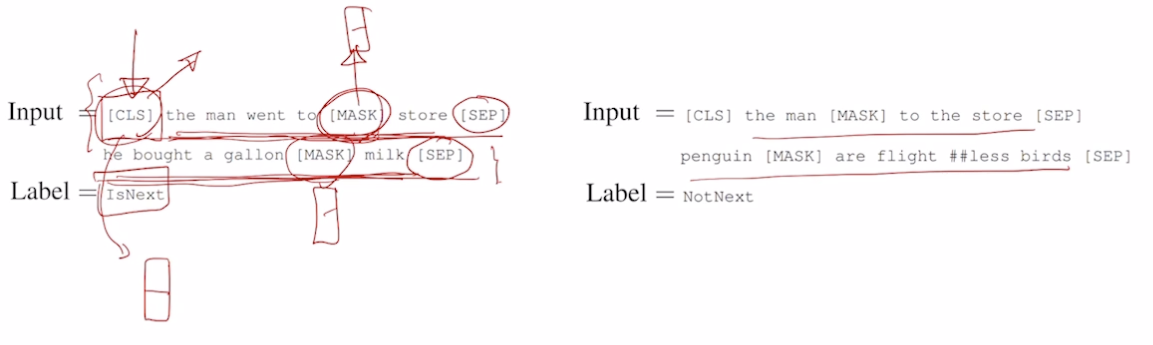
- Pre-training Tasks in BERT : Next Sentence Prediction (문장간 관계를 학습하는 방법 제시)
- 두 개의 문장을 가져와서 각 문장 뒤에 [SEP] 를 붙이고 합쳐줌.
- 첫 문장의 앞에는 [CLS] 라는 다수의 문장에서 예측을 담당하는 토큰을 줌 (GPT 에서 제일 뒤에 EXTRACT 를 붙이던 것과 같은 역할). 라벨 없는 입력 데이터만으로 예측을 하도록 학습.
- 첫 문장 뒤에 두 번째 문장이 나오는게 적절한지 아닌지를 봐주도록 함.
- 맞으면 IsNext 라벨, 아니면 NotNext 라벨을 줌
- 문장간 관계를 이해하기 위해 A 문장을 수행해서 나오는 B 문장이 나와야하는지를 예측
- BERT Summary
- 모델 아키텍쳐
- BERT BASE : L (트랜스포머 개수) = 12, H (인코딩 벡터의 차원수, 파라미터 수) = 768, A (어텐션 헤드 개수) = 12
- BERT LARGE : L = 24, H = 1024, A = 16
- 입력에 사용된 기법들
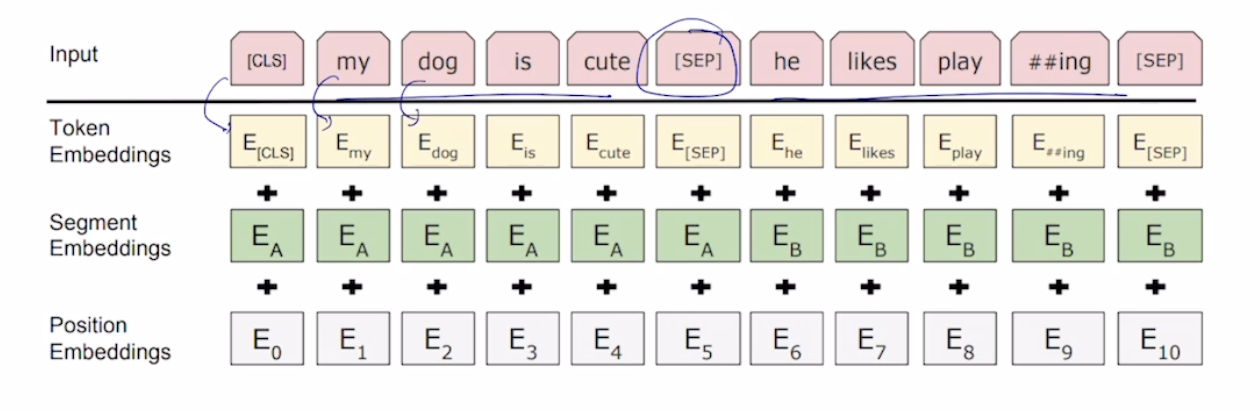
- WordPiece embeddings (30,000 WordPiece), 임베딩할 때 워드별로 임베딩하는 것이 아니라 워드를 좀 더 잘게 쪼개서 각각 시퀀스 단위를 서브워드 단위로 나눠서 넣어줌
- pretraining → pre, training
- Learned Positional Eembedding, 기존의 PE 는 사전에 정의된 sin, cos 기법을 사용했는데 이 부분을 학습시켜서 최적화되게 PE 를 진행
- [CLS] : Classification embedding, [CLS] 토큰을 앞에 붙임
- [SEP] : Packed sentence embedding, 두 문장을 붙일 때 구분해주는 역할로 [SEP] 붙임
- Segment Embedding : 버트 학습할 때 마스크된 단어를 예측하는 태스크 (단어 레벨 태스크) 와 주어진 두 문장이 인접인지 아닌지 확인하는 태스크 (문장 레벨 태스크) 가 있었음. 두 문장이 합쳐졌을 때 PE 를 수행하면 다른 문장인데 같은 문장으로 착각할 수 있으니, 다른 문장이라는 것을 알려주는 Segment Embedding 을 사용
- 토큰 임베딩 + 세그먼트 임베딩 + 포지셔널 임베딩을 더해줌
- WordPiece embeddings (30,000 WordPiece), 임베딩할 때 워드별로 임베딩하는 것이 아니라 워드를 좀 더 잘게 쪼개서 각각 시퀀스 단위를 서브워드 단위로 나눠서 넣어줌
- 모델 아키텍쳐
- GLUE 벤치마크 사용
BERT 의 fine tuning
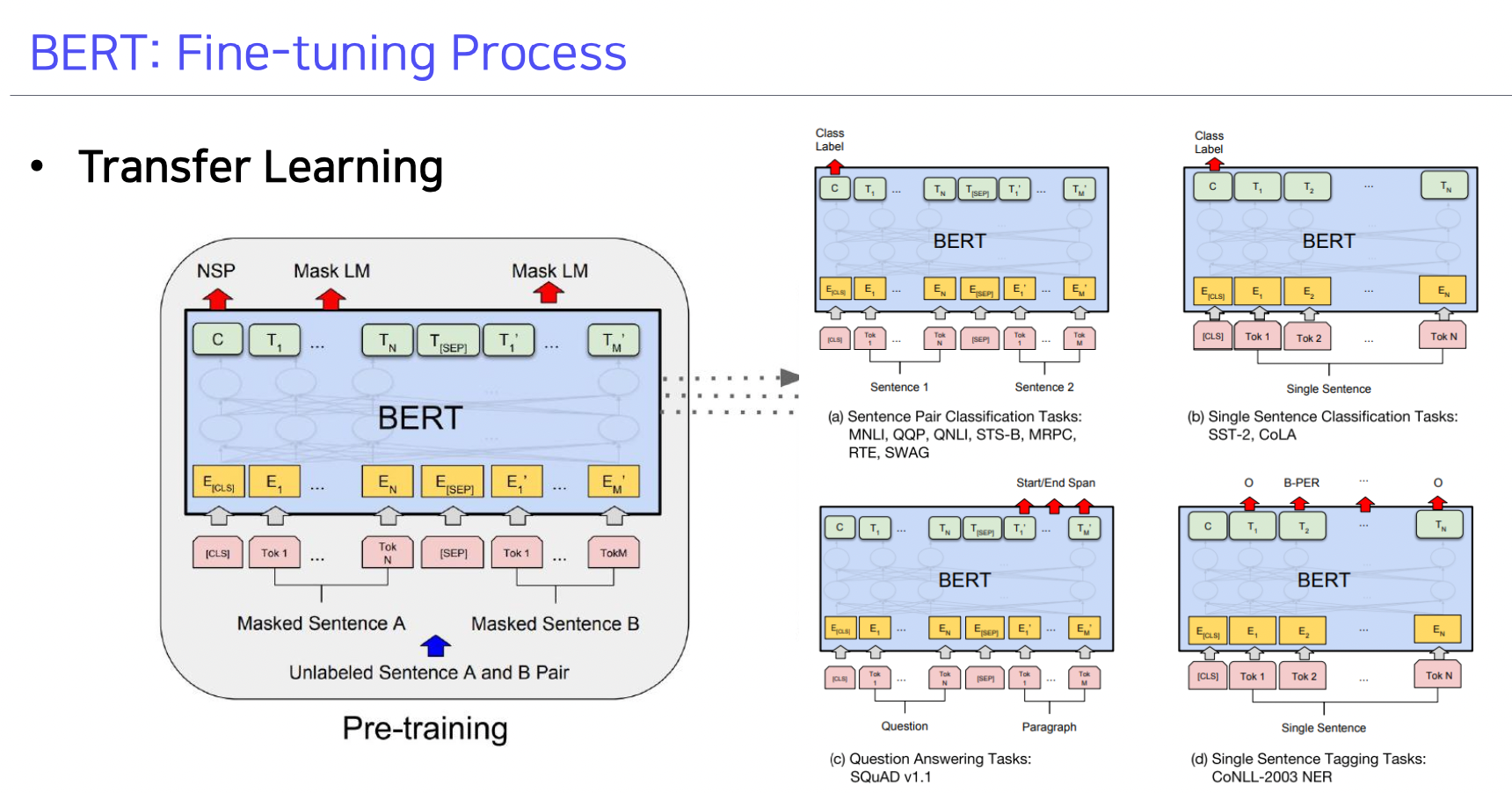
- (a) : 문장 페어에 대해 문장의 내포 관계, 모순 관계 파악
- (b) : 단일 문장의 클래스 분류
- (c) : Question Answering
- (d) : 단일 문장의 단어들의 품사 태깅
GPT1 과 BERT 의 차이
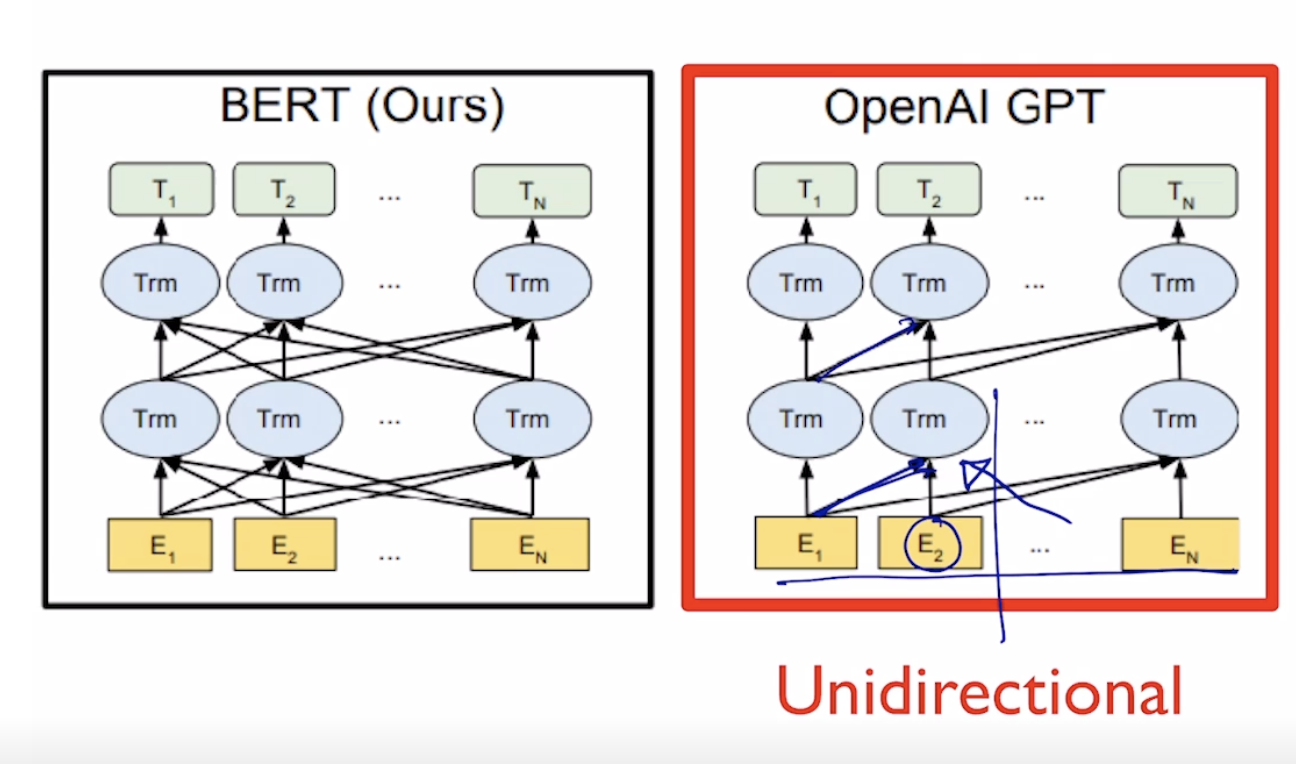
- GPT 는 뒷 단어들을 안 보기 위해 트랜스포머의 디코더처럼 Masked Self-attention 을 사용함
- BERT 는 단어 자체를 MASK 시켜서 모든 단어 접근 가능함. 트랜스포머의 인코더처럼 Self-attention 사용

- GPT 는 800만 단어, BERT 는 2500만 단어 학습
- BERT 는 [SEP], [CLS] 토큰을 학습하고, sentence A/B embedding (문장 관계성 파악) 도 프리트레이닝에서 진행
- BERT 는 한 배치에 128,000 단어, GPT 는 32,000 단어 (한 번에 학습하는 단어 수), 일반적으로 더 큰 배치 크기를 사용하면 학습이 더 잘되고 안정화가 더 잘됨 (경사하강법할 때 더 많은 데이터를 바탕으로 경사하강법을 해주기 때문), 배치크기를 키우기 위해서는 메모리가 증가해서 고성능의 GPU 필요
- GPT 는 여러 태스크에서 fine-tuning 할 때 lr 을 고정한 반면, BERT 는 각 태스크마다 lr 을 다르게 함
Machine Reading Comprehension (MRC), Question Answering

- 독해뿐만 아니라 질문에서 주요 내용을 추출해서 적절한 답변을 함
- 주어진 문서로 학습을 통해 질문에 적절한 답을 뽑아냄
- 위 예시보다 더 어렵고 복잡한 태스크 수행 가능, SQuAD 1.1 데이터를 사용하여 수행

- BERT 로 기계 독해 (QA) 하는 과정, SQuAD 1.1
- 질문의 정답에 해당될 법한 문구의 위치를 예측하도록 학습 (문장에 답이 정확히 있는 문제)

- 최종 예측 단어 벡터들이 나왔을 때 이를 FC1 하여 스칼라로 만듦. 이 여러 스칼라들로부터 답에 해당되는 문구가 어느 위치에서 시작되는지 파악. 124 개의 단어가 있으면 스칼라 범위는 ~124. 소프트맥스를 통해 확률이 주어지고 스칼라와 이 확률의 loss 를 통해 학습 진행.
- FC2 는 각 워드의 인코딩 벡터가 스칼라 값 나오게함. 소프트맥스 하여 마지막 단어 위치 에측하게 함
- FC1 은 첫 단어, FC2 는 마지막 단어 위치 예측
- SQuAD 2 학습 과정
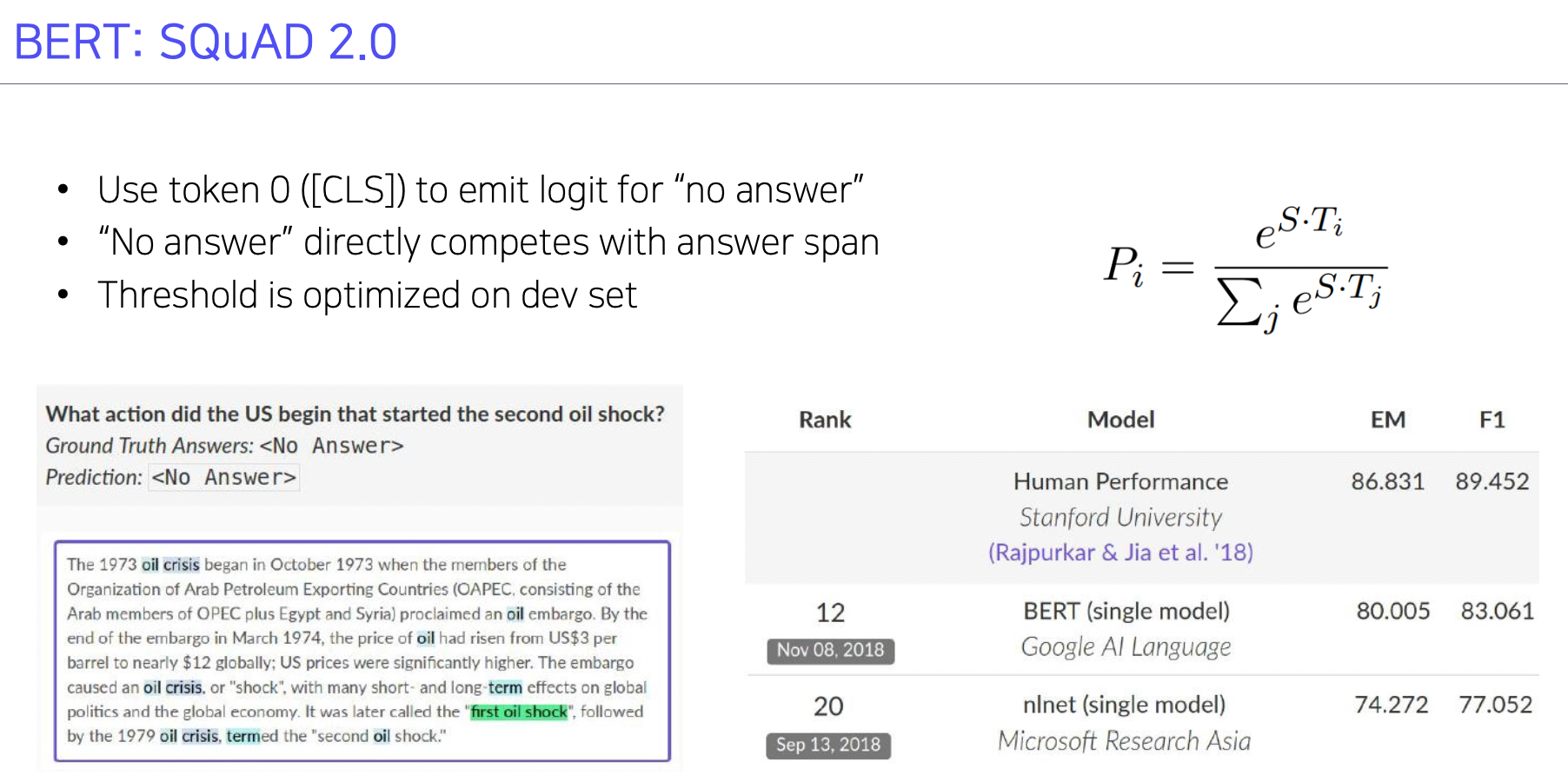
- 질문에 대한 답이 없는 경우 (데이터셋) 까지 원래 데이터에 추가함
- 질문에 대해 답이 있는지 없는지 파악하고 답이 있으면 위 과정으로 답을 찾음
- [CLS] 토큰을 통해 질문과 지문을 합쳐서 트레이닝함. 답이 있는지 문맥 파악
- On SWAG

- 앞의 문장에 이어 나올 수 있는 다수의 문장 중 가장 적절한 문장 찾기
- [CLS] + 앞 문장에 각 후보 문장을 붙여 FC 를 통과시킴. 스칼라 값이 나옴. 이들을 소프트맥스 시키고 ground truth 와 loss 학습하여 정답이 100% 확률이 될 수 있도록 학습
- Ablation Study, 버트의 또 다른 결과는 버트가 제안한 사이즈보다 더 크게 만들면 성능이 더 좋아짐 (규모가 최고). 아무리 커져도 계속 좋아짐. 가능하다면 모델 사이즈 키우자.
Further Reading
- GPT-1
- BERT : Pre-training of deep bidirectional transformers for language understanding, NAACL’19
- SQuAD: Stanford Question Answering Dataset
- SWAG: A Large-scale Adversarial Dataset for Grounded Commonsense Inference
Advanced Self-supervised Pre-training Models
GPT-2
- 구조는 GPT-1 과 같지만, 트랜스포머 레이어를 더 많이 쌓음
- 트레이닝 데이터 40 기가로 늘어남
- 데이터셋을 대규모로 사용하는 과정에서 되도록 퀄리티 높은 (잘 쓰여진 글) 데이터 사용하도록 유도
- 랭귀지 모델은 제로샷 세팅의 다운스트림 태스크 수행 가능 - 파라미터나 아키텍쳐 수정 안 함
- 문장 생성 예시, 그럴듯하게 만들어 냄
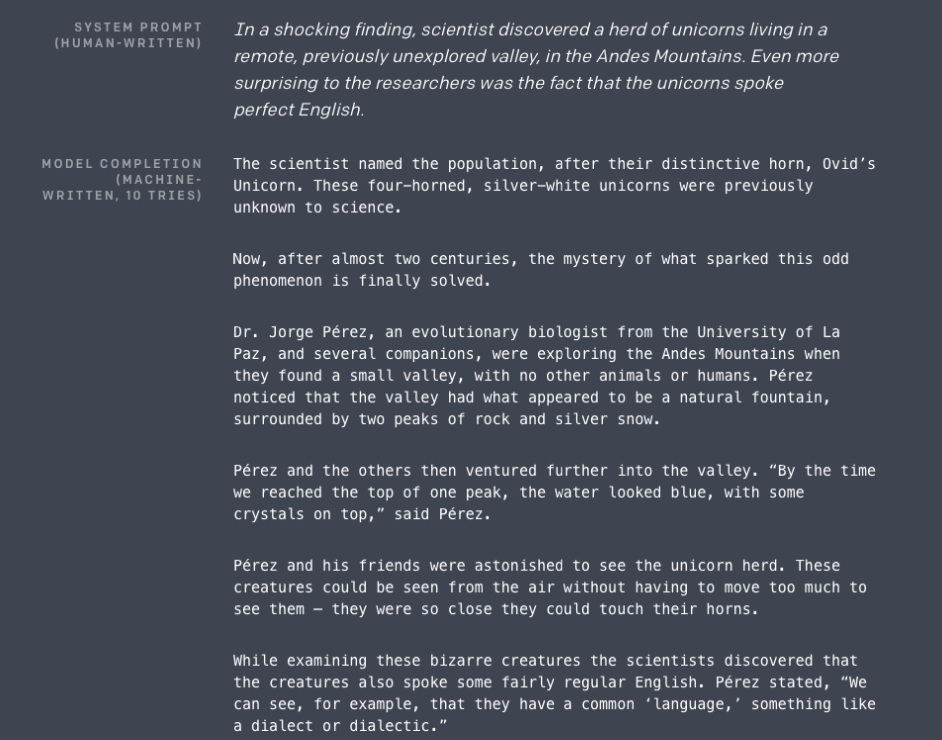
- Motivation : decaNLP, The Natural Language Decathlon : Multitask Learning as QA 에서 착안
- 주어진 문장이 긍정인지 부정인지 예측하는거면, 문장을 인코딩하고 [CLS] 토큰 뽑아서 이진 분류하는 구조인데 다른 태스크, 요약 등과는 모델 관점에서 다른 구조가 됨.
- 이 논문에서는 모든 종류의 자연어 문제들이 질의응답으로 바뀔 수 있다고 말함.
- 뭐든 질문으로 물어보면 됨. 질문에 대해 모든 태스크들은 자연어를 생성해냄
- Datasets
- 다양하고 좋은 데이터를 가져오기 위해 Reddit 에서 크롤링을 함. 스파게티 요리법에 관한 글이 있고 답변으로 외부 링크를 포함했을 때 3 개 이상의 좋아요를 받았으면 그 링크를 가서 글을 가져옴.
- 전처리
- BERT 의 WordPiece 와 비슷하게 BPE 를 사용하여 서브워드 구축
- 원래 트랜스포머 모델과 비교하면 Layer Normalization 이 사용되는 타이밍이 달라짐. 레이어가 위로 가면 갈 수록 웨이트 random 초기화를 1/루트(레이어개수) 크기로 반영함. 위쪽 레이어일수록 영향력이 작아지도록 함.
- QA 문제
- 대화형 질의응답 데이터 사용 (CoCA)
- 55 F1 score 을 보임. 점수는 낮지만 라벨 없는 데이터로 질의응답으로 뭐든 처리할 수 있기 때문에 의미가 큼
- 제로샷세팅 (파인튜닝 안함)
- 파인튜닝된 버트는 89 F1 score.
- 55 F1 score 을 보임. 점수는 낮지만 라벨 없는 데이터로 질의응답으로 뭐든 처리할 수 있기 때문에 의미가 큼
- 대화형 질의응답 데이터 사용 (CoCA)
- 요약 문제
- 요약에서도 제로샷 세팅 적용.
- 뒤에 TL;DR 이라는 토큰 (Too long, didn't read) 를 주면 요약을 해줌. 파인튜닝 필요 없음
GPT-3
- GPT-2 개선. 모델 구조말고 파라미터 수와 모델 크기를 매우 매우 크게 만듦.
- 더 많은 데이터와 큰 배치 사이즈 적용
- 제로샷 세팅을 발전시켜 Few shot 세팅 사용
- 제로샷 세팅은 질문과 Promp (대상) 만 주어졌다면, 이제는 이 사이에 example (shot) 들이 주어짐
- 샷이 많아지고 모델이 커질수록 성능이 더 좋아짐 (큰 모델일수록 동적인 적응 능력이 좋아짐)

ALBERT
- A Lite BERT for Self-supervised Learning of Language Representaitons
- 모델을 크게 만들면 성능이 좋아짐
- 문제점 : 메모리 크기, 학습 속도
- 솔루션 (크기는 줄이고 성능은 높이고)
- Factorized Embedding Parameterization
- Cross-layer Parameter Sharing
- (For performance) Sentence Order Prediction
- Factorized Embedding Parameterization
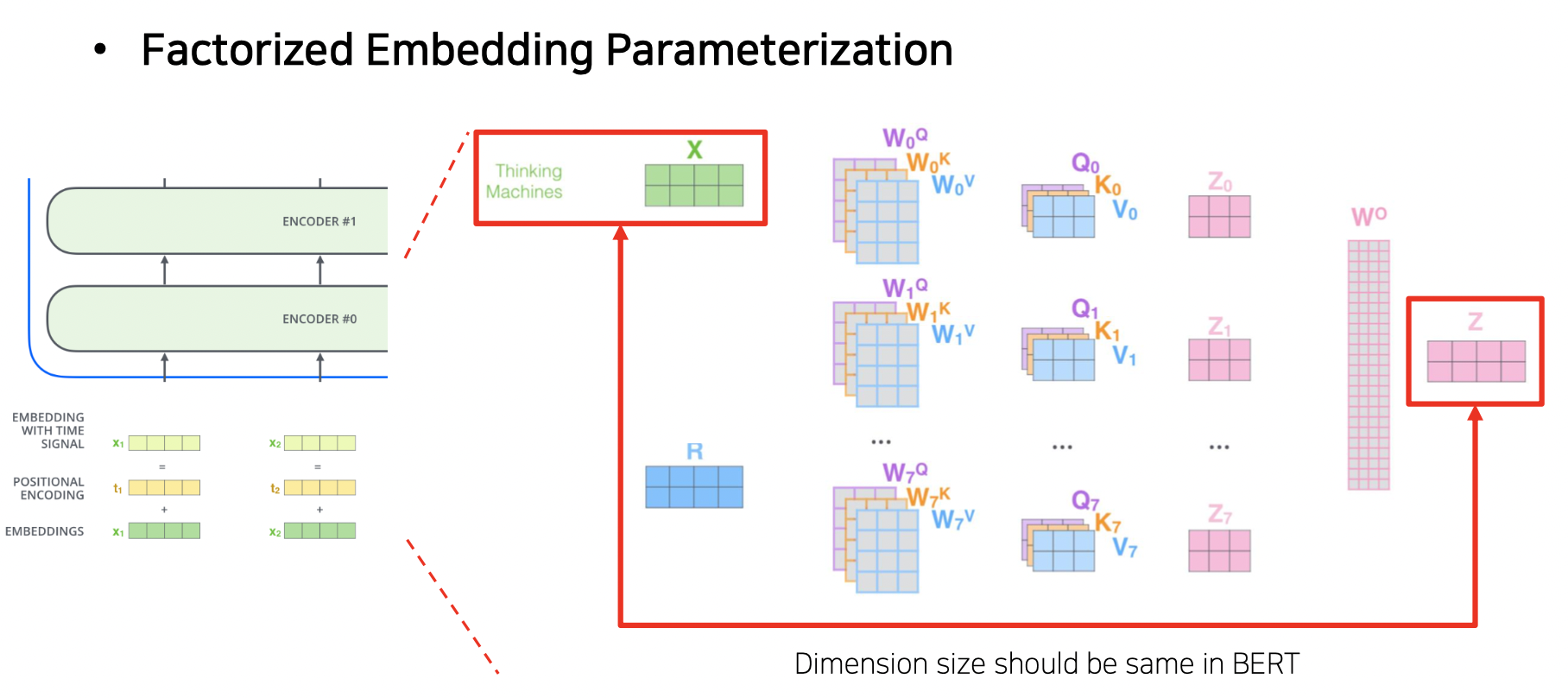
- 처음에 생성된 워드 임베딩이 멀티헤드어텐션에 적용됨
- 워드 임베딩을 적절한 내용만 추출하면 가벼워짐
- 임베딩 레이어의 차원을 줄이는 기법 사용
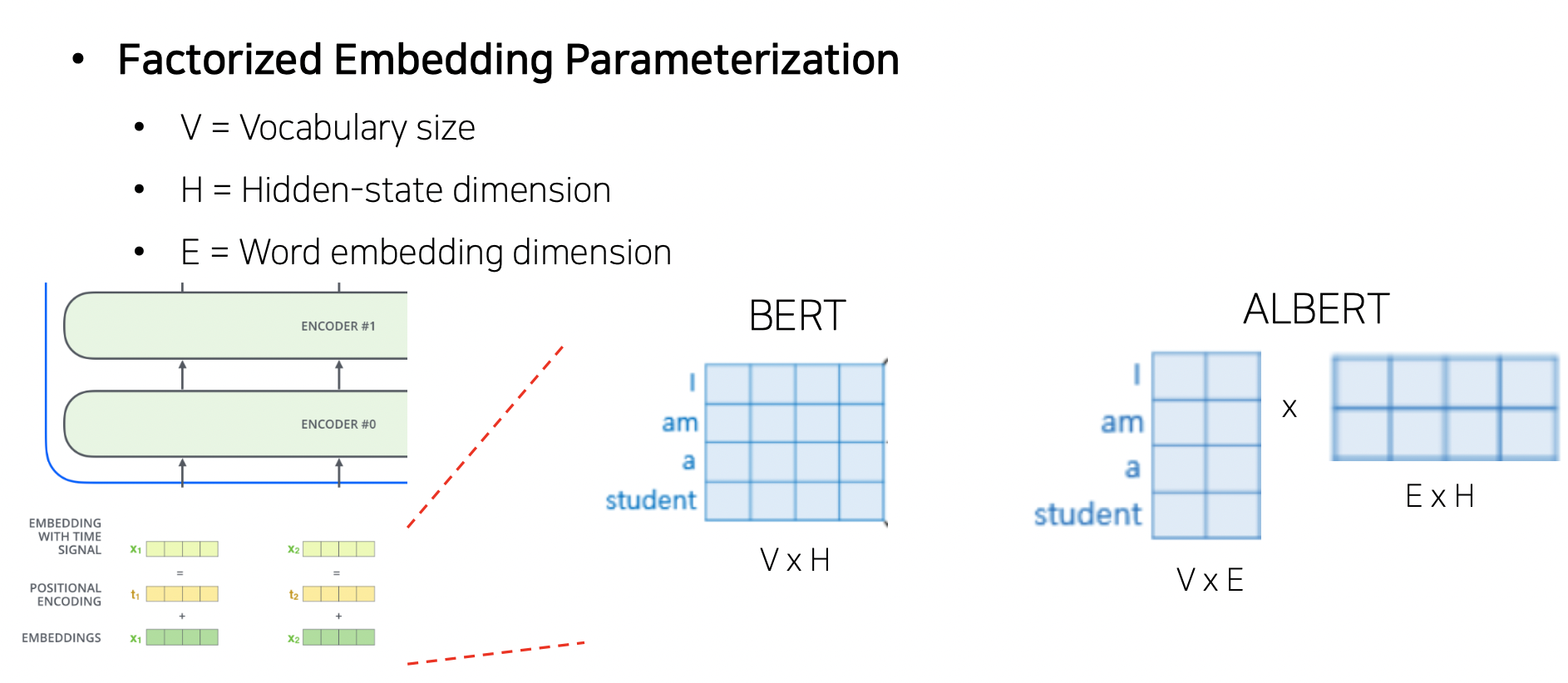
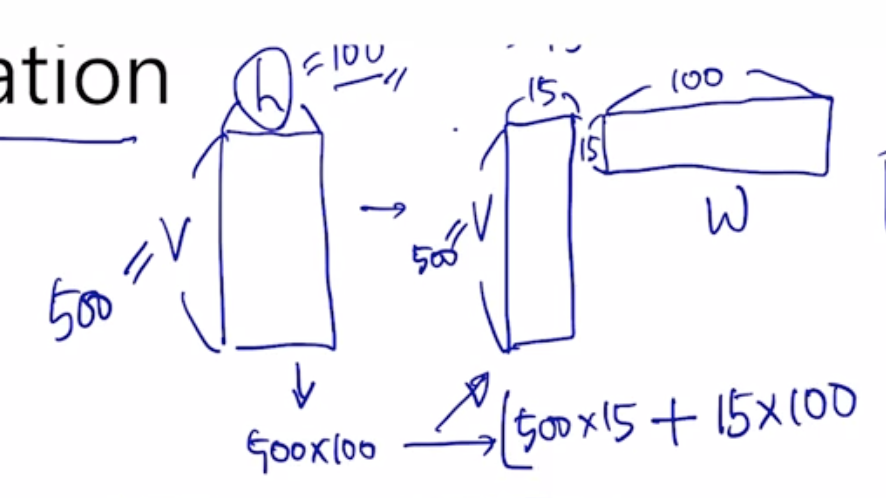
- 만약 임베딩된 벡터 크기가 4차원이 필요하다면 4x4 로 임베딩이 되야하는데, 이제는 4x2 x 2x4 를 함. 근사적으로 2차원을 4차원으로 바꿔주는 matrix factorization 으로 파라미터 수를 줄여줌
- CNN 의 VGGNet 처럼 줄여짐 (5x5 커널보다 3x3 커널 2 개가 더 파라미터 작음)
- Cross-layer Parameter Sharing
- 원래 멀티헤드 어텐션은 여러 어텐션을 컨캣했었는데 이제는 여러 어텐션에 대해 공유되는 하나의 파라미터를 적용
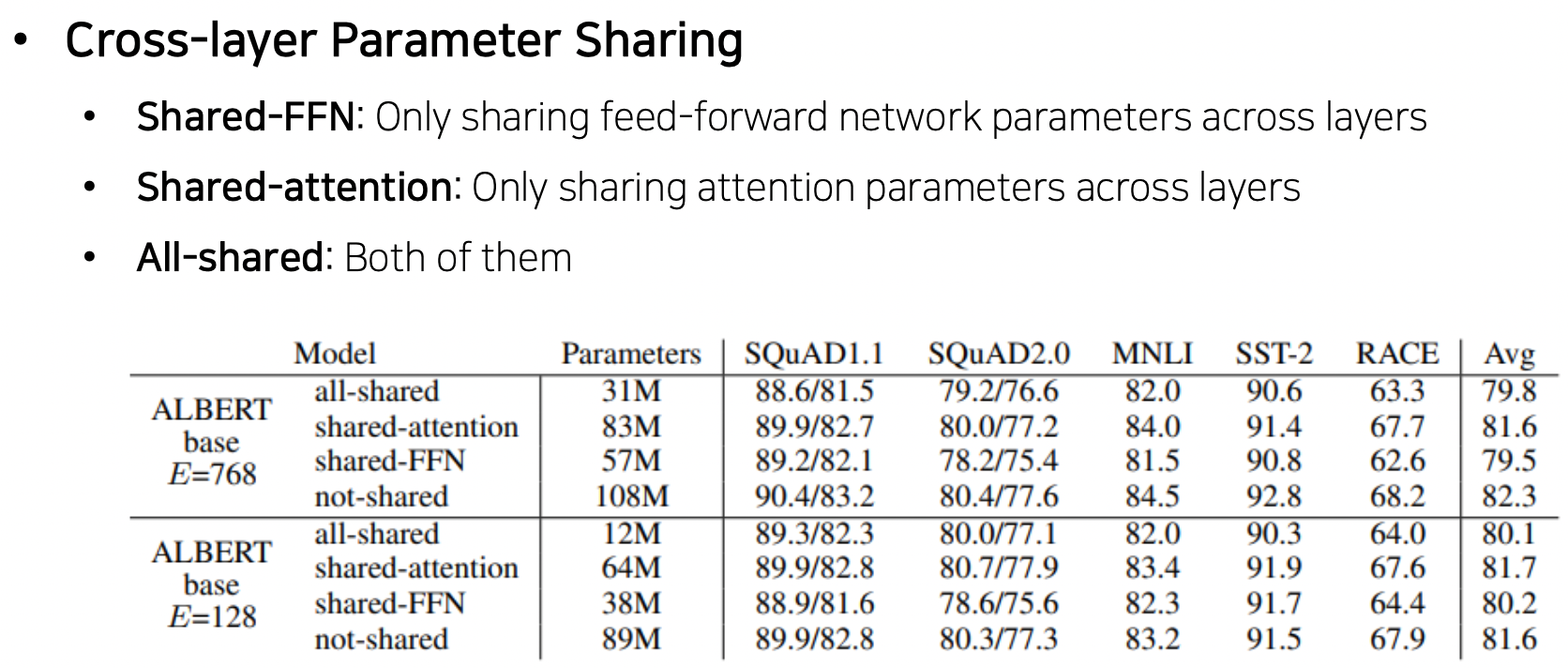
- Sentence Order Prediction
- 원래 BERT 는 마스크된 단어 맞추는 태스크와 두 문장이 연속된 문장인지 맞추는 태스크 (Next Sentence Prediction) 가 존재했음. 버트에게 Next Sentence Prediction 은 너무 쉬워서 별 효과 없음을 후속 논문들이 밝혀냄
- 관련 없는 두 문서에서 추출된 두 문장 (Negative samples) 을 보면 같은 문서에서 나온 두 문장은 관련이 높고 다른 문서에서 나온 문장은 관련이 적기 때문에 파악이 너무 쉬움
- 유의미한 정보를 깨우칠 수 있도록 함. 항상 연속되는 문장들에 대해 하나는 원래 순서대로 가져오고 (AB), 하나는 바뀐 순서로 가져옴 (BA). 위 문제를 더 어렵게 만들어서 학습시켜줌.
- 원래 BERT 는 마스크된 단어 맞추는 태스크와 두 문장이 연속된 문장인지 맞추는 태스크 (Next Sentence Prediction) 가 존재했음. 버트에게 Next Sentence Prediction 은 너무 쉬워서 별 효과 없음을 후속 논문들이 밝혀냄
ELECTRA
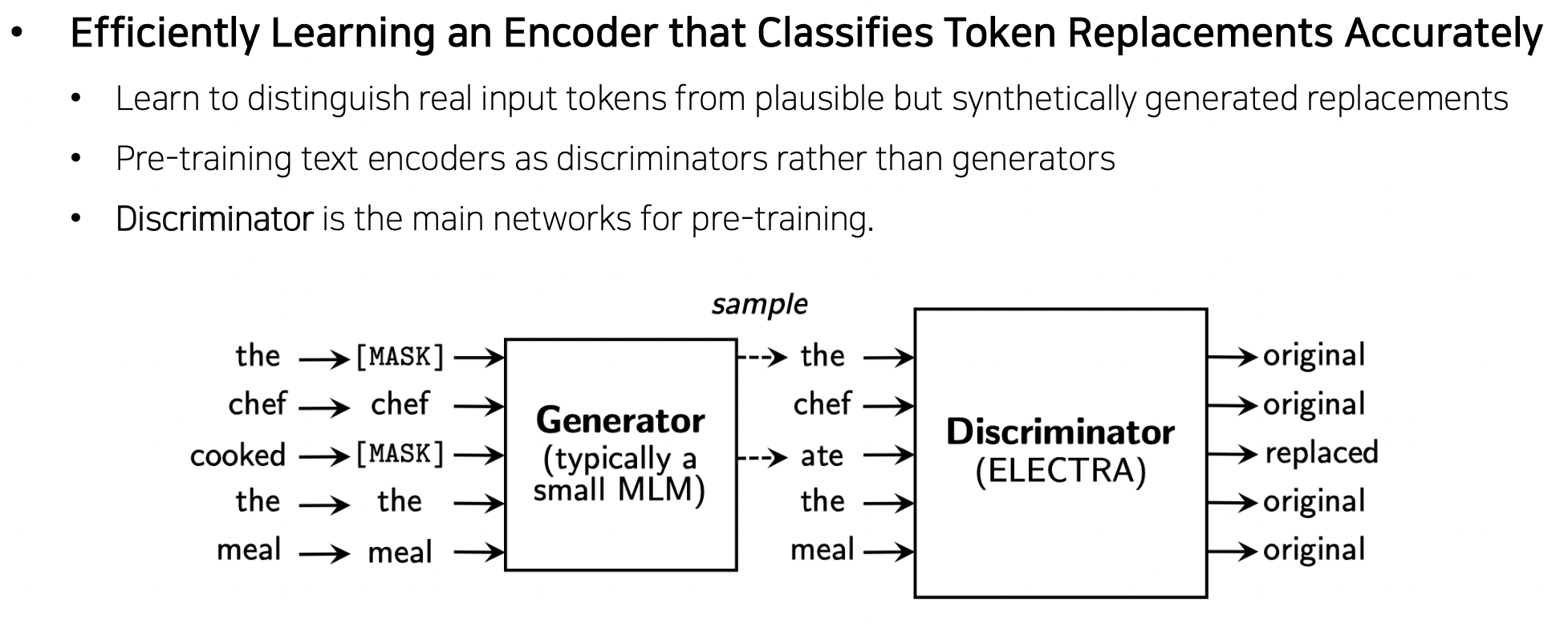
- Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- 랭귀지 모델에서 단어를 복원해주는 Generator (BERT) (원래 단어 → 마스크된 단어 → 제너레이터 → 원래 단어) 와 그 결과를 구분해주는 Discriminator (ELECTRA) (original, replaced 구분) 구조. 적대적 관계 (Adversarial). GAN 과 비슷.
- 즉, 예측한 단어가 완전한지 불완전한지 파악할 수 있게 됨
- 최종 학습되고 나서는 Generator 말고 Discriminator 를 down stream task 에 사용함
- 버트보다 성능 좋아짐
Light-weight Models
- 규모가 커서 비대해진 모델들 (비효율적) 을 적은 파라미터와 규모로 줄여주는 경량화 모델들
- 성능 유지하면서 크기와 계산 속도 줄여줌
- DistillBERT
- 트랜스포머를 이미 구현해서 사용하기 편하게 만든 HuggingFace 에서 발표한 논문
- 티쳐 모델 (스튜던트 모델을 가르침) 과 스튜던트 모델 (경량화된 모델, 티쳐 모델을 잘 모사할 수 있도록 함) 이 있음
- 티쳐에 I 라는 단어가 들어가서 go 가 나오면 go 확률이 높은 보캐뷸러리 사이즈의 소프트맥스 확률이 되는 것인데, 스튜던트는 I 가 들어갔을 때 ground truth 로 티쳐의 확률을 사용하여 잘 모사하도록 함.
- TinyBERT
- 티쳐와 스튜던트 구조이지만, 디스틸버트 방법 + 임베딩 레이어와 각 셀프 어텐션이 가지는 wq, wk, wv 등과 결과로 나오는 히든 스테이트 벡터까지도 스튜던트와 유사해지도록 (MSE loss 로) 학습.
- 하지만 티쳐의 히든 스테이트 벡터 크기보다 스튜던트의 h 벡터 크기가 더 작을 수 있어서 이 논문에서는 티쳐의 h 를 FC 를 거쳐 작은 크기로 변환되어 유사해지도록 해줌.
최신 트렌드
Fusing Knowledge Graph into Language Model
- 기존 프리트레이닝 모델과 지식 그래프 (외부적인 정보) 를 잘 겹합하여 연구
- 버트가 언어적 특성을 잘 이해하는지 분석하는 연구가 많이 진행되었음. 주어진 긴 글이 있을 때 문맥을 잘 파악하고 단어들 간의 유사도를 잘 파악하지만, 주어지지 않은 문장 (추가적인 정보가 필요한 경우) 에는 기존 정보를 잘 활용하지 못함
- 땅을 팠다 라는 주어진 문장 (꽃을 심기 위해, 집을 짓기 위해) 가 있을 때 무엇으로 팠을까? 질문하면 사람은 추측할 수 있지만 버트는 못 함 (상식, 외부지식을 활용해야 함)
- 지식 그래프로 개체간 관계를 정의해놓음
Further Reading
- How to Build OpenAI’s GPT-2: “ The AI That Was Too Dangerous to Release”
- GPT-2
- Illustrated Transformer
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, ICLR’20
- ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators, ICLR’20
- DistillBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, NeurIPS Workshop'19
- TinyBERT: Distilling BERT for Natural Language Understanding, Findings of EMNLP’20
- ERNIE: Enhanced Language Representation with Informative Entities, ACL'19
- KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoning, EMNLP'19
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.