2021 부스트캠프 Day12
[Day 12] 딥러닝 기초
Optimization
Gradient Descent
- 반복적으로 일차 미분값을 사용하여 국소적으로 최솟 값을 찾는 것을 목적으로 하는 알고리즘
Importtant Concepts in Optimization
- Generalization
- Under-fitting vs Over-fitting
- Cross validation
- bias-variance tradeoff
- Bootstrapping
- Bagging and boosting
Generalization
- 일반화 성능을 높이는 것이 목적이다.
- 일반적으로 traing error와 Test error의 차이를 Generalization gap이라 한다.
Underfitting vs Overfitting
- 학습데이터에서는 정확도가 높지만, Test데이터에서는 정확도가 낮을 경우 Overfittng이 발생했다고 한다.
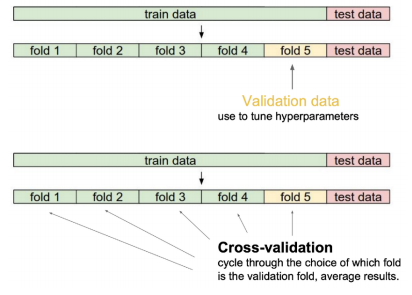
Cross validation
- 모델이 독립데이터 셋으로 일반화되는 방식을 평가하기 위한 모델 검증 기술
Bias-variance tradeoff
- underfitting과 overfitting과 이어지는 개념
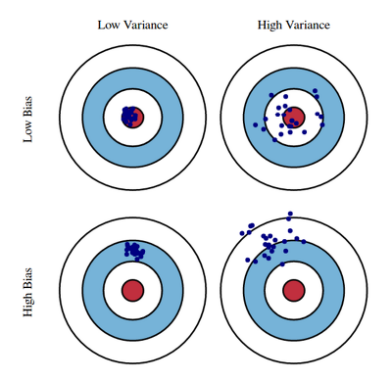
- 최소화하는 것(cost)이 세 부분으로 나뉘어 진다 : bias, variance, and noise

Bootstrapping
- 어떤 테스트 또는 메트릭스에서 램덤샘플링으로 대체하여 사용하겠다.
- 학습데이터를 여러개로 만들고, 여러 모델들을 만들어 적용.
- 모델들이 예측하는 값들의 일치성을 보고, 전체적인 모델들의 성능을 파악하기 위한 방법
Bagging and boosting
-
Bagging(Bootstrapping aggregating)
- Multiple models are being trained with bootstrapping.
- 앙상블기법이 bagging에 속하는 경우가 많다.
-
Boosting
- It focuses on thos specific training samples that are hard to classify.
- A strong model is built by combining weak learners in sequence where each learner learns from the mistakes of the previous weak learner.
- 결국에는 여러개의 weak learners 가 하나의 strong model을 만들어준다.
Practical Gradient Descent Methods
SGD(Stochastic gradient descent)
- Update with the gradient computed from a single sample
Mini-batch gradient descent
- Update with the gradient computed from a subset of data
Bath gradient descent
- Update with the gradient computed from a while data
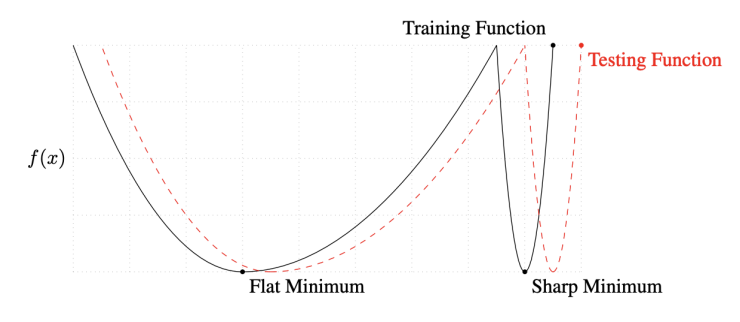
Batch-size Matters
- batch size를 작게 쓰는것이 일반적으로 좋다.
- batch size가 클수록 sharp minimizers에 도달하고, batch size가 작을수록 flat minimizers에 도달하게된다.
Gradient Descent

Momentum
- 한번 흘러간 gradient를 어느정도를 유지시켜준다. gradient가 많이 왔다갔다하더라도 잘 학습이 되는 성질이 있다.

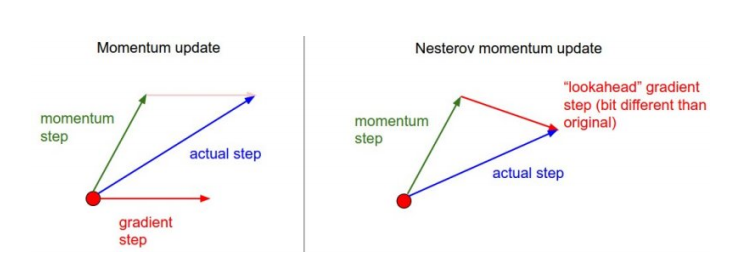
Newterov Accelerated Gradient
- 라는 현재 정보가 있으면 그 방향으로 한번 가보고, 그에 대해서 gradient를 개선하는 방법
- 최소화에 좀더 빠른 접근이 가능하다는 장점.
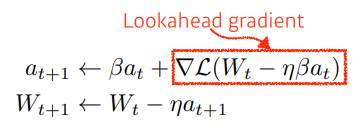
Adagrad
- 신경망의 파라미터가 얼마나 많이, 적게 변한지에 대해 집중하는 방법
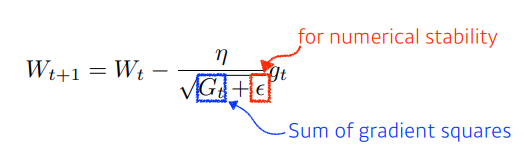
- 가장 큰 문제 : 결국 가 커질수록 학습이 멈추게 된다.
Adadelta
- 위 Adagrad의 에 대한 문제를 해결

RMSprop
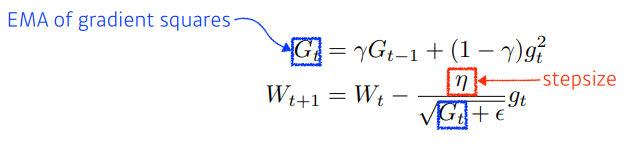
Adam
- 앞의 Moment 측정 방법론을 squared gradients에 대한 방법론과 합친 방법

Regularization
Generalization이 잘 되도록 하는 방법
Early Stopping
- validation loss와 같은 일정 기준을 두고, 학습을 일정기준에 따라 중단 시키는것.
Parameter norm penalty
- 학습을 시키는 경우 네트워크의 수가 작을 수록 좋다.

Data augmentation
- More data are always welcomed.
- 그렇지만, 주어진 데이터가 적은 경우가 많고, 이를 변화를 통해 학습데이터를 늘리는 방법
Noise robustness
- 입력데이터와 weights에 noise를 발생시켜 학습률을 높이는 방법
Label smoothing
- 데이터 두개를 뽑아, 이를 섞어주는 방법
- smoothing 효과가 있다.

- 교수님 경험상 노력대비 성능을 많이 높일 수 있는 방법(강추!)
Dropout
- 일정 네트워크를 버리는 방법
- 가장 일반적인 학습개선 방법
Batch normalization
- compute the empirical mean and variance independently for each dimention (layers) and normalize.
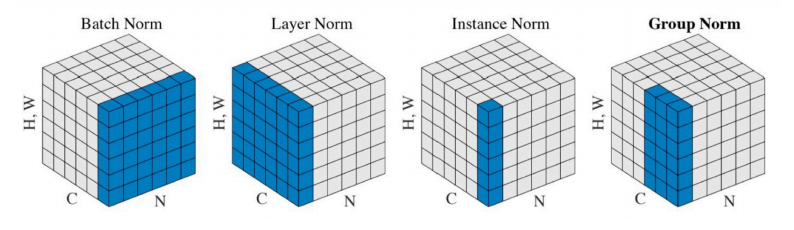
- 간단한 분류문제에서 활용하면 성능을 많이 높일 수 있는 방법이다.
Mathematics for Artificial Intelligence : CNN 첫걸음
Convolution 연산 이해하기
- 지금까지 배운 MLP는 각 뉴런들이 선형모델과 활성함수로 fully connected 구조
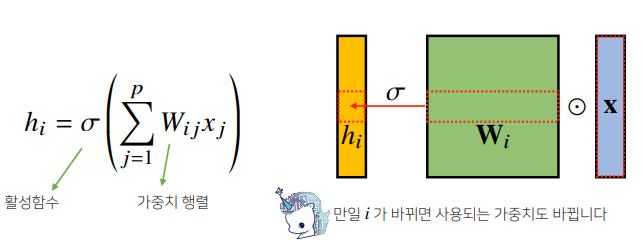
- Convolution 연산은 이와 달리 커널(kernel)을 입력벡터 상에서 움직여가면서 성형모델과 합성함수가 적용되는 구조
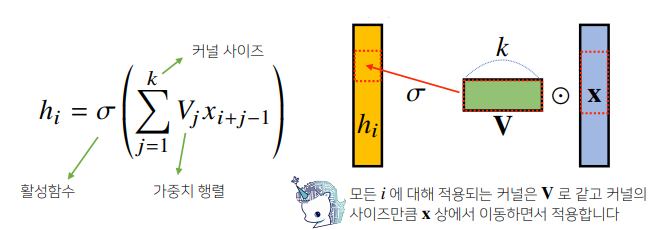
(활성화 함수를 제외한 convolution연산도 선형변환에 속한다.) - Convolution 연산의 수학적인 의미는 신호(signal)를 커널을 이용해 국소적으로 증폭 또는 감소시켜 정보를 추출 또는 필터링 하는 것.
- 커널은 정의역 내에서 움직여도 변하지 않고(traslation invaiant) 주어진 신호에 국소적(local)으로 적용된다.
다양한 차원에서의 Convolution
- 1차원뿐만 아니라 다양한 차원에서 계산가능.
- 데이터의 성격에 따라 사용하는 커널이 달라진다.
2차원 convolution 연산 이해하기
- 2D-Conv연산은 커널(kernel)을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조
- 입력 크기를 , 커널 크기를 (, ), 출력크기를 (, )라 하면 출력 크기를 다음과 같이 계산한다.
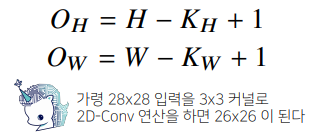
3차원 convolution 연산 이해하기
- 2차원 convolution을 3번 적용한다고 생각

Convolution 연산의 역전파
- Convolution연산은 커널이 모든 입력 데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 convolution연산이 나오게 된다.
Further Questions
올바르게 cross-validation을 하기위해서는 어떤 방법들이 존재할까요?
- answer : K-Fold CV, Stratified K-Fold CV, Leave-P-Out Cross Validation, Nested cross-validation(K*I-fold cv), Monte Carlo cv
- holdout cv

- k-fold cv
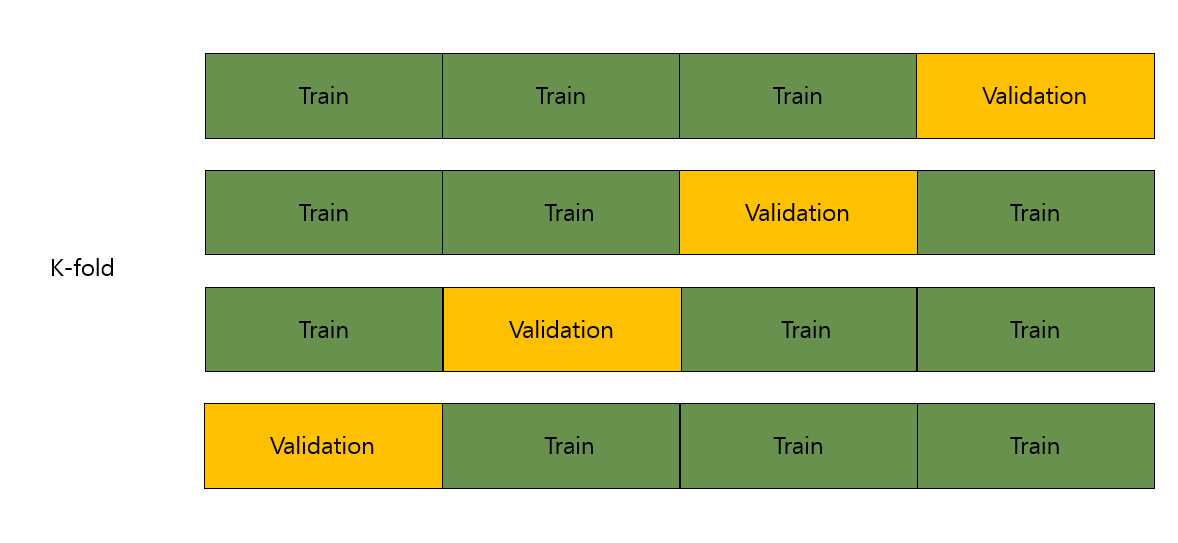
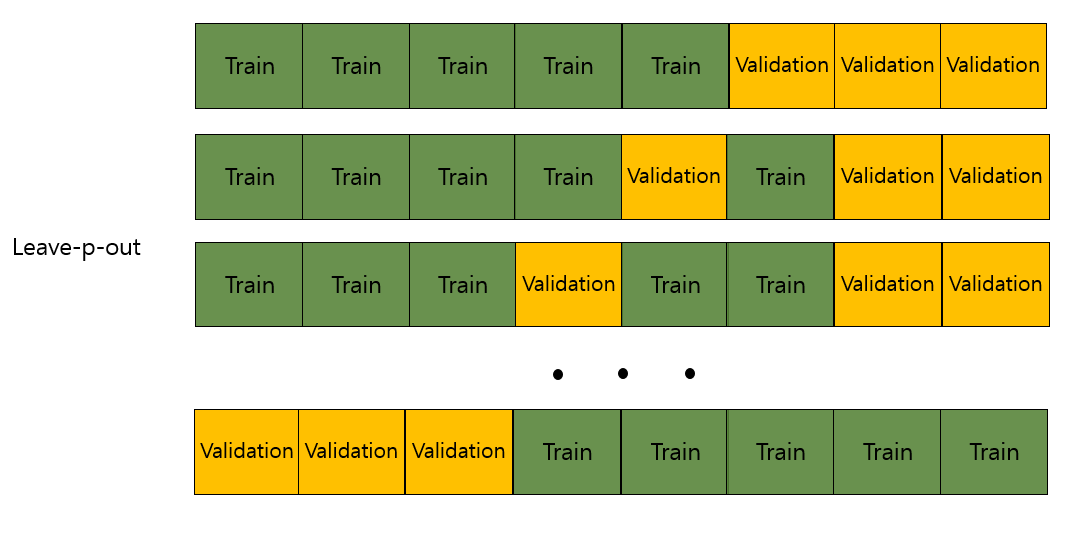
- Leave-P-out cv
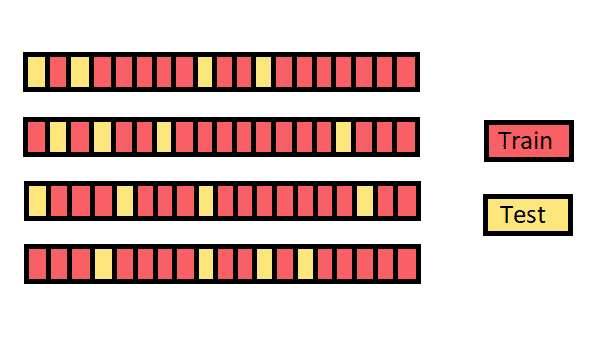
- Monte Carlo cv
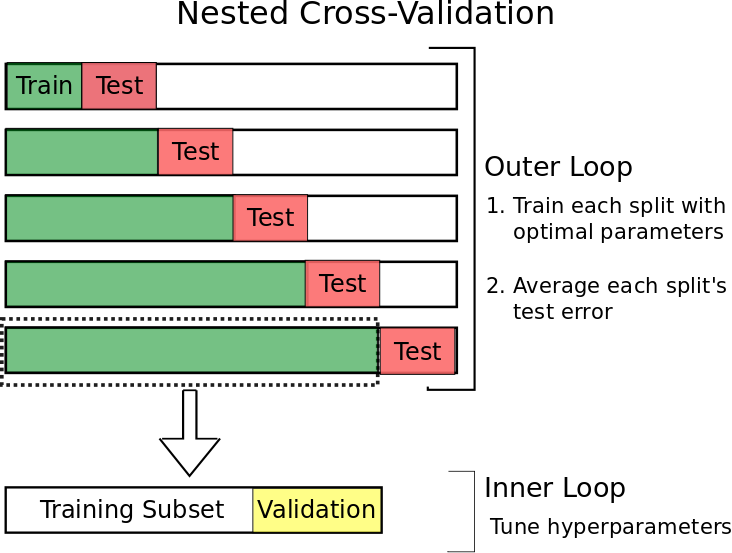
- Nested cv
- find link : https://towardsdatascience.com/cross-validation-in-machine-learning-72924a69872f, https://aiaspirant.com/cross-validation/
Time series의 경우 일반적인 k-fold cv를 사용해도 될까?
- 결론 : 안된다.
이유 : 시계열 데이터를 처리 할 때에는 두 가지 이유로 기존 교차 검증을 사용해서는 안된다.
1. 시간적 종속성
시계열 데이터의 경우 데이터 손실을 방지하기 위해 데이터를 분할 할 때 특히 주의해야한다.
우리가 현재에 서서 미래를 에측하기 위해는 시간순으로 발생하는 이벤트에 대한 모든 데이터를 보류해야한다. 따라서 k-fold 교차 검증을 사용하는 대신 시게열 데이터의 경우 데이터의 하위집합(일시적으로 분할)이 모델 성능 검증을 위해 사용.
2. 테스트 세트의 임의적? 멋대로인? 독단적인? (arbitary) 선택
that choice may mean that our test set error is a poor estimate of error on an independent test set. To address this, we use a method called Nested Cross-Validation.
BERT에 대한 스터디
medium의 towardsdatascience.com 채널을 요즘 흥미롭게 보고있다.
이 중 ClinicalBert에 대한 주제의 글을 보았다.
https://towardsdatascience.com/how-do-they-apply-bert-in-the-clinical-domain-49113a51be50
금일 스터디에 대해 논의 주제는 "subword Tokenization이 뭔지?" 이다.
이에 대해 medium에서 관련 글을 찾아보았다.
https://medium.com/@makcedward/how-subword-helps-on-your-nlp-model-83dd1b836f46
자주 참고하는 wikidocs도 참고하였다
https://wikidocs.net/86649
subword Tokenization?
서브워드 분리(Subword segmenation) 작업은 하나의 단어는 더 작은 단위의 의미있는 여러 서브워드들(Ex) birthplace = birth + place)의 조합으로 구성된 경우가 많기 때문에, 하나의 단어를 여러 서브워드로 분리해서 단어를 인코딩 및 임베딩하겠다는 의도를 가진 전처리 작업입니다. 이를 통해 OOV나 희귀 단어, 신조어와 같은 문제를 완화시킬 수 있습니다. 실제로 언어의 특성에 따라 영어권 언어나 한국어는 서브워드 분리를 시도했을 때 어느정도 의미있는 단위로 나누는 것이 가능합니다.
1. BPE(Byte Pair Encoding)
BPE(Byte pair encoding) 알고리즘은 1994년에 제안된 데이터 압축 알고리즘입니다. 하지만 후에 자연어 처리의 서브워드 분리 알고리즘으로 응용되었는데, 자연어 처리에 응용되어졌다.
BPE은 기본적으로 연속적으로 가장 많이 등장한 글자의 쌍을 찾아서 하나의 글자로 병합하는 방식을 수행합니다.
자연어 처리에서의 BPE는 글자(charcter) 단위에서 점차적으로 단어 집합(vocabulary)을 만들어 내는 Bottom up 방식의 접근을 사용한다.
우선 훈련 데이터에 있는 단어들을 모든 글자(chracters) 또는 유니코드(unicode) 단위로 단어 집합(vocabulary)를 만들고, 가장 많이 등장하는 유니그램을 하나의 유니그램으로 통합한다.
link : https://wikidocs.net/22592
2. WordPiece
Wordpiece는 다른 단어 분절 알고리즘과 비슷하다.(ex. BPE)
BPE와 비슷한 알고리즘으로 단어 분절이 진행되어지지만, 다른점은 likelihood기반으로 진행되어지지만 BPE와 같은 빈도수에 기반하여 진행되어지지 않는다.
알고리즘 순서
-
Prepare a large enough training data (i.e. corpus)
-
Define a desired subword vocabulary size
-
Split word to sequence of characters
-
Build a languages model based on step 3 data
-
Choose the new word unit out of all the possible ones that increases the likelihood on the training data the most when added to the model.
-
Repeating step 5until reaching subword vocabulary size which is defined in step 2 or the likelihood increase falls below a certain threshold.
3. Unigram Language Model
모든 하위 단어 발생이 독립적이고 하위 단어 발생 확률의 곱에 의해 하위 단어 시퀀스가 생성되는 방법
알고리즘 순서
-
Prepare a large enough training data (i.e. corpus)
-
Define a desired subword vocabulary size
-
Optimize the probability of word occurrence by giving a word sequence.
-
Compute the loss of each subword
-
Sort the symbol by loss and keep top X % of word (e.g. X can be 80). To avoid out-of-vocabulary, character level is recommend to be included as subset of subword.
-
Repeating step 3–5until reaching subword vocabulary size which is defined in step 2 or no change in step 5.
4. SentencePiece
- google이 개발한 subword tokenize
git link : https://github.com/google/sentencepiece/blob/master/python/README.md
5. Huggingface Tokenizer
Huggingface는 BERT, BART, ELECTRA 등등의 최신 자연어처리 알고리즘들을 TF, Torch로 구현한 transformers repository로 유명하다
Huggingface tokenizer는 아래 4가지 Tokenizer를 제공한다. 일반 BPE, Byte level BPE, SentencePiece, WordPiece이다.
- CharBPETokenizer: The original BPE
- ByteLevelBPETokenizer: The byte level version of the BPE
- SentencePieceBPETokenizer: A BPE implementation compatible with the one used by SentencePiece
- BertWordPieceTokenizer: The famous Bert tokenizer, using WordPiece
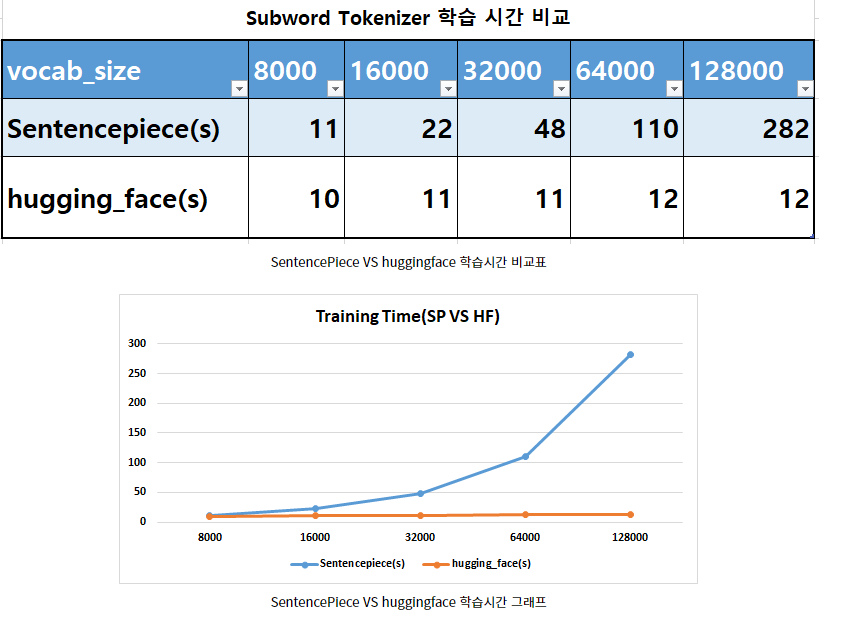
큰 장점은 Rust로 구현되어 1GB corpus에 대해 cpu로 20초만에 학습할 수 있다. 물론 tokenization도 빠르다.
6. opennmt
추가적인 내용
-
subword는 어휘 크기와 공간의 균형을 맞춘다.
좋은 결과를 얻기위해서는 16k 또는 32k 하위단어가 권장된다.(영어기반 기준) -
한국어는 공백으로 구분할 수 없다. 따라서 초기 어휘는 영어보다 훨씬 크게 구성된다.
단어 분할을 시작하려면 10k이상의 초기 단어를 준비해야 할 수도있으며, Schuster와 Nakajima 연구에서 한국어는 11k단어를 사용할 것을 권장한다. -
BERT 기반 요약, 번역모델 개발 시 BOS, EOS, SEP 등 추가 토큰들이 필요하다. 그러므로 user_defined_symbols을 이용해 Dummy token(UNK, unused, BOS, EOS 등등)을 추가해준다.