2021 부스트캠프 Day13
[Day 13] Convolutional Neural Network(CNN)
CNN
RGB Image Convolution
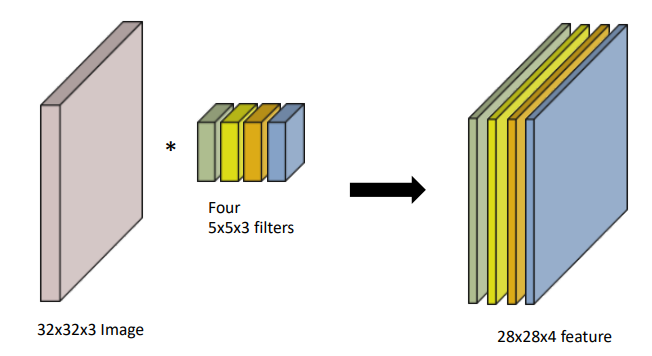
Stack of Convolutions
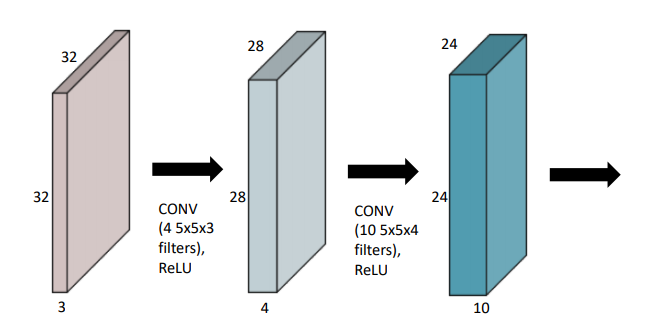
CNN 구성
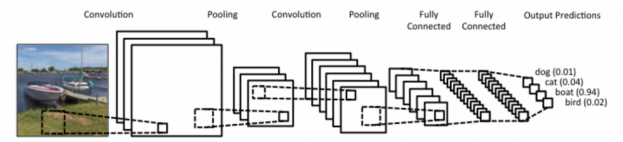
- CNN은 convolution layer, pooling layer, and fully connected layer로 구성
- Convolution and pooling layers : feature extraction(특징 추출)
- Fully connected layer : decision making (ex. classification)
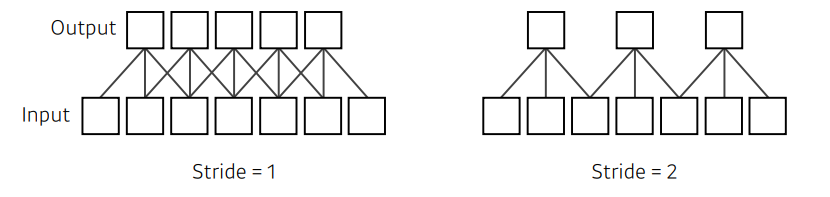
Stride
- 내가 가지고 있는 kernel(filter)를 적용시키는 간격
Padding
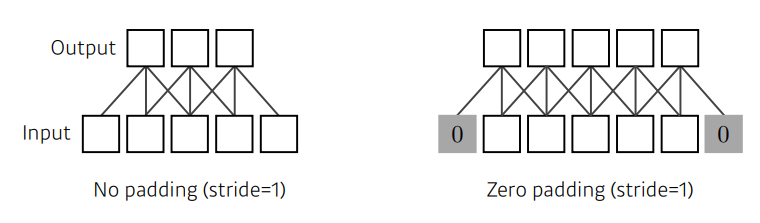
Convolution Arthmetic
- ex. Padding 1, Stride 1, 3 X 3 Kernel
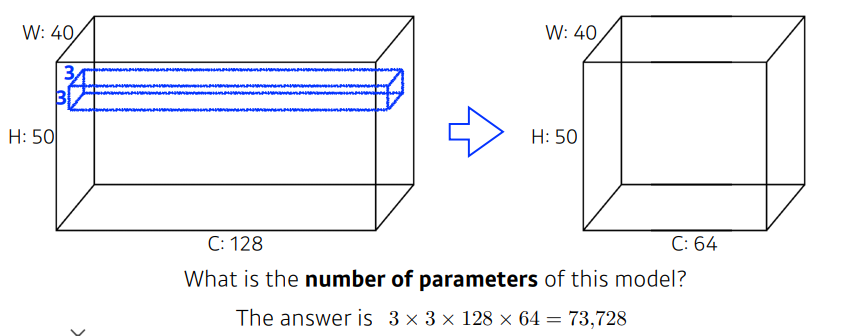
Exercise
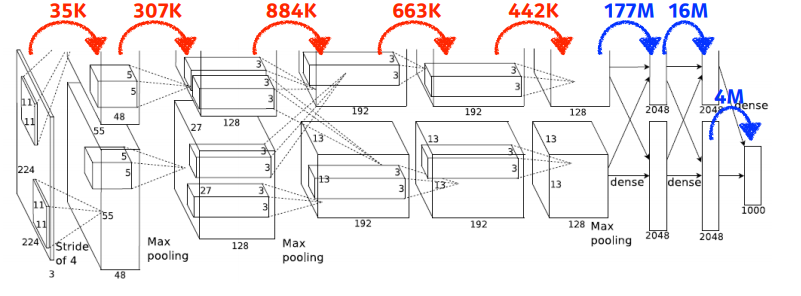
- 11 x 11 x 3 x 48 x 2 = 35k
- 5 x 5 x 48 x 128 x 2 = 307k
- 3 x 3 x 128 x 2 x 192 x 2 = 884k
- 3 x 3 x 192 x 192 x 2 = 663k
- 3 x 3 x 192 x 128 x 2 = 442k
- 13 x 13 x 128 x 2 x 2048 x 2 = 177M (Dense Layer)
- 2048 x 2 x 2048 x 2 = 16M (Dense Layer)
- 2048 x 2 x 1000 = 4M (Dense Layer)
1 X 1 Convolution
- 이미지에서 한 pixel만 보는 의미
- Dimension reduction(차원 감소)
- To reduce the number of parameters while increasing the depth
- ex. bottleneck architecture
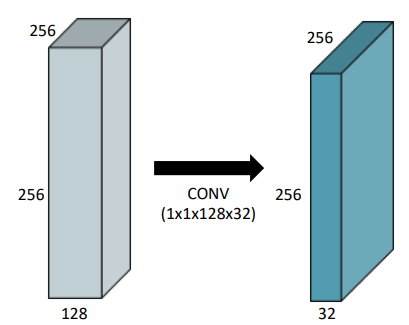
- 내가 이전에 찾아보았었던 좋은 설명 link가 있다.
https://hwiyong.tistory.com/45
Modern Convolutional Neural Networks
이번 강의에 대해서는 자주 보는 medium의 towardsdatascience채널에 있는 글을 통해 한번 정리된 자료를 보았었다.
https://towardsdatascience.com/illustrated-10-cnn-architectures-95d78ace614d
AlexNet
최초로 Deep Learning을 이용하여 ILSVRC에서 수상.
ILSVRC
ImageNet Large-Scale Visual Recognition Challenge
Classification / Detection / Localization / Segmentation
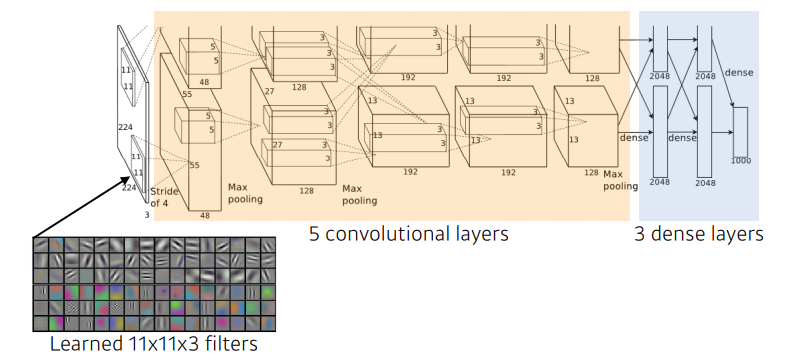
- Key ideas
- ReLU activation
- GPI implementation (2 GPUs)
- Local response normalization, Overlapping pooling
- Data augmentation
- Dropout
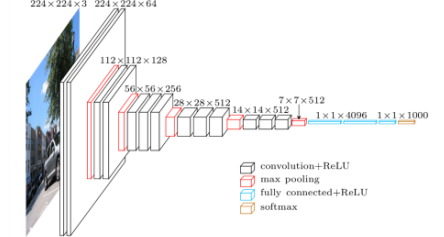
VGGNet
- 3x3 Convolution을 이용하여 Receptive field는 유지하면서 더 깊은 네트워크를 구성.
- 1x1 convolution for fully coneected layers
- 3x3 Convolution
- 3x3이 두번 진행될경우 5x5하나를 사용할 경우 receptive field는 똑같다.
- weight이 더 적어지므로 메모리의 효율이 높아지고, 실행속도도 높다.
- layer가 많을 수록 더 고차원적으로 뽑아내니, 3x3을 2번 사용했을 경우 layer가 5x5보다 증가되므로 더 고차원적인 feature를 뽑아낸다.
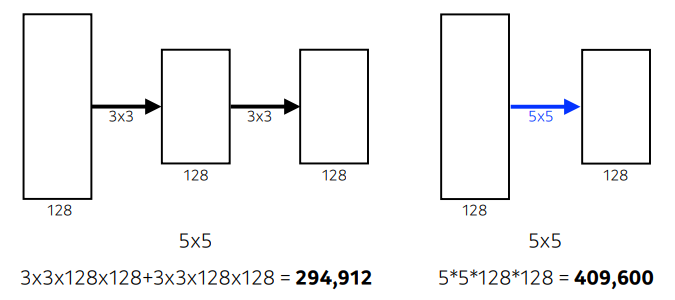
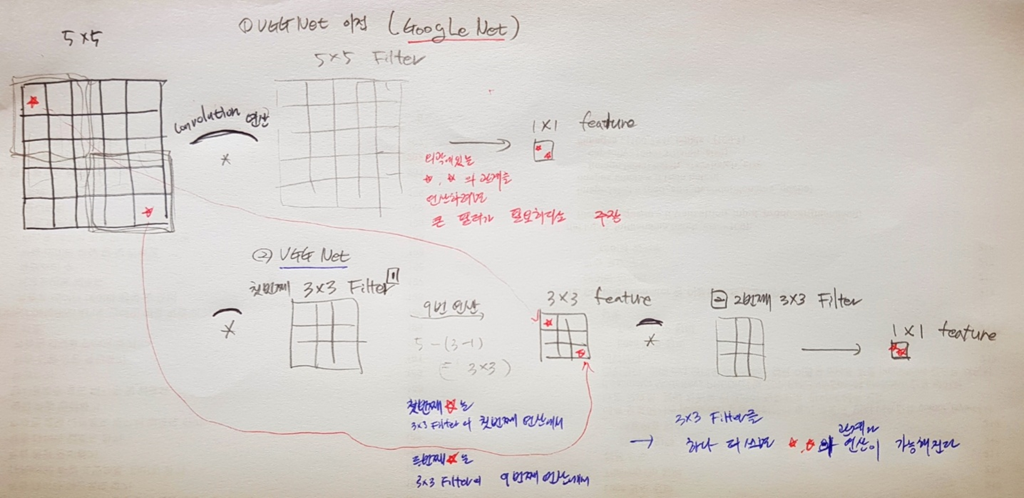
image from : https://nittaku.tistory.com/266
GoogLeNet
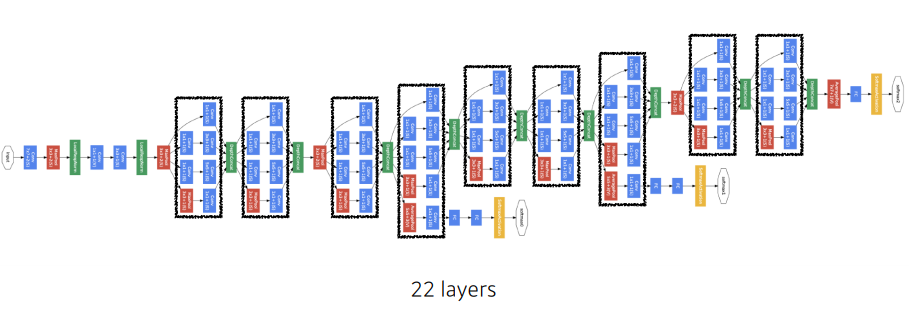
-
Inception blocks 을 제안.
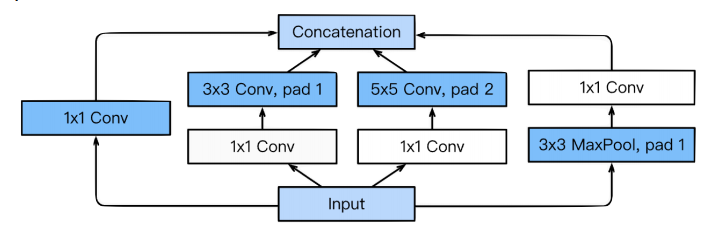
-
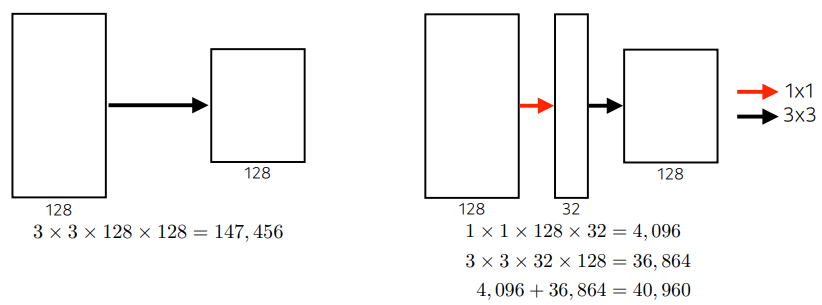
1x1 block을 활용함으로써 channel-wise dimension을 감소 시키면서, 결과적으로 parameter number를 감소할 수 있다.
-
benefit of 1x1 convolution
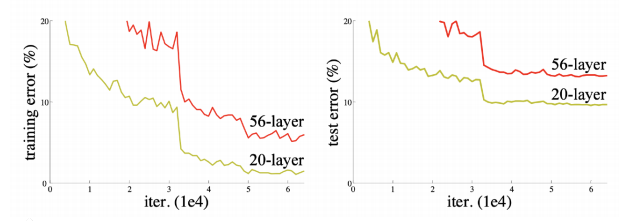
ResNet
- 당시 상황 : deeper neural networks are hard to train
- Add an identity map(skip connection)
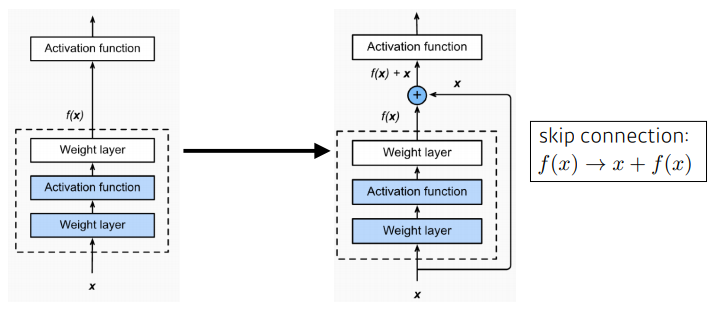
- Add an identity map after non linear activations
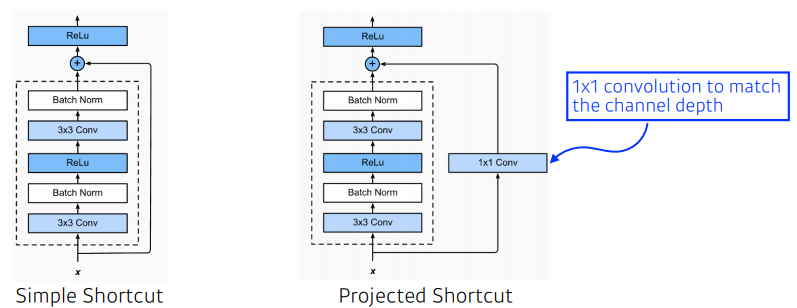
- batch normalization after convolutions
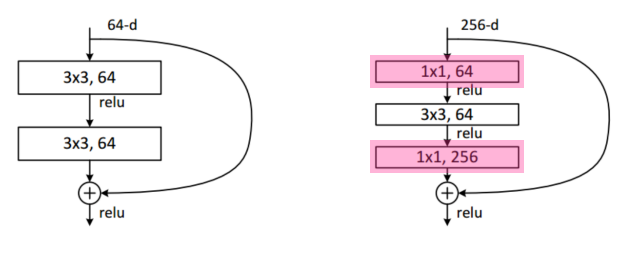
- Bottleneck architecture
DenseNet
- Resnet과 비슷한 아이디어지만 Addition이 아닌 Concatenation을 적용한 CNN.
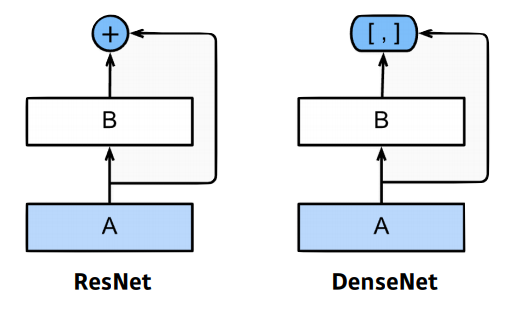

- Dense Block
- Each layer concatenates the feature maps of all preceding layers.
- The number of channels increases geometrically.
- Transition Block
- BatchNorm -> 1x1 Conv -> 2x2 AvgPooling
- Dimension reduction
Computer Vision Applications
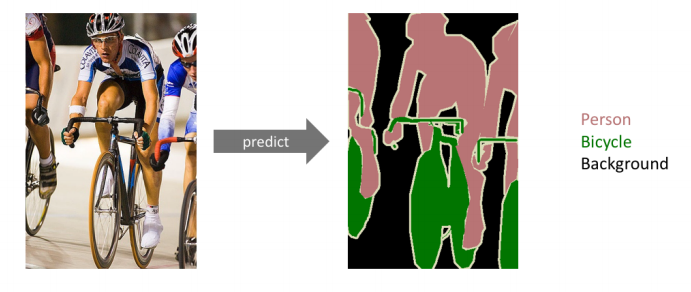
Semantic Segmentation
- 어떤 이미지가 있을 때, 각 이미지의 픽셀마다 분류하는 것.
- 자율주행 분야에서 활용이 많이 된다. 사람, 자동차에 대한 인식
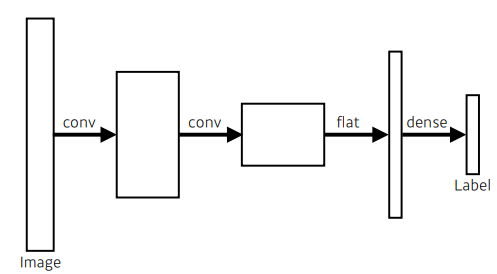
Fully Convolutional Network
-
위 이미지에서의 dense layer를 conv layer로 진행하는 방법
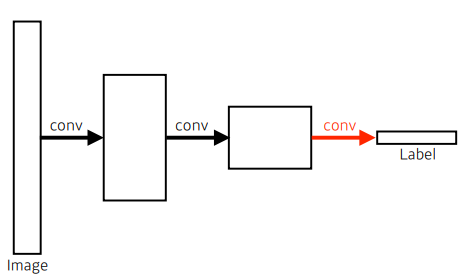
-
parameter의 차이는 없다.

left : 4x4x16x10 = 2560
right : 4x4x16x10 = 2560 -
그럼 왜 사용하는 것일까?
- dense layer와는 달리 input image의 size에 상관없이 동작할 수 있다.
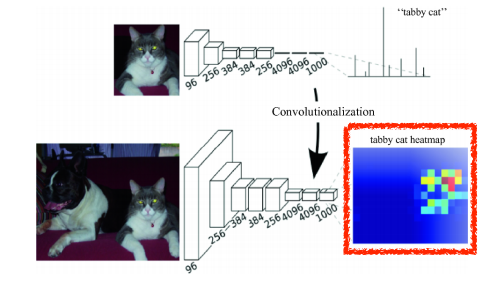
- dense layer와는 달리 input image의 size에 상관없이 동작할 수 있다.
-
while FCN can fun with inputs of any size, the ouput dimensions are typically reduced by subsampling.
-
So we need a way to connect the coarse ouput to the dense pixels.
Deconvolution
-
special dimension을 키워준다.
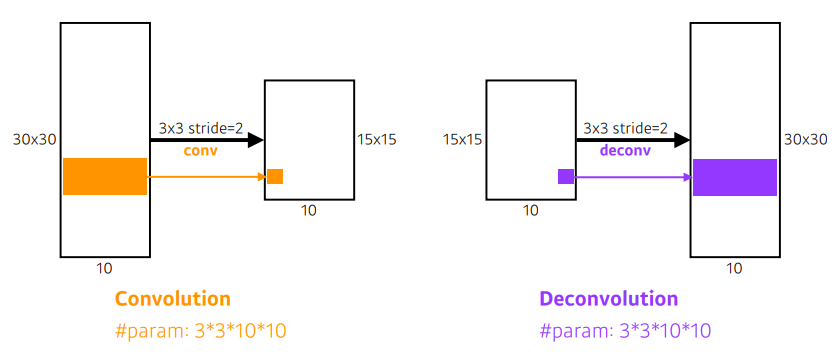
-
results
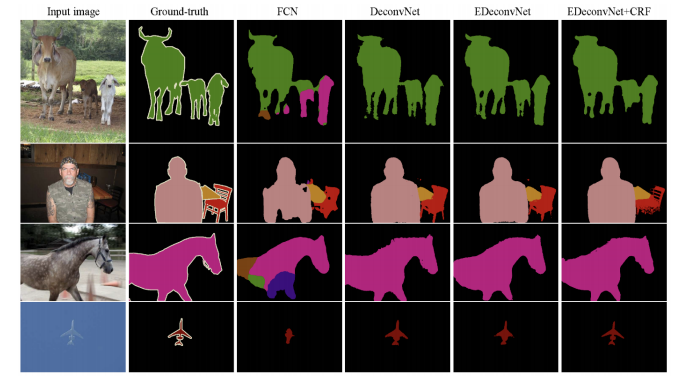
-
좀 더 자세한 내용을 원해 towardsdatascience에서 링크를 찾았다.
https://towardsdatascience.com/review-deconvnet-unpooling-layer-semantic-segmentation-55cf8a6e380e
Detection
R-CNN
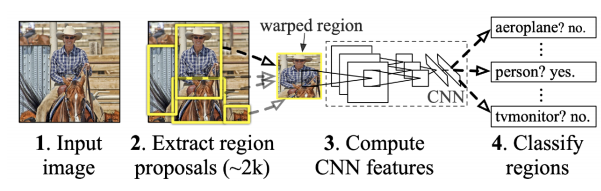
1. takes an input image
2. extracts around 2000 region proposals
3. compute features for each proposal(using AlexNet)
4. classifies with linear SVMs.
- 가장 큰 문제 : bounding box에서 2000개를 뽑으면 cnn을 2000번을 돌려야한다. 시간이 2000배로 걸린다.
SPPNet
- 위 문제를 cnn을 한번만 돌도록 진행.
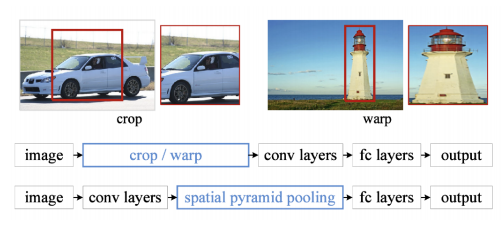
Fast R-CNN
- SPPNet과 동일안 concept를 사용.
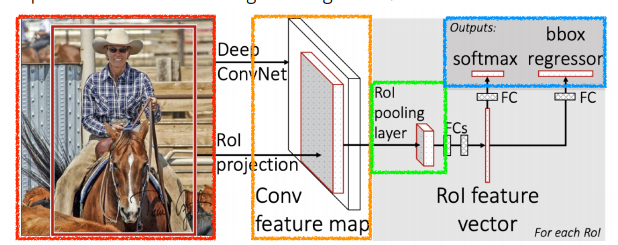
- Takes an input and a set of bounding boxes.
- Generated convolutional feature map
- For each region, get a fixed length feature from ROI pooling
- Two outputs: class and bounding-box regressor.
Faster R-CNN
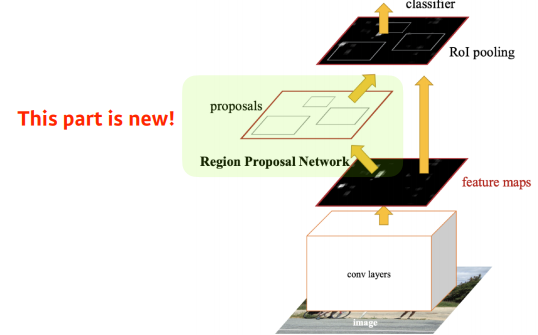
- bounding box를 뽑는 것도 network로 학습하자!
- Faster R-CNN = Regoin Proposal Network + Fast R-CNN
Region Proposal Network
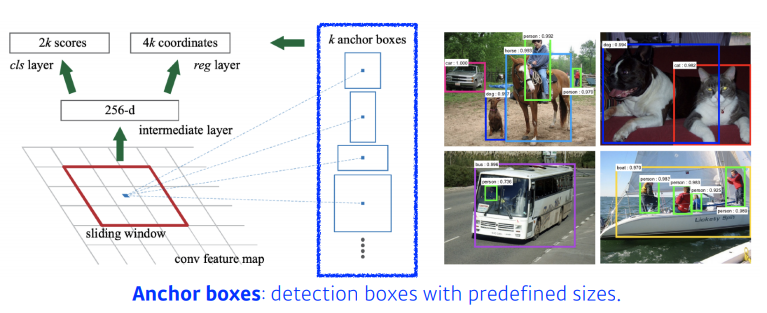
-
anchor boxes : 어떤 크기의 물체들이 있을 것 같다는 것을 미리 정의한다.
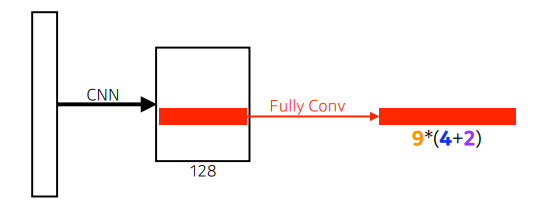
-
Fully conv가 활용
- 9 : Three different region sizes (128, 256, 512) with three different ratios. (1:1, 1:2, 2:1)
- 4 : four bounding box regression parameters
- 2 : box classification(whether to use it or not)
-
이에 대해 좀더 알기위해 towardsdatascience의 링크를 찾았다.
https://towardsdatascience.com/region-proposal-network-a-detailed-view-1305c7875853
YOLO
나는 이전의 프로젝트에서 object detect파트를 담당했을 때 yolo-v3를 사용했었다.
- Yolo is an extremely fast object detection algorithm
- It simultaneously predicts multiple bounding boxes and class probabilities.
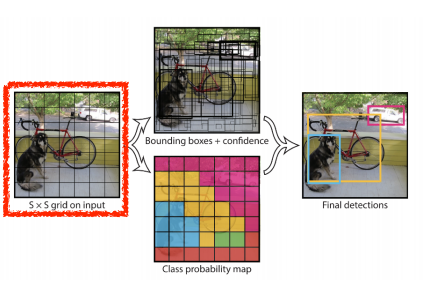
-
이미지가 들어오면 SxS grid로 나누어준다.
- 찾고싶은 물체가 해당 grid의 중앙에 들어오게되면, 해당 grid셀이 해당 물체에 대한 bounding box와 해당 물체가 무엇인지 같이 예측
-
각각의 셀은 B개의 bounding box를 예측하게 된다.
- box refinement(x,y,w,h)
- confidence(of objectness)
-
동시에 각각의 SxS grid가 이 중점에 해당하는 물체의 class를 예측해준다.
-
결국, bounding box와 box가 어느 클래스인지 예측해준다.
- SxSx(Bx5+C) size.
- SxS : Number of cells of the grid
- Bx5 : B bounding boxes with offsets (x,y,w,h) and confidence
- C : Number of classes
link : https://taeu.github.io/paper/deeplearning-paper-yolo1-02/
