2021 부스트캠프 Day6
[Day 6] Numpy / 벡터 / 행렬
Numpy
- Numerical Python
- 공성능 과학 계산용 패키지
- Matrix와 Vector와 같은 Array 연산의 사실상의 표준
import numpy as npNumpy 특징
- 일반 List에 비해 빠르고, 메모리 효율적
- 반복문 없이 데이터 배열에 대한 처리 지원
- 선형대수와 관련된 다양한 기능 제공
ndarray
- numpy는 np.array 함수를 활용하여 배열 생성 -> ndarray
test_array = np.array([1,4,5,8], float)- numpy는 하나의 데이터 type만 배열에 넣을 수 있음
- List와 가장 큰 차이점 -> dynamic typing not supported
Array dtype
- ndarray의 single element가 가지는 data type
- 각 element가 차지하는 memory의 크기가 결정됨
Array nbytes
- nbytes : ndarray object의 메모리 크기를 반환함
Handling shpae
reshape
- Array의 shape크기를 변경
np.array(test_matrix).reshape(-1,2).shpae
#size를 기반으로 row 개수 선정(-1)
#위 예시의 경우 test_matrix가 2*4 라고 할때, ?,2로 바꿔주려고 -1이 4가 자동으로 적용flatten
- 다차원 array를 1차원 array로 변환
- 이전 프로젝트 CNN사용 시, 늘 함께 사용되어졌었다.
Cration function
arange
- array의 범위를 지정하여, 값의 list를 생성하는 명령어
np.arange(10)
# array([0,1,2,3,4,5,6,7,8,9])
np.arange(0,5,0.5) # floating point도 표시가능함
# array([0., 0.5, 1., 1.5, 2., 2.5, 3., 3.5, 4., 4.5])zeros
- 0으로 가득찬 ndarray 생성
np.zeros(shape=(10,), dtype=np.int8)ones
- 1로 가득찬 ndarray생성
empty
- shape만 주어지고 비어있는 ndarray 생성(memory initialization이 되지 않음)
something_like
- 기존 ndarray의 shape의 크기 만큼, 1, 0 또는 empty array를 반환
test_mat = np.arange(30).reshape(5,6)
np.ones_like(test_matrix)identity
- 단위 행렬(i 행렬)을 생성함, 대각행렬
np.identity(n=3, dtype=np.int8)
# array([[1,0,0],[0,1,0],[0,0,1]], dtype=int8)eye
- 대각선이 1인 행렬, k값의 시작 index의 변경이 가능
np.eye(3, 5, k=2)
# array([[0., 0., 1., 0., 0.],
# [0., 0., 0., 1., 0.],
# [0., 0., 0., 0., 1.]])diag
- 대각 행렬의 값을 추출함
- eye와 같은 k의 값을 통해 시작 인덱스를 변경할수 있다.
random sampling
- 데이터 분포에 따른 sampling으로 array를 생성
np.random.uniform() # 균등분포
np.random.normal() # 정규분포operation functions
sum
- ndarray의 합
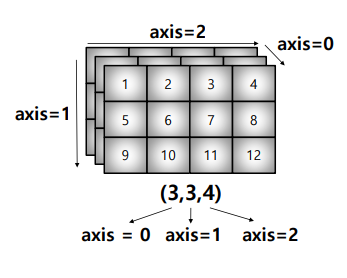
axis
- 모든 operation functions을 실행할 때 기준이 되는 dimension 축
mean & std
- ndarray의 element들 간의 평균 또는 표준 편차를 반환
concatenate
- numpy array를 합치는(붙이는) 함수
a = np.array([1,2,3])
b = np.array([2,3,4])
np.vstack((a,b)) # array([[1,2,3],[2,3,4]])
np.concatenate((a,b), axis = 0) # array([[1,2,3],[2,3,4]])
a = np.array([[1],[2],[3]])
b = np.array([[2],[3],[4]])
np.hstack((a,b)) # array([[1,2],[2,3],[3,4]])Comparisons
All & Any
- all : 모두가 조건에 만족한다면 True
np.all - any : 하나라도 조건에 만족한다면 True
np.any
np.where, np.isnan, np.isfinite
np.where(a>0, 3, 2) #where(condition, True, False)
# array([3, 3, 2])
a = np.arange(10)
np.where(a>5) # Index값 반환
a = np.array([1, np.NaN, np.Inf], float)
np.isnan(a) # array([False, True, False], dtype=bool)
np.isfinite(a)
#array([True, False, False], dtype=bool)argmax & argmin
- array내 최대값 또는 최소값의 index를 반환함
boolean & fancy index
boolean index
- 특정 조건에 따른 값을 배열 형태로 추출
test_array = np.array([1, 4, 0, 2, 3, 8, 9, 7], float)
test_array > 3
# array([False, True, False, False, False, True, True, True], dtype=bool)fancy index
- numpy는 array를 index value로 사용해서 값 추출
a = np.array([2, 4, 6, 8], float)
b = np.array([0, 0, 1, 3, 2, 1], int) # 반드시 int로 선언
a[b] # backet index, b 배열의 값을 index로 하여 a의 값들을 추출함
# array([2., 2., 4., 8., 6., 4.])
a.take(b) #take함수 : backet index와 같은 효과Mathematics for Artificial Intelligence
벡터
- 벡터는 숫자를 원소로 가지는 리스트 또는 배열
- 벡터는 공간에서 한 점을 나타낸다
- 벡터는 원점으로부터 상대적 위치를 표현
- 벡터에 숫자를 곱해주면 길이만 변한다.
- 벡터끼리 같은 모양을 가지면 덧셈, 뺄셈, 성분곱(Hadamard product)을 계산할 수 있다.
벡터의 덧셈과 뺄셈
- 두 벡터의 덧셈, 뺄셈은 다른 벡터로부터 상대적 위치이동을 표현
벡터의 노름
-
벡터의 노름(norm)
기호 : ||a||은 원점에서부터의 거리
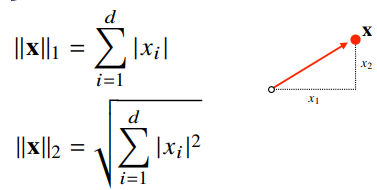
-
임의의 d차원에 대해 성립
-
L1-노름 : 각 성분의 변화량의 절대값을 모두 더한다.
-
L2-노름 : 피타고라스 정리를 이용해 유클리드 거리를 계산.
np.linalg.norm -
노름의 종류에 따라 기하학적 성질이 달라진다.
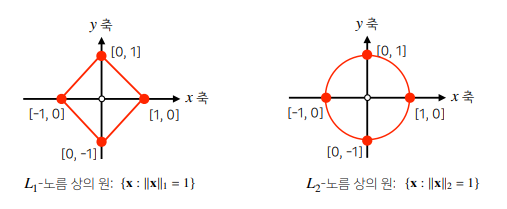
( 머신러닝에선 각 성질들이 필요할 때가 있으므로 둘다 사용 ) -
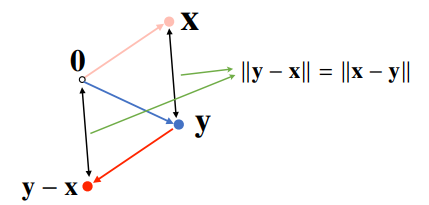
L1, L2-노름을 이용해 두 벡터 사이의 거리를 계산, 벡터의 뺄셈 이용
-
두 벡터 사이의 각도 계산, 제2 코사인 법칙, L2-노름에서만 가능하다.
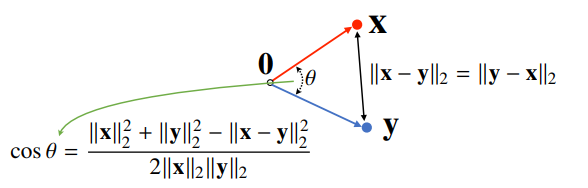
( 분자를 쉽게 계산하는 방법이 내적 )
내적
- 내적은 정사영(orthogonal projection)된 벡터의 길이와 관련
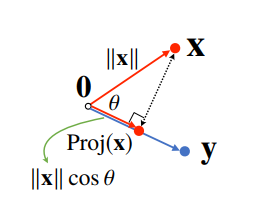
- Proj(x)의 길이는 코사인 법칙에 의해
||x||cosθ가 된다. - 내적은 정사영의 길이를 벡터 y의 길이
||y||만큼 조정한 값 (<x, y> = ||x||2 ||y||2 cosθ) - 내적은 두 벡터의 유사도(similarity)를 측정하는데 사용
행렬
- 벡터를 원소로 가지는 2차원 배열
- 행렬의 특정 행(열)을 고정하면 행(열)벡터라 부름
- 행렬끼리 같은 모양을 가지면 덧셈, 뺄셈, 성분곱을 계산할수 있음
행렬 곱셈(matrix multiplication)
- i번째 행벡터와 j번째 열벡터 사이의 내적
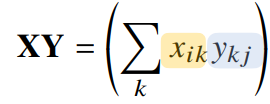
- numpy에선
@연산을 사용ex. X @ Y - numpy의 np.inner는 i번째 행벡터와 j번째 행벡터 사이의 내적을 성분으로 가지는 행렬을 계산, 수학에서 말하는 내적과는 다르므로 주의
- 행렬곱을 통해 패턴을 추출하고 데이터를 압축할수 있다.
역행렬
- 어떤 행렬 A의 연산을 거꾸로 되돌리는 행렬을 역행렬(inverse matrix)이라 부르고 A-1 라 표기한다. 역행렬은 행과 열 숫가자 같고 행렬식(determinant)이 0이 아닌 경우에만 계산할수 있다.
- 만일 역행렬을 계산할 수 없다면 유사역행렬(pseudo-inverse) 또는 무어-펜로즈(Moore-Penrose) 역행렬 A+을 이용한다.
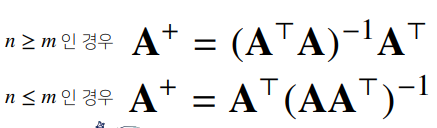
연립 방정식 풀기
-np.linalg.pinv를 이용하면 연립방정식의 해를 구할 수 있다.

Preparation student who dreams of becoming an AI engineer.