2021 부스트캠프 Day7
[Day 7] 경사하강법
딥러닝에서 아주 중요한 학습 최적화 방법.
미분(differentiation)
- 변수의 움직임에 따른 함수값의 변화를 측정하기 위한 도구, 최적화에서 제일 많이 사용
import sympy as sym
sym.diff(sym.poly(x**2 + 2*x + 3), x)- 함수
f의 주어진 점(x,f(x))에서의 접선의 기울기 - 한 점에서 접선의 기울기를 알면 어느 방향으로 점을 움직여야 함수값이 증가하는지/감소하는지 알 수 있다.
( 증가시키고 싶다면 미분값을 더하고, 감소시키고 싶으면 미분값을 뺀다. ) - 미분값을 더하면 경사상승법(gradient ascent)이라 하며 함수의 극대값의 위치를 구할 때 사용
- 미분값을 빼면 경사하강법(gradient descent)이라 하며 함수의 극소값의 위치를 구할 때 사용 -> 목적함수를 최소화할 때 사용
- 경사상승/경사하강 방법은 극값에 도달하면 움직임을 멈춘다. -> 극값에선 미분값이 0
경사하강법 알고리즘
# Input : gradient(미분을 계산하는 함수)
# init : 시작점
# lr : 학습률(경사하강법을 다룰 때 민감하므로 주의해서 다루어야 한다.)
# eps : 알고리즘 종료조건
var = init
grad = gradient(var)
while(abs(grad) > eps):
var = var - lr * grad
grad = gradient(var)변수가 벡터라면?
- 벡터가 입력인 다변수 함수의 경우 편미분(partial differentiation)을 사용
import sympy as sym
sym.diff(sym.poly(x**2 + 2*x*y +3) + sym.cos(x + 2*y), x)
# 2*x + x*y -sin(x + 2*y)- 각 변수 별로 편미분을 계산한 그래디언트(gradient)벡터를 이용하여 경사하강/경사상승법에 사용
- 그래디언트 벡터 ∇f(x,y)는 각점(x,y)에서 가장 빨리 증가하는 방향으로 흐르게 된다.
- -∇f(x,y)는 각점(x,y)에서 가장 빨리 감소하는 방향으로 흐르게 된다.
경사하강법 알고리즘 : 벡터
- 경사하강법 알고리즘은 그대로 적용되며, 벡터는 절대값 대신 노름(norm)을 계산해서 종료조건을 설정
# Input : gradient(그레디언트 벡터를 계산하는 함수)
# init : 시작점
# lr : 학습률(경사하강법을 다룰 때 민감하므로 주의해서 다루어야 한다.)
# eps : 알고리즘 종료조건
var = init
grad = gradient(var)
while(norm(grad) > eps):
var = var - lr * grad
grad = gradient(var)선형회귀분석
np.linalg.pinv를 이용하면 데이터를 선형모델(linear model)로 해석하는 선형회귀식을 찾을 수 있다.- 선형모델의 경우 아래와 같은 무어-펜로즈 역행렬을 이용해서 회귀분석이 가능하다.
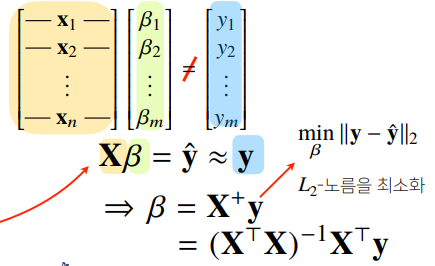
- 선형모델의 경우 무어-펜로즈 역행렬을 이용해서 가능하지만, 선형모델이 아닌 경우 무어-펜로즈를 사용하지 못하게 되며 경사하강법을 일반적으로 사용하므로 경사하강법을 통한 선형모델을 알아야한다.
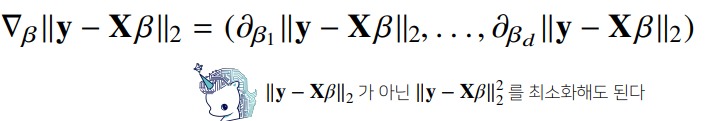
- 선형회귀 목적식은 ||y=Xβ||2이고 이를 최소화하는 β를 찾아야 하므로 위와 같은 그레디언트 벡터를 구해야 한다.
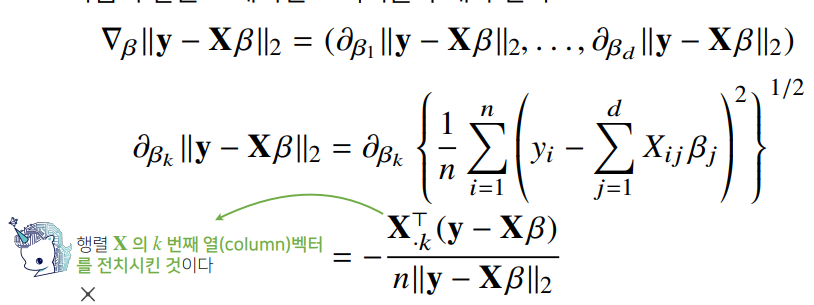
- 복잡한 계산이지만 사실 Xβ를 계수 β에 대해 미분한 결과인 XT만 곱해지는 것
경사하강법 : 선형회귀
- λ앞에 붙은 마이너스(-) 부호가 플러스(+) 부호로 바뀐 것에 주의
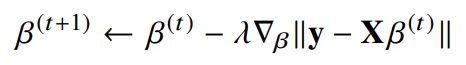
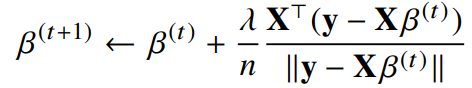
# Input : X, y
# Ountput : beta
# lr : 학습률(경사하강법을 다룰 때 민감하므로 주의해서 다루어야 한다.)
# norm : L2-노름을 계산
# T : 학습횟수
for t in range(T):
error = y - X @ beta
grad = - transpose(X) @ error
beta = beta - lr * grad- 오늘날 경사하강법 알고리즘에서는 종료조건으로 학습률과 학습횟수가 중요한 hyperparameter가 된다.
- 이론적으로 경사하강법은 미분가능하고 볼록(convex)한 함수에 대해선 적절한 학습률과 학습횟수를 선택했을 때 수렴이 보장
- L2-노름(norm)을 사용하게 되는데 이는 회귀계수 beta(β)에 대해 볼록함수 이기 때문에 수렴이 보장
- 하지만, 비선형회귀 문제의 경우 목적식이 볼록하지 않을 수 있으므로 수렴이 항상 보장되지는 않는다.
(딥러닝을 사용하는 경우 목적식은 대부분 볼록함수가 아니다.)
확률적 경사하강법(SGD : Stochastic Gradient Descent)
- 모든 데이터를 사용해서 업데이트 하는 대신 데이터 한개 또는 일부 활용하여 업데이트
- 볼록이 아닌(non-convex) 목적식은 SGD를 통해 최적화 할 수 있다.
(SGD라고 해서 만능은 아니지만 딥러닝의 경우 SGD가 경사하강법보다 실증적으로 더 낫다고 검증) - 데이터의 일부를 통해 parameter를 업데이트 하기에 연산자원을 좀더 효율적으로 활용하는데 도움

확률적 경사하강법 : 미니배치 연산
- SGD는 미니배치(전체데이터가 아닌 일부 데이터)를 가지고 그레디언트 벡터를 계산하므로 원래 경하강법 그래프와는 조금 차이가 발생
- 미니배치는 확률적으로 선택하므로 목적식 모양이 바뀌게 된다.
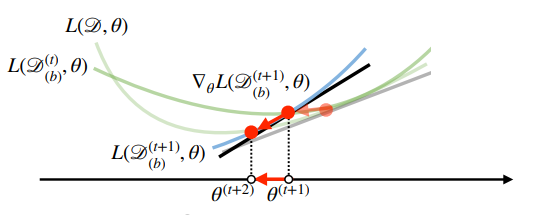
- 볼록이 아닌 목적식에서도 사용 가능하므로 경사하강법보다 머신러닝 학습에 더 효율적
( 극소점(극대점)에서 목적식이 확률적으로 바뀌게 되므로 극소점이 더이상 아니게 된다. 목적식이 바뀌게 되었을 경우 min이 0이아니게 되므로, 일반적인 경사하강법 보다 효율적 )

Preparation student who dreams of becoming an AI engineer.