Expanded Fine-tuning
Fine tuning
참고)
- 지식백과 Question Answering: HyperCLOVA 지식의 한계에 도전합니다. : https://tv.naver.com/v/23649497
- 언어 모델 학습과 사용 쉽게 하세요! : 효율적이고 확장성 있는 사내 라이브러리 개발기 : https://tv.naver.com/v/23650773
일반적인 방법
- 일반적인 Finetuning은 사전학습 모델의 모든 Layer를 열어두고 학습을 진행.
- 더 나아가 사전학습 Layer는 Freeze하고 task를 위한 Additional layer들을 추가해 사전학습의 representation을 활용 (위 방법 보다 조금 더 적은 resource)
따라서, 여러 fine tuning 방법론이 제시되고 있다.

In-context Learning
-
prompt learning 이라고도 불림.
-
점점 Model은 커지게 되고, 이를 Finetuning하는 것은 더욱 많은 resource가 필요하게 되어지며 해결하기 위한 방법들이 나오면서 P-Tuning이 GPT-3논문에서 제시되며 화두
-
기존 finetuning 방법 보다 정확도는 낮지만 적은 resource를 이용해 finetuning을 진행가능.
-
Prompt의 길이(개수)를 정해주는 것에 따른 성능차이가 크다
-
어떤 데이터셋이냐 어떤 태스크이냐 학습셋의 row수가 얼마이냐 배치를 얼마나둘거냐에 대해 매우 민감
-
이를 동적으로 정해주는 방법들에 대한 연구가 다양하게 이루어지고 있다.
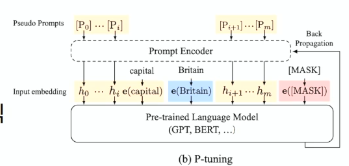
P-tuning
-
Prompt based tuning 이라고도 불림
-
GPT Understands, Too. 2021.03.18
https://arxiv.org/abs/2103.10385 -
작은 사이즈의 Prompt Encoder를 Embedding layer에 추가해 사전학습 model의 weight는 제외하고 prompt 토큰만 continuous space에서 학습시킨 Light-weight Fine-tune 방식
네이버 데뷰에서는 누구는 써봤는데 안좋다고 하고 누구는 써봤는데 좋다고 하고......
LoRA : Low-Rank Adaption
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (2021.08.16) - Microsoft
Paper : https://arxiv.org/pdf/2106.09685.pdf
Code : https://github.com/microsoft/LoRA
Adapter
- 여러 Task를 학습하면서 생긴 정보를 활용해 각 Task의 성능을 끌어올리는 Transfer Learning 기법에 의해 제안된 개념.
최근 NLP에서는 비슷한 task에 대한 학습을 각 task별 모델을 따로 두는 것이 아닌, 하나의 모델을 이어서 학습하는 방식이나 Q&A와 같은 하나의 task로 해결하는 기술 및 연구들이 이루어짐.
ex. T5(Text-to-Text Transfer Transformer)
Google에서 작년말에 발표한 기술로 전이학습에 대해서 Deep하게 다루면서 GLUE, SUPER GLUE benchmark에서 Human baseline에 상회하는 성능을 내면서 잠깐 화두됨.
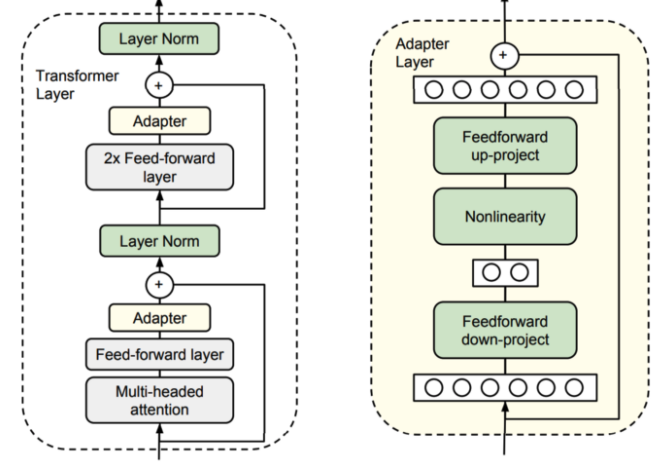
- 나아가서 사전학습 모델에 추가적인 Layer를 어떻게 잘 배치해, Fine-tuining시 더 적은 resource를 활용할 지에 대한 기술
More Detail : https://amazingguni.medium.com/paper-adapterfusion-non-destructive-task-composition-for-transfer-learning-752a8d616a74
LoRA
-
올해 Microsoft에서 발표한 Adaptation 방법
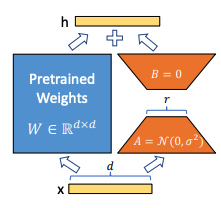
-
단순 Fine tuning보다 더 좋은 성능
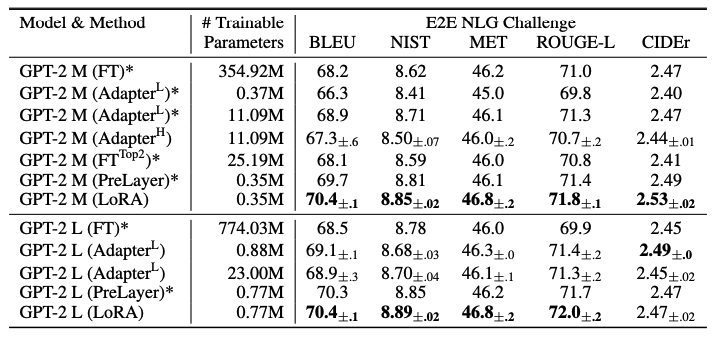
-
다른 Finetuning 방법론대비 매우 적은 Resource
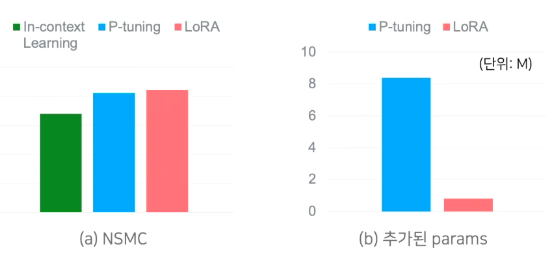
HyperCLOVA 1.3B 실험 결과(from. DEVIEW)

좋은 글 잘 읽었습니다!