GO SOPT 서버파트 2차 세미나(Spring boot의 이해) 스스로 학습 키워드 정리입니다.
⭐️ PUT과 PATCH의 차이점
👉 PUT: 리소스의 모든 것을 업데이트 한다.
👉 PATCH : 리소스의 일부를 업데이트 한다.
아래와 같은 원본 데이터를 수정한다고 가정해보자!
{
"name": "이동섭", // 이름
"age": 24, // 나이
"major": "컴퓨터교육" // 전공
}PUT은 리소스의 모든 것을 업데이트하기 떄문에, 아래와 같이 요청을 보냈을 때 전달하지 않은 필드의 값은 모두 null이나 초기값으로 바뀐다.
👉 요청
PUT /api/user/1234
{
"age": 20
}
👉 결과 ❌
{
"name": null, // ????
"age": "20,
"major": null // ????
}따라서 아래와 같이 모든 필드의 값을 body에 담아서 요청을 보내야한다.
👉 요청
PUT /api/user/1234
{
"name": 이동섭, // 업데이트하지 않는 필드도 함께 보내야함
"age": 20,
"major": "컴퓨터교육" // 업데이트하지 않는 필드도 함께 보내야함
}
👉 결과 ⭕️ 원하는대로 업데이트강 이루어진 모습!
{
"name" : 이동섭,
"age": "20,
"major": "컴퓨터교육"
}업데이트 하고싶은 필드만 body에 담아서 보내고 싶다면 PUT 대신 PATCH를 사용하면 된다.
👉 요청
PATCH /api/user/1234
{
"age": 20
}
👉 결과 ⭕️ 원하는대로 업데이트강 이루어진 모습!
{
"name" : 이동섭,
"age": "20,
"major": "컴퓨터교육"
}⭐️ 자바의 컴파일 과정
❗️ 자바는 OS에 독립적인 특징을 가지고 있음. 그것이 가능한 이유는 JVM 덕분인데, JVM은 자바 프로그램이 어느 기기나 운영체제 상에서도 실행될 수 있도록 하며 프로그램 메모리를 관리하고 최적화 하는 역할을 함
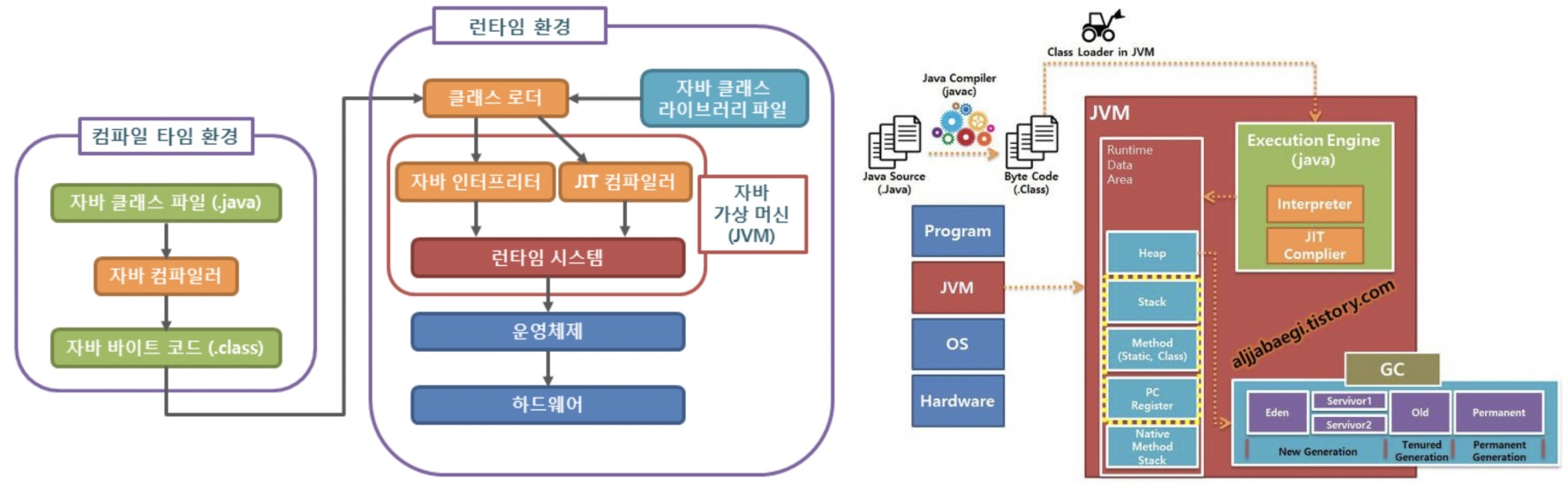
1️⃣ 개발자가 자바 소스코드(.java)를 작성
2️⃣ 자바 컴파일러(Java Compiler)가 자바 소스파일을 컴파일. 이때 나오는 파일은 바이트 코드 (.class) 파일로, 아직 컴퓨터가 읽을 수 없는 JVM만 이해할 수 있는 코드
3️⃣ 컴파일된 바이트 코드를 JVM의 클래스 로더(Class Loader)에게 전달
4️⃣ 클래스 로더는 동적 로딩(Dynamic Loading)을 통해 필요한 클래스들을 로딩 및 링크하여 런타임 데이터 영역(Runtime Data area), 즉 JVM의 메모리에 올림
👉 클래스 로더 세부 동작
1) 로드: 클래스 파일을 가져와서 JVM의 메모리에 로드
2) 검증: 자바 언어 명세 및 JVM 명세에 명시된 대로 구성되어 있는지 검사
3) 준비: 클래스가 필요로 하는 메모리를 할당
4) 분석: 클래스의 상수 풀 내 모든 심볼릭 레퍼런스를 다이렉트 레퍼런스로 변경
5) 초기화: 클래스 변수들을 적절한 값으로 초기화 (static 필드)
5️⃣ 실행 엔진(Excution Engine)은 JVM 메모리에 올라온 바이트 코드들을 명령어 단위로 하나씩 가져와서 실행. 이때 실행 엔진은 두가지 방식으로 변경함
👉 인터프리터: 바이트 코드 명령어를 하나씩 읽어서 해석하고 실행. 하나하나의 실행은 빠르나, 전체적인 실행 속도가 느리다는 단점이 있음
👉 JIT 컴파일러(Just-In-Time Compiler): 인터프리터의 단점을 보완하기 위해 도입된 방식으로, 바이트 코드 전체를 컴파일하여 바이너리 코드로 변경하고 이후에는 해당 메서드를 더이상 인터프리팅 하지 않고, 바이너리 코드로 직접 실행하는 방식. 바이트 코드 전체가 컴파일된 바이너리 코드를 실해하는 것이기 때문에 전체적인 실행 속도는 인터프리팅 방식보다 빠름
⭐️ Builder Pattern
객체를 생성하기 위해서는 생성자 패턴, 정적 메소드 패턴, 수정자 패턴, 빌더 패턴 등을 사용할 수 있음
그중 빌더 패턴(Builder Pattern)은 아래와 같은 4가지 장점이 있기 때문에 다른 객체 생성 패턴보다 사용하는 것이 권장됨
1️⃣ 필요한 데이터만 설정할 수 있음
예를 들어 User 객체를 생성해야 하는데 age라는 파라미터가 필요 없는 상황이라고 가정해보자
생성자나 정적 메소드를 이용하는 경우라면 age에 더미 값을 넣어주거나 age가 없는 생성자를 새로 만들어주어야 함
// 1. 더미값을 넣어주기
User user = new User("서버파트원", 0, 180, 80)
// 2. 생성자 또는 정적 메소드를 추가하기
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private int age;
private int height;
private int weight;
public User (String name, int height, int weight) { // age가 없는 생성자를 추가
this.name = name;
this.height = height;
this.weight = weight;
}
public static User of(String name, int height, int weight) { // age가 없는 정적 메소드를 추가
return new User(name, 0, height, weight);
}
}이러한 방법은 요구사항이 계속 변화할 때 반복적인 변경을 필요로 하고, 이는 시간 낭비로 이어짐
하지만 빌더 패턴을 이용하면 객체 생성시에 파라미터 설정을 동적으로 처리할 수 있게 됨
User user = User.builder()
.name("서버파트원")
.height(180)
.weight(80).build();2️⃣ 유연성을 확보할 수 있음
예를 들어 User 클래스에 전공을 나타내는 새로운 변수 major을 추가해야 한다고 가정해보자
하지만 이미 아래와 같이 생성자로 객체를 만드는 코드가 있을 수 있는데, 그러면 새롭게 추가되는 변수 때문에 기존의 코드를 수정해야하는 상황에 직면하게 됨. 기존의 코드가 방대하다면 이러한 수정이 감당하기 어려울 수 있음
// 기존
User user = new User("서버파트원", 24, 180, 80)
// 전공 필드 추가를 위해선 코드 변경 필요
User user = new User("서버파트원", 24, 180, 80, "컴퓨터공학")하지만 빌더 패턴을 이용하면 새로운 변수가 추가되는 등의 상황이 생겨도 기존의 코드에 영향을 주지 않을 수 있음
왜냐하면 빌더 패턴은 유연하게 객체의 값을 설정할 수 있도록 도와주기 때문
3️⃣ 가독성을 높일 수 있음
빌더 패턴을 사용하면 매개변수가 많아져도 가독성을 높일 수 있음.
생성자로 객체를 생성하는 경우에는 각각의 매개변수가 무엇을 의미하는지 바로 파악이 힘들지만, 빌더 패턴을 적용하면 직관적으로 어떤 데이터에 어떤 값이 설정되는지 쉽게 파악하여 가독성을 높일 수 있음
// 어떤 데이터에 어떤 값을 넣는지 파악하기가 어려움
User user = new User("서버파트원", 24, 180, 80)
// 어떤 데이터에 어떤 값이 들어가는지 파악하기가 쉬움
User user = User.builder()
.name("서버파트원")
.age(24)
.height(180)
.weight(80).build();4️⃣ 변경 가능성을 최소화할 수 있음
수정자 패턴(Setter)을 사용할 경우 불필요하게 변경 가능성을 열어두게 됨. 이는 유지보수 시에 값이 할당된 지점을 찾기 힘들게 만들며, 불필요한 코드 리딩 등을 유발함. 만약 값을 할당하는 시점이 객체의 생성뿐이라면 객체에 잘못된 값이 들어왔을 때 그 지점을 찾기 쉬우므로 유지보수성이 훨씬 높아짐
변경 가능성을 최소화하는 가장 좋은 방법은 변수를 final로 선언하는 방법인데, 이를 적용하여 위의 User 클래스를 아래와 같이 수정할 수 있음
@Builder // 자동으로 클래스에 builder() 메소드를 생성해줌
@RequiredArgsConstructor
public class User {
private final String name;
private final int age;
private final int height;
private final int weight;
}경우에 따라서 클래스 변수에 final을 붙일 수 없는 경우라면, Setter을 구현하지 않음으로써 동일한 효과를 얻을 수 있음
@Builder
@AllArgsConstructor
public class User {
private String name;
private int age;
private int height;
private int weight;
// Setter를 구현 X
}❗️ 객체를 생성하는 대부분의 경우에는 빌더 패턴을 적용하는 것이 좋지만, 대표적으로 크게 다음의 2가지 상황에서는 빌더를 구현할 필요가 없음
👉 객체의 생성을 라이브러리로 위임하는 경우
엔티티(Entity)나 도메인(Domain) 객체로부터 DTO를 생성하는 경우라면, 직접 빌더를 만들고 하는 작업이 번거로우므로 MapStruct나 Model Mapper와 같은 라이브러리를 통해 생성을 위임할 수 있음
👉 변수의 개수가 2개 이하이며, 변경 가능성이 없는 경우
정적 팩토리 메소드를 사용하는 것이 더 좋을 수 있음, 오히려 빌더를 남용할 경우 코드를 비대하게 만들 수 있으므로 적용할지 판단할 것!
⭐️ 오늘 사용한 모든 Annotation
@Getter
xxx라는 필드에 대해 자동으로 getXxx 메소드를 만들어주는 어노테이션 (boolean 타입의 경우 isXxx 메소드)
private로 선언되어 있는 클래스의 필드 값을 외부에서 안전하게 사용하기 위해 getX 메소드를 (접근자라고도 함) 선언해주는 일이 자주 있는데, 이를 자동으로 생성해주는 편리한 어노테이션
필드 레벨이 아닌 클래스 레벨에 @Getter 어노테이션을 선언해줄 경우, 모든 필드에 접근자가 자동으로 생성됨
@Setter
xxx라는 필드에 대해 자동으로 setXxx 메소드를 만들어주는 어노테이션
private로 선언되어 있는 클래스의 필드 값을 외부에서 안전하게 수정하기 위해 setX 메소드를 (설정자라고도 함) 선언해주는 일이 자주 있는데, 이를 자동으로 생성해주는 편리한 어노테이션
필드 레벨이 아닌 클래스 레벨에 @Setter 어노테이션을 선언해줄 경우, 모든 필드에 설정자가 자동으로 생성됨
@NoArgsConstructor
파라미터가 없는 기본 생성자를 만들어줌
@AllArgsConstructor
모든 필드 값을 파라미터로 받는 생성자를 만들어줌
👉 access = AccessLevel.PRIVATE
'AccessLevel.PRIVATE'는 생성된 생성자를 private로 설정해야 함을 나타냄. 즉, 생성자는 클래스 자체 내에서만 호출할 수 있으며 다른 클래스에서는 호출할 수 없음
이는 클래스의 모든 인스턴스가 직접 인스턴스화가 아닌 정적 팩터리 메서드 또는 빌더 패턴을 통해 생성되도록 하는 방법임.
이는 클래스에서 개체의 생성 및 초기화를 제어하고 코드를 보다 강력하고 유지 관리할 수 있도록 만드는 데 도움이 될 수 있음
@RequiredArgsConstructor
final이나 @NonNull인 필드 값만 파라미터로 받는 생성자를 만들어줌
@Override
상위 클래스가 가지고 있는 메소드를 하위 클래스가 재정의(오버라이드) 해서 사용할 때 붙이는 어노테이션
사용하지 않아도 에러는 발생하지 않지만, 컴파일 타임에 오타와 같은 휴먼 이슈를 잡아줄 수 있다는 점에서 안전핀 역할을 하므로, 사용하는 것이 권장됨
또한 @Override를 표시함으로써 코드 리딩시에 이 메소드가 오버라이딩 되었음을 쉽게 파악할 수 있음
@Controller
컨트롤러 역할을 하는 클래스에 사용하는 어노테이션
해당 어노테이션이 적용된 클래스는 컨트롤러임을 나타내고, Bean으로 등록되며, Spring에게 해당 클래스가 컨트롤러로 사용됨을 알림
이후에 설명할 @RestController와 다르게, View를 반환하기 위해 사용됨
@Service
서비스 역할을 하는 클래스에 사용하는 어노테이션
해당 어노테이션이 적용된 클래스는 서비스임을 나타내고, Bean으로 등록되며, Spring에게 해당 클래스가 서비스로 사용됨을 알림
@Repository
레포지토리 역할을 하는 클래스에 사용하는 어노테이션
해당 어노테이션이 적용된 클래스는 레포지토리임을 나타내고, Bean으로 등록되며, Spring에게 해당 클래스가 레포지토리로 사용됨을 알림
@RequestBody
HttpRequest의 본문 requestBody의 내용을 Java 객체로 매핑하는 역할을 함
@ResponseBody
메소드에서 return된 값을(Java 객체 등) HttpResponse의 본문 responseBody에 매핑시키는 역할을 함 (Json 형태 등으로 매핑됨)
@RestController
@Controller에 @ResponseBody가 추가된 것으로, 컨트롤러가 Json 형태로 객체 데이터를 반환하는 등 HttpResponse의 body에 값을 직접 반환하기 위해 사용됨
@RequestMapping
특정 HTTP Method와 URI를 통해 들어온 HTTP request를 어떻게 처리할지에 대해 컨트롤러에 정의하고 있음
이때, 컨트롤러에 정의된 특정 메소드와 매핑하기 위해 @RequestMapping 어노테이션을 사용
method 속성을 통해 어떤 HTTP Method로 받을 것인지 설정하고, value 속성을 통해 요청받을 URI를 설정함
이떄 method 속성을 사용하는 대신, @GetMapping이나 @PostMapping과 같은 어노테이션을 주로 사용함
@RequestMapping을 메소드가 아닌 컨트롤러 클래스 위에 사용하면, 아래와 같이 공통적으로 처리할 URI를 손쉽게 처리할 수 있음
@RestController
@RequestMapping(value = "/hello")
public class HelloController {
// URI가 "/hello/hi" 꼴로 들어오는 경우와 매핑됨
@GetMapping("/hi")
public String helloGet(...) {
...
}
@PostMapping()
public String helloPost(...) {
...
}
}@SpringBootApplication
프로젝트 구조에 가장 상단에 위치하며, main메소드가 있는 XXXApplication 클래스에서 사용됨
스프링 부트의 가장 기본적인 설정을 담당하는데, 아래와 같은 기능을 포함함
@SpringBootApplication = @SpringBootConfiguration + @EnableAutoConfiguration + @ComponentScan
👉 @SpringBootConfiguration : 사용자가 추가적으로 빈이나 설정 클래스들을 등록 가능하게 함
👉 @EnableAutoConfiguration : jar properties를 기반으로 자동으로 의존성 설정
👉 @ComponentScan : @Component가 적용된 클래스들을 스캔하여 자동으로 빈 등록
