GO SOPT 서버파트 3차 세미나(관계형 데이터베이스와 JPA) 스스로 학습 키워드 정리입니다.
⭐️ 데이터베이스 제약조건
데이터의 무결성을 지키기 위해 입력받은 데이터에 대한 제한을 두는 것을 의미
1️⃣ NOT NULL : 제약조건을 설정 시, 해당 필드는 null 값을 저장할 수 없게 하는 제약조건
CREATE TABLE user(
name VARCHAR(20) NOT NULL // name 필드는 null 값 저장 불가
);2️⃣ UNIQUE : 제약조건을 설정 시, 중복된 값을 저장할 수 없게 하는 제약조건
// 👍 기본적인 UNIQUE
CREATE TABLE user(
contact VARCHAR(20) UNIQUE // contact 필드는 중복된 값 저장 불가
);
// 👍 CONSTRAINT를 통해 제약조건에 이름부여
Create TABLE user(
contact VARCHAR(20),
...
CONSTRAINT uq_contact UNIQUE contact
// contact 필드에 중복된 값을 저장하지 못하게 하는 uq_contact라는 제약조건 걸어줌
);3️⃣ PRIMARY KEY : 기본키를 지정하는 제약조건으로, 해당 필드는 NOT NULL과 UNIQUE 제약조건의 특성을 모두 가짐
// 👍 기본적인 PRIMARY
CREATE TABLE user(
id INT PRIMARY KEY
);
// 👍 CONSTRAINT를 통해 제약조건에 이름부여
CREATE TABLE user(
id INT,
...
CONSTRAINT pk_id PRIMARY KEY id
// id 필드를 기본키로 지정하는 pk_id라는 제약조건 걸어줌
);4️⃣ FOREIGN KEY : 한 테이블을 다른 테이블과 연결하여 외래키를 지정하는 제약조건으로, 해당 테이블은 다른 테이블에 의존됨
CREATE TABLE post(
id INT,
...
CONSTRAINT fk_user FOREIGN KEY (user_id) // 👍 CONSTRAINT fk_user 부분 생략 가능
REFERENCES user (id)
);특정 테이블의 삭제 및 수정을 진행할 때, 연관된 필드가 어떤 동작을 수행할지 지정 가능
(위의 코드에서는 REFERENCES user (id) 뒷부분에 적어주면 됨)
// 참조하는 테이블에 데이터 남아있으면 삭제 불가
ON DELETE RESTRICT
ON UPDATE RESTRICT
// 삭제 및 수정 시 연관되어있는 필드 같이 삭제
ON DELETE CASCADE
ON UPDATE CASCADE
// 삭제 및 수정 시 연관되어있는 필드 null
ON DELETE SET NULL
ON UPDATE SET NULL
// 삭제 및 수정 시 연관되어있는 필드 기본값으로 설정
ON DELETE SET DEFAULT
ON UPDATE SET DEFAULT5️⃣ DEFAULT : 해당 필드의 기본값을 설정할 수 있게 해주는 제약조건
CREATE TABLE user(
name VARCHAR(20) DEFAULT '신짱구'
);⭐️ 관계형 데이터베이스의 정규화
데이터베이스 정규화(Normalization)란, 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 의미
👉 정규화의 목표: 관련이 없는 함수 종속성은 별개의 릴레이션으로 표현하는 것. 이를 통해 무결성(Integrity)을 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있음
👉 정규형: 정규화된 결과를 정규형이라고 하며, 기본 정규형 [제1정규형, 제2정규형, 제3정규형, BCNF(보이스/코드 정규형)] 과 고급 정규형 [제4정규형, 제5정규형]으로 나뉜다.
👍 정규화의 장점: 이상 현상의 발생 가능성을 줄임
👎 정규화의 단점: 연산 시간이 증가함
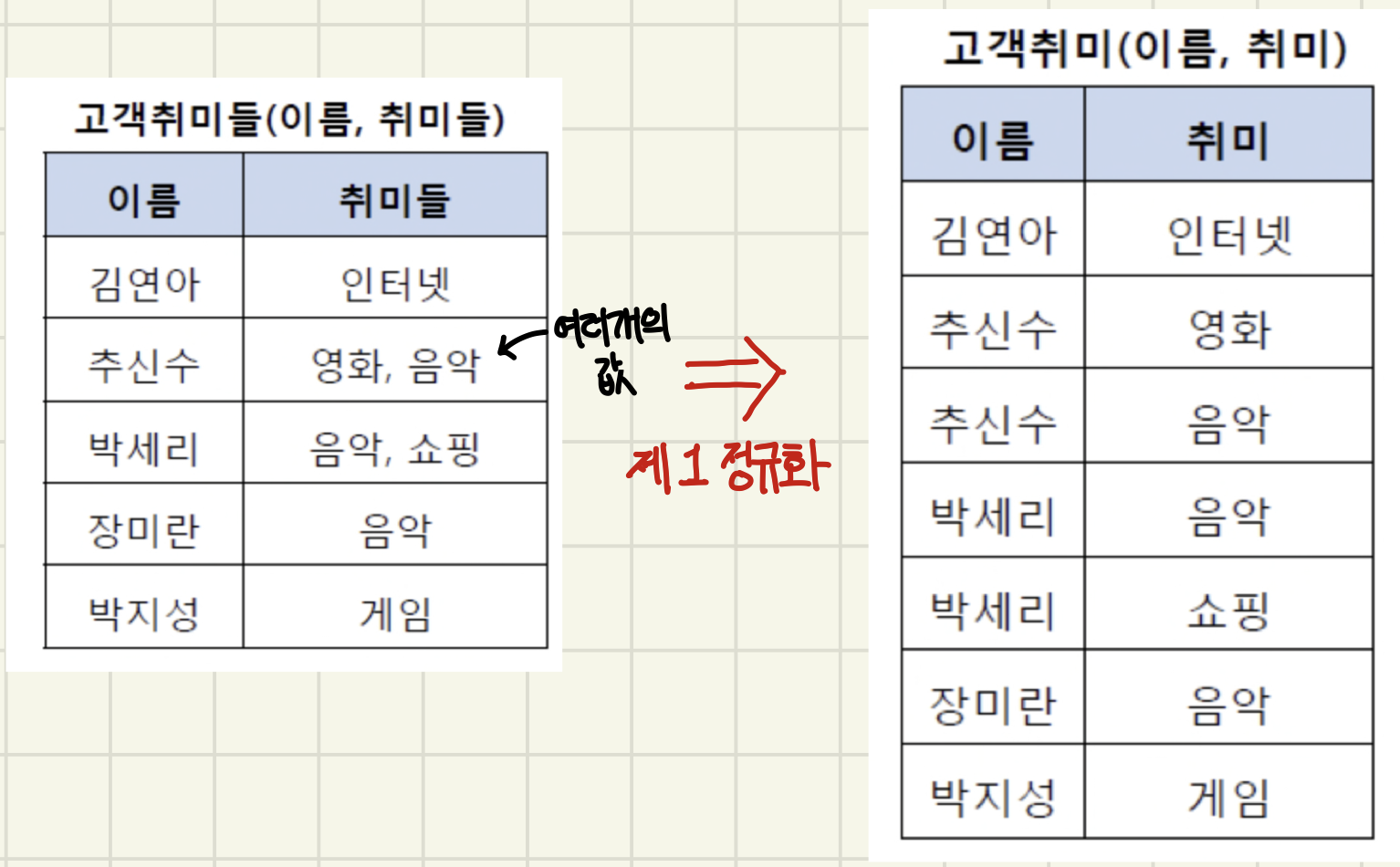
1️⃣ 제 1 정규화
- 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것
2️⃣ 제 2 정규화
- 제 1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것. 완전 함수 종속이란 기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미

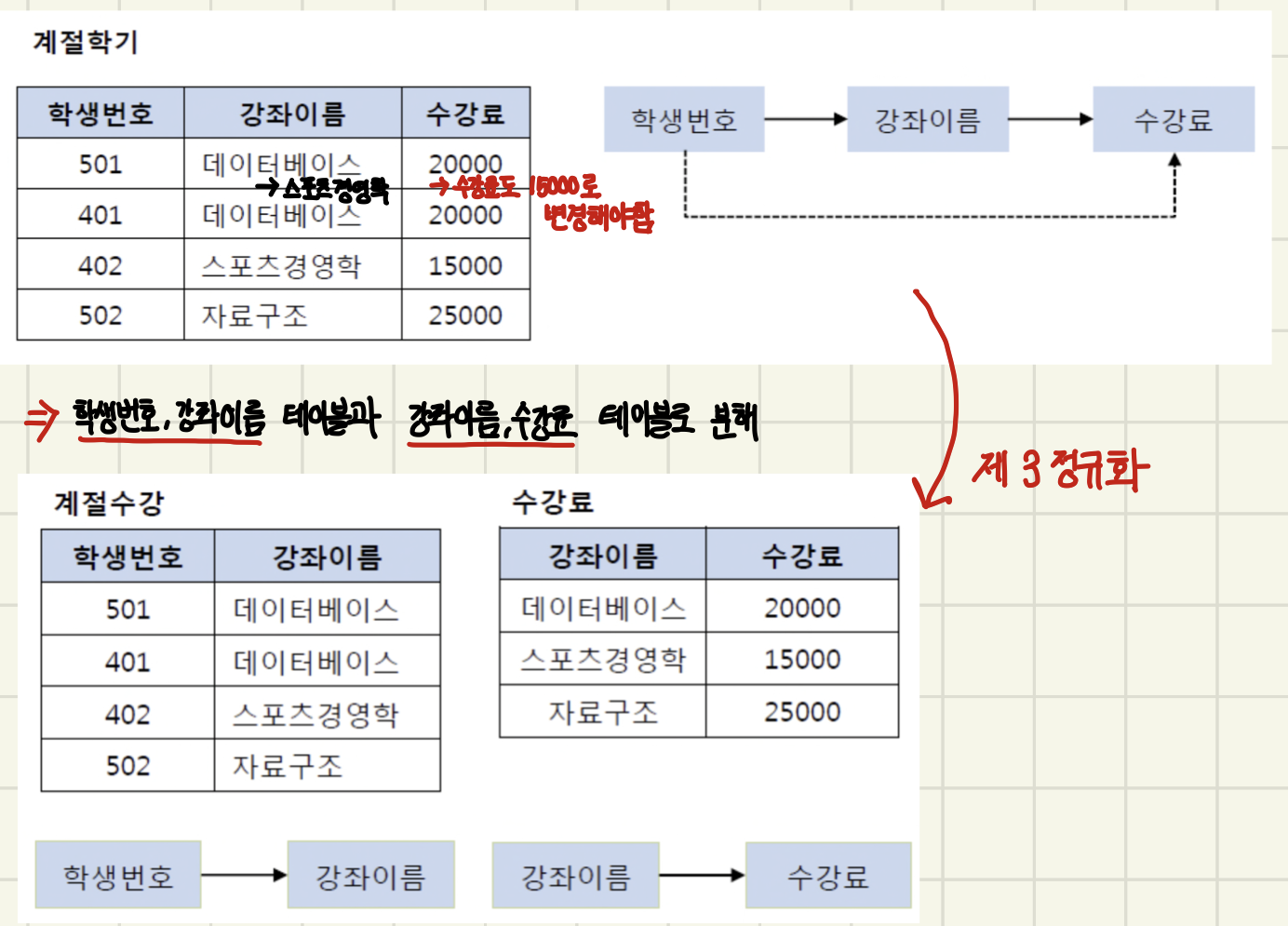
2️⃣ 제 3 정규화
- 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것. 이행적 종속이라는 것은 A -> B, B -> C가 성립할 때 A -> C가 성립되는 것을 의미
⭐️ ORM의 장단점
ORM이란 Object-Related Mapping의 줄임말로, 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑해주는 것을 말함
객체지향프로그래밍은 클래스를 사용하고 관계형 데이터베이스는 테이블을 사용하는데, 두 모델 간에 불일치가 존재함 ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결해줌
👍 ORM의 장점
1️⃣ 객체 지향적인 코드로 인해 더 직관적이고, 비즈니스 로직에 더 집중할 수 있게 도와줌
2️⃣ 재사용성 및 유지보수의 편리성이 증가함
ORM은 독립적으로 작성되어 있으므로 해당 객체들을 재활용할 수 있음. 또한 매핑정보가 명확하여 ERD를 보는 것에 대한 의존도를 낮출 수 있음
3️⃣ DBMS에 대한 종속성이 줄어들음
개발자는 Object에 집중함으로써 극단적으로 DBMS를 교체하는 거대한 작업에도 비교적 적은 리스크와 시간이 소요. 자바에서 가공할 경우 equals, hashCode의 오버라이드 같은 자바의 기능을 이용할 수 있고, 간결하고 빠른 가공이 가능해짐
👍 ORM의 단점
1️⃣ 완벽한 ORM으로만 서비스를 구현하기가 어려움
2️⃣ 프로시저가 많은 시스템에서는 ORM의 객체 지향적인 장점을 활용하기 어려움
프로시저는 데이터베이스에 대한 일련의 작업을 정리한 절차를 RDBMS에 저장한 것으로, 다시 객체로 바꾸는 과정에서 생산성 저하나 리스크가 많이 발생할 수 있음
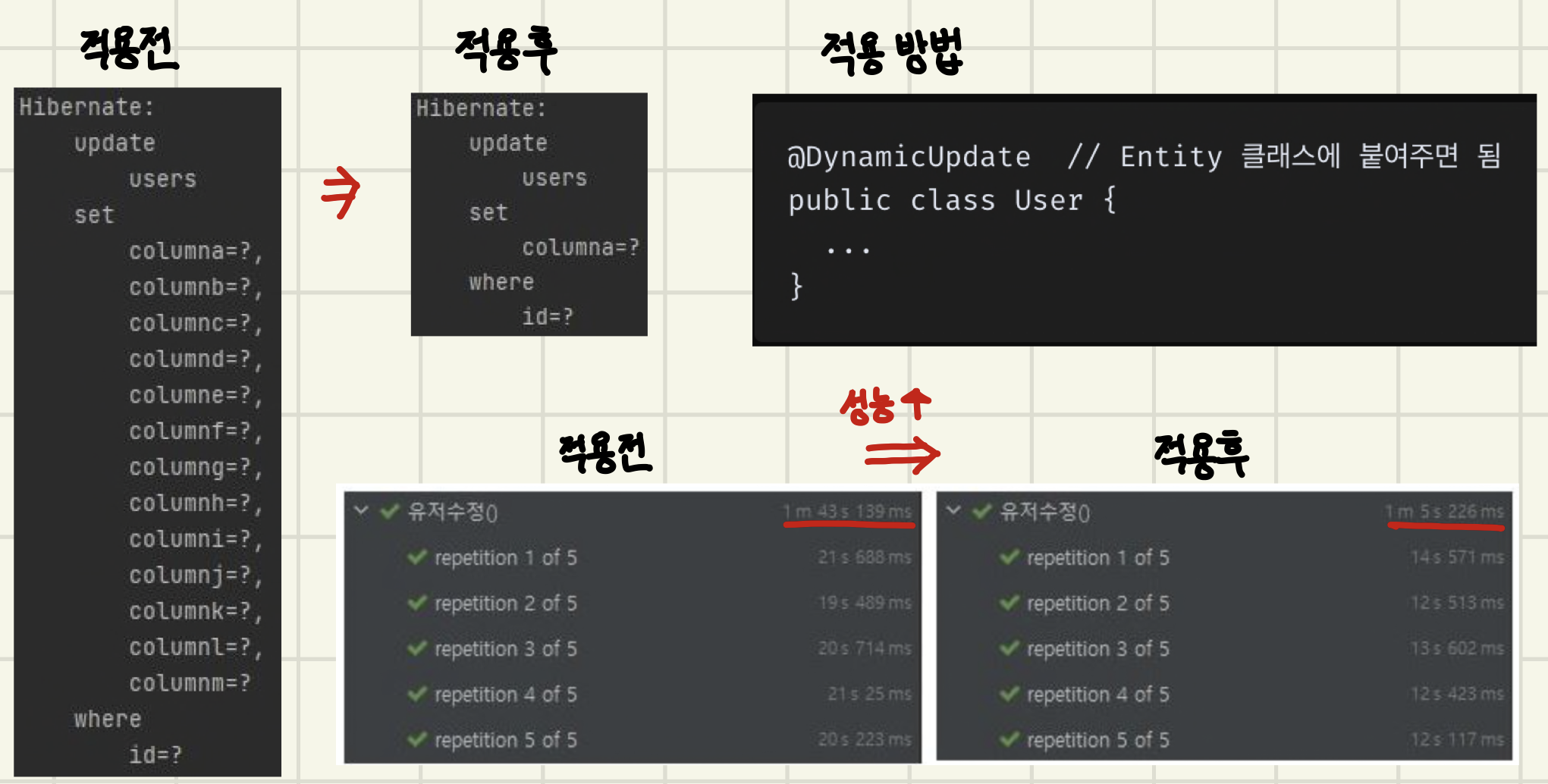
⭐️ @DynamicUpdate
JPA Entity에 사용하는 어노테이션으로, 실제 값이 변경된 컬럼으로만 update 쿼리를 만드는 기능
JPA의 기본 동작은 변경되지 않은 컬럼도 update 쿼리에 포함하기 때문에, 이 어노테이션을 사용하면 변경된 컬럼만 쿼리에 포함시킬 수 있음
단, 성능상의 손해가 존재. 따라서 하나의 테이블에 정말 많은 수의 컬럼이 있고, 몇몇개의 컬럼만 자주 업데이트 하는 경우에 사용해야함
⭐️ 정규표현식
문자열을 패턴으로 찾거나 자르기 위해서 사용. 기존의 복잡하게 구현된 쿼리문을 정규식 함수를 사용하면 간단하게 처리할 수 있음
1️⃣ 기본 메타 문자
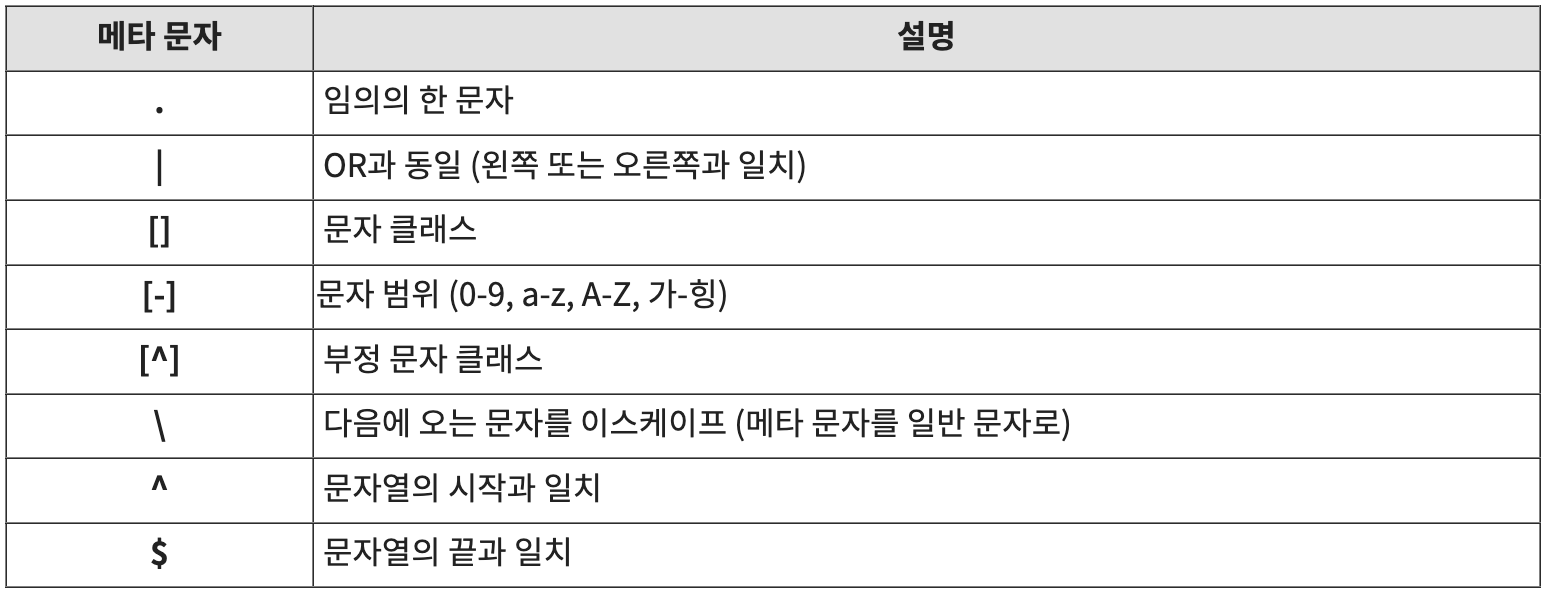
a. 문자열 찾기
대상 문자열에 정확히 일치하는 문자열이 있을 경우 해당 문자열을 반환
SELECT REGEXP_SUBSTR('oracle database', 'oracle') AS regex1
, REGEXP_SUBSTR('oracle database', 'database') AS regex2
, REGEXP_SUBSTR('oracle database', 'sql') AS regex3
FROM dual // dual 테이블은 사용자가 함수(계산)를 실행할 때 임시로 사용하는 테이블
b. 점( . ) : 임의의 한 문자
메타 문자에서 점(.)은 모든 문자를 의미 (숫자, 영문자, 특수문자 등)
점을 세번 사용하면 (...) 임의의 연속된 3개의 문자를 의미
SELECT REGEXP_SUBSTR('oracle database', '.') AS regex1
, REGEXP_SUBSTR('oracle database', '.', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', '.', 1, 3) AS regex3
FROM dual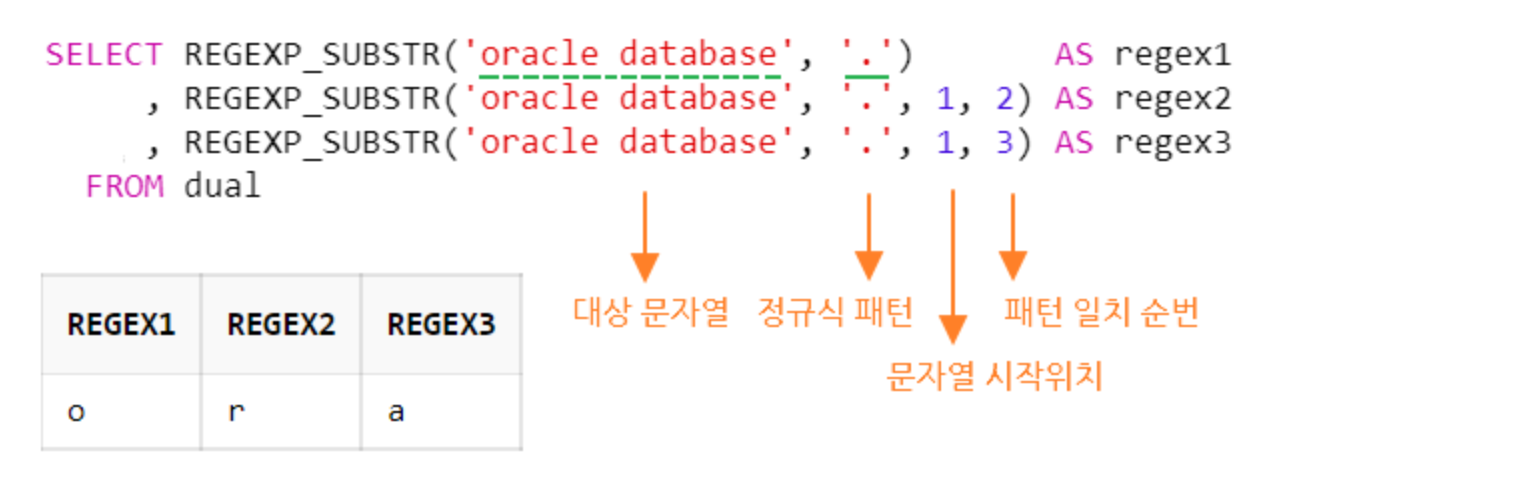
c. 파이프( | ) : OR과 동일
WHERE 절의 OR과 비슷하며, '문자열|문자열|문자열'과 같은 방식으로 사용됨. 파이프로 구분된 문자열 중 하나와 일치하면 해당 문자열이 반환됨
SELECT REGEXP_SUBSTR('oracle database', 'a|b|c') AS regex1
, REGEXP_SUBSTR('oracle database', 'a|b|c', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', 'a|b|c', 1, 3) AS regex3
FROM dual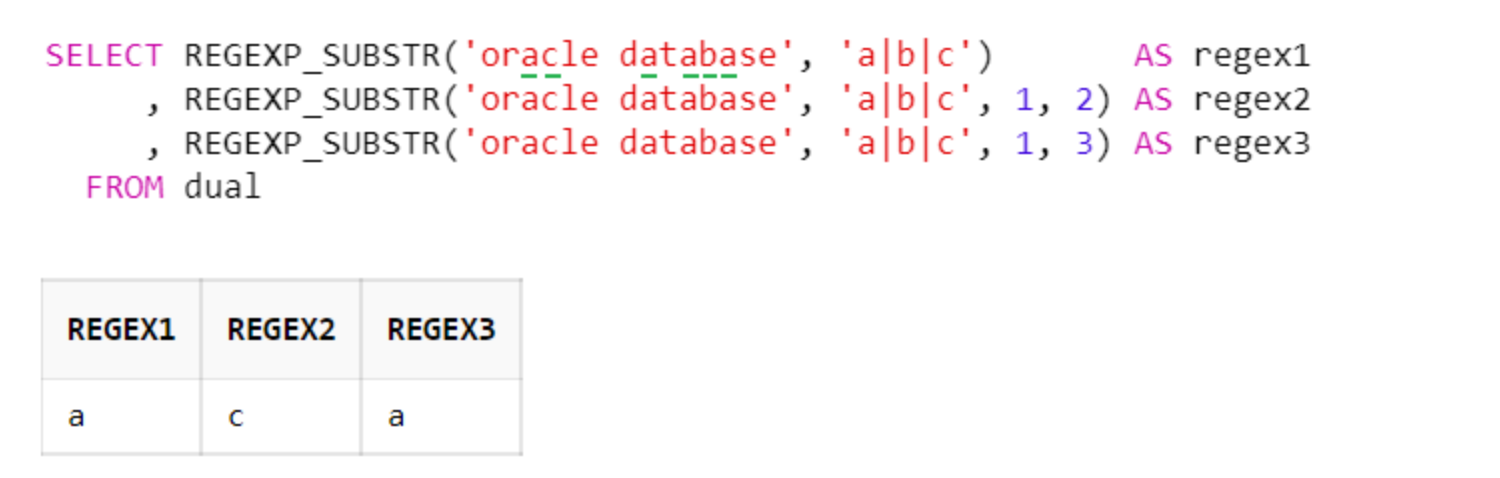
d. 대괄호( [] ): 문자 클래스
문자 클래스 대괄호([]) 안의 문자 하나하나가 OR로 인식된다고 생각하면 됨. 예를들어 '[abc]'는 'a|b|c'와 동일
SELECT REGEXP_SUBSTR('oracle database', '[abc]') AS regex1
, REGEXP_SUBSTR('oracle database', '[abc]', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', '[abc]', 1, 3) AS regex3
FROM dual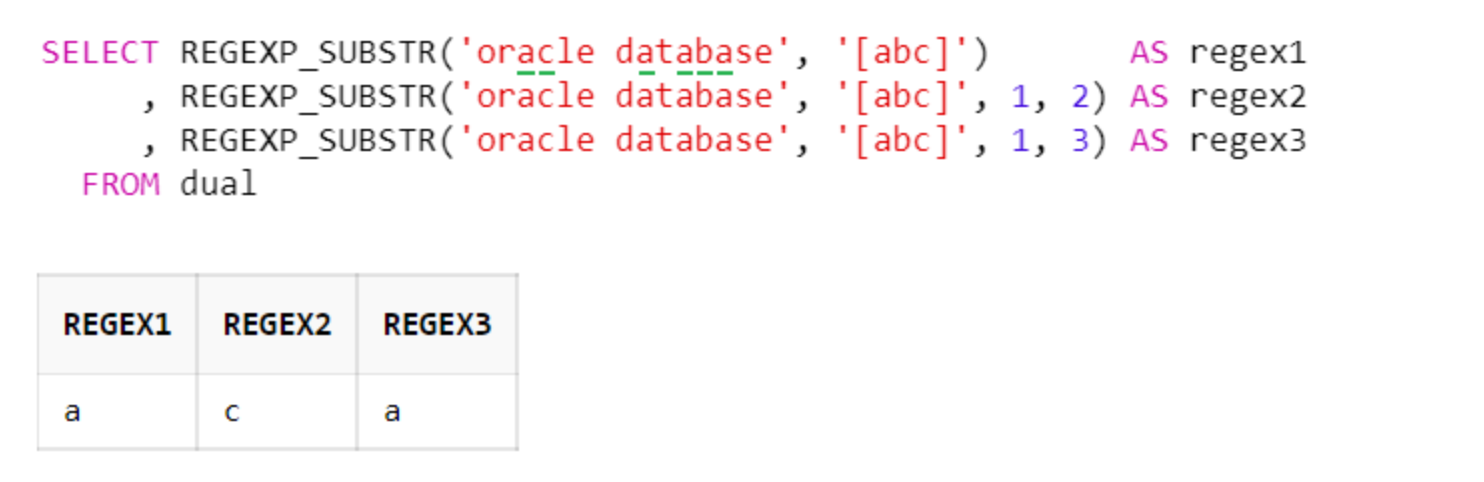
e. 대괄호 + 대시( [-] ) : 문자 범위 (0-9, a-z, A-Z, 가-힝)
문자 클래스에서 대시(-) 기호를 사용하여 연속된 문자의 범위를 지정할 수 있음. 대시 기호를 사용하여 범위를 지정했을 뿐, 대괄호([]) 하나는 위와 같이 하나의 문자를 지칭하게 되는데, 예시로 '[a-c]'는 '[abc]'와 같음
'[a-zA-Z]'나 '[0-9a-zA-Z]'와 같이 문자 범위를 조합해서 사용할 수 있음
SELECT REGEXP_SUBSTR('oracle database', '[a-c]') AS regex1
, REGEXP_SUBSTR('oracle database', '[a-c]', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', '[a-c]', 1, 3) AS regex3
FROM dual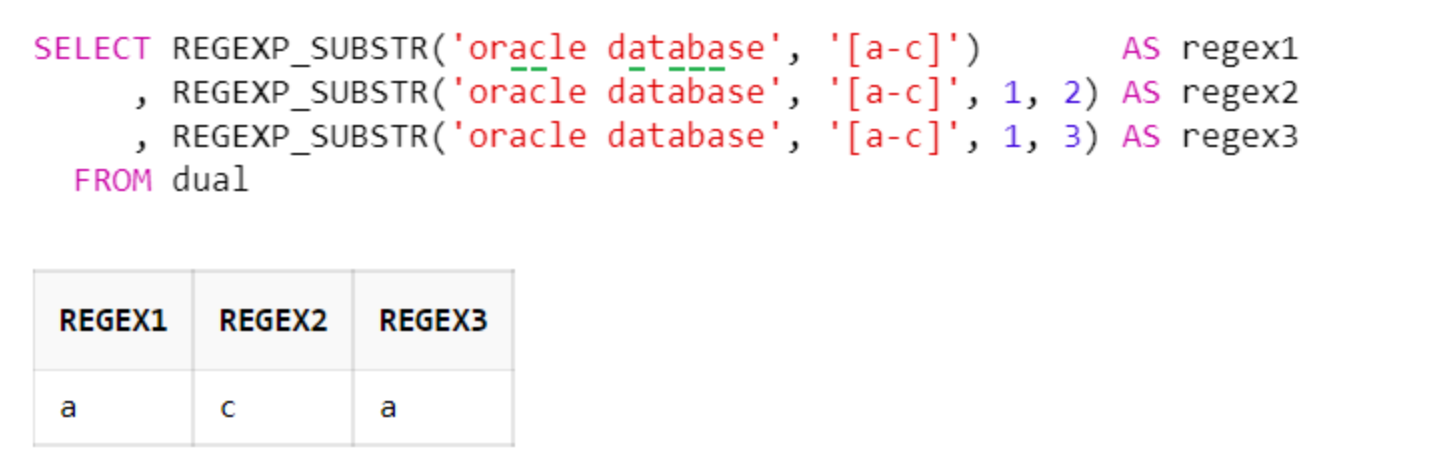
f. 대괄호 + 앵커( [^] ) : 부정 문자 클래스
대괄호([]) 내부의 문자를 제외한 모든 문자를 찾음. 아래의 예시에서는 a, b, c 문자를 제외한 문자가 반환되며, 이때 공백도 하나의 문자에 포함됨
SELECT REGEXP_SUBSTR('oracle database', '[^abc]') AS regex1
, REGEXP_SUBSTR('oracle database', '[^abc]', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', '[^abc]', 1, 3) AS regex3
FROM dual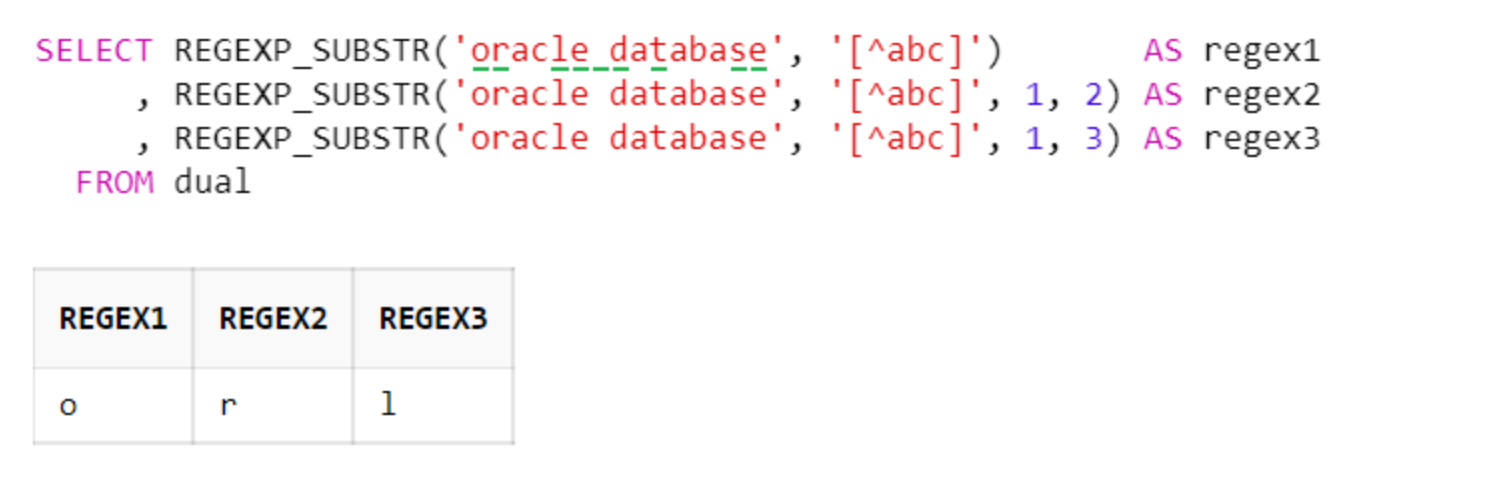
g. 역슬래시( \ ): 메타 문자를 일반 문자로
메타 문자에 해당하는 문자를 검색하기 위해서는 이스케이프(\) 문자를 함께 사용해야 함. 아래의 예시처럼 메타문자인 '[21c]' 문자열이 존재하는지 검색하기 위해서는 대괄호 앞에 역슬래시를 넣어주어야 함
SELECT REGEXP_SUBSTR('oracle database [21c]', '[21c]') AS regex1
, REGEXP_SUBSTR('oracle database [21c]', '\[21c\]') AS regex2
FROM dual
h. 앵커 ( ^ ) : 문자열의 시작과 일치
앵커(^)는 문자열의 시작을 의미. '^oracle'은 문자열의 시작에 'oracle' 문자열이 존재하기 때문에 패턴이 일치하고, '^database'은 문자열의 시작에 'database' 문자열이 존재하지 않기 때문에 반환 값이 없음
SELECT REGEXP_SUBSTR('oracle database', '^oracle') AS regex1
, REGEXP_SUBSTR('oracle database', '^database') AS regex2
FROM dual
i. 달러 ( $ ) : 문자열의 끝과 일치
달러($)는 문자열의 끝을 의미. 찾을 문자열 + 문자열의 끝($)에 해당하는 패턴을 찾음
SELECT REGEXP_SUBSTR('oracle database', 'oracle$') AS regex1
, REGEXP_SUBSTR('oracle database', 'database$') AS regex2
FROM dual
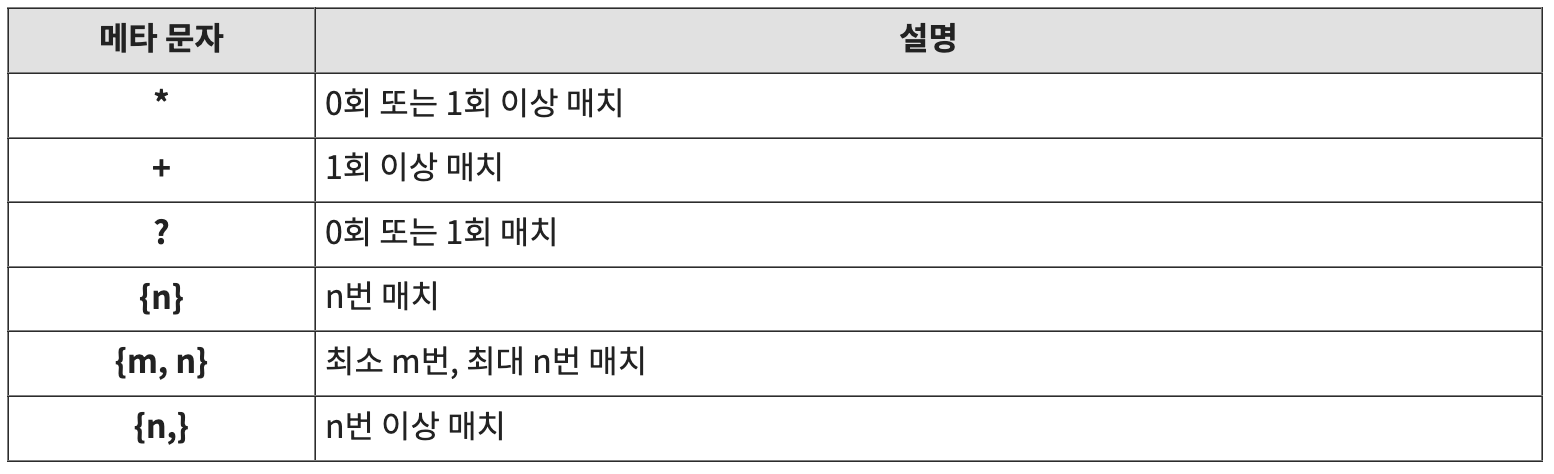
2️⃣ 수량자
문자나 패턴의 반복 횟수를 지정. 아래의 예제는 단순 문자 하나에 수량자를 지정했지만, 문자 클래스(대괄호)나 그룹(괄호)에 많이 사용함
a. 별표 ( * ) : 0회 또는 1회 이상 매치
별표(*) 수량자는 바로 앞의 문자가 없거나 1회 이상 반복할 경우를 의미
아래 예시는 'or + a* + cle'와 일치하는 문자열을 찾음 ('a'가 'or'과 'cle' 문자열 사이에 없거나 1번 이상 반복될 경우)
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora*cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora*cle', 1, 2) AS regex2
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora*cle', 1, 3) AS regex3
FROM dual
b. 플러스 ( + ) : 1회 이상 매치
플러스(+) 수량자는 바로 앞의 문자가 1회 이상 반복할 경우를 의미
아래 예시는 'or + a+ + cle'와 일치하는 문자열을 찾음 ('a'가 'or'과 'cle' 문자열 사이에 1번 이상 반복될 경우)
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora+cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora+cle', 1, 2) AS regex2
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora+cle', 1, 3) AS regex3
FROM dual
c. 물음표 ( ? ) : 0회 또는 1회 매치
물음표(?) 수량자는 바로 앞의 문자가 없거나 1번 있는 경우를 의미
아래 예시는 'or + a? + cle'와 일치하는 문자열을 찾음 ('a'가 'or'과 'cle' 문자열 사이에 없거나 1번 있는 경우)
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora?cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora?cle', 1, 2) AS regex2
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora?cle', 1, 3) AS regex3
FROM dual
d. 중괄호 ( {n} ) : n번 매치
중괄호{n} 수량자는 바로 앞의 문자가 n회 반복할 경우를 의미
아래 예시는 'or + a{2} + cle'와 일치하는 문자열을 찾음 ('a'가 'or'과 'cle' 문자열 사이에 2회 반복될 경우)
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2}cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2}cle', 1, 2) AS regex2
FROM dual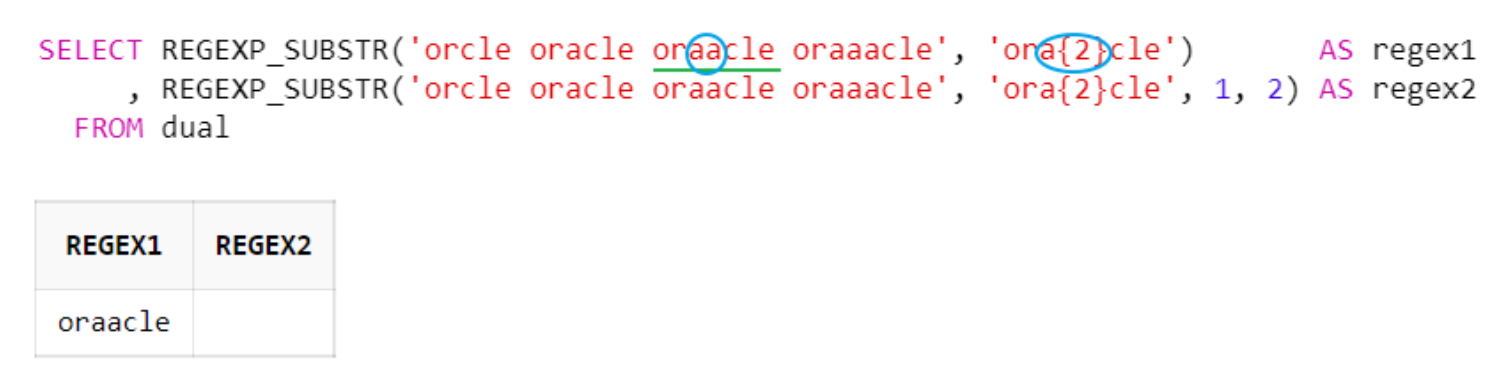
e. 중괄호 ( {m, n} ) : 최소 m번, 최대 n번 매치
중괄호{m, n} 수량자는 바로 앞의 문자가 최소 m회, 최대 n회 반복할 경우를 의미
아래 예시는 'or + a{2,3} + cle'와 일치하는 문자열을 찾음 ('a'가 'or'과 'cle' 문자열 사이에 최소 2회, 최대 3회 반복될 경우)
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2,3}cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2,3}cle', 1, 2) AS regex2
FROM dual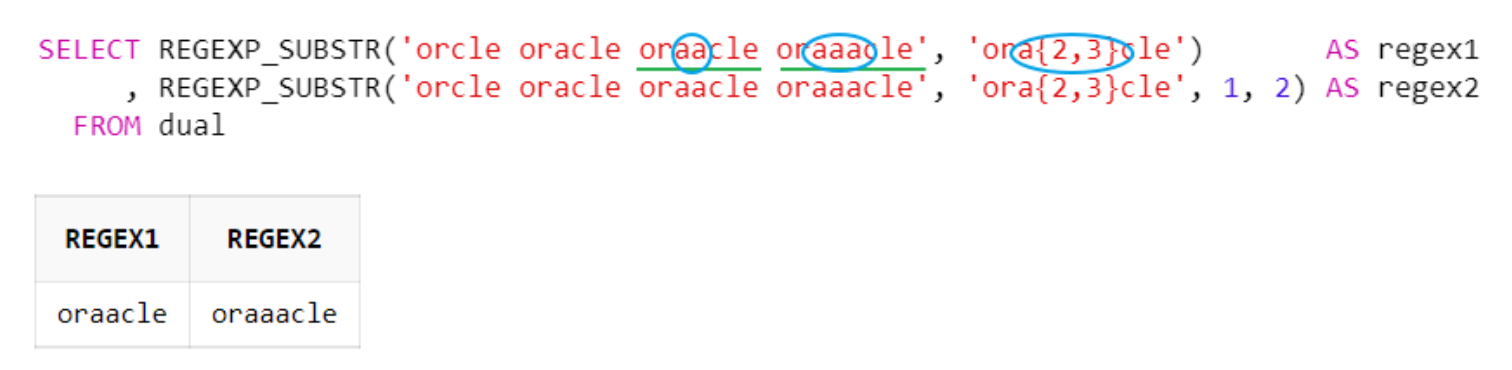
f. 중괄호 ( {n,} ) : n번 이상 매치
중괄호{n,} 수량자는 바로 앞의 문자가 n회 이상 반복할 경우를 의미
위의 예시는 'or + a{2,} + cle'와 일치하는 문자열을 찾음 ('a'가 'or'과 'cle' 문자열 사이에 2회 이상 반복될 경우)
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2,}cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2,}cle', 1, 2) AS regex2
FROM dual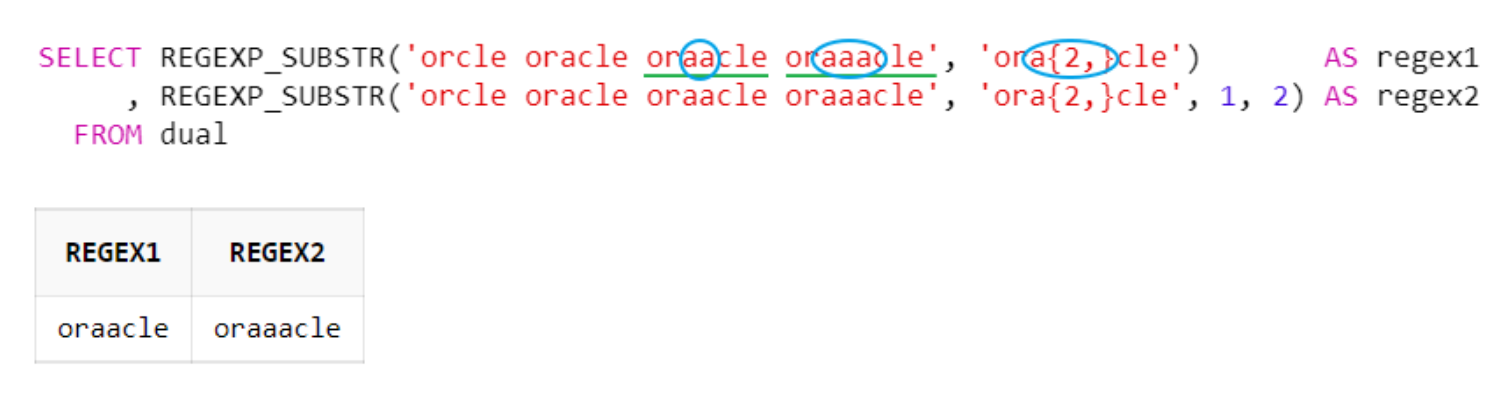
3️⃣ 그룹과 역참조
패턴 그룹과 역참조는 패턴이 조합된 상태에서 사용하는 메타 문자 이므로 조금 복잡해 보일 수 있음. 아래의 예제를 조금씩 변형해 연습해 보면서 이해하기

a. 패턴 그룹
문자열이나 패턴을 괄호로 묶으면 하나의 단위가 됨. 아래 예제는 2개의 패턴 그룹을 파이프(|) 메타 문자로 연결했으므로 2개의 패턴 중 일치하는 패턴이 있으면 찾음
SELECT REGEXP_SUBSTR('abc abbc abbbc', '(ab{2}c)|(ab{3}c)') AS regex1
, REGEXP_SUBSTR('abc abbc abbbc', '(ab{2}c)|(ab{3}c)', 1, 2) AS regex2
FROM dual
b. 역참조
역참조(\순번)는 앞의 패턴 그룹(괄호)의 값을 복사해서 사용할 수 있음. 'a' 다음에 오는 임의의 한 문자(.)는 'b'이며 \1로 한번 복사하면 'bb'이고 \1\1로 두 번 복사하면 abbb임
SELECT REGEXP_SUBSTR('abc abbc abbbc', 'a(.)\1c') AS regex1
, REGEXP_SUBSTR('abc abbc abbbc', 'a(.)\1\1c') AS regex2
FROM dual
4️⃣ 정규식 함수
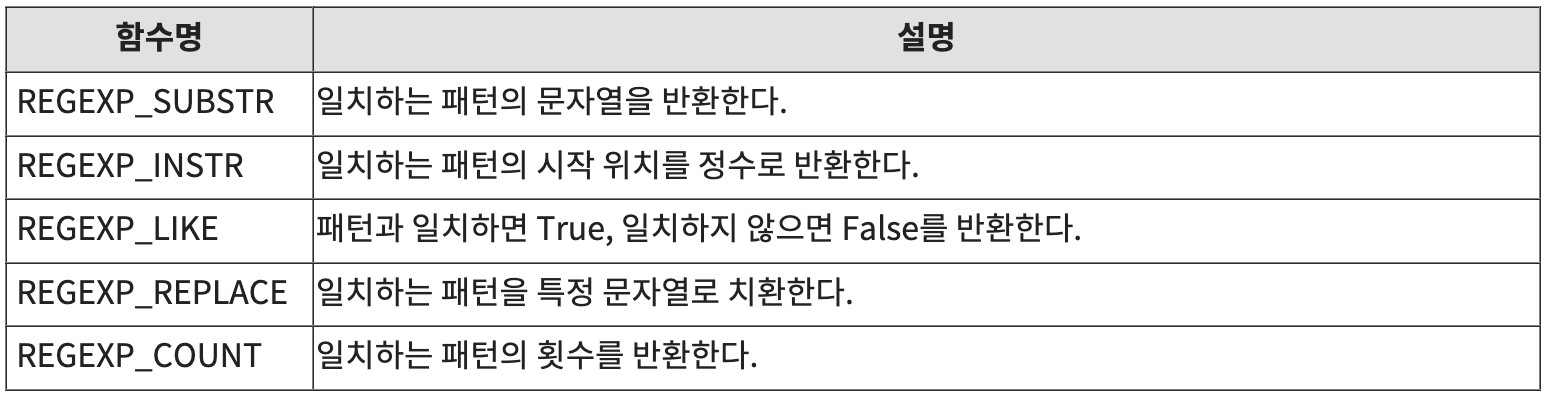
5️⃣ 세미나 예제 정규표현식 해석
egexp="(?=.*[0-9])(?=.*[a-zA-Z])(?=.*\\W)(?=\\S+$).{8,20}",
message = "비밀번호는 영문 대,소문자와 숫자, 특수기호가
적어도 1개 이상씩 포함된 8자 ~ 20자의 비밀번호여야 합니다."(?=.*[0-9]) : 숫자가 1개 이상 들어가야 한다.
(?=.*[a-zA-Z]) : 알파벳(대소문자)이 1개 이상 들어가야 한다.
(?=.*\W) : 특수문자가 1개 이상 들어가야 한다.
(?=\S+$) : 공백 없이 문자열 전체가 일치해야 한다.
.{8,20} : 최소 8자에서 최대 20자까지의 문자열이어야 한다.
👉 ( ?= ) 은 전방탐색을 의미하며, 전방 탐색(lookahead)이란 작성한 패턴에 일치하는 영역이 존재하여도 그 값을 반환하지 않는 패턴
👉 ( .* ) 은 1개 이상 있으면 된다는 의미로 , 위의 예시에서 숫자나 알파벳이 1개 이상 있으면 조건을 만족함
👉 ( \W ) 은 특수문자를 의미
👉 ( \S ) 은 공백 문자가 아닌 문자를 의미
👉 ( .{8,20} ) 에서 ( . ) 은 앞의 전방탐색 구문에서 조건을 만족하는 문자열 중에서 라는 의미
⭐️ 프록시 (Proxy)
1️⃣ 즉시로딩과 지연로딩
👉 즉시로딩 (Eager): 데이터를 조회할 떄, 연관된 모든 객체의 데이터까지 한번에 물러오는 것
👉 지연로딩 (Lazy): 필요한 시점에 연관된 객체의 데이터를 불러오는 것
즉시로딩과 같이, 어떤 엔티티를 조회하는데 그 엔티티와 관련된 모든 엔티티들이 함께 조회된다면 성능상의 문제가 발생할 것임
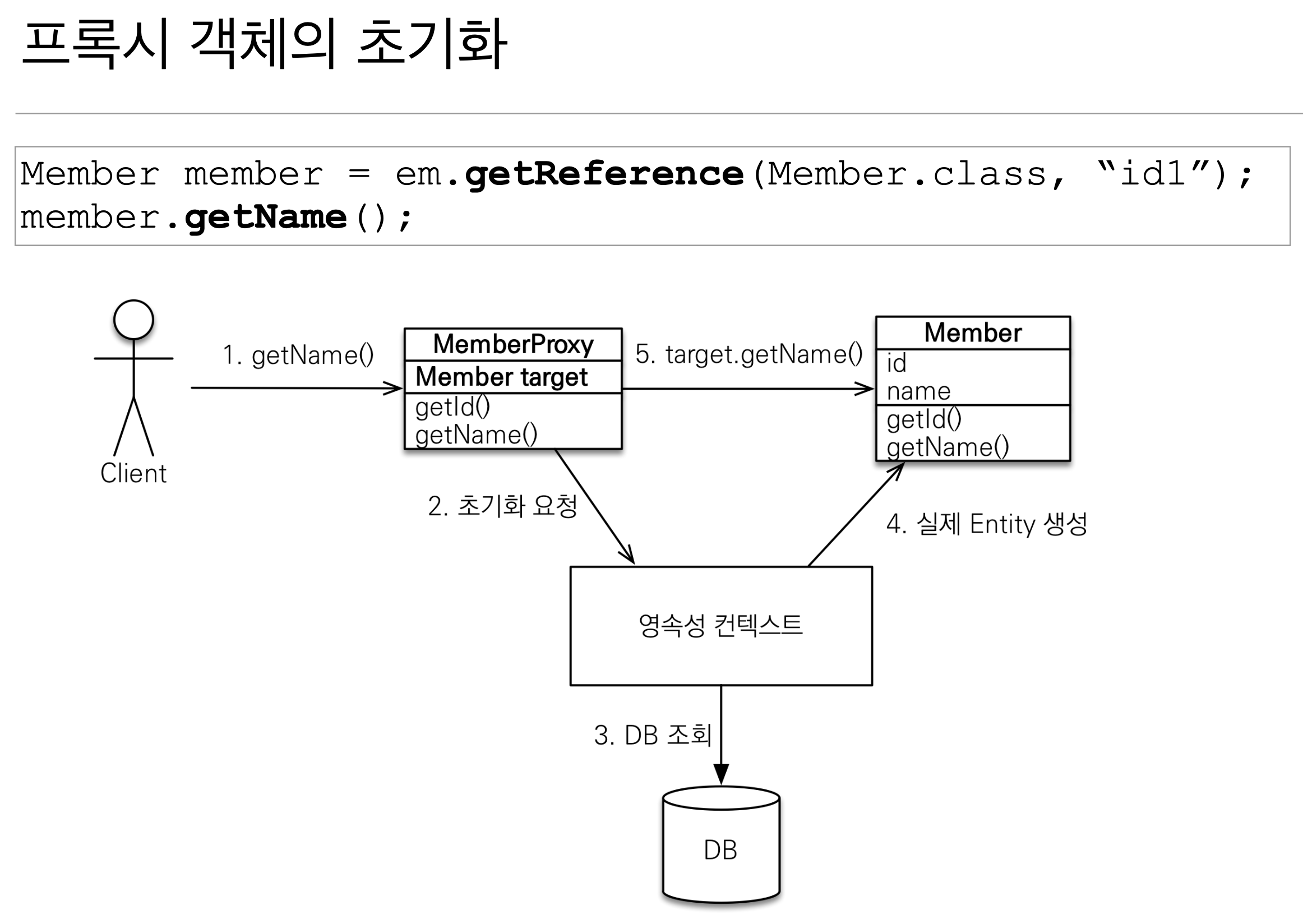
2️⃣ 프록시 (Proxy)
지연로딩을 위해서는 프록시라는 객체가 필요한데, 프록시는 실제 엔티티 객체 대신에 사용되는 객체로서 데이터베이스 조회를 미루기 위해 사용됨
👉 프록시 객체는 실제 엔티티 클래스를 상속 받아서 만들어지므로 실제 엔티티와 겉모습이 같음
👉 사용하는 입장에서는 진짜 객체인지 프록시 객체인지 구분하지 않고 사용하면 됨 (이론상)
👉 프록시 객체는 실제 객체의 참조(target)를 보관하며, 프록시 객체를 호출하면 프록시 객체는 실제 객체의 메소드 호출
em.find() // 데이터베이스를 통해서 실제 엔티티 객체 조회
em.getReference() // 데이터베이스 조회를 미루는 가짜(프록시) 엔티티 객체 조회