
💭 단일 서버
-
모든 컴포넌트가 단 한 대의 서버에서 실행되는 간단한 시스템
- 웹, 앱, 데이터베이스, 캐시 등이 전부 서버 1대에서 실행
- 웹, 앱, 데이터베이스, 캐시 등이 전부 서버 1대에서 실행
-
시스템 구성 이해
-
사용자 요청이 처리되는 과정과 요청을 만드는 단말에 대한 이해
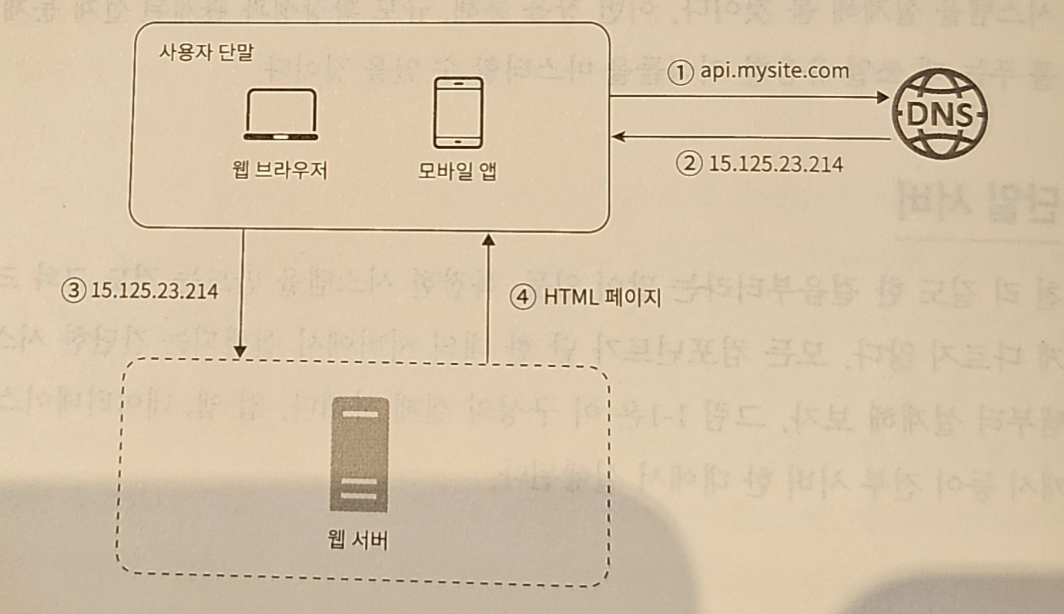
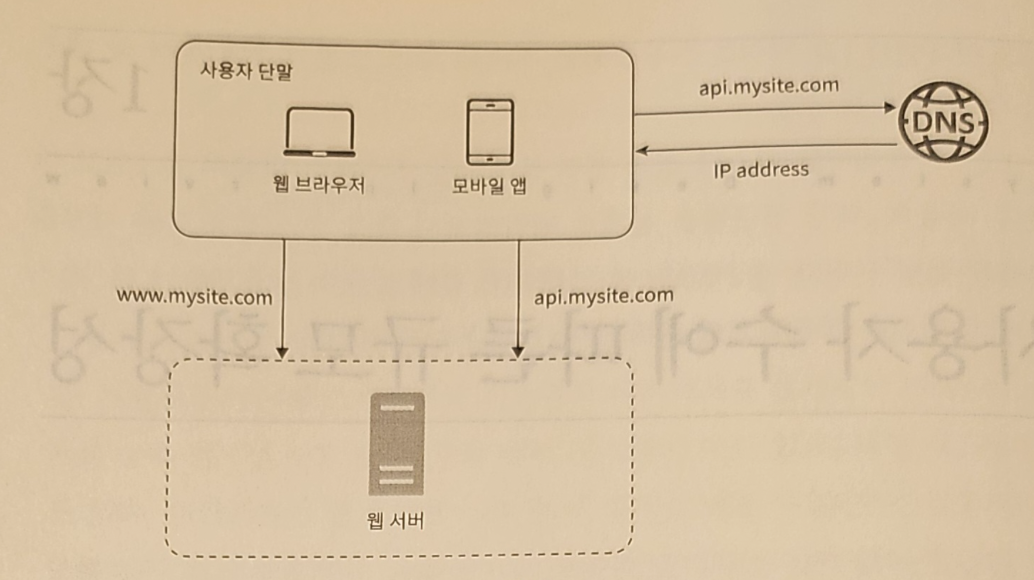
- 사용자 : 도메인 이름(api.mysite.com)을 이용해 웹사이트에 접속
- 접속하기 위해 도메인 이름 → DNS(Domain Name Service, 보통 Thired party(제 3 사업자)가 제공하는 유료 서비스 이용)로 질의 → IP 주소로 변환
- DNS 조회 결과로 IP 주소 반환됨.
- 그림에서 15.125.23.214
- 해당 IP 주소로 HTTP 요청 전달됨.
- 요청 받은 웹 서버 : HTML 페이지 or JSON 형태 응답 반환
- 사용자 : 도메인 이름(api.mysite.com)을 이용해 웹사이트에 접속
-
-
예시에서의 요청의 종류 2가지
- 웹 애플리케이션
- 비즈니스 로직, 저장 등 처리 → 서버 구현용 언어(자바, 파이썬 등)를 사용
- 프레젠테이션용 → 클라이언트 구현용 언어(HTML, 자바스크립트 등)를 사용
- 모바일 앱
- 모바일 앱과 웹 서버 간 통신 ↔ HTTP 프로토콜 ↔ JSON(JavaScript Object Natation):HTTP 프로토콜을 통해 반환될 응답 데이터 포맷 ex) GET /users/12-id가 12인 사용자 데이터 접근
{ "id": 12, "firstName": "John", "lastName": "Smith", "address": { "streetAddress": "21 2nd Street", "city": "New Tork", "state": "NY", "postalCode": 10021 }, "phoneNumbers": [ "212 555-1234", "646 555-4567" ] }
- 모바일 앱과 웹 서버 간 통신 ↔ HTTP 프로토콜 ↔ JSON(JavaScript Object Natation):HTTP 프로토콜을 통해 반환될 응답 데이터 포맷 ex) GET /users/12-id가 12인 사용자 데이터 접근
- 웹 애플리케이션
💡 질문1: 웹 브라우저와 모바일 앱의 경우 도메인 주소가 다른 이유?(웹 브라우저 : www / 모바일 앱 : api)
- 웹 브라우저의 경우, 보통의 전통적인 도메인으로 바로 접속하기 때문에 www.mysite.com을 통해 접속하는 것으로 보임. 또한, 엔드포인트를 URL 상으로 보여주지 않는 경우가 많아 보안적으로 일반적인 www.mysite.com을 사용하는 것으로 보임.
- 모바일 앱의 경우, api로 구성된 서버의 경우 웹 기반으로 구성된 경우가 많고, 모바일 앱 내에서 웹 기반 api의 엔드포인트별로 접속해야하기 때문에 api.mysite.com과 같은 도메인을 가지는 것으로 판단
- 사용자가 모바일 기기에서 앱을 실행하면, 앱은 미리 정의된 API 서버의 주소로 접속을 시도. 이 때,
api와 같은 API 서비스용 서브도메인이 사용됨.- 결론적으로, 웹 브라우저는 주로 정적인 파일을 로드하여 사용자에게 웹 페이지를 보여주는 반면, 모바일 앱은 API를 통해 서버와 동적으로 데이터를 교환하여 사용자 인터페이스를 업데이트
💭 데이터베이스
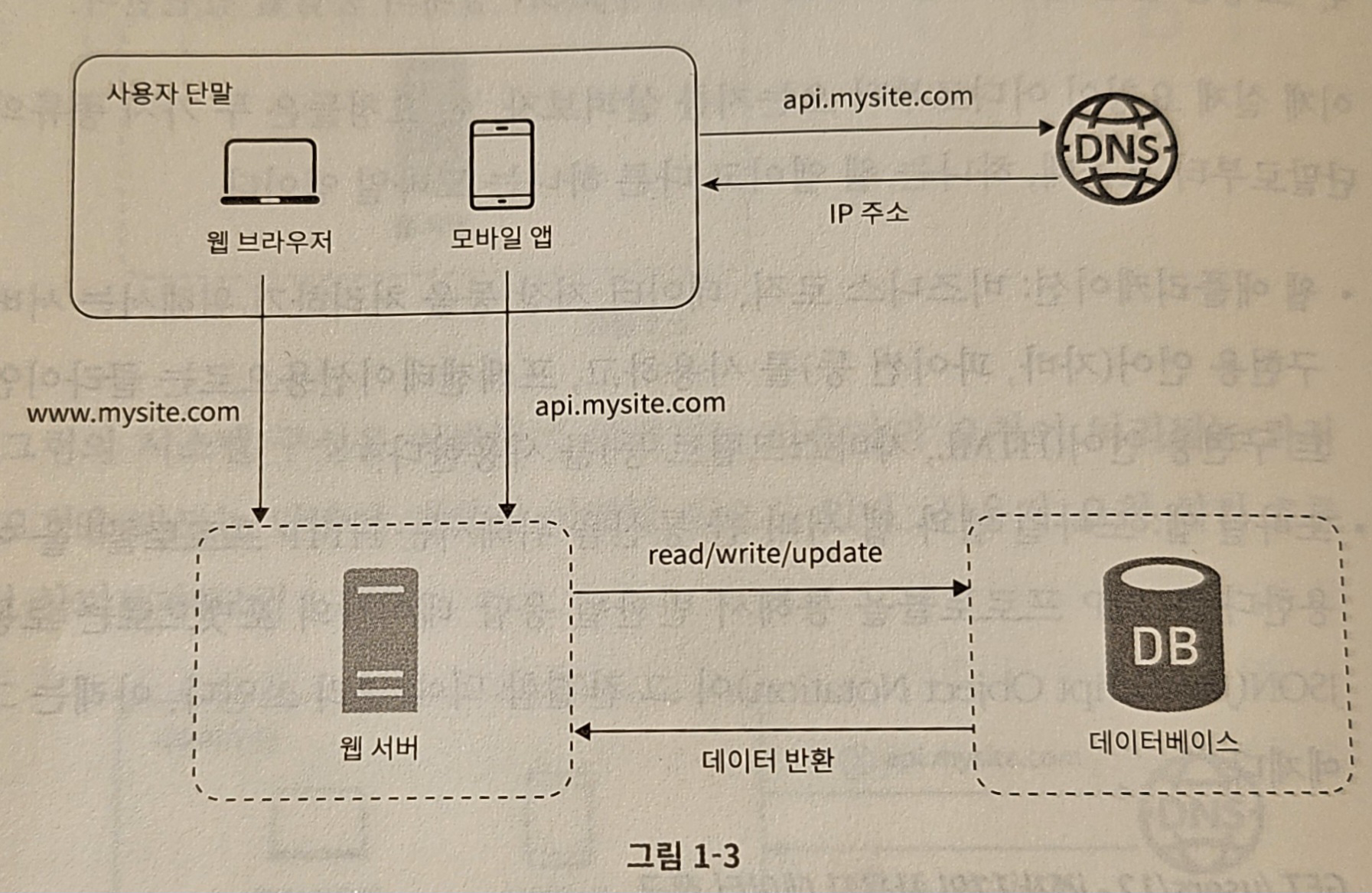
- 여러 개의 서버를 두기 위한 용도 분류
- 웹/모바일 트래픽 처리용
- 데이터베이스용
- 웹/모바일 트래픽 처리 서버(웹 계층)와 데이터베이스 서버(데이터 계층)를 분리 → 독립적 확장 가능
- 데이터베이스 사용을 하기 위한 비교
- 전통적인 관계형 데이터베이스(relational database) VS 비-관계형 데이터베이스
- 관계형 데이터베이스
-
관계형 데이터베이스 관리 시스템(Relational Database Management System, DBMS)라고도 부름
ex) MySQL, 오라클 데이터베이스, PostgreSQL 등
-
자료를 테이블과 열, 칼럼으로 표현
-
SQL 사용 시 여러 테이블에 있는 데이터를 그 관계에 따라 Join해 합치기 가능
-
- 비-관계형 데이터베이스
-
NoSQL이라고도 부름
ex) CouchDB, Neo4j, HBase, Amazon DynamoDB 등
-
NoSQL의 4가지 분류
- 키-값 저장소(key-value store)
- 그래프 저장소(graph store)
- 칼럼 저장소(column store)
- 문서 저장소(document store)
-
일반적으로 Join 연산 지원 X
-
- 관계형 데이터베이스
- 전통적인 관계형 데이터베이스(relational database) VS 비-관계형 데이터베이스
- 비 관계형 데이터베이스가 더 유리한 경우
- 아주 낮은 응답 지연시간(latency)이 요구됨
- 다루는 데이터가 비정형(unstructured) (=관계형 데이터가 X)
- 데이터(JSON, YAML, YML 등)를 직렬화(Serialize) or 역직렬화(deserialize)할 수 있기만 하면 됨
- ⭐️아주 많은 양의 데이터를 저장할 필요가 있음⭐️: 주로 이 이유로 사용
💭 수직적 규모 확장 vs 수평적 규모 확장
-
Scale Up
- 수직적 규모 확장에 해당
- 서버에 고사양 자원(더 좋은 CPU, 더 많은 RAM 등)을 추가하는 행위
- 장점
- 서버로 유입되는 트래픽의 양이 적을 경우
- 단순함
- 단점
- 한계가 있음. 한 대의 서버에 CPU나 메모리르 무한대로 증설할 방법 X
- 장애에 대한 자동복구(failover) 방안이나 다중화(redundancy) 방안 제시 X. 서버에 장애가 발생하면 웹사이트/앱은 완전히 중단
-
Scale Out
- 수평적 규모 확장에 해당
- 더 많은 서버를 추가해 성능을 개선하는 행위
-
대규모 애플리케이션 지원에는 수평적 규모 확장법이 적합
-
앞선 설계의 문제점
- 사용자는 웹 서버에 바로 연결 → 웹 서버 다운 시 사용자는 웹 사이트 접속 불가
- 너무 많은 사용자가 접속해 웹 서버가 한계 상황에 도달하게 되면 응답 속도가 느려지거나 서버 접속 불가능해질 수 있음.
-
로드밸런서
- 이 문제점을 해결하는 것이 바로 부하 분산기 또는 로드밸런서 도입
- 부하 분산 집합(load balancig set)에 속9한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할
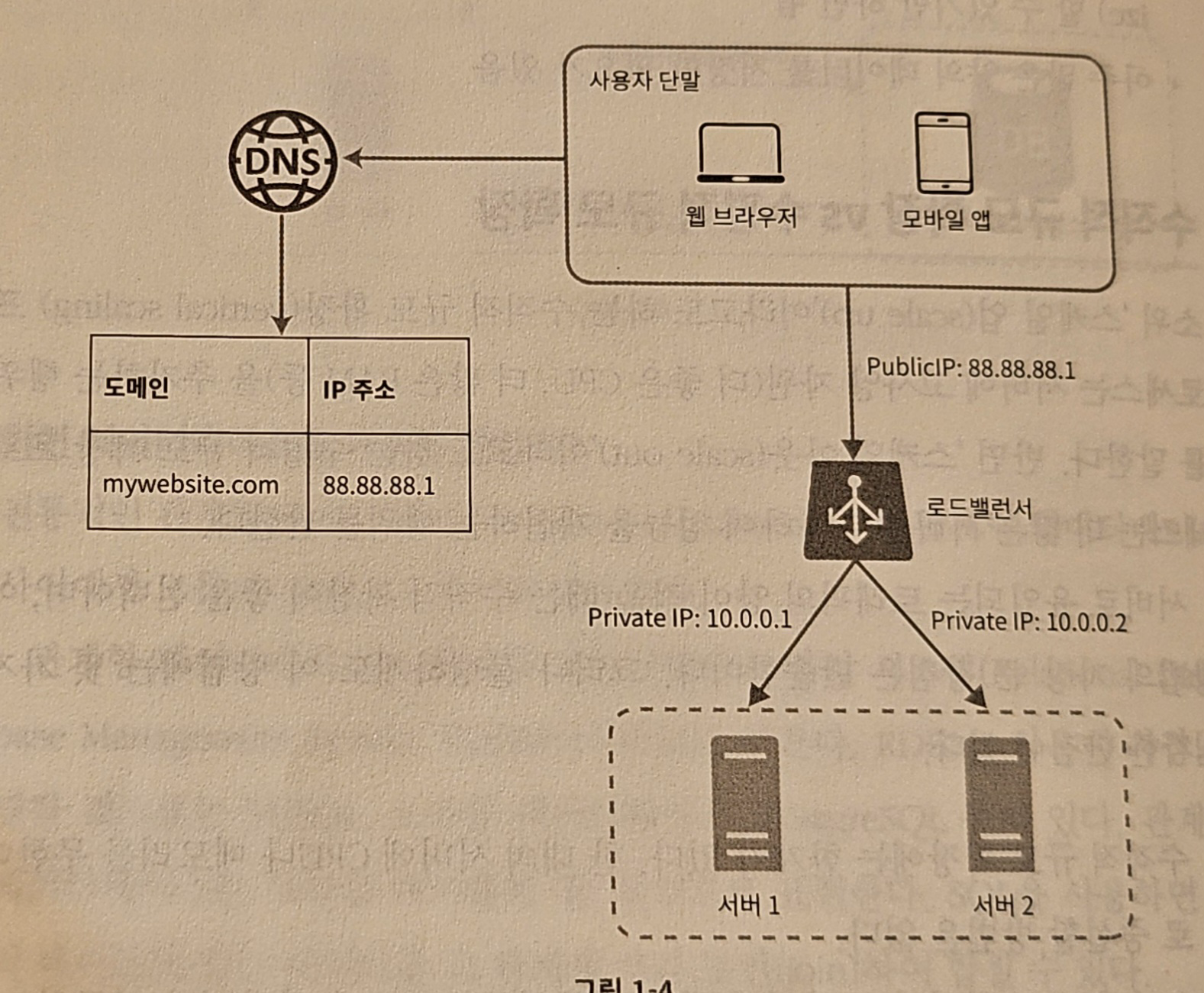
- 사용자는 로드밸런서의 공개 IP 주소(public IP address)로 접속 → 웹 서버는 클라이언트의 접속을 직접 처리하지 X
- 서버 간 통신 → 사설 IP 주소(private IP address) 이용 ⇒ 로드밸런서가 사설 IP 주소 이용!
- 사설 IP 주소: 같은 네트워크에 속한 서버 사이의 통신에만 쓰임.
- 인터넷을 통해 접속 X
- 부하 분산 집합에 또 하나의 웹 서버를 추가 → 장애를 자동 복구하지 못하는 문제(no failover) 해결, 웹 계층 가용성(availability) 향상
- 서버 1 다운(offline) → 모든 트래픽은 서버 2로 전송 → 따라서 웹사이트 전체가 다운되는 일 방지
- 웹 사이트로 유입되는 트래픽의 가파른 증가 → 2대의 서버로 트래픽을 감당할 수 없는 시점이 옴 → 로드밸런서가 있으므로 우아한 대처 가능
- 웹 서버 계층에 더 많은 서버 추가로 해결 → 로드밸런스가 자동 트래픽 분산 수행
-
웹 계층은 괜찮지만, 여전히 데이터베이스 계층은?⬆️
- 현재 설계: 1개의 데이터베이스 서버뿐, 장애의 자동복구나 다중화를 지원하는 구성 X → 데이터베이스 다중화로 해결(보편적 해결법)
-
데이터베이스 다중화
- “많은 데이터베이스 관리 시스템이 다중화를 지원한다. 보통은 서버 사이에 주(master)-부(slave) 관계를 설정하고 데이터 원본은 주 서버에, 사본은 부 서버에 저장하는 방식이다”_위키피디아
- 쓰기 연산(write operation): 마스터만 지원
- 부 데이터베이스: 주 데이터베이스로부터 그 사본 전달받음 + 읽기 연산(read operation)만을 지원
- 데이터베이스 변경 명령어(insert, delete, update) 등 → 주 데이터베이스로만 전달되어야 함.
- 대부분의 애플리케이션: 읽기 연산 비중 > 쓰기 연산 비중 → 통상 부 데이터베이스의 수가 주 데이터베이스 수보다 ⬆️
-
데이터베이스 다중화의 이점
- 더 나은 성능
- 주-부 다중화 모델에서 모든 데이터 변경 연산 → 주 데이터베이스 서버로만 전달
- 읽기 연산 → 부 데이터베이스 서버들로 분산
- 병렬로 처리되는 query 수가 늘어남 → 성능이 좋아짐
- 안정성(reliability)
- 자연 재해 등으로 데이터베이스의 서버 가운데 일부가 파괴 → 데이터는 보존
- 데이터를 지역적으로 떨어진 여러 장소에 다중화시킬 수 있기 때문
- 가용성(availability)
- 데이터를 여러 지역에 복제 → 하나의 데이터베이스 서버에 장애가 발생하더라도 다른 서버에 있는 데이터를 가져와 계속 서비스
- 더 나은 성능
-
데이터베이스 서버 가운데 하나가 다운되면?
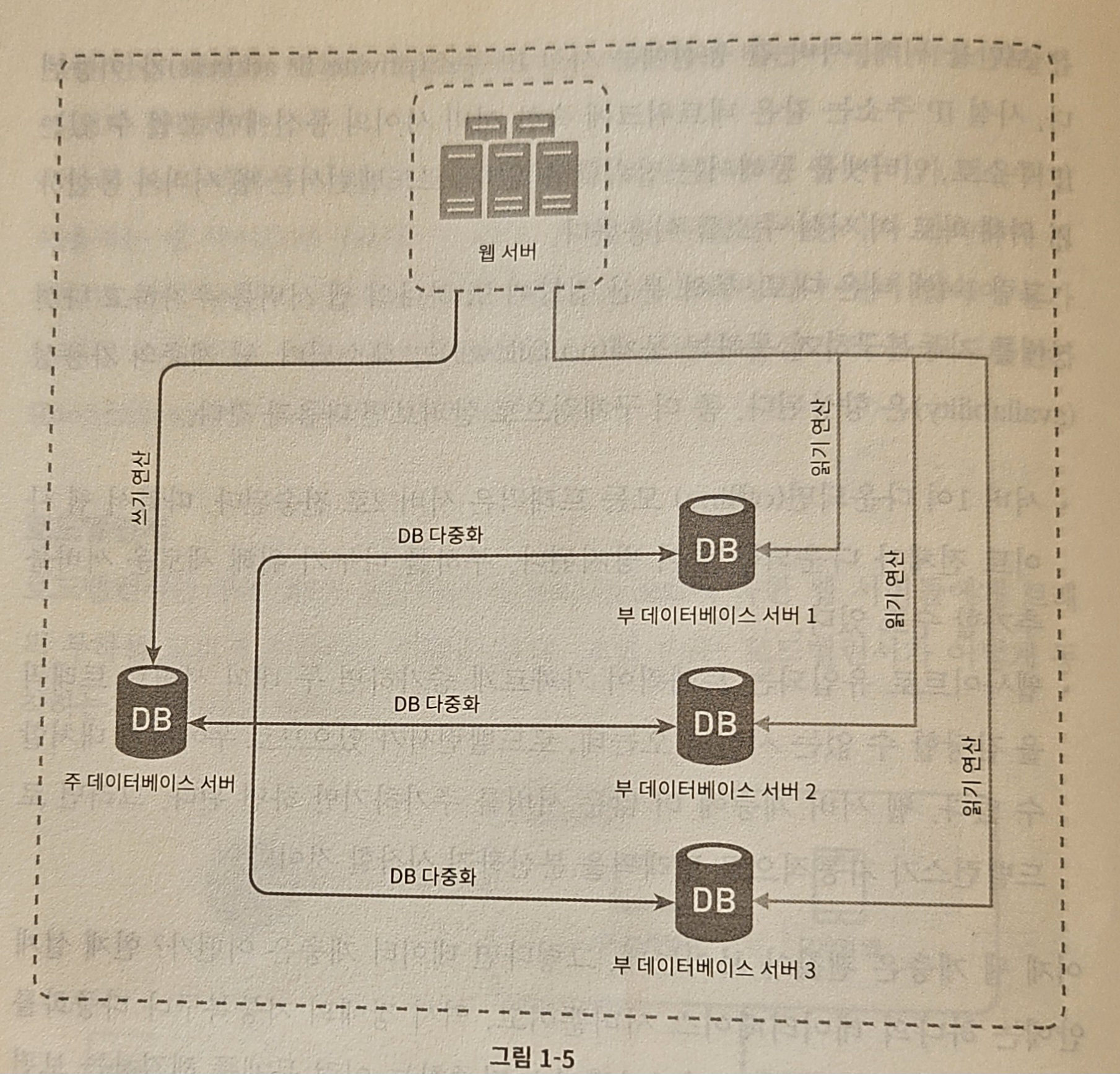
- 부 서버가 한 대 뿐인데 다운된 경우
- 읽기 연산은 한시적으로 모두 주 데이터베이스로 전달
- 즉시 새로운 부 데이터베이스 서버가 장애 서버를 대체
- 부 서버가 여러 대인 경우
- 읽기 연산 → 나머지 부 데이터베이스 서버들로 분산
- 새로운 부 데이터베이스 서버가 장애 서버를 대체
- 주 데이터베이스 서버 다운
- 한 대의 부 데이터베이스만 있는 경우
- 해당 부 데이터베이스 서버가 새로운 주서버
- 모든 데이터베이스 연산은 일시적으로 새로운 주 서버에서 수행
- 새로운 서버 추가
- 프로덕션(production) 환경에서 벌어지는 일
- 부 서버에 보관된 데이터가 최신 상태가 아니라면 → 없는 데이터는 복구 스크립트(recovery spript)를 돌려 추가해야 함
- 다중 마스터(multi-masters) or 원형 다중화(circular replication) 방식 도입하면 도움이 될 수 있음
- 한 대의 부 데이터베이스만 있는 경우
- 부 서버가 한 대 뿐인데 다운된 경우
-
로드밸린서와 데이터베이스 다중화를 고려한 설계안
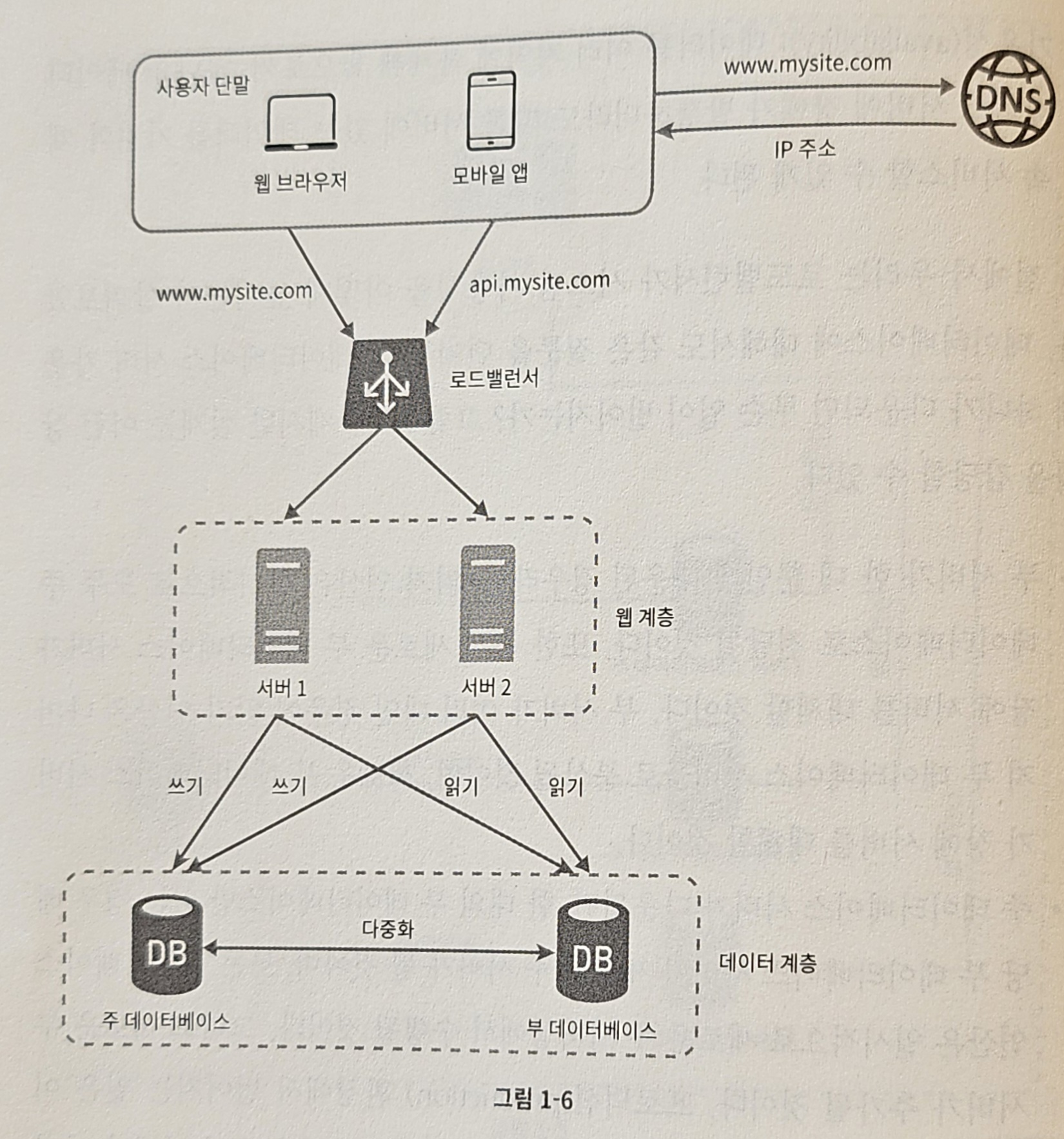
- 동작 방법
- 사용자
- 사용자는 DNS로부터 로드밸런서의 공개 IP 주소를 받음
- 사용자는 해당 IP 주소를 사용해 로드밸런서에 접속
- HTTP 요청은 서버 1 또는 서버 2로 전달
- 웹 서버
- 웹 서버는 사용자 데이터를 부 데이터베이스 서버에서 읽음
- 웹 서버는 데이터 변경 연산은 주 데이터베이스로 전달(데이터 추가, 삭제, 갱신 연산 등이 이에 해당)
- 사용자
- 동작 방법
-
응답시간(latency) 개선
- 응답시간은 캐시(cache)를 붙이고 정적 콘텐츠를 콘텐츠 전송 네트워크(Content Delivery Network, CDN)로 옮겨 개선
💡 그렇다면 로드밸런서와 API Gatway의 차이점은 무엇인지?
- 출처 : https://f-lab.kr/insight/api-gateway-and-load-balancer
- API 게이트웨이와 로드 밸런서의 차이점API 게이트웨이와 로드 밸런서는 서로 다른 역할을 수행하며, 각각의 목적에 맞게 설계되었기 때문에 API 게이트웨이는 API 관리와 라우팅에 초점을 맞추고, 로드 밸런서는 트래픽 분산과 서버 부하 관리에 중점을 둔다.
- 출처 : https://velog.io/@dongvelop/AWS-로드밸런서와-API-게이트웨이
- 이 둘은, 요청 자체인지 네트워크 트래픽인지에 따라 용도가 매우 다르고, 네트워크 아키텍처의 서로 다른 계층에서 작동
- API Gateway
- 요청 자체에 관심을 가짐.
- 요청의 형식이 올바르고, 올바른 마이크로서비스로 라우팅되며, 리소스 가용성에 따라 우선 순위를 지정
- 인증, 규정 준수 및 기타 확인 프로세스와 같은 작업을 처리해 요청이 최상의 상태로 제공되도록 함
- Load Balancer
- 네트워크 트래픽에 더 많은 관심
- 요청이 제대로 형성되었는지, 어느 MS로 전송되는지가 아닌 → 요청을 처리할 수 있는 서버가 여유는 있는지, 네트워크 수요로 인해 과부하가 걸리지는 않는지를 중점적으로 봄
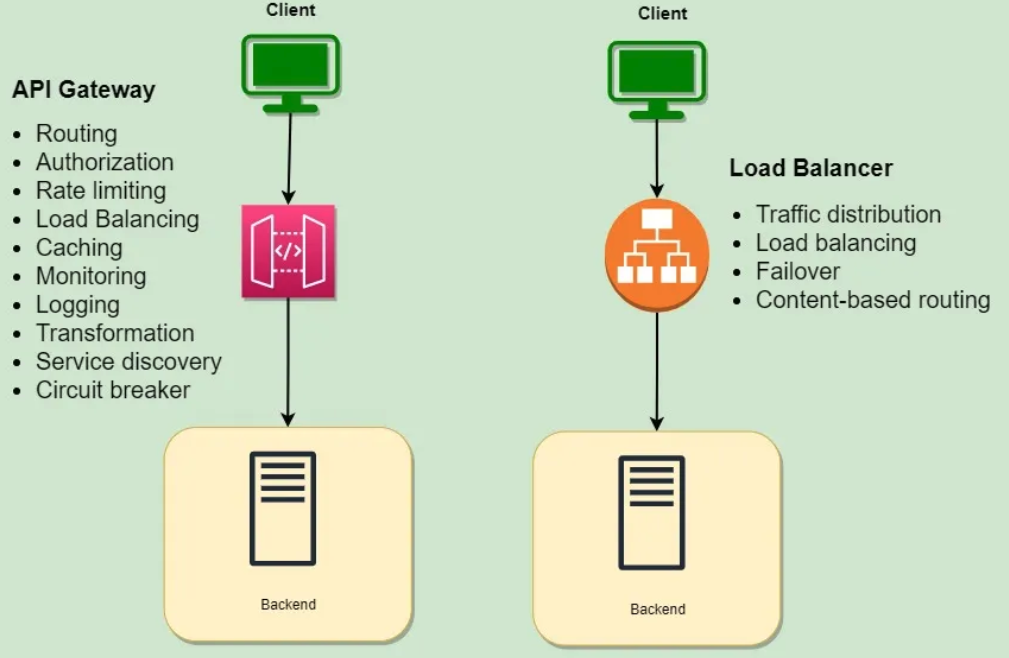
💡 그렇다면, API Gateway와 Load Balancer를 함께 사용할 수 있는지?
- 가능
- API Gateway : 요청을 관리하고 적절한 마이크로서비스로 라우팅
- Load Balancer : 네트워크 트래픽을 여러 서버에 분산
- 이러한 조합으로 효율적인 요청 처리와 부하 분산 보장 → 보다 강력하고 확장 가능한 시스템 구축 가능
💭 캐시
-
값비싼 연산 결과 또는 자주 참조되는 데이터를 메모리 안에 두고, 뒤이은 요청이 보다 빨리 처리될 수 있도록 하는 저장소
-
웹 페이지를 새로고침 할 때 마다 표시할 데이터를 가져오려면 → 한 번 이상의 데이터베이스 호출이 발생
-
애플리케이션의 성능 → 데이터베이스를 얼마나 자주 호출하느냐에 따라 크게 좌우되기 때문에 이러한 문제를 완화하는 것이 “캐시”
-
캐시 계층(cache tier)
-
데이터가 잠시 보관되는 곳
-
데이터베이스보다 훨씬 빠름
-
별도의 캐시 계층을 두면 성능 개선 + 데이터베이스 부하 감소 + 캐시 계층의 규모를 독립적으로 확장하는 것도 가능
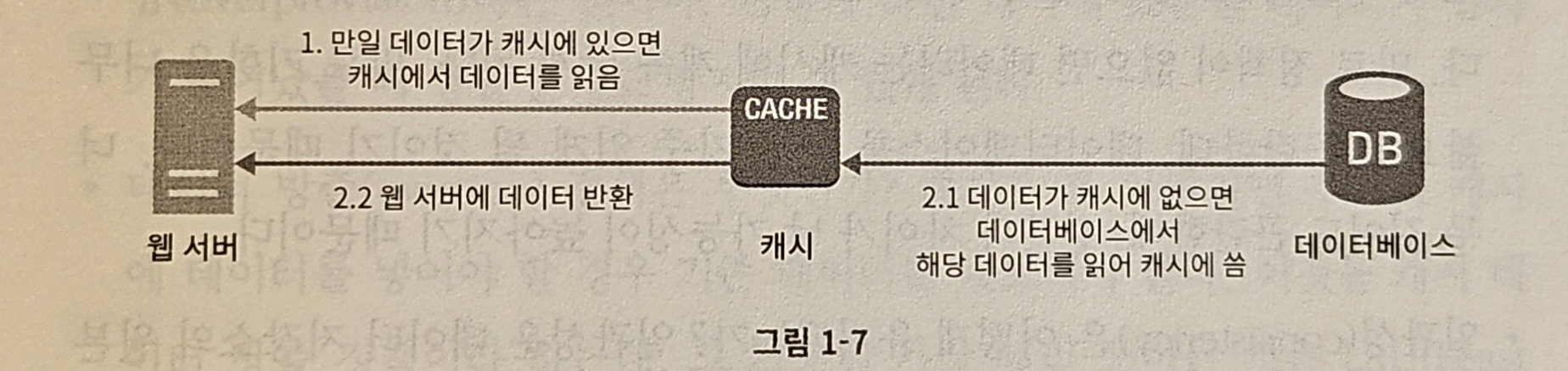
- 주도형 캐시 전략(read-through caching strategy)
- 요청을 받은 웹 서버는 캐시에 응답이 저장되어 있는지 여부 확인
- 저장 O → 해당 데이터를 클라이언트에 반환
- 저장 X → 데이터베이스 질의를 통해 데이터를 찾아 캐시에 저장한 뒤 클라이언트에 반환
- 이 외에도 많은 캐시 전략 존재 → 케시할 데이터 종류, 크기, 액세스 패턴에 맞는 캐시 전략 선택
- 주도형 캐시 전략(read-through caching strategy)
-
-
캐시 서버 이용 방법 → 간단한 편
- 대부분의 캐시 서버들이 일반적으로 널리 쓰이는 프로그래밍 언어로 API 제공하기 때문
//memcached API의 전형적 사용 예 SECONDS = 1 cache.set('myKey', 'hi there', 3600 * SECONDS) cache.get('myKey')
- 대부분의 캐시 서버들이 일반적으로 널리 쓰이는 프로그래밍 언어로 API 제공하기 때문
-
캐시 사용 시 유의할 점
- 캐시는 어떤 상황에 바람직한가?
- 데이터 갱신은 자주 일어나지 않지만 참조는 빈번하게 일어난다면 고려해볼 만하다.
- 어떤 데이터를 캐시에 두어야 하는가?
- 캐시는 데이터를 휘발성 메모리에 두므로, 영속적을 보관할 데이터를 캐시에 두는 것은 바람직하지 않다. ex) 캐시 서버가 재시작되면 캐시 내의 모든 데이터는 사라진다. 중요 데이터는 여전히 지속적 저장소(presistent data store)에 두어야 한다.
- 캐시는 데이터를 휘발성 메모리에 두므로, 영속적을 보관할 데이터를 캐시에 두는 것은 바람직하지 않다. ex) 캐시 서버가 재시작되면 캐시 내의 모든 데이터는 사라진다. 중요 데이터는 여전히 지속적 저장소(presistent data store)에 두어야 한다.
- 캐시에 보관된 데이터는 어떻게 expire(만료)되는가?
- 이에 대한 정책을 마련해 두는 것은 좋은 습관이다.
- 만료된 데이터 → 캐시에서 삭제되어야 한다. | 만료 정책 X → 데이터는 캐시에 계속 남게 된다.
- 만료 기한은 너무 짧으면 곤란(데이터베이스를 너무 자주 읽게 될 것이기 때문), 너무 길어도 곤란(원본과 차이가 날 가능성이 높아지기 때문)
- 일관성(consistency)은 어떻게 유지되는가?
- 일관성은 데이터 저장소의 원본과 캐시 내의 사본이 같은지 여부
- 저장소 원본을 갱신하는 연산과 캐시를 갱신하는 연산이 단일 트랜잭션으로 처리되지 않는 경우 → 일관성 깨짐
- 여러 지역에 걸쳐 시스템을 확장해 나가는 경우 → 캐시와 저장소 사이의 일관성 유지는 어려운 문제가 됨
- 장애에는 어떻게 대처할 것인가?
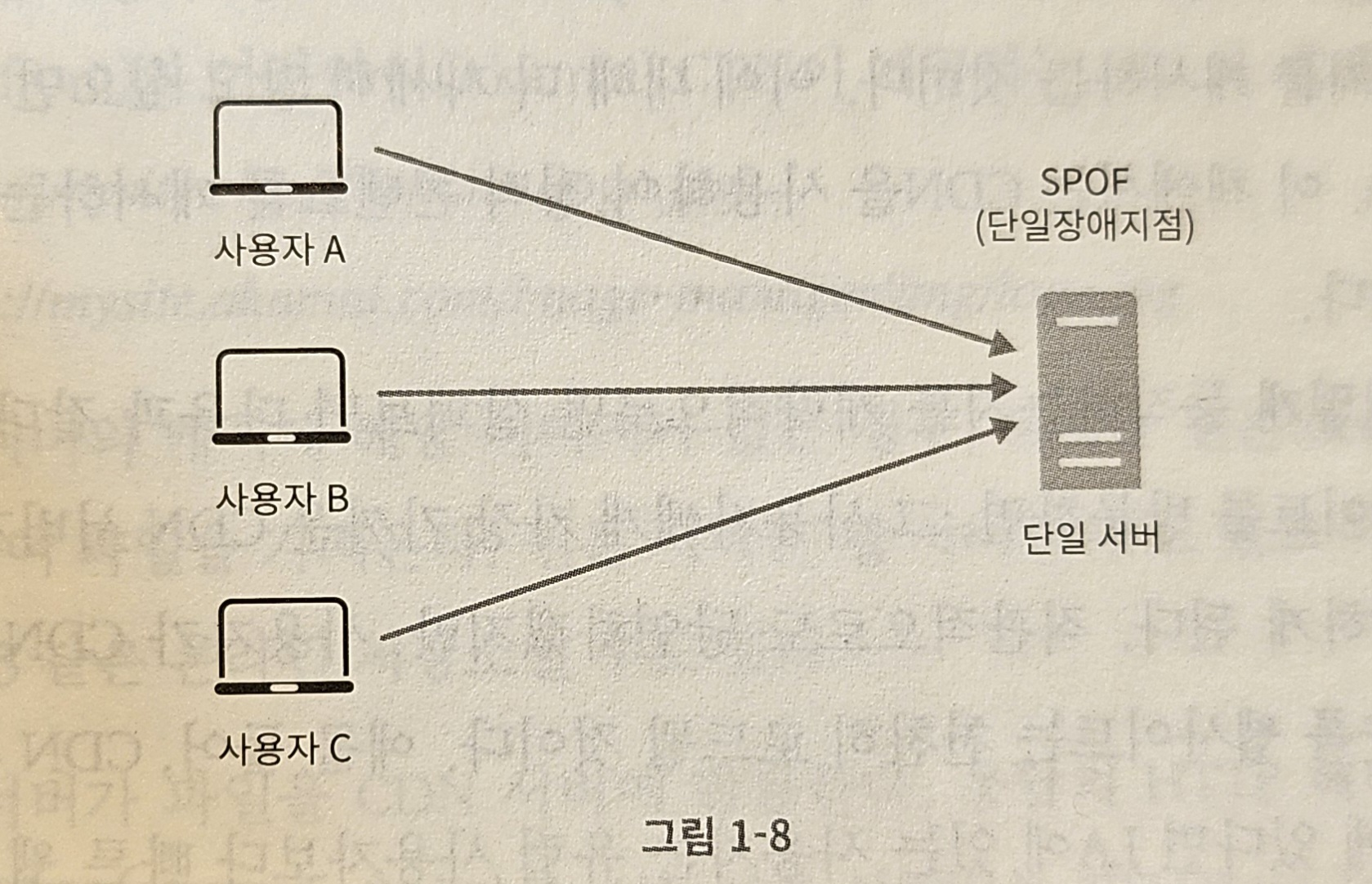
- 캐시 서버를 한 대만 두는 경우 → 해당 서버는 단일 장애 지점(Single Point of Failure, SPOF)이 되어버릴 가능성이 있음
- 단일 장애 지점의 정의(위키피디아): “어떤 특정 지점에서의 장애가 전체 시스템의 동작을 중단시켜버릴 수 있는 경우, 우리는 해당 지점을 단일 장애 지점이라고 부른다.”
- 결과적으로 SPOF를 피하려면 → 여러 지역에 걸쳐 캐시 서버를 분산시켜야 함
- 캐시 메모리는 얼마나 크게 잡을 것인가?
- 캐시 메모리가 너무 작으면 → 액세스 패턴에 따라서는 데이터가 너무 자주 캐시에서 밀려나버려(eviction) 캐시의 성능이 떨어짐
- 예방 : 캐시 메모리를 과할당(overprovision)하는 것 → 캐시에 보관될 데이터가 갑자기 늘어났을 때 생길 문제도 방지할 수 있게 됨
- 데이터 방출(eviction) 정책은 무엇인가?
- 캐시가 꽉 차버리면 추가로 캐시에 데이터를 넣어야 할 경우 → 기존 데이터를 내보내야 함 → 이것을 캐시 데이터 방출 정책이라고 함
- LRU(Least Recently Used - 가장 널리 쓰이는 정책, 마지막으로 사용된 시점이 가장 오래된 데이터를 내보내는 정책
- LFU(Least Frequently Used - 사용된 빈도가 가장 낮은 데이터를 내보내는 정책
- FIFO(First In First Out - 가장 먼저 캐시에 들어온 데이터를 가장 먼저 내보내는 정책
- 캐시는 어떤 상황에 바람직한가?
💭 콘텐츠 전송 네트워크(CDN)
-
CDN : 정적 콘텐츠를 전송하는 데 쓰이는, 지리적으로 분산된 서버의 네트워크
- 이미지, 비디오, CSS, JavaScript 파일 등을 캐시할 수 있음
-
동적 콘텐츠 캐싱은 상대적으로 새로운 개념
- 요청 경로(request path), 질의 문자열(query string), 쿠키(cookie), 요청 헤더(request header) 등의 정보에 기반해 HTML 페이지를 캐시하는 것
-
CDN의 개략적 동작 방식
- 어떤 사용자가 웹사이트를 방문 → 그 사용자에게 가장 가까운 CDN 서버가 정적 콘텐츠를 전달하게 됨
- 사용자가 CDN 서버로부터 멀면 멀수록 → 웹사이트를 천천히 로드 ex) CDN 서버가 샌프란시스코에 있다면 LA에 있는 사용자는 유럽 사용자보다 빠른 웹사이트를 보게 될 것
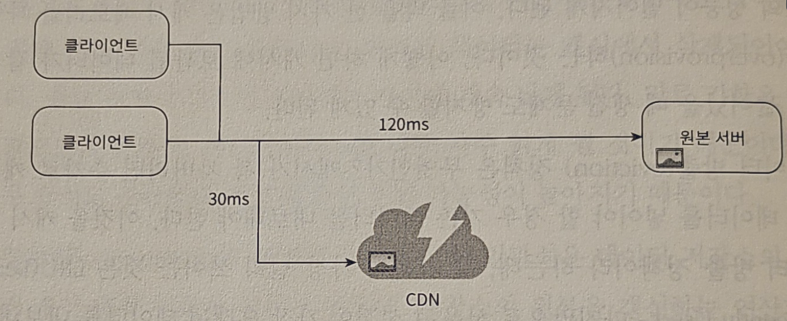
- CDN 동작 순서
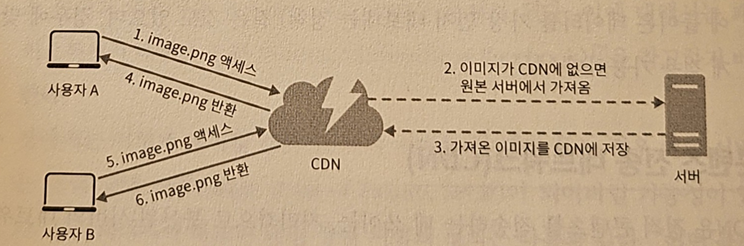
- 사용자 A가 이미지 URL을 이용해 image.png에 접근
- URL의 도메인은 CDN 서비스 사업자가 제공한 것
- 클라우드프론트(Cloudfront)와 아카마이(Akamai) CDN이 제공하는 URL의 예제
- CDN 서버의 캐시에 해당 이미지가 없는 경우 → 서버는 원본(origin) 서버에 요청해 파일을 가져옴
- 원본 서버는 웹 서버 or 아마존(Amazon) S3와 같은 온라인 저장소
- 원본 서버가 파일을 CDN 서버에 반환
- 응답의 HTTP 헤더에는 해당 파일이 얼마나 오래 캐시될 수 있는지를 설명하는 TTL(Time-To-Live) 값이 들어 있음
- CDN 서버는 파일을 캐시하고 사용자 A에게 반환 + 이미지는 TTL에 명시된 시간이 끝날 때까지 캐시됨
- 사용자 B가 같은 이미지에 대한 요청을 CDN 서버에 전송함
- 만료되지 않은 이미지에 대한 요청은 캐시를 통해 처리됨
- 사용자 A가 이미지 URL을 이용해 image.png에 접근
-
CDN 사용 시 고려해야 할 사항
- 비용
- CDN은 보통 third-party providers(제3사업자)에 의해 운영 → 데이터 전송 양에 따라 요금 부과
- 자주 사용되지 않는 콘텐츠를 캐싱하는 것은 이득이 크지 않으니 CDN에서 빼는 것 고려하기
- 적절한 만료 시한 설정
- 시의성이 중요한(time-sensitive) 콘텐츠의 경우 만료 시점 잘 정해야 함
- 너무 길면 → 콘텐츠 신선도 ⬇️, 너무 짧으면 원본 서버에 빈번히 접속해 좋지 않음
- CDN 장애에 대한 대처 방안
- CDN 자체가 죽었을 경우 웹사이트/애플리케이션이 어떻게 동작해야 하는지 고려
- 일시적으로 CDN이 응답하지 않을 경우 → 해당 문제를 감지해 원본 서버로부터 직접 콘텐츠를 가져오도록 클라이언트를 구성하는 것이 필요할 수도 있음
- 콘텐츠 무효화(invalidation) 방법
- 아직 만료되지 않은 콘텐츠라 하더라도 CDN에서 제거 가능
- CDN 서비스 사업자가 제공하는 API 이용
- 콘텐츠의 다른 버전을 서비스하도록 오브젝트 버저닝(object versioning) 이용
- 콘텐츠의 새로운 버전을 지정하기 위해서는 URL 마지막에 버전 번호를 인자로 주기(image.png?v=2)
- 아직 만료되지 않은 콘텐츠라 하더라도 CDN에서 제거 가능
- 비용
-
CDN과 캐시가 추가된 설계
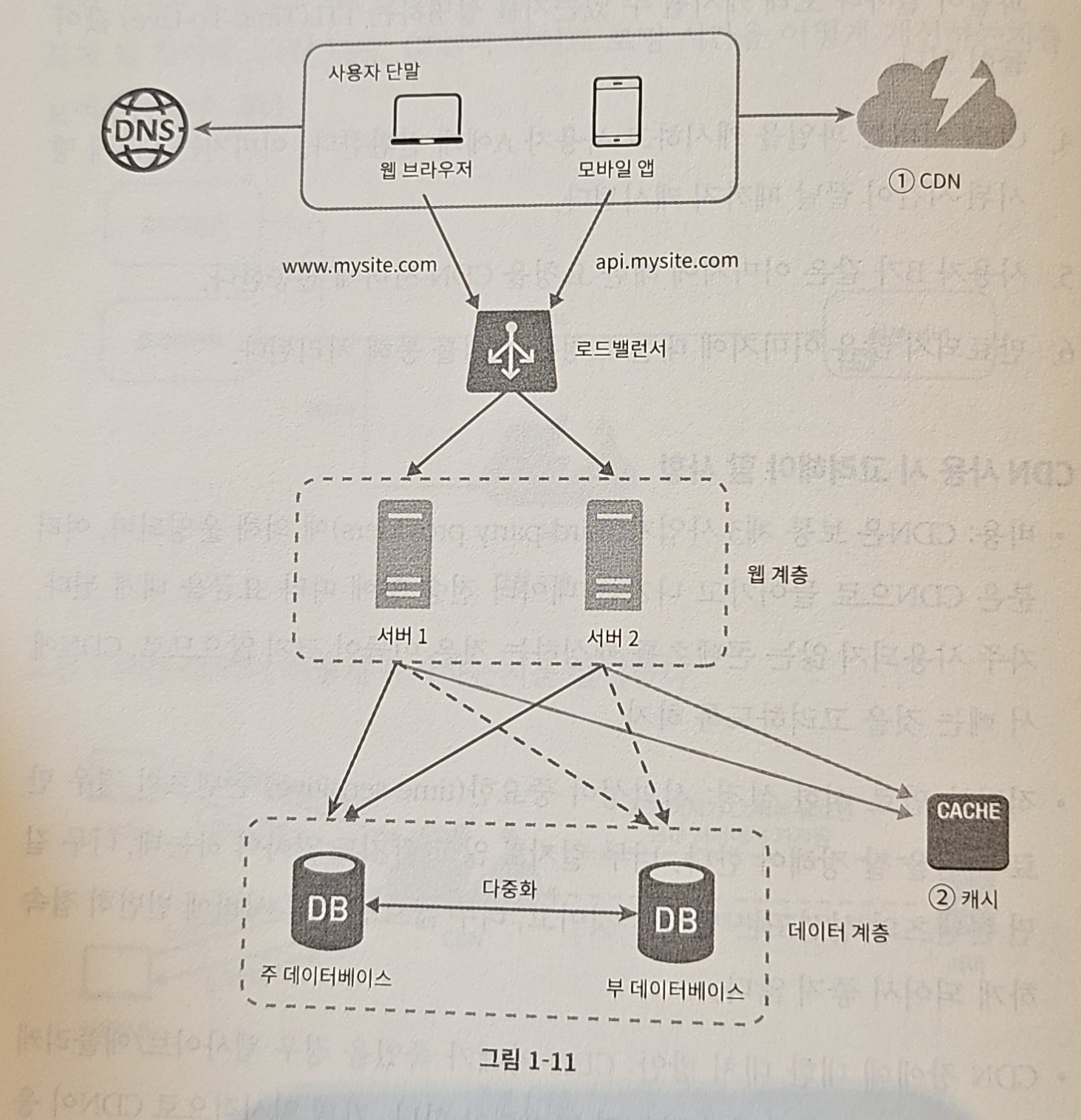
- 변화지점
- 정적 콘텐츠(JS, CSS, 이미지 등)는 더 이상 웹 서버를 통해 서비스하지 않으며, CDN을 통해 제공해 더 나은 성능 보장
- 캐시가 데이터베이스 부하 줄임
- 변화지점
{kind=link}
{kind=link}
💭 무상태(stateless) 웹 계층
-
무상태(stateless) 웹 계층?
- 웹 계층을 수평적으로 확장하는 방법
- 상태 정보(사용자 세션 데이터와 같은)를 웹 계층에서 제거: 상태 정보를 관계형 데이터베이스나 NoSQL 같은 지속성 저장소에 보관, 필요할 때 가져오는 방식
-
상태 정보 의존적인 아키텍처
-
상태 정보를 보관하는 서버 : 클라이언트 정보 즉, 상태를 유지해 요청들 사이에 공유되도록 함
-
무상태 서버 : 이러한 장치가 없음
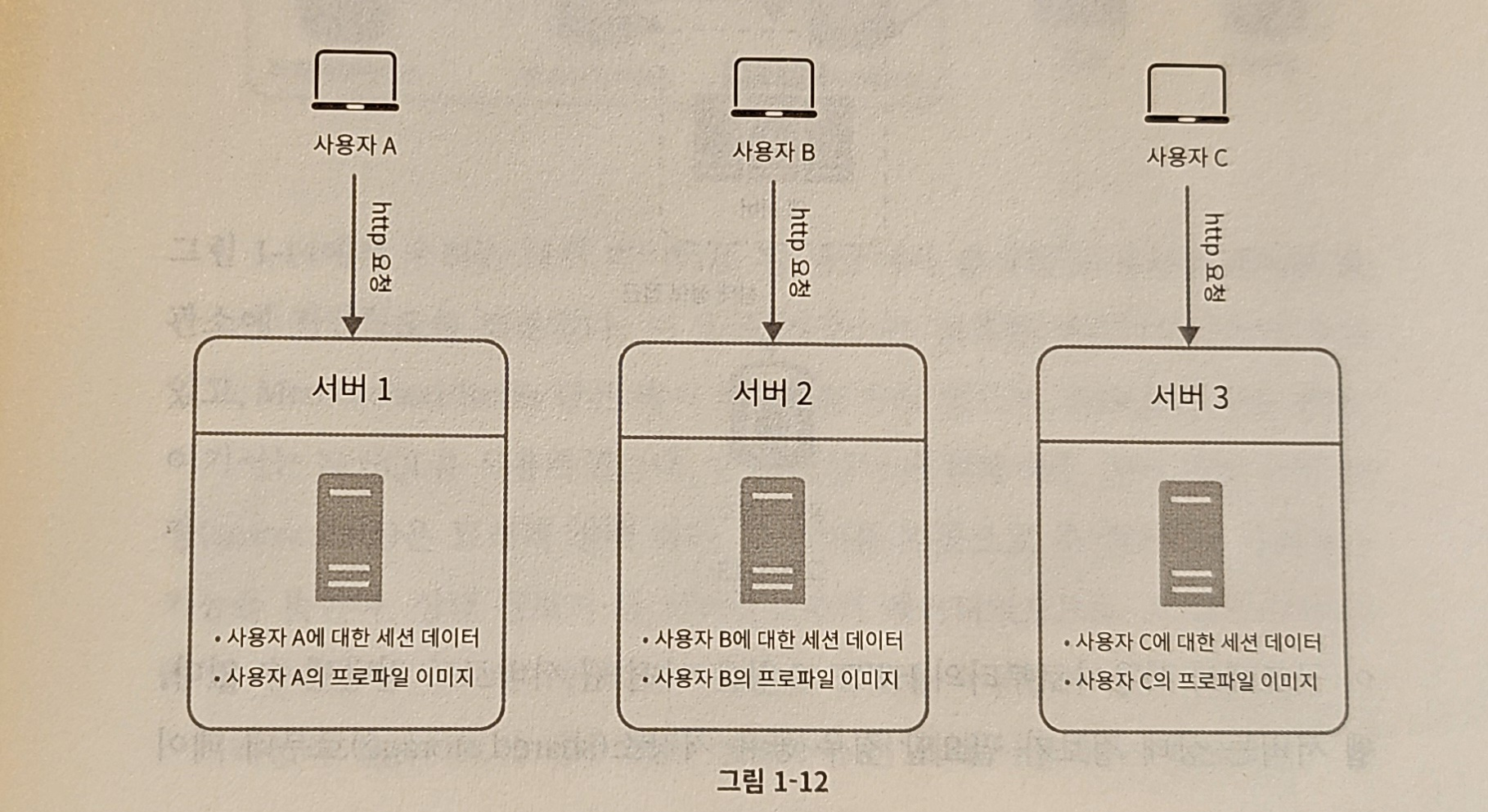
-
사용자 A의 세션 정보나 프로파일 이미지 같은 상태 정보는 서버 1에 저장
-
사용자 A를 인증하기 위해 HTTP 요청은 반드시 서버 1로 전송되어야 함
- 서버 2에 요청이 전송된다면 인증은 실패한 것 → 서버 2에 사용자 A에 관한 데이터는 보관되어 있지 않기 때문
-
사용자 B로부터의 HTTP 요청은 전부 서버 2로 전송되어야 함
-
사용자 C로부터의 요청은 전부 서버 3으로 전송되어야 함
-
-
문제는 같은 클라이언트로부터의 요청 → 항상 같은 서버로 전송되어야 한다는 것
- 대부분의 로드밸런서가 고정 세션(sticky session)이라는 기능을 제공 → 로드밸런서에 부담을 줌
- 게다가 로드밸런서 뒷단에 서버를 추가하거나 제거하기 까다로워짐
- 이들 서버의 장애를 처리하기도 복잡해짐
-
무상태 아키텍처
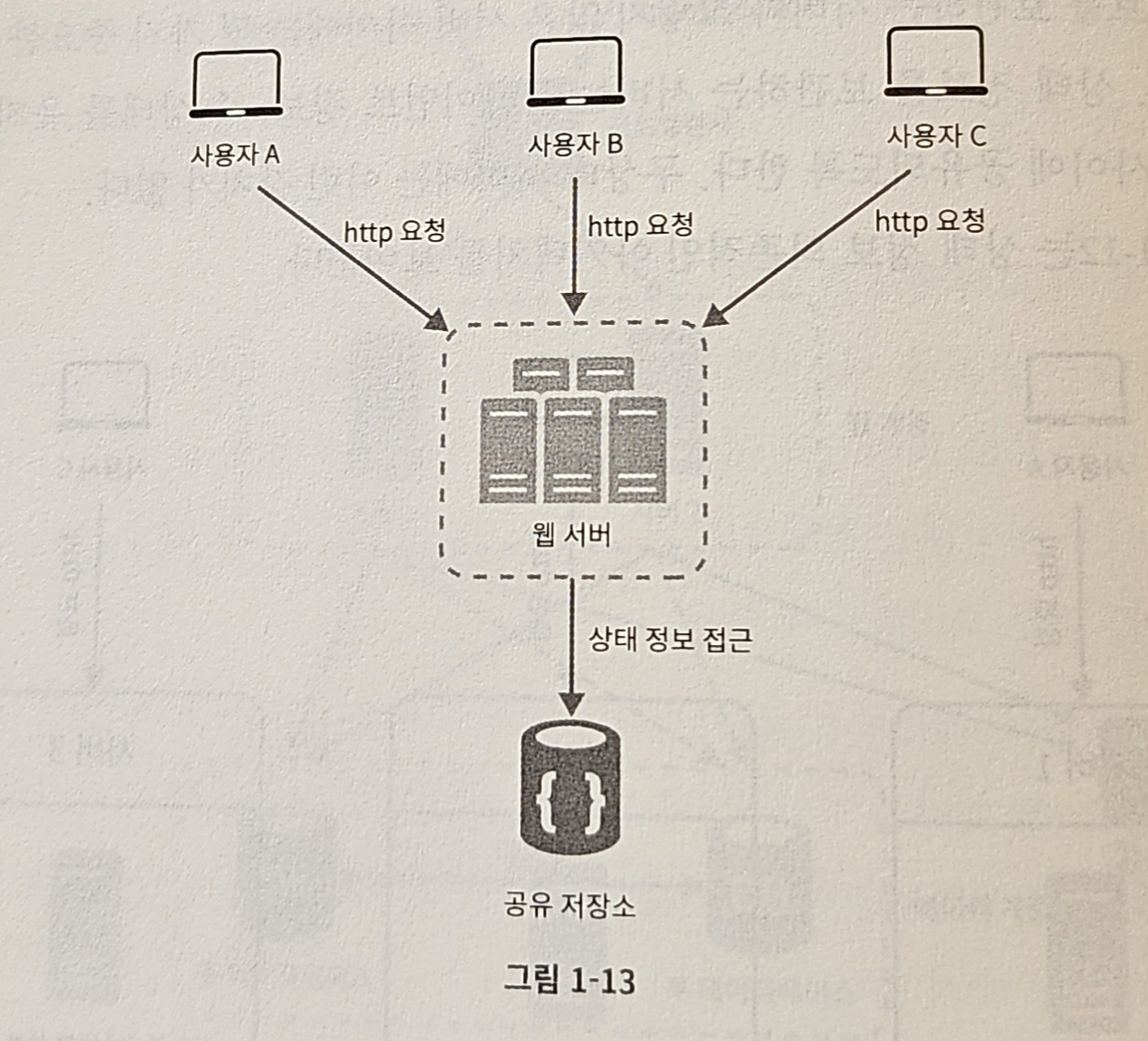
- 사용자로부터의 HTTP 요청은 어떤 웹 서버로도 전달될 수 있음
- 웹 서버는 상태 정보가 필요할 경우 공유 저장소(shared storage)로부터 데이터를 가져옴
- 상태 정보는 웹 서버로부터 물리적으로 분리되어 있음
- 이러한 구조는 단순하고, 안정적이며, 규모 확장이 쉽다
-
무상태 웹 계층을 갖도록 기존 설계를 변경한 결과
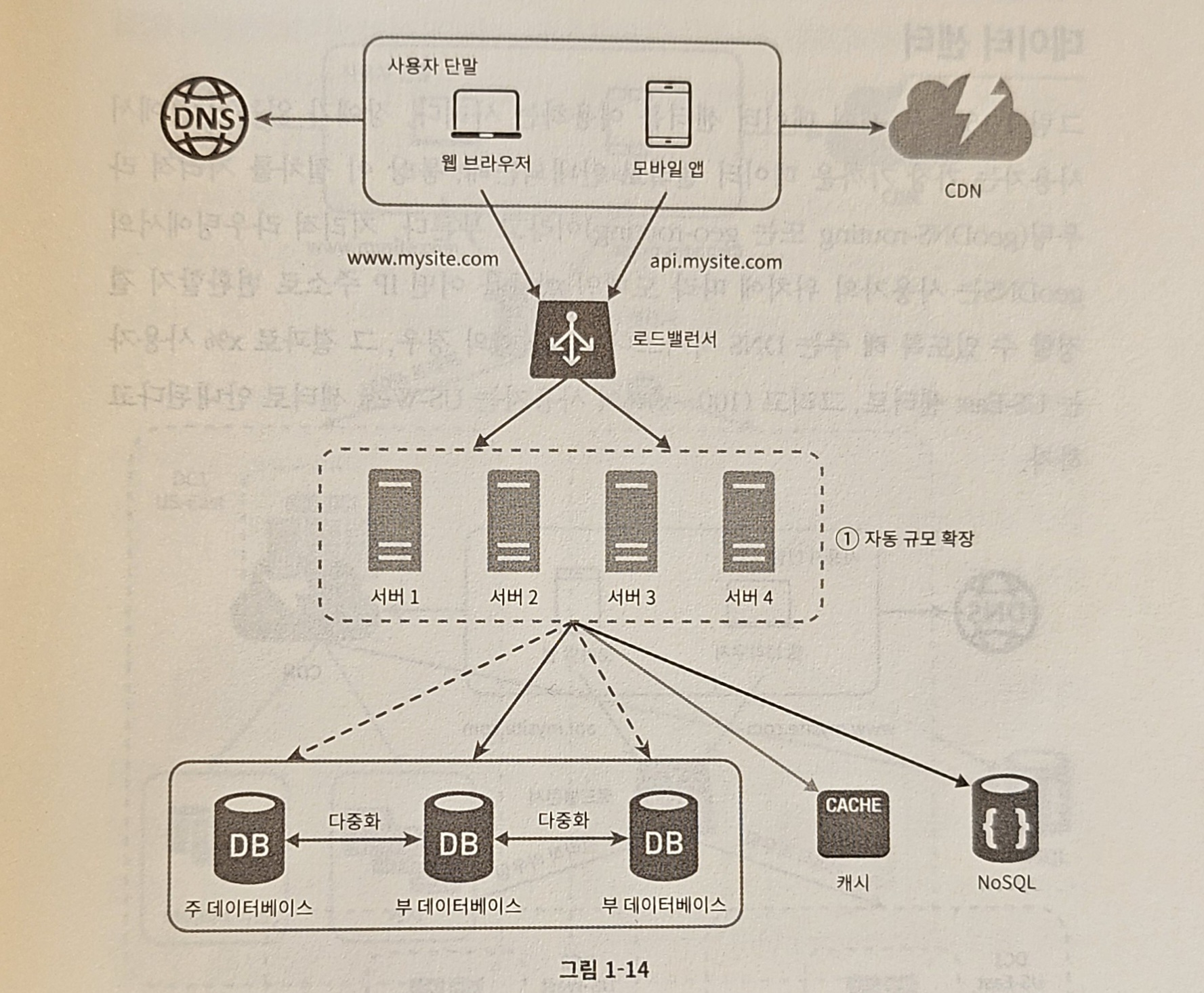
- 세션 데이터를 웹 계층에서 분리하고 지속성 데이터 보관소에 저장하도록 만들었음
- 이 공유 저장소는 관계형 데이터베이스일 수도, Memcached/Redis 같은 캐시 시스템일 수도, NoSQL일 수도 있음
- 이 예시 → NoSQL
- 규모 확장이 간편하기 때문
- 1️⃣의 자동 규모 확장(autoscaling)은 트래픽 양에 따라 웹 서버를 자동으로 추가하거나 삭제하는 기능
- 상태 정보가 웹 서버들로부터 제거 → 트래픽 양에 따라 웹 서버를 넣거나 빼기만 하면 자동으로 규모를 확장할 수 있게 되었음
💭 데이터 센터
-
두 개의 데이터 센터를 이용하는 사례
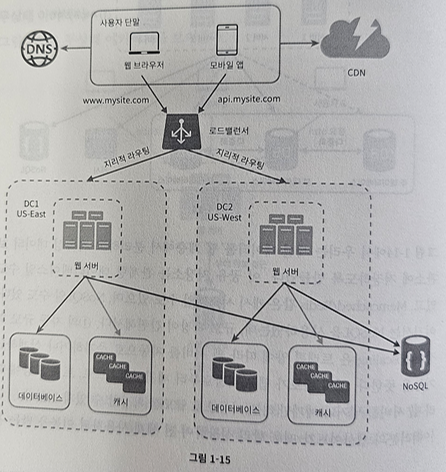
- 장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내됨 → 이를 지리적 라우팅(geoDNS-routing or geo-routing)이라 함
- geoDNS : 사용자의 위치에 따라 도메인 이름은 어떤 IP 주소로 변환할지 결정할 수 있도록 해주는 DNS 서비스
- 이 예제의 경우 그 결과로 x% 사용자는 US-East 센터로, 그리고 (100-x)%의 사용자는 Us-West 센터로 안내된다고 하자.
- 이들 데이터 센터 중 하나에 심각한 장애가 발생하면 모든 트래픽은 장애가 없는 데이터 센터로 전송됨.
- 데이터센터2(Us-West)에 장애가 발생해 모든 트래픽이 데이터센터1(US-East)로 전송되는 상황
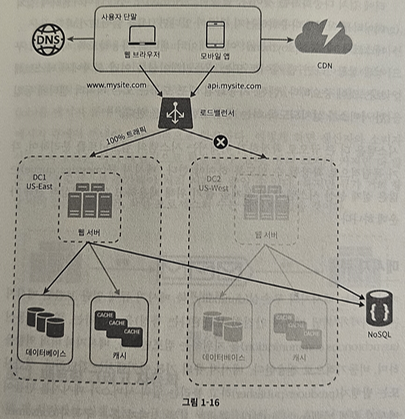
- 장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내됨 → 이를 지리적 라우팅(geoDNS-routing or geo-routing)이라 함
-
이 사례와 같은 다중 데이터센터 아키텍처를 만들기 위한 기술적 난제 해결
- 트래픽 우회
- 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법을 찾아야 함
- GeoDNS는 사용자에게서 가장 가까운 데이터센터로 트래픽을 보낼 수 있도록 해줌
- 데이터 동기화(synchronization)
- 데이터 센터마다 별도의 데이터베이스를 사용하고 있는 상황 → 장애가 자동으로 복구되어(failover) 트래픽이 다른 데이터베이스로 우회된다 해도 해당 데이터센터에는 찾는 데이터가 없을 수 있음
- 이 상황을 막는 보편적 전략은 데이터를 여러 데이터 센터에 걸쳐 다중화하는 것 ex) 넷플릭스(Netflix)
- 테스트와 배포(deployment)
- 여러 데이터 센터를 사용하도록 시스템이 구성된 상황 → 웹 사이트 또는 애플리케이션을 여러 위치에서 테스트해보는 것이 중요
- 자동화된 배포 도구는 모든 데이터 센터에 동일한 서비스가 설치되도록 하는 데 중요한 역할을 함
- 트래픽 우회
-
시스템을 더 큰 규모로 확장하기 위해 → 시스템의 컴포넌트를 분리하여 독립적으로 확장될 수 있도록 해야 함
-
메시지 큐(message queue)는 많은 실제 분산 시스템이 이 문제를 풀기 위해 채용하고 있는 핵심적 전략 가운데 하나
💭 메시지 큐
-
메시지 큐
- 메시지의 무손실(durability, 즉 메시지 큐에 일단 보관된 메시지는 소비자가 꺼낼 때까지 안전히 보관된다는 특성)을 보장하는, 비동기 통신(asynchronous communication)을 지원하는 컴포넌트
- 메시지의 버퍼 역할, 비동기적 전송
-
메시지 큐의 기본 아키텍처
- 생산자 또는 발행자(producer/publisher)라고 불리는 입력 서비스가 메시지를 만들어 메시지 큐에 발행함(publish)
- 큐에는 보통 소비자 혹은 구독자(consumer/subscriber)라 불리는 서비스 혹은 서버가 연결되어 있는데, 메시지를 받아 그에 맞는 동작을 수행하는 역할을 함.

-
메시지 큐 이용 시 이점
- 서비스 또는 서버 간 결합이 느슨해진다.
- 규모 확장성이 보장되어야 하는 안정적 애플리케이션을 구성하기 좋음
- 생산자는 소비자 프로세스가 다운되어 있어도 메시지를 발행할 수 있다.
- 소비자는 생산자 서비스가 가용한 상태가 아니더라도 메시지를 수신할 수 있다.
- 서비스 또는 서버 간 결합이 느슨해진다.
-
메시지 큐 사용 예
- 이미지의 크로핑(cropping), 샤프닝(sharpening), 블러링(blurring) 등을 지원하는 사진 보정 애플리케이션을 만든다면?
- 비동기적으로 처리하면 편리함
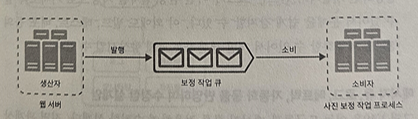
- 웹 서버는 사진 보정 작업(job)을 메시지 큐에 넣음
- 사진 보정 작업(worker) 프로세스들은 이 작업을 메시지 큐에서 꺼내어 비동기적으로 완료함
- 이를 통해 생산자와 소비자 서비스의 규모는 각기 독립적으로 확장될 수 있음
- 비동기적으로 처리하면 편리함
- 큐의 크기가 커지면 더 많은 작업 프로세스를 추가해야 처리 시간을 줄일 수 있음
- 큐가 거의 항상 비어 있는 상태라면 → 작업 프로세스의 수는 줄일 수 있을 것
- 이미지의 크로핑(cropping), 샤프닝(sharpening), 블러링(blurring) 등을 지원하는 사진 보정 애플리케이션을 만든다면?
💭 로그, 메트릭 그리고 자동화
-
로그
- 에러 로그 모니터링 중요
- 시스템 오류와 문제들을 보다 쉽게 찾아낼 수 있도록 하기 때문
- 에러 로그: 서버 단위로 모니터링할 수도 있지만, 로그를 단일 서비스로 모아주는 도구를 활용하면 더 편리하게 검색 및 조회 가능
-
메트릭
- 메트릭을 잘 수집하면 사업 현황에 관한 유용한 정보를 얻을 수도 있고, 시스템의 현재 상태를 손쉽게 파악할 수도 있음
- 메트릭 가운데 특히 유용한 것
- 호스트 단위 메트릭 - CPU, 메모리, 디스크 I/O에 관한 메트릭이 해당
- 종합(aggregated) 메트릭 - 데이터베이스 계층의 성능, 캐시 계층의 성능이 해당
- 핵심 비즈니스 메트릭 - 일별 능동 사용자(daily active user), 수익(revenue), 재방문(retention)이 해당
-
자동화
- 시스템이 크고 복잡해지면 생산성을 높이기 위해 자동화 도구를 활용해야 함
- 지속적 통합(continuous integration)을 도와주는 도구 활용 → 개발자가 만드는 코드가 어떤 검증 절차를 자동으로 거치도록 할 수 있어 문제를 쉽게 감지 가능
- 빌드, 테스트, 배포 등의 절차도 자동화할 수 있어 개발 생산성을 크게 향상
-
메시지 큐, 로그, 메트릭, 자동화 등을 반영해 수정한 설계안
- 지면 관계상 하나의 데이터센터만 그림에 포함
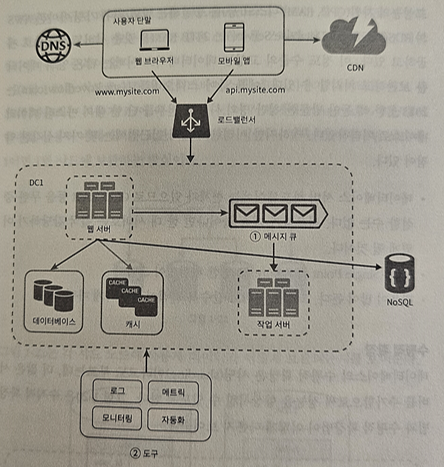
- 메시지 큐는 각 컴포넌트가 보다 느슨히 결합(loosely coupled)될 수 있도록 하고, 결함에 대한 내성 높임
- 로그, 모니터링, 매트릭, 자동화 등을 지원하기 위한 장치 추가
- 지면 관계상 하나의 데이터센터만 그림에 포함
💭 데이터베이스의 규모 확장
-
저장할 데이터가 많아지면 데이터베이스 부하도 증가 → 데이터베이스 증설 방법을 찾아야 함
-
수직적 확장과 수평적 확장의 차이점
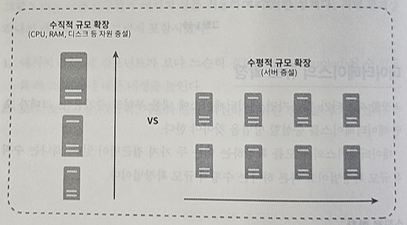
-
데이터베이스 규모 확장의 2가지 방법
- 수직적 확장
- 스케일 업
- 기존 서버에 더 많은, 또는 고성능의 자원(CPU, RAM, 디스크 등)을 증설하는 방법
- 아마존 AWS RDS(Relational Database Service) → 24TB RAM을 갖춘 서버도 상품으로 제공하고 있음
- 이 정도 수준의 고성능 데이터베이스 서버는 많은 양의 데이터를 보관하고 처리할 수 있음 ex) 스택오버플로(stackoverflow.com) → 2013년 한 해 동안 방문한 천만 명의 사용자 전부를 단 한 대의 마스터 데이터베이스로 처리함
- 이 정도 수준의 고성능 데이터베이스 서버는 많은 양의 데이터를 보관하고 처리할 수 있음 ex) 스택오버플로(stackoverflow.com) → 2013년 한 해 동안 방문한 천만 명의 사용자 전부를 단 한 대의 마스터 데이터베이스로 처리함
- 심각한 약점
- 데이터베이스 서버 하드웨어에는 한계가 있으니 CPU, RAM 등을 무한 증설할 수는 X → 서버 1대로는 결국 감당하기 어렵게 될 것
- SPOF(Single Point of Failure)로 인한 위험성이 큼
- 비용이 많이 듦 → 고성능 서버로 갈수록 가격이 올라가기 마련
- 수평적 확장
- 샤딩(sharding)이라고도 부름
- 더 많은 서버를 추가함으로써 성능을 향상시킬 수 있도록 함
- 샤딩은 대규모 데이터베이스를 샤드(shard)라고 부르는 작은 단위로 분할하는 기술을 말함
- 모든 사드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없음
- 샤드로 분할된 데이터베이스의 예
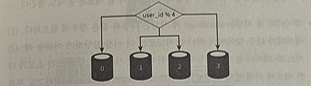
- 사용자 데이터를 어느 샤드에 넣을지는 사용자 ID에 따라 정함
- 이 사례) user_id % 4를 해시 함수로 사용해 데이터가 보관되는 샤드를 정함 → 결과가 0이면 0번 샤드에, 1이면 1번 샤드에 보관하는 방식
- 수직적 확장
-
각 샤드 노드에 사용자 데이터가 어떻게 보관되는지 여부
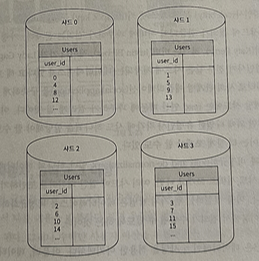
- 샤딩 키 : user_id
-
샤딩 전략 구현 시 고려할 가장 중요한 것 → 샤딩 키(sharding key)를 어떻게 정하느냐
- 샤딩 키 : 파티션 키(partition key)라고도 부르는데, 데이터가 어떻게 분산될지 정하는 하나 이상의 칼럼으로 구성됨
- 샤딩 키를 통해 올바른 데이터베이스에 질의를 보내어 데이터 조회나 변경을 처리해 효율을 높일 수 있음
- 샤딩 키를 정할 때는 데이터를 고르게 분할할 수 있도록 하는 게 가장 중요
- 샤딩 도입 시 시스템 복잡 + 풀어야 할 새로운 문제도 생김
-
데이터의 재 샤딩(resharding)
(1) 데이터가 너무 많아져서 하나의 샤드로는 더 이상 감당하기 어려울 때 (2) 샤드 간 데이터 분포가 균등하지 못해 어떤 샤드에 할당된 공간 소모가 다른 샤드에 비해 빨리 진행될 때 = 샤드 소진(shard exhaustion) - 해당 현상 발생 시, 샤드 키를 계산하는 함수를 변경하고 데이터 재배치 필요 → 안정 해시(consistent hashing) 기법 활용해 해결 (3) 유명인사(celebrity) 문제 - 핫스팟 키(hotspot key) 문제라고고 불림 - 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제 ex) Katy Perry, Justin Bieber, Lada Gaga 같은 유명인사가 전부 같은 샤드에 저장되는 데이터베이스가 있다면? → 이 데이터로 사회 관계망 애플리케이션(social application)을 구축하게 되면 결국 해당 샤드에는 read 연산때문에 과부하 발생! - 해결법 : 유명인사 각각에 샤드 하나씩을 할당해야 할수도, 심지어는 더 잘게 쪼개야 할 수도 있음(4) 조인과 비정규화(join and de-normalization)
-
일단 하나의 데이터베이스를 여러 샤드 서버로 쪼개고 나면 → 여러 샤드에 걸친 데이터를 조인하기가 힘들어짐
-
해결법 : 데이터베이스를 비정규화하여 하나의 테이블에서 질의가 수행될 수 있도록 하는 것
-
-
데이터베이스 샤딩을 적용한 아키텍처
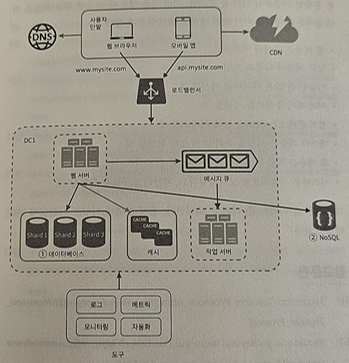
- 데이터베이스에 대한 부하를 줄이기 위해 굳이 관계형 데이터베이스가 요구되지 않는 기능들은 NoSQL로 이전
💭 백만 사용자, 그리고 그 이상
-
시스템의 규모를 확장하는 것은 지속적이고 반복적(iterative)인 과정
-
수백만 사용자 이상을 지원하려면 새로운 전략 도입해야 하고, 지속적으로 시스템을 가다듬어야 함
-
시스템을 최적화하고 더 작은 단위의 서비스로 분할해야 할 수도 있음
-
시스템 규모 확장 기법 정리
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 한 많은 데이터를 캐시할 것
- 여러 데이터 센터를 지원할 것
- 정적 콘텐츠는 CDN을 통해 서비스할 것
- 데이터 계층은 샤딩을 통해 그 규모를 확장할 것
- 각 계층은 독립적 서비스로 분할할 것
- 시스템을 지속적으로 모니터링하고, 자동화 도구들을 활용할 것
