
1-1. 들어가며
학습 목표
- 시계열 분석의 방법을 알아보기
- 분석을 위해 필요한 기초 라이브러리 학습
- 어떤 도메인에서 활용하는지 알아보기
시계열 데이터란?
- 일정 시간 간격 배치 데이터의 수열(순서 O)
- 시간적 종속이 있다면 시계열 데이터!
시계열 분석이란?
- 시간 순서로 정렬된 데이터 -> 유의미한 요약 및 통계 정보 추출을 위한 노력
- 예측에 활용(과거 행동 진단도 일부 포함)
- "과거가 미래에 어떠한 영향을 주는지", "과거와 미래가 어떤 연관이 있는지"의 해답을 찾는 과정임
1-2. 데이터 관련 라이브러리 복기
용어 정리
-
행렬(Matrix)
- 수 or 수식을 가로(행, row), 세로(열, column)로 배열
-
배열(array)
- 순서 있는 원소들이 연속적인 나열이 되어 있음
-
다차원 배열(Multi-dimensional array)
- 2차원 이상 배열(n차원)
-
난수(Random)
- 무작위 수
- Python : random 모듈
-
모듈(Module)
- 파이썬의 함수(function), 변수(variable), 클래스(class) 집합
-
패키지(Package)
- 특정 기능을 하는 여러 모듈 -> 한 파일에 집합
-
라이브러리(Library)
- 패키지와 모듈의 집합
-
인자(Argument)
- 함수 정의 시 변수 이름
- 보통 x, y 값
-
파라미터(Parameter)
- 매개변수
- 함수 호출 시 인자로 전달된 값이 함수 내부에서 사용될 수 있도로 함
- 인자와 혼용 사용
Numpy
- List에서의 행렬 및 배열
- 행렬 생성 :
np.array() - 배열 열 개수 확인 :
ndarray.shape() - 배열 차원 확인 :
ndarray.ndim() - 배열 원소 접근 :
ndarray[0, 0] - Numpy array 합치기 :
np.concatenate((a,b)) - 배열 슬라이싱 & 인덱싱 :
array[a:b] - 배열 연산(집계) :
np.max(),np.min(),np.sum()
- 행렬 생성 :
Numpy vs Python list
- numpy array
- 숫자형 + 문자열 혼합 -> 문자열로 출력
- 연산 속도 빠름
- 유연성 부족
- Dynamic typing X
- python list
- 숫자형 + 문자열 혼합 -> 각자 자료형 타입 유지 가능
- 연산 속도 느림
- Dynamic typing O(자료형 명시가 없어도 자료형이 들어가는 것)
Pandas
-
숫자 테이블, 시계열 조작을 위한 데이터 구조 및 연산 제공
-
Pandas DataFrame
- 대표적 데이터 핸들링 도구
- 파이썬에서 엑셀, 데이터베이스의 역할
- 2차원 배열 형태
- 1차원 배열 형태인 시리즈(Series)의 합으로 구성 - 각 컬럼별 다른 데이터타입 사용 가능
-
Pandas 함수
df.head(): 앞에서부터 확인(디폴트 5)df.tail(): 뒤에서부터 확인(디폴트 5)df.index: 전체 데이터프레임에서 인덱스 및 데이터 타입 확인df.columns: 전체 데이터프레임에서 컬럼 치 데이터 타입 확인df.loc[...],df.iloc[index number, column number]: 특정 행, 열 기준으로 나눠서 컬럼 기준 혹은 인덱스 기준으로 가져오는 함수
1-3. 시계열 데이터의 이해
용어 정리
-
시계열 데이터(Time Series data)
- 대표적 예시 : 심전도, 월별 혹은 계절별 온도 및 수온 데이터 등
-
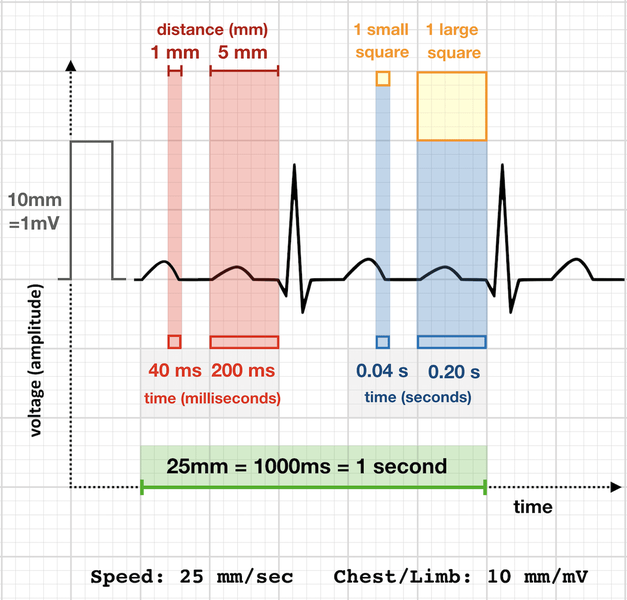
심전도(Electrocardiogram)
- 심장 박동 시 심장 통과 전류가 기록된 데이터
- ECG, EKG
-
예측(Prediction)
- 입력값(input, x)을 모델에 넣어 나온 출력
- 예측값(출력값), predict, pred 혼용
-
곰페르츠 모형(Gompertz)
- (유통업) 어떤 특정 제품이 시장에서 얼마나 팔릴지 추정하는 모델
의료 분야 시계열
-
‘Natural and Political Observations Made upon the Bills of Mortality’
- 1676년도 초판 발행
- 최초 의료 시계열 데이터 기록
- 사망 시 교회의 종이 울림 -> 죽음을 사후 추적해 사망한 사람 수를 시계열적으로 기록
-
EKG(ECG) 데이터
- 전기 신호를 통한 심장 상태 진단
- 심장 상태 정보 -> 시계열적으로 제공
금융 분야 시계열
- 주가 예측
- 단기(Short Term) vs 장기(Long Term)
- 시장 지수 예측 vs 개별 주가 예측
리테일 분야 시계열
- 유통업 물량 수요 예측
- 시계열 분석 + 정성적 기법으로 미래 수요 예측
- 곰페르츠 모형
그 외
-
시계열 데이터는 주로
Line Plot으로 시각화 -
Electrical activity in the brain
- 뇌전도 검사(EEG)
- 뇌파 or 뇌의 전기적 활동 이상 감지 검사
- 뇌전도 검사(EEG)

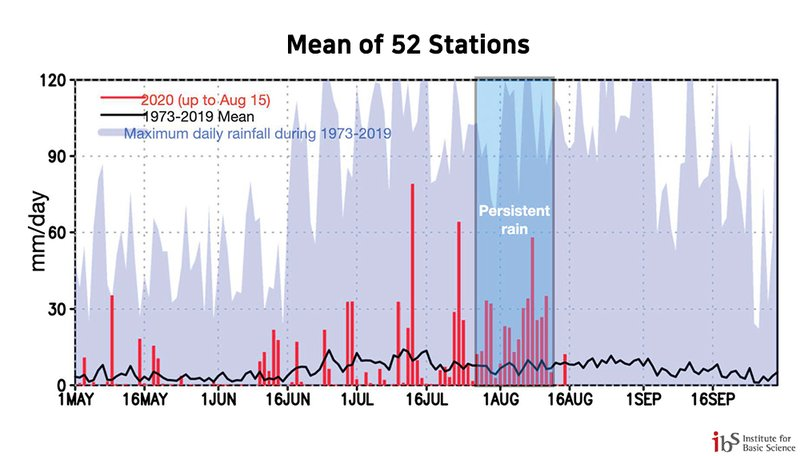
- Rainfall measurements
- 강수량 예측
- 우량계를 통해 강우심도, 강우강도 측정
- 초단기 강수량, 월별, 연도별, 계절별 강수량 분석 가능
- 한국 52개 관측소 일강수량
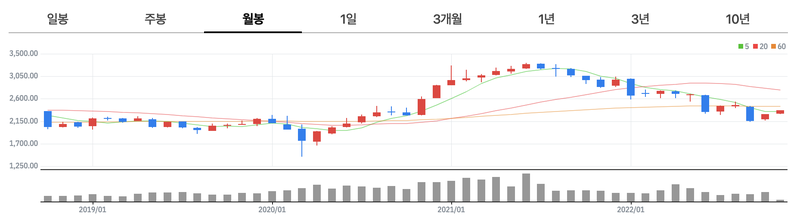
- Stock prices
- 주가 예측
- 장단기 주가 예측
- candle chart 사용
- 거래자가 지정한 시가, 종가, 고가, 저가 표시
- 과거 패턴 기반 가격 움직임 결정에 사용
- 네이버 KOSPI 월봉
- 주가 예측
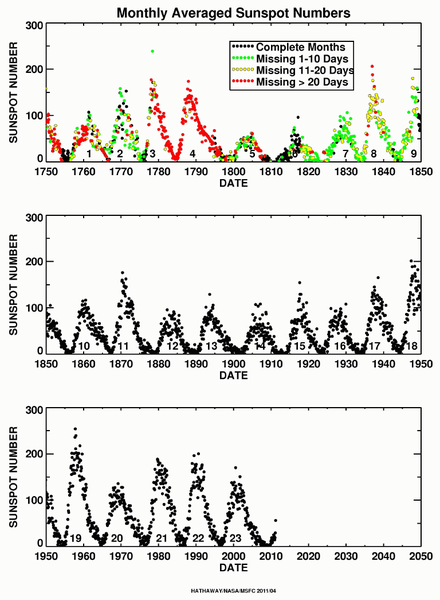
- Number of sunspots
- 태양의 흑점 수
- 태양풍 및 우주 물리적 현상의 이해를 위해 태양 표면 흑점을 측정 및 활용
- 태양 표면에 존재하는 흑점 및 흑점 그룹수를 나타낸 시계열 데이터
- 태양의 흑점 수
{kind=link}
- Annual retail sales
- 연간 소매 판매
- 소매 단계의 총 판매액 변동 측정
- 기업에서의 매출 상승을 위한 판매 전략 혹은 상권 변환 예측 분석 지표로 활용
- Korea annual retail sales
- 연간 소매 판매

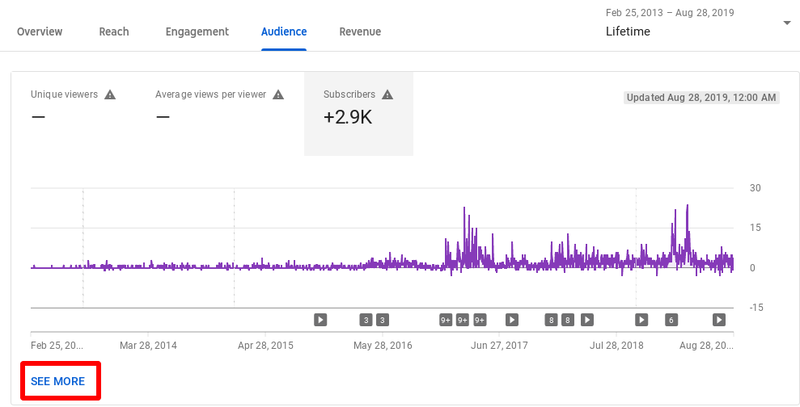
- Monthly subscribers
- 월 구독자수
- 실시간 일, 월 평균 구독자 증가 및 하락으로 -> 채널 성장 예측
- 영상 조회수 분석으로 영상의 인기도 측정 및 채널 성장의 지표로 활용
- 유튜브 스튜디오 Lifetime 구독자 수
- 월 구독자수
- Heartbeats per minute
- 분당 심장 박동수
- 심장 질환 예측에 활용
- ECG Rate Interpretation
- 분당 심장 박동수

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️