
2-1. 들어가며
학습 목표
- 범주형 데이터의 전처리
- 수치형 데이터의 전처리
- 머신러닝을 이용한 예측
2-2. 사이킷런 활용하기
사이킷런?
- python을 이용한 머신러닝 툴(도구)
- 데이터 분석 및 예측을 위한 툴
- 오픈 소스
- 사용이 쉽다는 장점이 있음.
- 학습 : fit, 예측 : predict
사이킷런의 용도
- 분류(ex. 스팸인지 아닌지)
- 회귀(ex. 가격 예측)
- 클러스터링 (ex. 고객 세그먼트)
- 비지도 학습
- 차원축소 (ex. 컬럼 수 간소화)
- 모델 선택 (ex. 모델 튜닝, 평가)
- 전처리 (ex. 데이터 가공/변환)
실습
- 데이터 불러오기(final_modudak.csv)
- 데이터 변경(기존 2가지 원산지, 별도의 1가지 원산지 추가)
- 활용 데이터 선택
2-3. 데이터 전처리: 범주형 데이터
type 확인

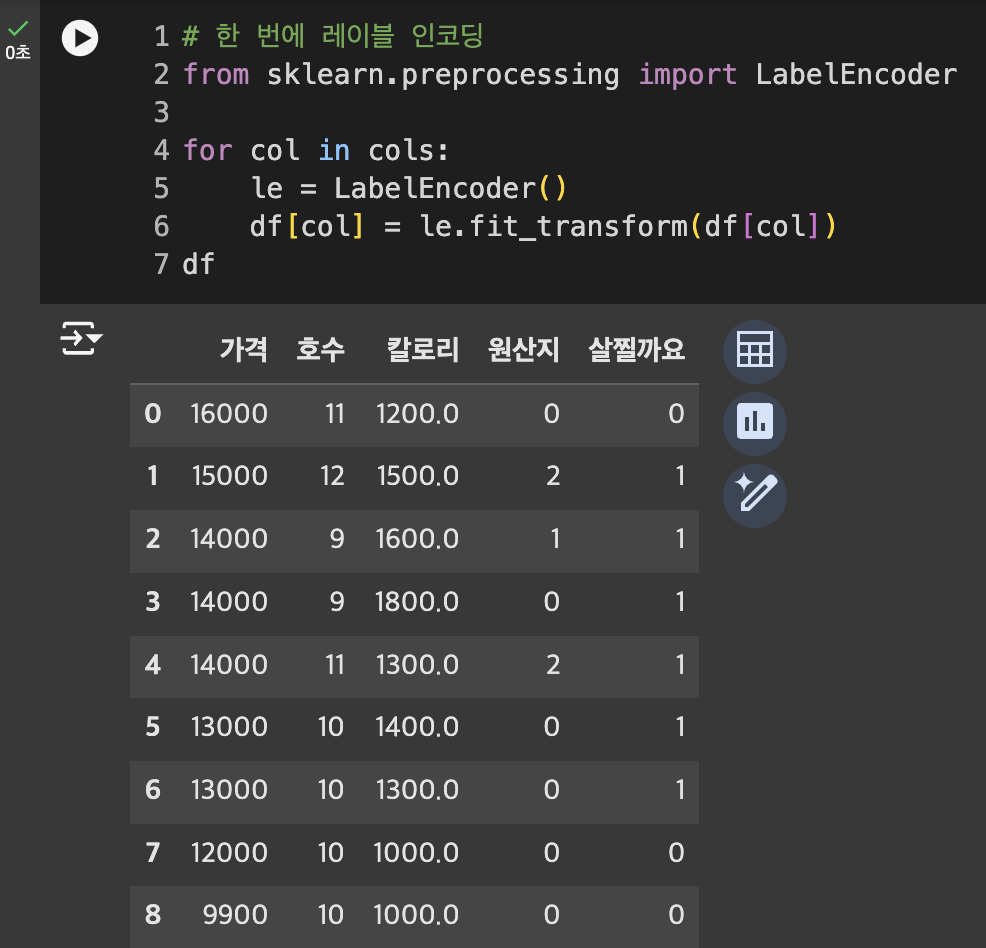
레이블 인코딩
각 고유값에 -> 고유 숫자 부여
-
라이브러리 불러오기 & 레이블 인코딩 준비
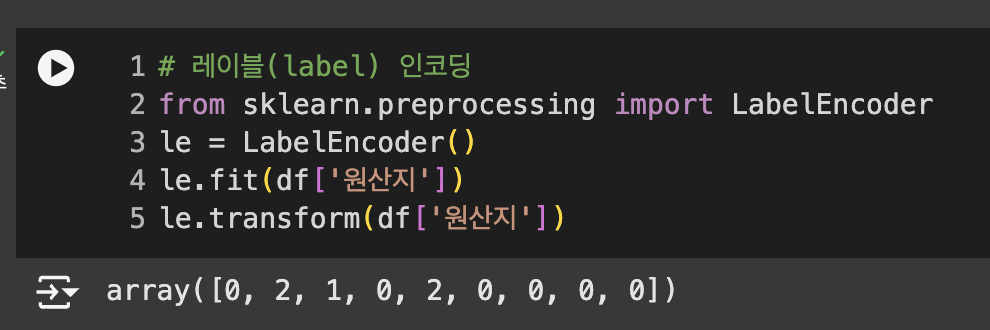
-
fit_transform: 한번에 학습한 결과 출력
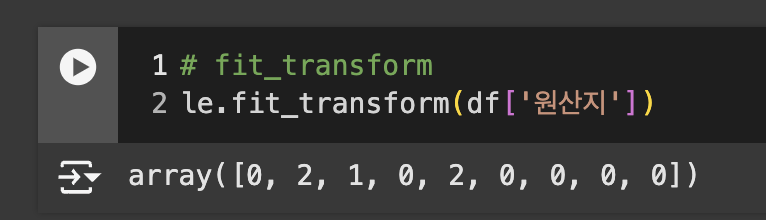
-
확인
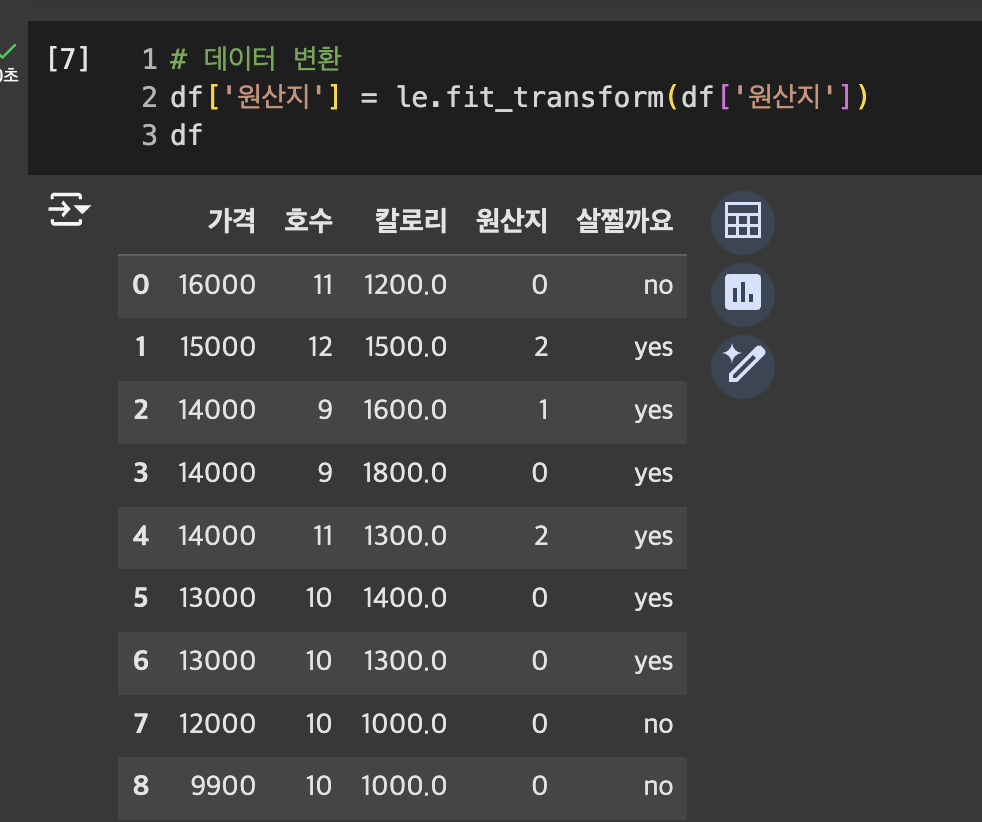
-
'살찔까요' 레이블 인코딩
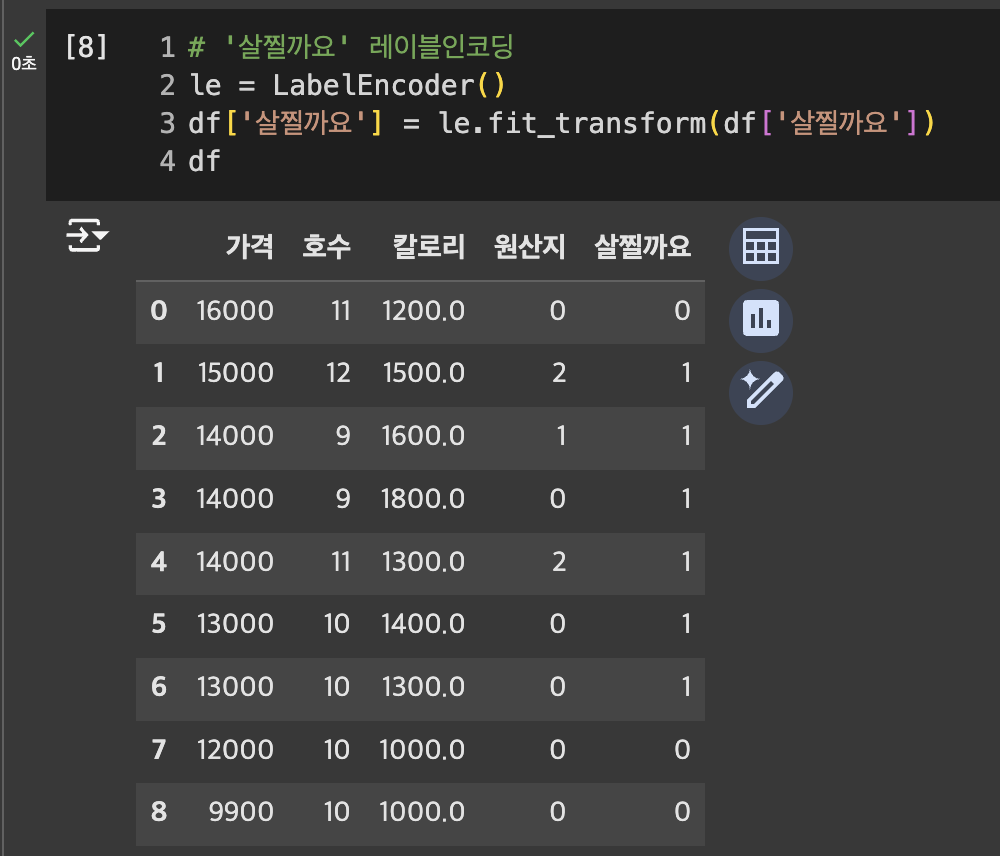
-
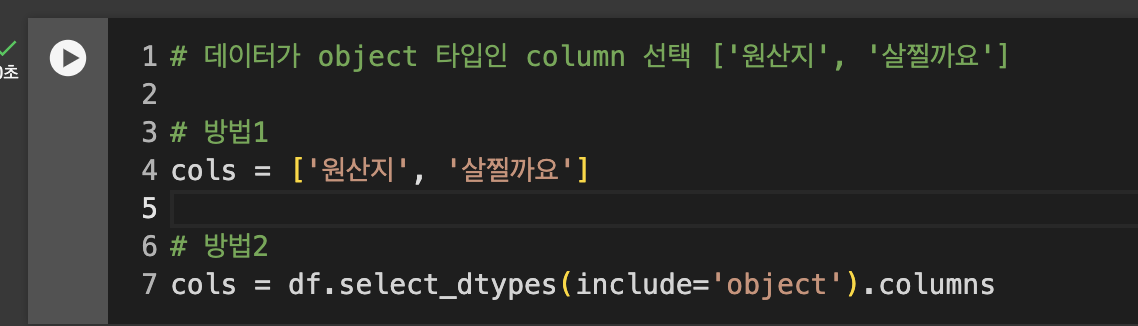
여러 컬럼 인코딩
cols = df.select_dtypes(include='object').columns
-
반복문 사용
원핫 인코딩
새 컬럼을 만듦(해당 컬럼이 맞으면 1, 아니면 0으로 채워짐)
-
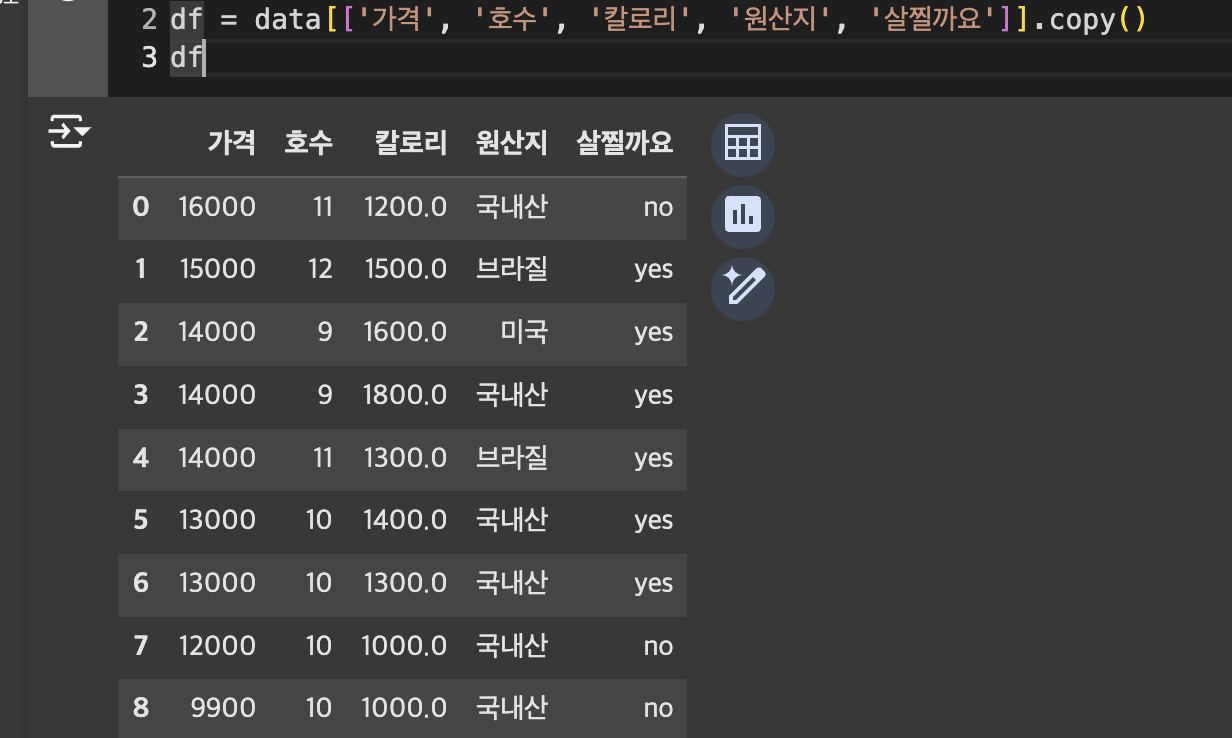
활용 데이터
-
원핫인코딩
- sparse는 sparse_output으로 이름 변경됨.
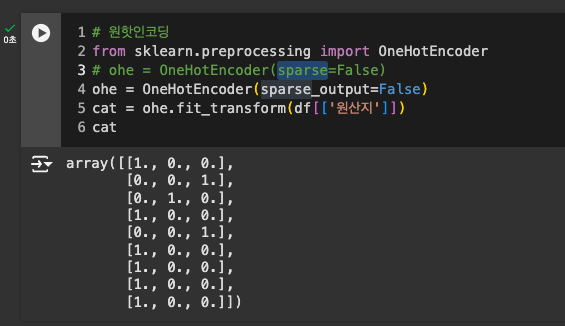
- sparse는 sparse_output으로 이름 변경됨.
-
카테고리 확인
_

- 피쳐 이름 및 카테고리

-
데이터 프레임으로 변환 & 합치기
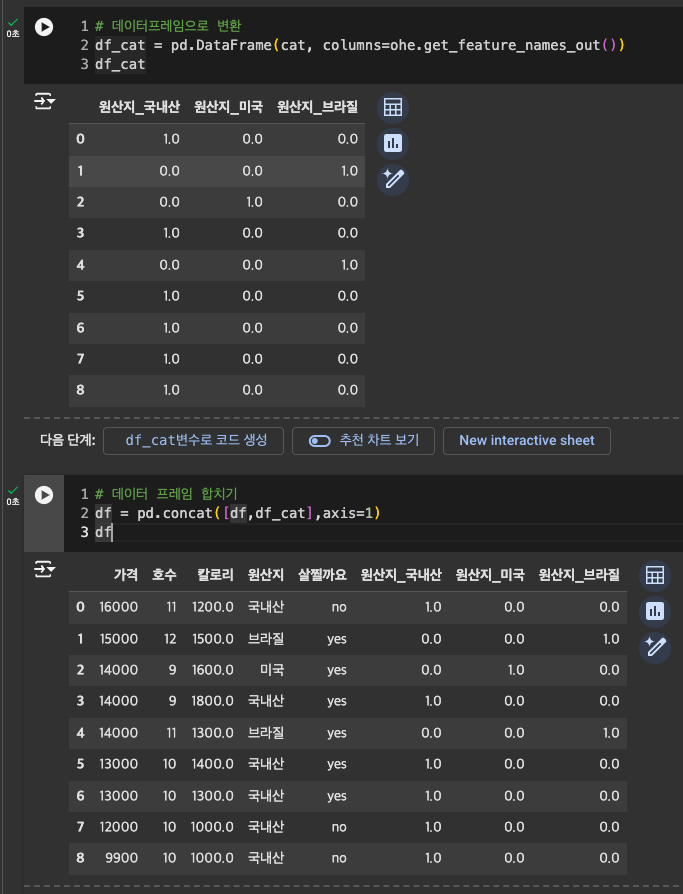
-
원본 컬럼은 삭제
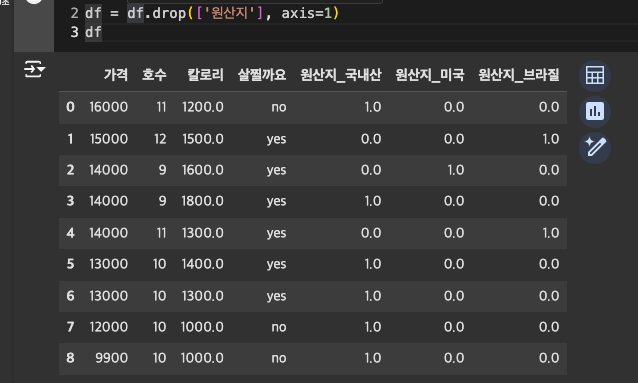
-
여러 컬럼 인코딩(앞, 뒤 과정은 1개 컬럼 인코딩 시와 동일)
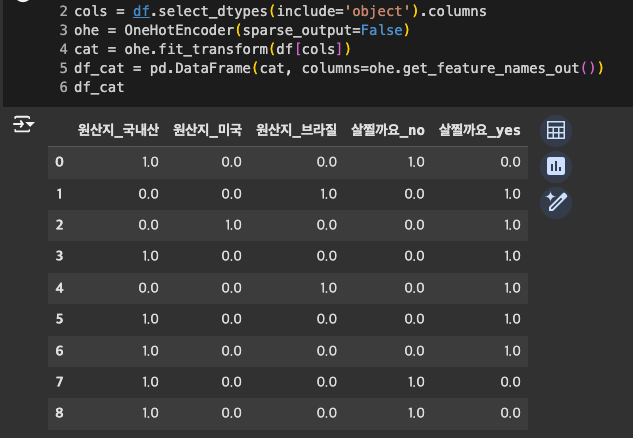
판다스로 원핫인코딩 한번에 하자!
pd.get_dummies()
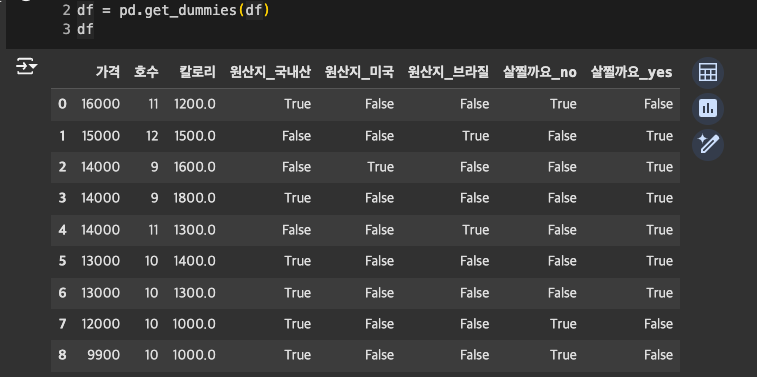
2-4. 데이터 전처리: 수치형 데이터
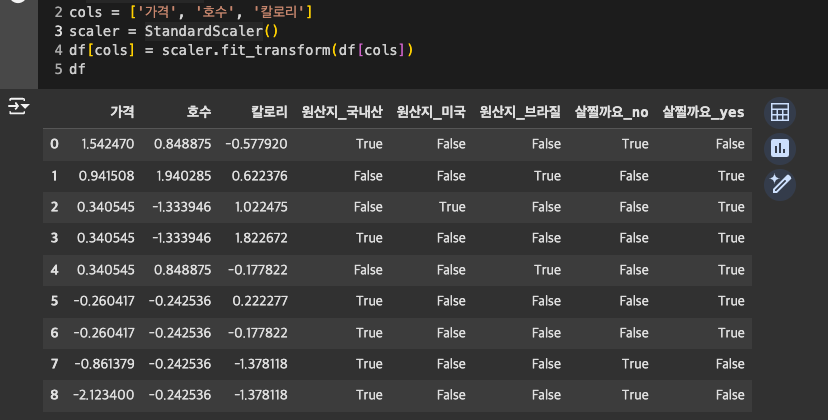
표준화(StandardScaler)
-
평균 0, 분산 1인 표준정규분포로 변환
-
StandardScaler 임포트하여 바로 사용
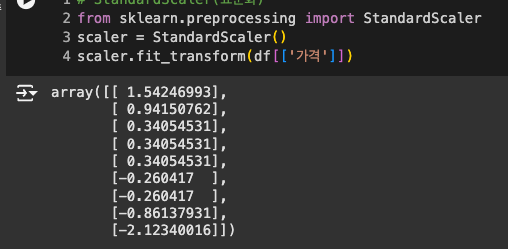
-
여러 컬럼에 적용
정규화(MinMaxScaler)
- 데이터 값을 0~1로 축소
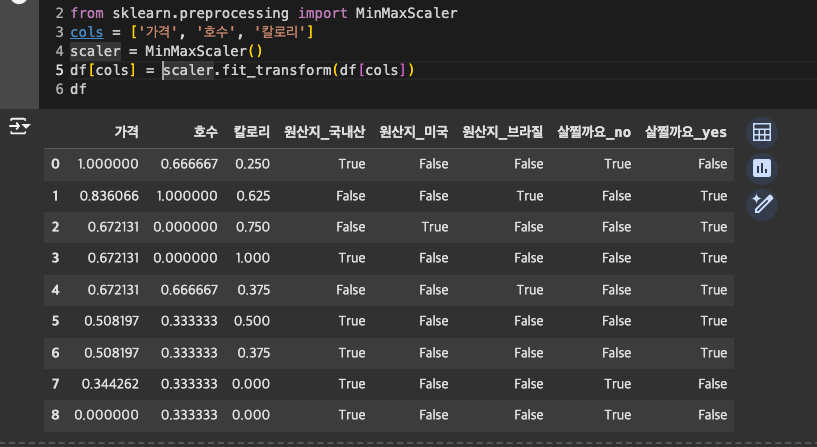
2-5. 사이킷런에서 제공하는 데이터셋
유방암 데이터
-
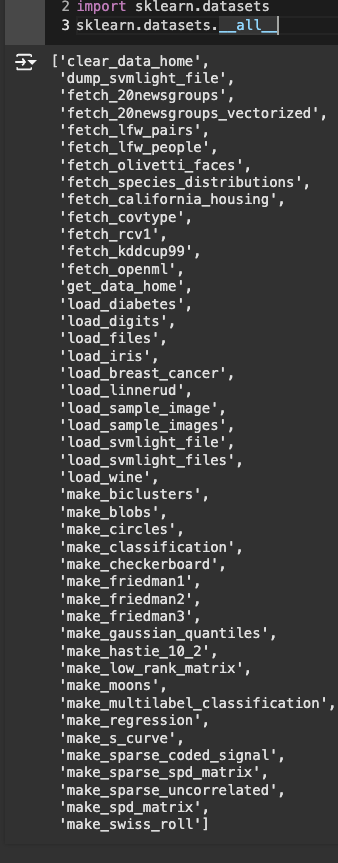
사이킷런 데이터 불러오기

- data

- target, frame, target_names

- DESCR, feature_names, filename, data_module
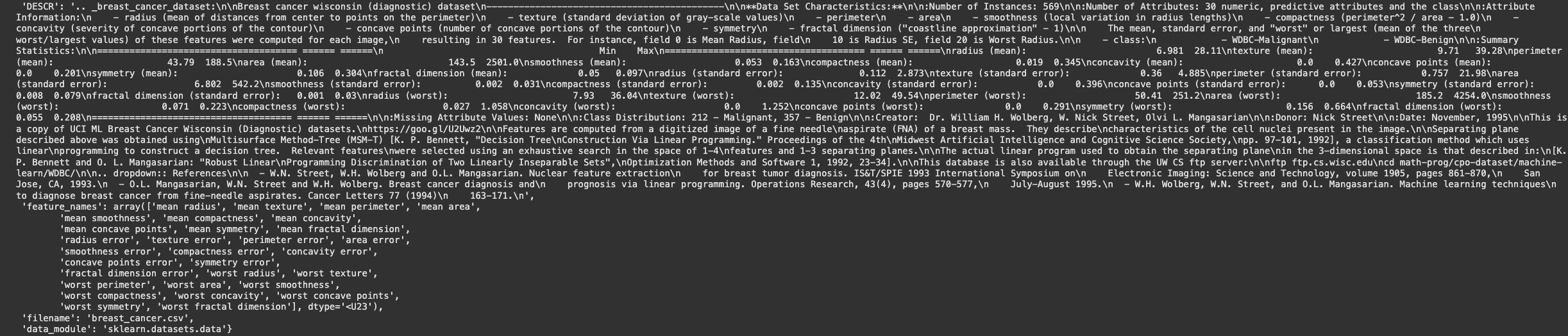
- data
-
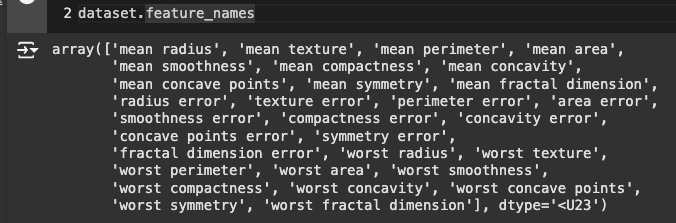
피처 이름 확인 :
.feature_names
-
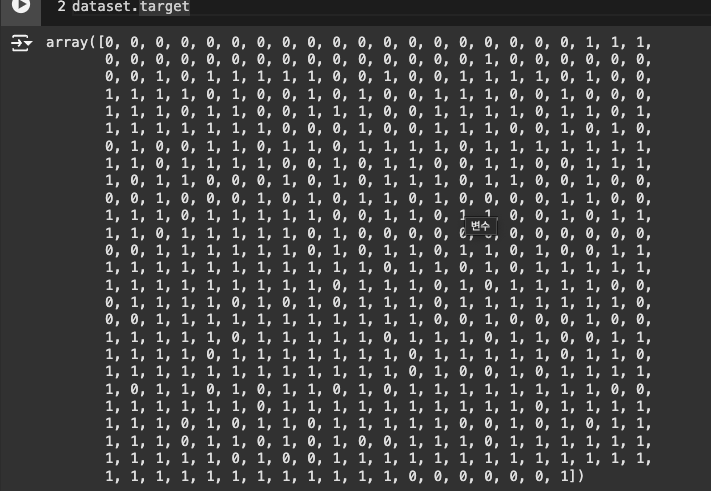
타겟 확인 :
.target
-
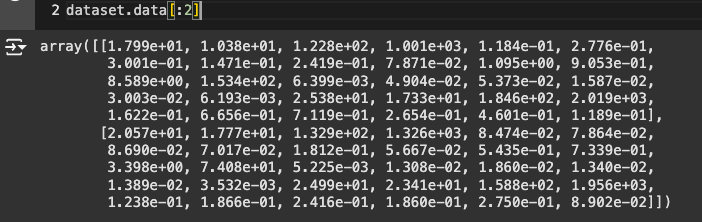
데이터 확인
-
데이터프레임으로 변환

-
타겟 추가

-
데이터셋 확인
당뇨병 데이터
-
당뇨병 데이터

-
데이터 프레임으로 변환
diabetes_df = pd.DataFrame(data=dataset.data, columns=dataset.feature_names)
- 타겟 추가
diabetes_df['target'] = dataset.target
2-6. 머신러닝
분류
검증데이터 분리

-
X : train 데이터 확인

-
y : train 데이터 확인
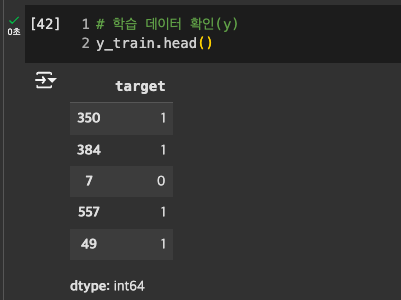
-
데이터 사이즈

의사결정나무(DecisionTree)
분류 ➡️ 모델 선택 ➡️ 학습&예측순서

평가(accuracy)
accuracy_score(실제값, 예측값)

회귀
검증데이터 분리
-
test_size=0.3: 데이터를 학습용 70%, 테스트용 30%로 설정 -
random_state: 랜덤값 고정해서 같은 결과 빼낼 때 사용

-
X : train 데이터 확인

-
y : train 데이터 확인
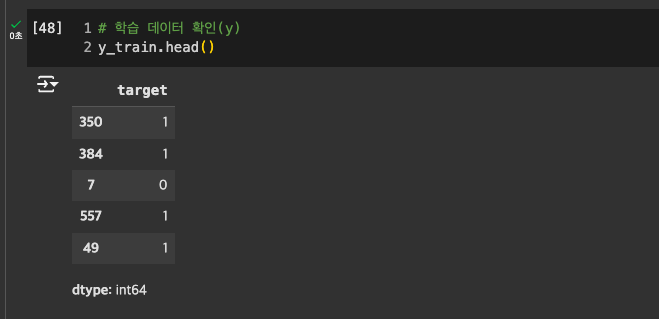
-
데이터 사이즈

선형회귀 (LinearRegression)
회귀 ➡️ 모델 선택 ➡️ 학습&예측순서
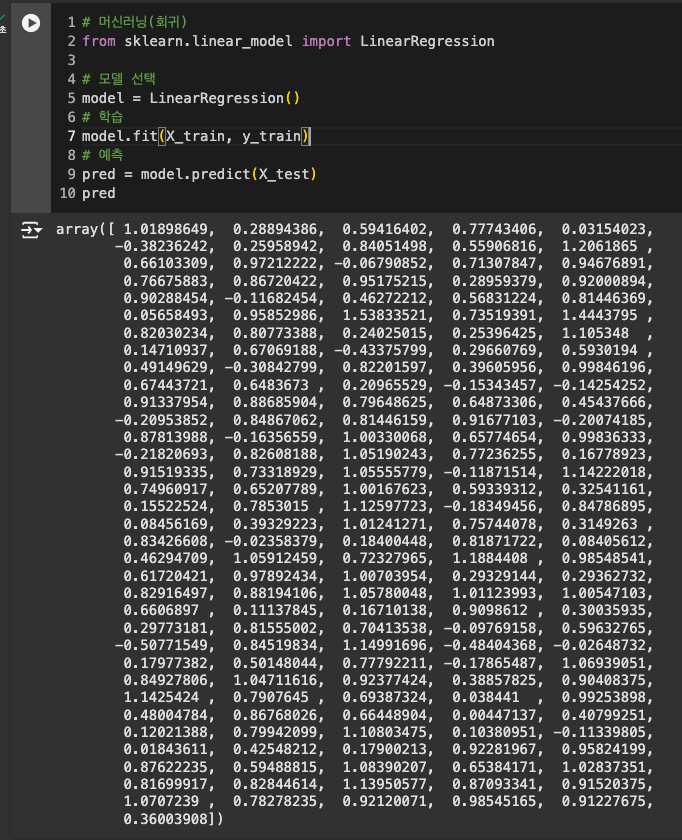
평가(MSE)
mean_squared_error(실제값, 예측값)

2-7. 공식문서 소개
- 현재, 공식문서에서는 튜토리얼이 삭제되었으나 "한글 번역본"이 있는 상태
🔗 scikit-learn-korean

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️