
11-1. 들어가며
학습 목표
- Fashion MNIST 데이터셋: 딥러닝 모델 실습
- 모델 최적화: 딥러닝 모델 학습 기술 및 최적화 실습
11-2. Fashion MNIST 모델
Fashion MNIST

- MNIST 손글씨 숫자 인식 유사
- 패션 이미지 -> 10개 종류
- 손글씨 숫자 인식보다는 어려운 형태
데이터 로드
fashion_mnistimporttrain_test_split(): 학습용 데이터셋 중 30%를 검증 데이터셋으로 만듦
from tensorflow.keras.datasets import fashion_mnist
from sklearn.model_selection import train_test_split
(x_train_full, y_train_full), (x_test, y_test) = fashion_mnist.load_data()
x_train, x_val, y_train, y_val = train_test_split(x_train_full, y_train_full,
test_size=0.3,
random_state=123)
print(f"전체 학습 데이터: {x_train_full.shape} 레이블: {y_train_full.shape}")
print(f"학습 데이터: {x_train.shape} 레이블: {y_train.shape}")
print(f"검증 데이터: {x_val.shape} 레이블: {y_val.shape}")
print(f"테스트 데이터: {x_test.shape} 레이블: {y_test.shape}")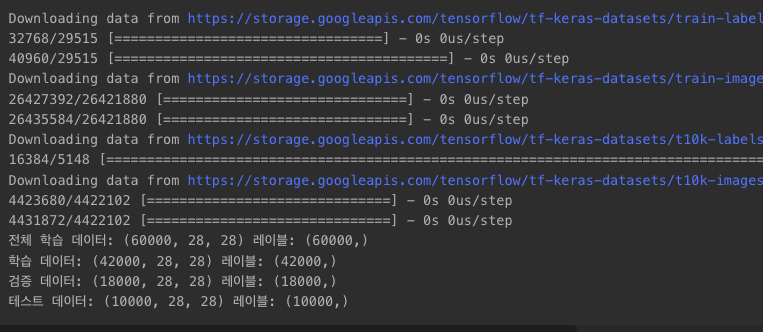
class_names: 10개의 클래스 이름 저장
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
class_names
- y_train의 0번째 : 6 -> 실제로는
Shirt출력!
print(y_train[0], class_names[y_train[0]])
x_train0번째 구성 확인
print(x_train[0])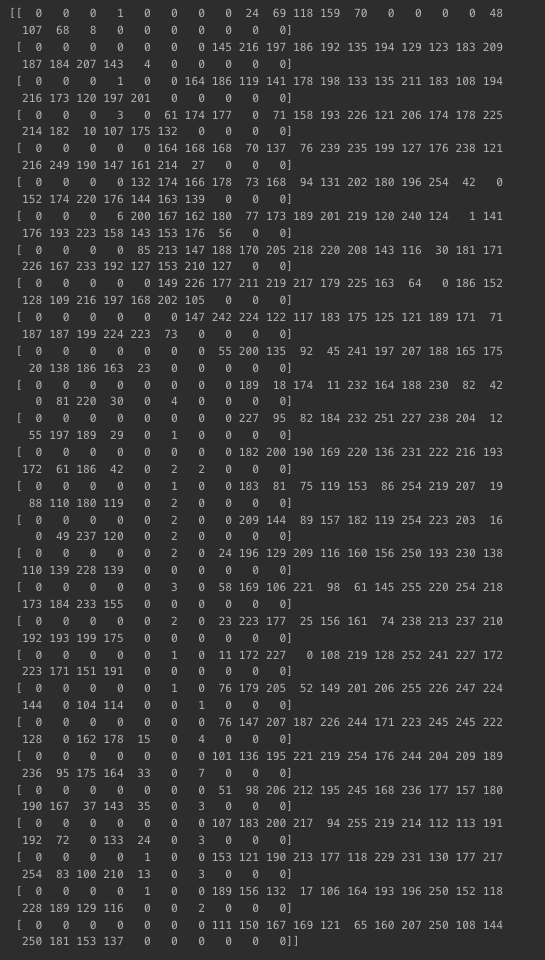
colorbar(): 값 범위 확인- 이미지 : 0 ~ 255 ->
imshow()로 출력
- 이미지 : 0 ~ 255 ->
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
plt.figure()
plt.imshow(x_train[0])
plt.colorbar()
plt.show()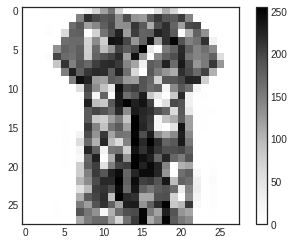
- 전체 학습 데이터 60,000개 중 랜덤 4개 선택
- 인덱스, 레이블, 패션 이미지 출력
import numpy as np
num_sample = 4
random_idxs = np.random.randint(60000, size=num_sample)
plt.figure(figsize=(15, 10))
for i, idx in enumerate(random_idxs):
image = x_train_full[idx, :]
label = y_train_full[idx]
plt.subplot(1, len(random_idxs), i+1)
plt.imshow(image)
plt.title(f'Index: {idx}, Label: {class_names[label]}')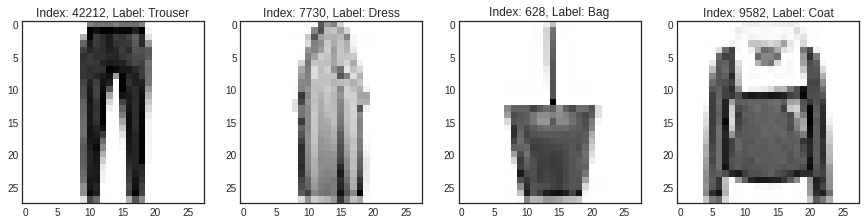
데이터 전처리
- 데이터셋 기본 구성
- 28 x 28
- 학습 데이터 42,000개
- 검증 데이터 18,000개
- 테스트 데이터 10,000개
print(x_train.shape)
print(x_val.shape)
print(x_test.shape)
reshape(): 784(28 x 28)로 모양 바꾸기- 훈련 데이터, 검증 데이터, 테스트 데이터 : 28 x 28로만 지정(나머지는 -1)
x_train = x_train.reshape(-1, 28 * 28)
x_val = x_val.reshape(-1, 28 * 28)
x_test = x_test.reshape(-1, 28 * 28)
print(x_train.shape)
print(x_val.shape)
print(x_test.shape)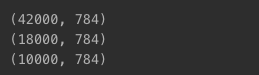
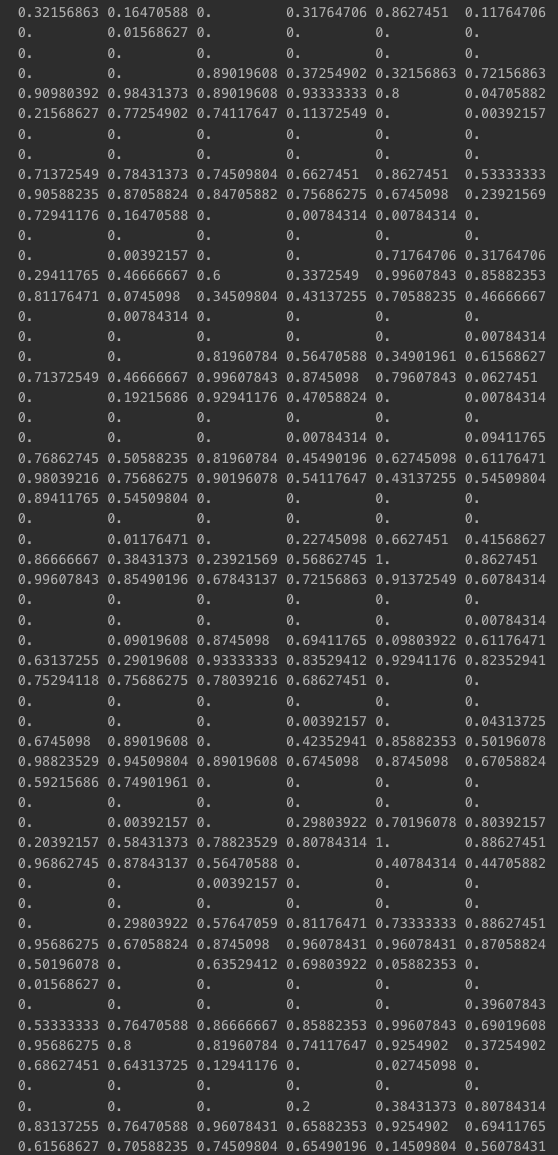
- 학습 데이터 양 줄일 필요 있음
- 0~255 사이값이기 때문
print(x_train[0])
- 0~1 범위로 스케일링
x_train = x_train / 255.
x_val = x_val / 255.
x_test = x_test / 255.
print(x_train[0])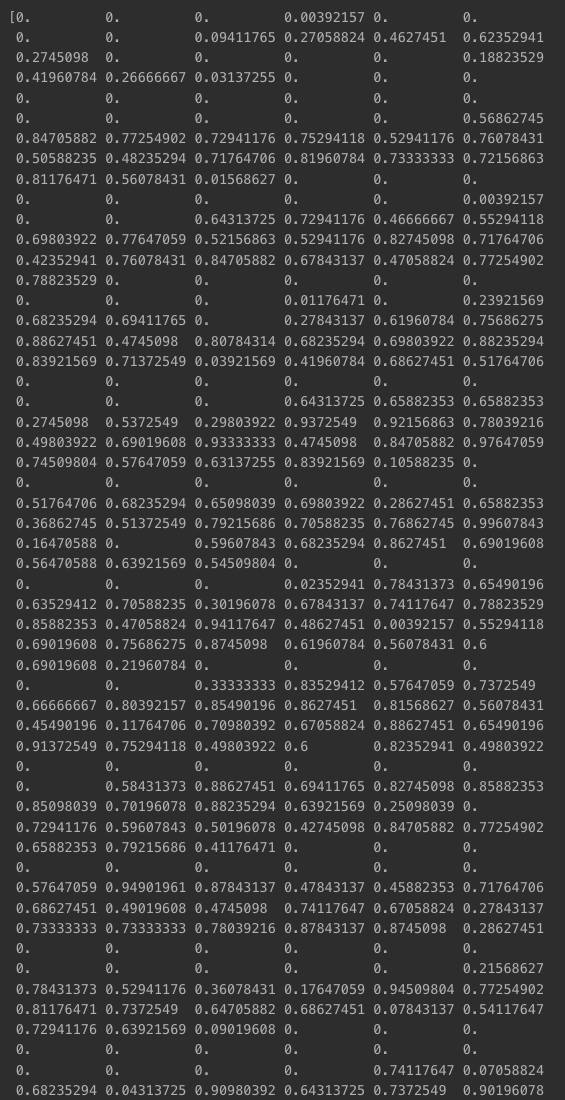

모델 구성
- Sequential()
- 첫번째 레이어
Input: 전처리 형태 유지(784) - 두번째 레이어 : 유닛수 512개, 활성화 함수 sigmoid
- 마지막 레이어 : 유닛수 10개(클래스 개수), 활성화 함수 softmax
- 첫번째 레이어
from tensorflow.keras import models, layers
model = models.Sequential()
model.add(layers.Input(shape=(784, )))
model.add(layers.Dense(512, activation='sigmoid'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
모델 컴파일 및 학습
- 옵티마이저 : SGD
- 손실 함수 : sparse_categorical_crossentropy(다중 분류, 레이블 정수 형태)
- 지표 : accuracy
model.compile(loss='sparse_categorical_crossentropy',
optimizer='SGD',
metrics=['accuracy'])- 데이터셋 분리
- 학습용 데이터셋 : x_train, y_train
- 에폭(epochs) : 60
- 배치 사이즈 : 512
- 검증용 데이터 : x_val, y_val
history = model.fit(x_train, y_train,
epochs=60,
batch_size=512,
validation_data=(x_val, y_val))Epoch 1/60
83/83 [==============================] - 17s 8ms/step - loss: 2.1737 - accuracy: 0.3718 - val_loss: 2.0145 - val_accuracy: 0.4675
Epoch 2/60
83/83 [==============================] - 0s 4ms/step - loss: 1.8944 - accuracy: 0.5748 - val_loss: 1.7866 - val_accuracy: 0.5638
Epoch 3/60
83/83 [==============================] - 0s 4ms/step - loss: 1.6955 - accuracy: 0.6352 - val_loss: 1.6102 - val_accuracy: 0.6411
Epoch 4/60
83/83 [==============================] - 0s 4ms/step - loss: 1.5374 - accuracy: 0.6697 - val_loss: 1.4707 - val_accuracy: 0.6759
Epoch 5/60
83/83 [==============================] - 0s 4ms/step - loss: 1.4118 - accuracy: 0.6882 - val_loss: 1.3597 - val_accuracy: 0.6808
Epoch 6/60
83/83 [==============================] - 0s 4ms/step - loss: 1.3118 - accuracy: 0.6996 - val_loss: 1.2690 - val_accuracy: 0.6871
Epoch 7/60
83/83 [==============================] - 0s 4ms/step - loss: 1.2306 - accuracy: 0.7055 - val_loss: 1.1968 - val_accuracy: 0.6912
Epoch 8/60
83/83 [==============================] - 0s 4ms/step - loss: 1.1641 - accuracy: 0.7098 - val_loss: 1.1373 - val_accuracy: 0.6944
Epoch 9/60
83/83 [==============================] - 0s 4ms/step - loss: 1.1090 - accuracy: 0.7158 - val_loss: 1.0847 - val_accuracy: 0.7136
Epoch 10/60
83/83 [==============================] - 0s 4ms/step - loss: 1.0624 - accuracy: 0.7209 - val_loss: 1.0428 - val_accuracy: 0.7069
Epoch 11/60
83/83 [==============================] - 0s 4ms/step - loss: 1.0228 - accuracy: 0.7213 - val_loss: 1.0049 - val_accuracy: 0.7245
Epoch 12/60
83/83 [==============================] - 0s 4ms/step - loss: 0.9882 - accuracy: 0.7266 - val_loss: 0.9769 - val_accuracy: 0.7190
Epoch 13/60
83/83 [==============================] - 0s 4ms/step - loss: 0.9584 - accuracy: 0.7295 - val_loss: 0.9461 - val_accuracy: 0.7230
Epoch 14/60
83/83 [==============================] - 0s 4ms/step - loss: 0.9322 - accuracy: 0.7303 - val_loss: 0.9203 - val_accuracy: 0.7312
Epoch 15/60
83/83 [==============================] - 0s 4ms/step - loss: 0.9087 - accuracy: 0.7338 - val_loss: 0.8993 - val_accuracy: 0.7332
Epoch 16/60
83/83 [==============================] - 0s 3ms/step - loss: 0.8879 - accuracy: 0.7353 - val_loss: 0.8792 - val_accuracy: 0.7339
Epoch 17/60
83/83 [==============================] - 0s 4ms/step - loss: 0.8693 - accuracy: 0.7380 - val_loss: 0.8622 - val_accuracy: 0.7347
Epoch 18/60
83/83 [==============================] - 0s 4ms/step - loss: 0.8524 - accuracy: 0.7396 - val_loss: 0.8487 - val_accuracy: 0.7359
Epoch 19/60
83/83 [==============================] - 0s 4ms/step - loss: 0.8369 - accuracy: 0.7429 - val_loss: 0.8334 - val_accuracy: 0.7365
Epoch 20/60
83/83 [==============================] - 0s 4ms/step - loss: 0.8231 - accuracy: 0.7438 - val_loss: 0.8191 - val_accuracy: 0.7397
Epoch 21/60
83/83 [==============================] - 0s 3ms/step - loss: 0.8100 - accuracy: 0.7456 - val_loss: 0.8059 - val_accuracy: 0.7433
Epoch 22/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7981 - accuracy: 0.7469 - val_loss: 0.7940 - val_accuracy: 0.7461
Epoch 23/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7872 - accuracy: 0.7490 - val_loss: 0.7907 - val_accuracy: 0.7326
Epoch 24/60
83/83 [==============================] - 0s 3ms/step - loss: 0.7772 - accuracy: 0.7489 - val_loss: 0.7752 - val_accuracy: 0.7482
Epoch 25/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7674 - accuracy: 0.7518 - val_loss: 0.7653 - val_accuracy: 0.7496
Epoch 26/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7585 - accuracy: 0.7525 - val_loss: 0.7569 - val_accuracy: 0.7521
Epoch 27/60
83/83 [==============================] - 0s 3ms/step - loss: 0.7500 - accuracy: 0.7552 - val_loss: 0.7494 - val_accuracy: 0.7527
Epoch 28/60
83/83 [==============================] - 0s 3ms/step - loss: 0.7422 - accuracy: 0.7562 - val_loss: 0.7418 - val_accuracy: 0.7532
Epoch 29/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7349 - accuracy: 0.7583 - val_loss: 0.7363 - val_accuracy: 0.7516
Epoch 30/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7279 - accuracy: 0.7587 - val_loss: 0.7285 - val_accuracy: 0.7549
Epoch 31/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7213 - accuracy: 0.7597 - val_loss: 0.7211 - val_accuracy: 0.7565
Epoch 32/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7151 - accuracy: 0.7611 - val_loss: 0.7155 - val_accuracy: 0.7575
Epoch 33/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7091 - accuracy: 0.7629 - val_loss: 0.7106 - val_accuracy: 0.7629
Epoch 34/60
83/83 [==============================] - 0s 4ms/step - loss: 0.7034 - accuracy: 0.7642 - val_loss: 0.7046 - val_accuracy: 0.7615
Epoch 35/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6980 - accuracy: 0.7643 - val_loss: 0.7006 - val_accuracy: 0.7628
Epoch 36/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6929 - accuracy: 0.7658 - val_loss: 0.6971 - val_accuracy: 0.7584
Epoch 37/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6880 - accuracy: 0.7664 - val_loss: 0.6895 - val_accuracy: 0.7653
Epoch 38/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6831 - accuracy: 0.7682 - val_loss: 0.6878 - val_accuracy: 0.7654
Epoch 39/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6786 - accuracy: 0.7694 - val_loss: 0.6809 - val_accuracy: 0.7673
Epoch 40/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6743 - accuracy: 0.7701 - val_loss: 0.6767 - val_accuracy: 0.7674
Epoch 41/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6698 - accuracy: 0.7714 - val_loss: 0.6732 - val_accuracy: 0.7682
Epoch 42/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6657 - accuracy: 0.7721 - val_loss: 0.6687 - val_accuracy: 0.7701
Epoch 43/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6620 - accuracy: 0.7734 - val_loss: 0.6649 - val_accuracy: 0.7717
Epoch 44/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6581 - accuracy: 0.7740 - val_loss: 0.6608 - val_accuracy: 0.7727
Epoch 45/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6544 - accuracy: 0.7753 - val_loss: 0.6571 - val_accuracy: 0.7731
Epoch 46/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6509 - accuracy: 0.7768 - val_loss: 0.6553 - val_accuracy: 0.7729
Epoch 47/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6474 - accuracy: 0.7777 - val_loss: 0.6508 - val_accuracy: 0.7747
Epoch 48/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6441 - accuracy: 0.7791 - val_loss: 0.6483 - val_accuracy: 0.7764
Epoch 49/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6409 - accuracy: 0.7797 - val_loss: 0.6454 - val_accuracy: 0.7788
Epoch 50/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6377 - accuracy: 0.7803 - val_loss: 0.6420 - val_accuracy: 0.7771
Epoch 51/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6347 - accuracy: 0.7810 - val_loss: 0.6393 - val_accuracy: 0.7802
Epoch 52/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6317 - accuracy: 0.7817 - val_loss: 0.6363 - val_accuracy: 0.7793
Epoch 53/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6287 - accuracy: 0.7833 - val_loss: 0.6373 - val_accuracy: 0.7770
Epoch 54/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6261 - accuracy: 0.7840 - val_loss: 0.6303 - val_accuracy: 0.7809
Epoch 55/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6231 - accuracy: 0.7847 - val_loss: 0.6275 - val_accuracy: 0.7829
Epoch 56/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6204 - accuracy: 0.7862 - val_loss: 0.6270 - val_accuracy: 0.7808
Epoch 57/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6178 - accuracy: 0.7867 - val_loss: 0.6229 - val_accuracy: 0.7824
Epoch 58/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6154 - accuracy: 0.7875 - val_loss: 0.6209 - val_accuracy: 0.7835
Epoch 59/60
83/83 [==============================] - 0s 3ms/step - loss: 0.6128 - accuracy: 0.7886 - val_loss: 0.6186 - val_accuracy: 0.7861
Epoch 60/60
83/83 [==============================] - 0s 4ms/step - loss: 0.6103 - accuracy: 0.7888 - val_loss: 0.6159 - val_accuracy: 0.7868- 시각화 함수 정의
def show_history(history):
history_dict = history.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(loss) + 1)
fig = plt.figure(figsize=(12, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, loss, 'b-', label='train_loss')
ax1.plot(epochs, val_loss, 'r-', label='val_loss')
ax1.set_title('Train and Validation Loss')
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Loss')
ax1.grid()
ax1.legend()
accuracy = history_dict['accuracy']
val_accuracy = history_dict['val_accuracy']
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, accuracy, 'b-', label='train_accuracy')
ax2.plot(epochs, val_accuracy, 'r-', label='val_accuracy')
ax2.set_title('Train and Validation Accuracy')
ax2.set_xlabel('Epochs')
ax2.set_ylabel('Accuracy')
ax2.grid()
ax2.legend()
plt.show()- 시각화
show_history(history)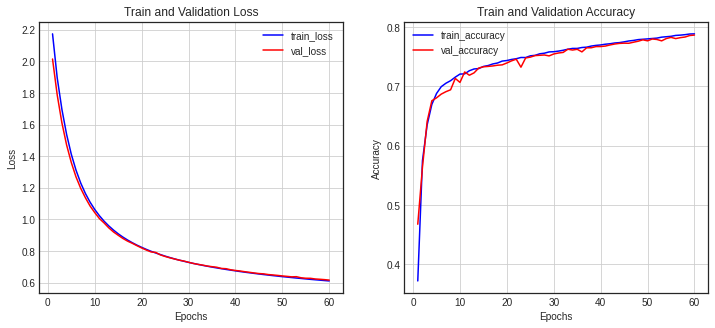
모델 평가 및 예측
평가
- 테스트 데이터셋 : x_test, y_test ->
evaluate()실행- 실행 결과 : loss, accuracy
model.evaluate(x_test, y_test)
예측
predict()- 테스트 데이터셋 x_test의 모델 예측 결과 : pred_ys의 5번째 출력해 클래스 10개 당 예측 비율 확인 가능
argmax()- 클래스 10개 각 값 중 가장 큰 값 위치 반환
- 결과는
arg_pred_y에 저장 - 예시 : 5번째 출력 -> 1이 나올 것
- 인덱스 1의 클래스가 무엇인지 : Trouser 출력될 것
pred_ys = model.predict(x_test)
print(pred_ys[5])
arg_pred_y = np.argmax(pred_ys, axis=1)
print(arg_pred_y[5])
print(class_names[arg_pred_y[5]])
- 이미지, 모델 예측 결과값 같이 출력
- 바지 이미지 및 예측 결과 출력될 것
plt.imshow(x_test[5].reshape(-1, 28))
plt.title(class_names[arg_pred_y[5]])
plt.show()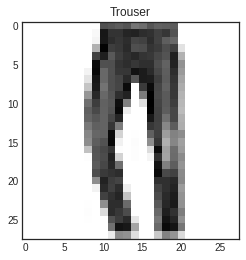
plot_image()- 이미지와 레이블 같이 출력
- 테스트 데이터셋 정답(y_test)과 이미지에 대한 i번째 출력
- 예측 결과 레이블(predicted_label) = 정답 레이블(y_test) ➡️ blue
- 예측 결과 레이블(predicted_label) ≠ 정답 레이블(y_test) ➡️ red
def plot_image(i, pred_ys, y_test, img):
pred_ys, y_test, img = pred_ys[i], y_test[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(pred_ys)
if predicted_label == y_test:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(pred_ys),
class_names[y_test]), color=color)plot_class()- 전체 10개 클래스 중 어떤 클래스에 얼만큼의 확률에 의한 예측이 되었는지 알려주는 함수
- 예측 결과 레이블(pred_ys)과 정답 레이블(true_label)에서의 i번째 데이터에 대한 10개 클래스 값을 시각화해 확인
- 예측한 레이블 : red, 정답 레이블 : blue
def plot_class(i, pred_ys, true_label):
pred_ys, true_label = pred_ys[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.ylim([0, 1])
predicted_label = np.argmax(pred_ys)
plot = plt.bar(range(10), pred_ys, color='darkgray')
plot[predicted_label].set_color('red')
plot[true_label].set_color('blue')- 5번째 데이터 확인
- plot_image(), plot_class() 호출
i = 5
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plot_image(i, pred_ys, y_test, x_test.reshape(-1, 28, 28))
plt.subplot(1, 2, 2)
plot_class(i, pred_ys, y_test)
plt.show()
결과 : 95% 확률로 Trouser 예측 성공
- 10번째 데이터
i = 10
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plot_image(i, pred_ys, y_test, x_test.reshape(-1, 28, 28))
plt.subplot(1, 2, 2)
plot_class(i, pred_ys, y_test)
plt.show()
결과 : 모델이 Pullover로 예측 -> 실제로는 Coat임(예측 실패)
- 예측 결과 여러 개 한번에 확인
- 32(8x4)
num_rows = 8
num_cols = 4
num_images = num_rows * num_cols
random_num = np.random.randint(10000, size=num_images)
plt.figure(figsize=(2 * 2 * num_cols, 2 * num_rows))
for idx, num in enumerate(random_num):
plt.subplot(num_rows, 2 * num_cols, 2 * idx + 1)
plot_image(num, pred_ys, y_test, x_test.reshape(-1, 28, 28))
plt.subplot(num_rows, 2 * num_cols, 2 * idx + 2)
plot_class(num, pred_ys, y_test)
plt.show()
classification_report- 분류 모델 결과를 10개 분류 기준별 precision, recall, f1-score, support 출력
from tensorflow.keras import utils
from sklearn.metrics import classification_report
y_test_cat = utils.to_categorical(y_test)
print(classification_report(np.argmax(y_test_cat, axis=-1),
np.argmax(pred_ys, axis=-1),
target_names=class_names))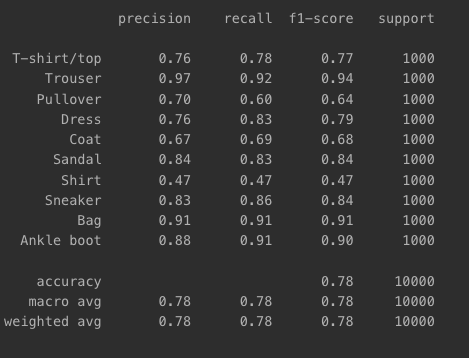
confusion_matrix- 예측 레이블과 실제 레이블 일치 여부
- 혼동 행렬(confusion matrix)로 시각화
import seaborn as sns
from sklearn.metrics import confusion_matrix
plt.figure(figsize=(8, 8))
cm2 = confusion_matrix(np.argmax(y_test_cat, axis=-1), np.argmax(pred_ys, axis=-1))
sns.heatmap(cm2, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()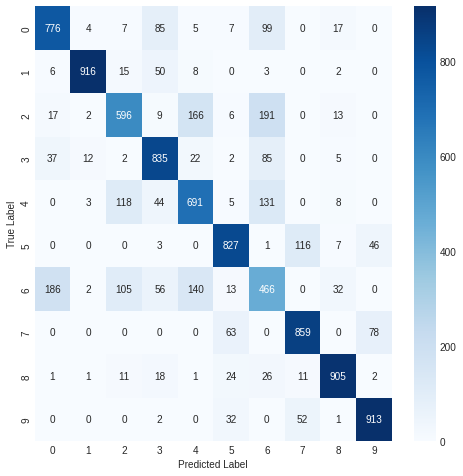
11-3. 모델 최적화
Early Stopping
fashion_mnist_model.h5- 가장 좋은 모델을 파일로 저장
- 콜백 함수 ModelCheckpoint 사용
- val_loss를 10으로 지정해 성능 변화가 없는 시점에서 조기 종료
from tensorflow.keras import callbacks
check_point_cb = callbacks.ModelCheckpoint('fashion_mnist_model.h5',
save_best_only=True)
early_stopping_cb = callbacks.EarlyStopping(patience=10,
monitor='val_loss',
restore_best_weights=True)
history = model.fit(x_train, y_train, epochs=60,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb])Epoch 1/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5961 - accuracy: 0.7906 - val_loss: 0.5873 - val_accuracy: 0.7971
Epoch 2/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5685 - accuracy: 0.8029 - val_loss: 0.5686 - val_accuracy: 0.7981
Epoch 3/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5474 - accuracy: 0.8096 - val_loss: 0.5511 - val_accuracy: 0.8069
Epoch 4/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5310 - accuracy: 0.8145 - val_loss: 0.5367 - val_accuracy: 0.8129
Epoch 5/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5176 - accuracy: 0.8197 - val_loss: 0.5208 - val_accuracy: 0.8194
Epoch 6/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5061 - accuracy: 0.8235 - val_loss: 0.5196 - val_accuracy: 0.8218
Epoch 7/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4970 - accuracy: 0.8261 - val_loss: 0.5089 - val_accuracy: 0.8228
Epoch 8/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4892 - accuracy: 0.8292 - val_loss: 0.4958 - val_accuracy: 0.8278
Epoch 9/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4813 - accuracy: 0.8312 - val_loss: 0.4969 - val_accuracy: 0.8241
Epoch 10/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4754 - accuracy: 0.8335 - val_loss: 0.4905 - val_accuracy: 0.8274
Epoch 11/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4695 - accuracy: 0.8353 - val_loss: 0.4851 - val_accuracy: 0.8295
Epoch 12/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4645 - accuracy: 0.8371 - val_loss: 0.4782 - val_accuracy: 0.8319
Epoch 13/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4599 - accuracy: 0.8379 - val_loss: 0.4701 - val_accuracy: 0.8385
Epoch 14/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4556 - accuracy: 0.8404 - val_loss: 0.4688 - val_accuracy: 0.8367
Epoch 15/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4516 - accuracy: 0.8420 - val_loss: 0.4650 - val_accuracy: 0.8394
Epoch 16/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4474 - accuracy: 0.8434 - val_loss: 0.4641 - val_accuracy: 0.8397
Epoch 17/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4444 - accuracy: 0.8431 - val_loss: 0.4570 - val_accuracy: 0.8432
Epoch 18/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4408 - accuracy: 0.8456 - val_loss: 0.4615 - val_accuracy: 0.8392
Epoch 19/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4376 - accuracy: 0.8462 - val_loss: 0.4542 - val_accuracy: 0.8426
Epoch 20/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4351 - accuracy: 0.8468 - val_loss: 0.4501 - val_accuracy: 0.8438
Epoch 21/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4320 - accuracy: 0.8478 - val_loss: 0.4496 - val_accuracy: 0.8454
Epoch 22/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4293 - accuracy: 0.8495 - val_loss: 0.4455 - val_accuracy: 0.8473
Epoch 23/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4270 - accuracy: 0.8506 - val_loss: 0.4472 - val_accuracy: 0.8446
Epoch 24/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4245 - accuracy: 0.8504 - val_loss: 0.4447 - val_accuracy: 0.8458
Epoch 25/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4223 - accuracy: 0.8515 - val_loss: 0.4404 - val_accuracy: 0.8503
Epoch 26/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4201 - accuracy: 0.8517 - val_loss: 0.4382 - val_accuracy: 0.8504
Epoch 27/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4182 - accuracy: 0.8524 - val_loss: 0.4377 - val_accuracy: 0.8485
Epoch 28/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4161 - accuracy: 0.8525 - val_loss: 0.4350 - val_accuracy: 0.8500
Epoch 29/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4140 - accuracy: 0.8539 - val_loss: 0.4374 - val_accuracy: 0.8494
Epoch 30/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4123 - accuracy: 0.8540 - val_loss: 0.4355 - val_accuracy: 0.8498
Epoch 31/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4102 - accuracy: 0.8550 - val_loss: 0.4353 - val_accuracy: 0.8486
Epoch 32/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4090 - accuracy: 0.8556 - val_loss: 0.4313 - val_accuracy: 0.8515
Epoch 33/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4069 - accuracy: 0.8559 - val_loss: 0.4348 - val_accuracy: 0.8491
Epoch 34/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4054 - accuracy: 0.8563 - val_loss: 0.4295 - val_accuracy: 0.8527
Epoch 35/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4042 - accuracy: 0.8566 - val_loss: 0.4277 - val_accuracy: 0.8526
Epoch 36/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4024 - accuracy: 0.8575 - val_loss: 0.4254 - val_accuracy: 0.8542
Epoch 37/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4011 - accuracy: 0.8582 - val_loss: 0.4238 - val_accuracy: 0.8548
Epoch 38/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3991 - accuracy: 0.8584 - val_loss: 0.4322 - val_accuracy: 0.8491
Epoch 39/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3981 - accuracy: 0.8588 - val_loss: 0.4226 - val_accuracy: 0.8549
Epoch 40/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3966 - accuracy: 0.8595 - val_loss: 0.4227 - val_accuracy: 0.8534
Epoch 41/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3951 - accuracy: 0.8600 - val_loss: 0.4218 - val_accuracy: 0.8560
Epoch 42/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3936 - accuracy: 0.8606 - val_loss: 0.4185 - val_accuracy: 0.8572
Epoch 43/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3925 - accuracy: 0.8599 - val_loss: 0.4230 - val_accuracy: 0.8517
Epoch 44/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3910 - accuracy: 0.8615 - val_loss: 0.4196 - val_accuracy: 0.8544
Epoch 45/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3898 - accuracy: 0.8623 - val_loss: 0.4167 - val_accuracy: 0.8563
Epoch 46/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3885 - accuracy: 0.8625 - val_loss: 0.4212 - val_accuracy: 0.8527
Epoch 47/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3874 - accuracy: 0.8627 - val_loss: 0.4143 - val_accuracy: 0.8568
Epoch 48/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3861 - accuracy: 0.8628 - val_loss: 0.4184 - val_accuracy: 0.8553
Epoch 49/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3852 - accuracy: 0.8638 - val_loss: 0.4166 - val_accuracy: 0.8546
Epoch 50/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3838 - accuracy: 0.8638 - val_loss: 0.4127 - val_accuracy: 0.8573
Epoch 51/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3825 - accuracy: 0.8639 - val_loss: 0.4131 - val_accuracy: 0.8568
Epoch 52/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3815 - accuracy: 0.8650 - val_loss: 0.4176 - val_accuracy: 0.8552
Epoch 53/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3805 - accuracy: 0.8638 - val_loss: 0.4131 - val_accuracy: 0.8560
Epoch 54/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3789 - accuracy: 0.8647 - val_loss: 0.4093 - val_accuracy: 0.8583
Epoch 55/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3781 - accuracy: 0.8653 - val_loss: 0.4108 - val_accuracy: 0.8565
Epoch 56/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3770 - accuracy: 0.8657 - val_loss: 0.4117 - val_accuracy: 0.8566
Epoch 57/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3761 - accuracy: 0.8662 - val_loss: 0.4079 - val_accuracy: 0.8590
Epoch 58/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3748 - accuracy: 0.8669 - val_loss: 0.4083 - val_accuracy: 0.8598
Epoch 59/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3739 - accuracy: 0.8669 - val_loss: 0.4055 - val_accuracy: 0.8584
Epoch 60/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3729 - accuracy: 0.8676 - val_loss: 0.4051 - val_accuracy: 0.8602- 히스토리 시각화
show_history(history)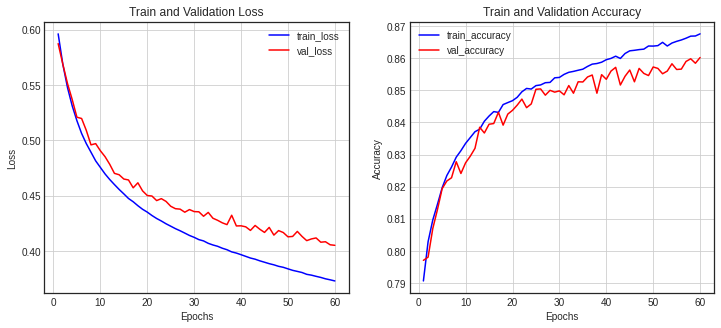
- 테스트 데이터셋으로 모델 평가 결과 확인
model.evaluate(x_test, y_test)
활성화 함수
- 기존 모델 : 선형 함수
sigmoid - 비선형 함수
relu로 변경해보기
model = models.Sequential()
model.add(layers.Input(shape=(784, )))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
optimizer='SGD',
metrics=['accuracy'])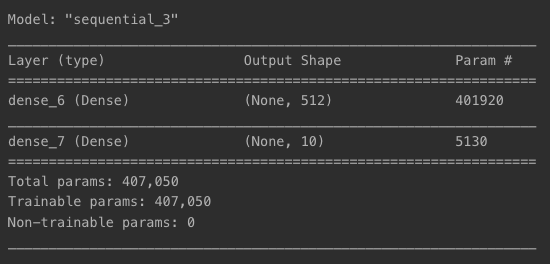
history2 = model.fit(x_train, y_train, epochs=60,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb])Epoch 1/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.7622 - accuracy: 0.7613 - val_loss: 0.5978 - val_accuracy: 0.8025
Epoch 2/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5275 - accuracy: 0.8218 - val_loss: 0.5226 - val_accuracy: 0.8231
Epoch 3/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4795 - accuracy: 0.8357 - val_loss: 0.4836 - val_accuracy: 0.8328
Epoch 4/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4535 - accuracy: 0.8430 - val_loss: 0.4503 - val_accuracy: 0.8485
Epoch 5/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4334 - accuracy: 0.8498 - val_loss: 0.4449 - val_accuracy: 0.8476
Epoch 6/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4191 - accuracy: 0.8535 - val_loss: 0.4304 - val_accuracy: 0.8514
Epoch 7/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4076 - accuracy: 0.8574 - val_loss: 0.4325 - val_accuracy: 0.8546
Epoch 8/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3968 - accuracy: 0.8621 - val_loss: 0.4151 - val_accuracy: 0.8577
Epoch 9/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3880 - accuracy: 0.8649 - val_loss: 0.4151 - val_accuracy: 0.8567
Epoch 10/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3789 - accuracy: 0.8680 - val_loss: 0.4480 - val_accuracy: 0.8375
Epoch 11/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3706 - accuracy: 0.8714 - val_loss: 0.4090 - val_accuracy: 0.8584
Epoch 12/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3636 - accuracy: 0.8736 - val_loss: 0.4094 - val_accuracy: 0.8544
Epoch 13/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3572 - accuracy: 0.8760 - val_loss: 0.3962 - val_accuracy: 0.8671
Epoch 14/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3509 - accuracy: 0.8784 - val_loss: 0.3900 - val_accuracy: 0.8634
Epoch 15/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3447 - accuracy: 0.8784 - val_loss: 0.3854 - val_accuracy: 0.8654
Epoch 16/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3395 - accuracy: 0.8799 - val_loss: 0.3820 - val_accuracy: 0.8693
Epoch 17/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3343 - accuracy: 0.8827 - val_loss: 0.3815 - val_accuracy: 0.8687
Epoch 18/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3297 - accuracy: 0.8841 - val_loss: 0.3695 - val_accuracy: 0.8704
Epoch 19/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3237 - accuracy: 0.8862 - val_loss: 0.3686 - val_accuracy: 0.8708
Epoch 20/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3212 - accuracy: 0.8858 - val_loss: 0.3769 - val_accuracy: 0.8679
Epoch 21/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3159 - accuracy: 0.8891 - val_loss: 0.3913 - val_accuracy: 0.8661
Epoch 22/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3123 - accuracy: 0.8900 - val_loss: 0.3611 - val_accuracy: 0.8739
Epoch 23/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3079 - accuracy: 0.8915 - val_loss: 0.3847 - val_accuracy: 0.8634
Epoch 24/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3047 - accuracy: 0.8926 - val_loss: 0.3638 - val_accuracy: 0.8734
Epoch 25/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3012 - accuracy: 0.8940 - val_loss: 0.3470 - val_accuracy: 0.8807
Epoch 26/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2974 - accuracy: 0.8943 - val_loss: 0.3520 - val_accuracy: 0.8785
Epoch 27/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2936 - accuracy: 0.8959 - val_loss: 0.3472 - val_accuracy: 0.8811
Epoch 28/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2905 - accuracy: 0.8980 - val_loss: 0.3491 - val_accuracy: 0.8784
Epoch 29/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2865 - accuracy: 0.8991 - val_loss: 0.3431 - val_accuracy: 0.8804
Epoch 30/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2838 - accuracy: 0.8996 - val_loss: 0.3524 - val_accuracy: 0.8768
Epoch 31/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2810 - accuracy: 0.9005 - val_loss: 0.3556 - val_accuracy: 0.8759
Epoch 32/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2778 - accuracy: 0.9019 - val_loss: 0.3407 - val_accuracy: 0.8804
Epoch 33/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2745 - accuracy: 0.9027 - val_loss: 0.3400 - val_accuracy: 0.8821
Epoch 34/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2722 - accuracy: 0.9038 - val_loss: 0.3425 - val_accuracy: 0.8804
Epoch 35/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2691 - accuracy: 0.9043 - val_loss: 0.3311 - val_accuracy: 0.8833
Epoch 36/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2660 - accuracy: 0.9051 - val_loss: 0.3482 - val_accuracy: 0.8786
Epoch 37/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2638 - accuracy: 0.9072 - val_loss: 0.3311 - val_accuracy: 0.8843
Epoch 38/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2602 - accuracy: 0.9079 - val_loss: 0.3393 - val_accuracy: 0.8800
Epoch 39/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2583 - accuracy: 0.9088 - val_loss: 0.3298 - val_accuracy: 0.8847
Epoch 40/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2550 - accuracy: 0.9111 - val_loss: 0.3431 - val_accuracy: 0.8807
Epoch 41/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2527 - accuracy: 0.9113 - val_loss: 0.3400 - val_accuracy: 0.8802
Epoch 42/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2507 - accuracy: 0.9109 - val_loss: 0.3315 - val_accuracy: 0.8838
Epoch 43/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2483 - accuracy: 0.9126 - val_loss: 0.3233 - val_accuracy: 0.8883
Epoch 44/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2457 - accuracy: 0.9131 - val_loss: 0.3274 - val_accuracy: 0.8884
Epoch 45/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2434 - accuracy: 0.9132 - val_loss: 0.3256 - val_accuracy: 0.8871
Epoch 46/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2412 - accuracy: 0.9160 - val_loss: 0.3270 - val_accuracy: 0.8851
Epoch 47/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2393 - accuracy: 0.9167 - val_loss: 0.3212 - val_accuracy: 0.8886
Epoch 48/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2361 - accuracy: 0.9172 - val_loss: 0.3245 - val_accuracy: 0.8867
Epoch 49/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2349 - accuracy: 0.9174 - val_loss: 0.3215 - val_accuracy: 0.8877
Epoch 50/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2321 - accuracy: 0.9188 - val_loss: 0.3227 - val_accuracy: 0.8888
Epoch 51/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2306 - accuracy: 0.9184 - val_loss: 0.3287 - val_accuracy: 0.8851
Epoch 52/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2286 - accuracy: 0.9197 - val_loss: 0.3277 - val_accuracy: 0.8866
Epoch 53/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2260 - accuracy: 0.9206 - val_loss: 0.3179 - val_accuracy: 0.8891
Epoch 54/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2233 - accuracy: 0.9224 - val_loss: 0.3182 - val_accuracy: 0.8894
Epoch 55/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2214 - accuracy: 0.9214 - val_loss: 0.3233 - val_accuracy: 0.8884
Epoch 56/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2204 - accuracy: 0.9225 - val_loss: 0.3528 - val_accuracy: 0.8776
Epoch 57/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2182 - accuracy: 0.9242 - val_loss: 0.3190 - val_accuracy: 0.8894
Epoch 58/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2154 - accuracy: 0.9246 - val_loss: 0.3149 - val_accuracy: 0.8894
Epoch 59/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2149 - accuracy: 0.9255 - val_loss: 0.3237 - val_accuracy: 0.8901
Epoch 60/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2124 - accuracy: 0.9260 - val_loss: 0.3380 - val_accuracy: 0.8847- 두 모델의 학습 히스토리 비교 함수 : diff_history()
def diff_history(history1, history2):
history1_dict = history1.history
h1_loss = history1_dict['loss']
h1_val_loss = history1_dict['val_loss']
history2_dict = history2.history
h2_loss = history2_dict['loss']
h2_val_loss = history2_dict['val_loss']
epochs1 = range(1, len(h1_loss) + 1)
epochs2 = range(1, len(h2_loss) + 1)
fig = plt.figure(figsize=(12, 5))
plt.subplots_adjust(wspace=0.3, hspace=0.3)
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs1, h1_loss, 'b-', label='train_loss')
ax1.plot(epochs1, h1_val_loss, 'r-', label='val_loss')
ax1.plot(epochs2, h2_loss, 'b--', label='train_loss')
ax1.plot(epochs2, h2_val_loss, 'r--', label='val_loss')
ax1.set_title('Train and Validation Loss')
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Loss')
ax1.grid()
ax1.legend()
h1_accuracy = history1_dict['accuracy']
h1_val_accuracy = history1_dict['val_accuracy']
h2_accuracy = history2_dict['accuracy']
h2_val_accuracy = history2_dict['val_accuracy']
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs1, h1_accuracy, 'b-', label='train_accuracy')
ax2.plot(epochs1, h1_val_accuracy, 'r-', label='val_accuracy')
ax2.plot(epochs2, h2_accuracy, 'b--', label='train_accuracy')
ax2.plot(epochs2, h2_val_accuracy, 'r--', label='val_accuracy')
ax2.set_title('Train and Validation Accuracy')
ax2.set_xlabel('Epochs')
ax2.set_ylabel('Accuracy')
ax2.grid()
ax2.legend()
plt.show()- 기존 모델 vs relu 변경 모델 결과 시각화
diff_history(history, history2)
- 활성화 함수 변경 모델 평가 결과 확인
model.evaluate(x_test, y_test)
옵티마이저
- 기존 모델 : SGD
- 변경 : Adam
model.compile(loss='sparse_categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])history3 = model.fit(x_train, y_train, epochs=60,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb])Epoch 1/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3771 - accuracy: 0.8674 - val_loss: 0.4260 - val_accuracy: 0.8500
Epoch 2/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3314 - accuracy: 0.8792 - val_loss: 0.3964 - val_accuracy: 0.8591
Epoch 3/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.3025 - accuracy: 0.8890 - val_loss: 0.3868 - val_accuracy: 0.8588
Epoch 4/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2872 - accuracy: 0.8927 - val_loss: 0.3866 - val_accuracy: 0.8617
Epoch 5/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2746 - accuracy: 0.8977 - val_loss: 0.3448 - val_accuracy: 0.8836
Epoch 6/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2589 - accuracy: 0.9048 - val_loss: 0.3709 - val_accuracy: 0.8757
Epoch 7/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2498 - accuracy: 0.9074 - val_loss: 0.3859 - val_accuracy: 0.8661
Epoch 8/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2366 - accuracy: 0.9108 - val_loss: 0.3432 - val_accuracy: 0.8844
Epoch 9/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2276 - accuracy: 0.9153 - val_loss: 0.3650 - val_accuracy: 0.8783
Epoch 10/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2201 - accuracy: 0.9180 - val_loss: 0.3719 - val_accuracy: 0.8787
Epoch 11/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2123 - accuracy: 0.9212 - val_loss: 0.3408 - val_accuracy: 0.8890
Epoch 12/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.2028 - accuracy: 0.9229 - val_loss: 0.3572 - val_accuracy: 0.8844
Epoch 13/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1958 - accuracy: 0.9261 - val_loss: 0.3493 - val_accuracy: 0.8917
Epoch 14/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1918 - accuracy: 0.9272 - val_loss: 0.3443 - val_accuracy: 0.8884
Epoch 15/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1857 - accuracy: 0.9294 - val_loss: 0.3407 - val_accuracy: 0.8915
Epoch 16/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1788 - accuracy: 0.9322 - val_loss: 0.3613 - val_accuracy: 0.8872
Epoch 17/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1717 - accuracy: 0.9350 - val_loss: 0.3585 - val_accuracy: 0.8859
Epoch 18/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1678 - accuracy: 0.9368 - val_loss: 0.3605 - val_accuracy: 0.8928
Epoch 19/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1618 - accuracy: 0.9388 - val_loss: 0.3784 - val_accuracy: 0.8900
Epoch 20/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1596 - accuracy: 0.9402 - val_loss: 0.3818 - val_accuracy: 0.8904
Epoch 21/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1514 - accuracy: 0.9427 - val_loss: 0.3675 - val_accuracy: 0.8913
Epoch 22/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1503 - accuracy: 0.9427 - val_loss: 0.3769 - val_accuracy: 0.8913
Epoch 23/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1474 - accuracy: 0.9438 - val_loss: 0.3863 - val_accuracy: 0.8954
Epoch 24/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1417 - accuracy: 0.9467 - val_loss: 0.4031 - val_accuracy: 0.8874
Epoch 25/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.1362 - accuracy: 0.9479 - val_loss: 0.4090 - val_accuracy: 0.8870- 기존 모델 vs 옵티마이저 비교 모델
- 조기 종료됨
- overfitting 발생
diff_history(history, history3)
- 옵티마이저 변경 모델 평가 결과
model.evaluate(x_test, y_test)
규제
- overfitting 규제를 위함
- 중간 Dense 레이어 -> L2 규제 수행
model = models.Sequential()
model.add(layers.Input(shape=(784, )))
model.add(layers.Dense(512, kernel_regularizer='l2', activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
optimizer='SGD',
metrics=['accuracy'])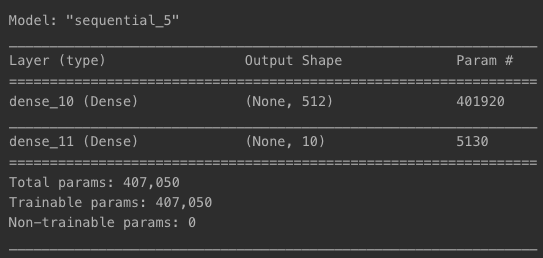
history4 = model.fit(x_train, y_train,
epochs=60,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb])Epoch 1/60
1313/1313 [==============================] - 4s 3ms/step - loss: 5.6393 - accuracy: 0.7517 - val_loss: 4.3222 - val_accuracy: 0.8048
Epoch 2/60
1313/1313 [==============================] - 3s 2ms/step - loss: 3.4732 - accuracy: 0.8183 - val_loss: 2.7753 - val_accuracy: 0.8246
Epoch 3/60
1313/1313 [==============================] - 3s 2ms/step - loss: 2.2759 - accuracy: 0.8307 - val_loss: 1.8825 - val_accuracy: 0.8226
Epoch 4/60
1313/1313 [==============================] - 3s 2ms/step - loss: 1.5702 - accuracy: 0.8357 - val_loss: 1.3355 - val_accuracy: 0.8346
Epoch 5/60
1313/1313 [==============================] - 3s 2ms/step - loss: 1.1500 - accuracy: 0.8392 - val_loss: 1.0077 - val_accuracy: 0.8423
Epoch 6/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.8999 - accuracy: 0.8422 - val_loss: 0.8235 - val_accuracy: 0.8428
Epoch 7/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.7511 - accuracy: 0.8439 - val_loss: 0.7487 - val_accuracy: 0.8163
Epoch 8/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.6593 - accuracy: 0.8450 - val_loss: 0.6547 - val_accuracy: 0.8357
Epoch 9/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.6034 - accuracy: 0.8473 - val_loss: 0.6268 - val_accuracy: 0.8331
Epoch 10/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5700 - accuracy: 0.8476 - val_loss: 0.5645 - val_accuracy: 0.8512
Epoch 11/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5475 - accuracy: 0.8486 - val_loss: 0.5518 - val_accuracy: 0.8476
Epoch 12/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5318 - accuracy: 0.8494 - val_loss: 0.5409 - val_accuracy: 0.8488
Epoch 13/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5230 - accuracy: 0.8506 - val_loss: 0.5483 - val_accuracy: 0.8389
Epoch 14/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5155 - accuracy: 0.8520 - val_loss: 0.5581 - val_accuracy: 0.8336
Epoch 15/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5096 - accuracy: 0.8527 - val_loss: 0.5266 - val_accuracy: 0.8474
Epoch 16/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5050 - accuracy: 0.8540 - val_loss: 0.5518 - val_accuracy: 0.8410
Epoch 17/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5016 - accuracy: 0.8540 - val_loss: 0.5250 - val_accuracy: 0.8468
Epoch 18/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4991 - accuracy: 0.8562 - val_loss: 0.5539 - val_accuracy: 0.8322
Epoch 19/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4964 - accuracy: 0.8558 - val_loss: 0.5353 - val_accuracy: 0.8385
Epoch 20/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4932 - accuracy: 0.8545 - val_loss: 0.5085 - val_accuracy: 0.8502
Epoch 21/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4919 - accuracy: 0.8570 - val_loss: 0.5026 - val_accuracy: 0.8554
Epoch 22/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4889 - accuracy: 0.8574 - val_loss: 0.5404 - val_accuracy: 0.8304
Epoch 23/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4864 - accuracy: 0.8580 - val_loss: 0.5259 - val_accuracy: 0.8428
Epoch 24/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4832 - accuracy: 0.8592 - val_loss: 0.5109 - val_accuracy: 0.8496
Epoch 25/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4838 - accuracy: 0.8588 - val_loss: 0.5229 - val_accuracy: 0.8383
Epoch 26/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4823 - accuracy: 0.8585 - val_loss: 0.4951 - val_accuracy: 0.8563
Epoch 27/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4787 - accuracy: 0.8598 - val_loss: 0.4893 - val_accuracy: 0.8588
Epoch 28/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4780 - accuracy: 0.8605 - val_loss: 0.4910 - val_accuracy: 0.8578
Epoch 29/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4751 - accuracy: 0.8596 - val_loss: 0.5203 - val_accuracy: 0.8413
Epoch 30/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4758 - accuracy: 0.8608 - val_loss: 0.5148 - val_accuracy: 0.8415
Epoch 31/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4740 - accuracy: 0.8601 - val_loss: 0.4892 - val_accuracy: 0.8544
Epoch 32/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4720 - accuracy: 0.8617 - val_loss: 0.4899 - val_accuracy: 0.8580
Epoch 33/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4713 - accuracy: 0.8613 - val_loss: 0.4953 - val_accuracy: 0.8559
Epoch 34/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4691 - accuracy: 0.8618 - val_loss: 0.5155 - val_accuracy: 0.8378
Epoch 35/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4678 - accuracy: 0.8620 - val_loss: 0.4869 - val_accuracy: 0.8576
Epoch 36/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4682 - accuracy: 0.8629 - val_loss: 0.4897 - val_accuracy: 0.8546
Epoch 37/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4656 - accuracy: 0.8634 - val_loss: 0.4893 - val_accuracy: 0.8558
Epoch 38/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4652 - accuracy: 0.8642 - val_loss: 0.4758 - val_accuracy: 0.8623
Epoch 39/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4626 - accuracy: 0.8628 - val_loss: 0.4992 - val_accuracy: 0.8527
Epoch 40/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4629 - accuracy: 0.8639 - val_loss: 0.4803 - val_accuracy: 0.8591
Epoch 41/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4615 - accuracy: 0.8635 - val_loss: 0.4774 - val_accuracy: 0.8594
Epoch 42/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4607 - accuracy: 0.8646 - val_loss: 0.5925 - val_accuracy: 0.7991
Epoch 43/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4614 - accuracy: 0.8635 - val_loss: 0.4794 - val_accuracy: 0.8569
Epoch 44/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4591 - accuracy: 0.8653 - val_loss: 0.4725 - val_accuracy: 0.8624
Epoch 45/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4580 - accuracy: 0.8655 - val_loss: 0.4876 - val_accuracy: 0.8581
Epoch 46/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4558 - accuracy: 0.8658 - val_loss: 0.5298 - val_accuracy: 0.8308
Epoch 47/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4559 - accuracy: 0.8666 - val_loss: 0.4667 - val_accuracy: 0.8647
Epoch 48/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4542 - accuracy: 0.8661 - val_loss: 0.4786 - val_accuracy: 0.8606
Epoch 49/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4534 - accuracy: 0.8657 - val_loss: 0.5449 - val_accuracy: 0.8310
Epoch 50/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4530 - accuracy: 0.8664 - val_loss: 0.4776 - val_accuracy: 0.8596
Epoch 51/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4518 - accuracy: 0.8651 - val_loss: 0.4916 - val_accuracy: 0.8558
Epoch 52/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4514 - accuracy: 0.8671 - val_loss: 0.4740 - val_accuracy: 0.8575
Epoch 53/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4514 - accuracy: 0.8660 - val_loss: 0.4713 - val_accuracy: 0.8607
Epoch 54/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4510 - accuracy: 0.8659 - val_loss: 0.5444 - val_accuracy: 0.8244
Epoch 55/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4519 - accuracy: 0.8661 - val_loss: 0.5099 - val_accuracy: 0.8437
Epoch 56/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4502 - accuracy: 0.8667 - val_loss: 0.4838 - val_accuracy: 0.8554
Epoch 57/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.4495 - accuracy: 0.8671 - val_loss: 0.4707 - val_accuracy: 0.8604- 기존 모델 vs L2 규제
diff_history(history, history4)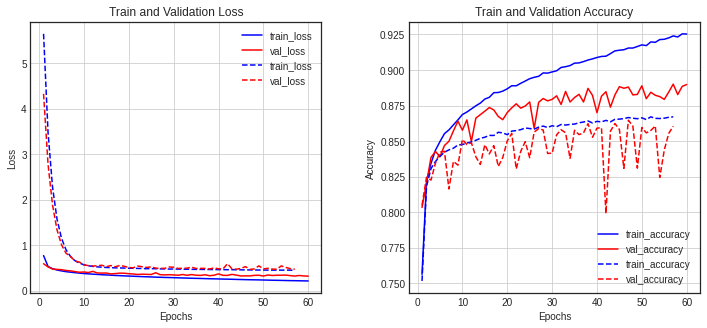
결과 : 성능 일부 저하, overfitting은 조금 덜해짐
- L2 규제 적용 모델 평가 결과
model.evaluate(x_test, y_test)
드롭아웃
- Dense 레이어 사이 50% Dropout 레이어 넣기
# 직접 코드를 입력해보세요
model = models.Sequential()
model.add(layers.Input(shape=(784, )))
model.add(layers.Dense(512, kernel_regularizer='l2', activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
optimizer='SGD',
metrics=['accuracy'])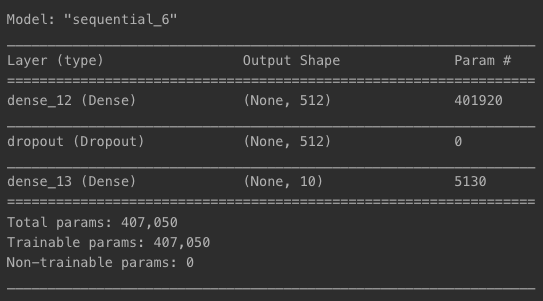
history5 = model.fit(x_train, y_train,
epochs=60,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb])Epoch 1/60
1313/1313 [==============================] - 4s 3ms/step - loss: 5.7358 - accuracy: 0.7068 - val_loss: 4.3508 - val_accuracy: 0.7882
Epoch 2/60
1313/1313 [==============================] - 3s 2ms/step - loss: 3.5406 - accuracy: 0.7932 - val_loss: 2.8029 - val_accuracy: 0.8213
Epoch 3/60
1313/1313 [==============================] - 3s 3ms/step - loss: 2.3322 - accuracy: 0.8124 - val_loss: 1.8920 - val_accuracy: 0.8246
Epoch 4/60
1313/1313 [==============================] - 3s 3ms/step - loss: 1.6181 - accuracy: 0.8207 - val_loss: 1.3506 - val_accuracy: 0.8320
Epoch 5/60
1313/1313 [==============================] - 3s 3ms/step - loss: 1.1962 - accuracy: 0.8234 - val_loss: 1.0265 - val_accuracy: 0.8377
Epoch 6/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.9420 - accuracy: 0.8306 - val_loss: 0.8329 - val_accuracy: 0.8407
Epoch 7/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.7899 - accuracy: 0.8308 - val_loss: 0.7237 - val_accuracy: 0.8438
Epoch 8/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.6979 - accuracy: 0.8346 - val_loss: 0.6470 - val_accuracy: 0.8454
Epoch 9/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.6425 - accuracy: 0.8350 - val_loss: 0.6094 - val_accuracy: 0.8423
Epoch 10/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.6074 - accuracy: 0.8365 - val_loss: 0.5728 - val_accuracy: 0.8482
Epoch 11/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5830 - accuracy: 0.8379 - val_loss: 0.5560 - val_accuracy: 0.8464
Epoch 12/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5662 - accuracy: 0.8407 - val_loss: 0.5607 - val_accuracy: 0.8404
Epoch 13/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5580 - accuracy: 0.8395 - val_loss: 0.5389 - val_accuracy: 0.8459
Epoch 14/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5498 - accuracy: 0.8410 - val_loss: 0.5648 - val_accuracy: 0.8312
Epoch 15/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5453 - accuracy: 0.8417 - val_loss: 0.5411 - val_accuracy: 0.8453
Epoch 16/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5421 - accuracy: 0.8413 - val_loss: 0.5324 - val_accuracy: 0.8491
Epoch 17/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5363 - accuracy: 0.8430 - val_loss: 0.5254 - val_accuracy: 0.8482
Epoch 18/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5344 - accuracy: 0.8423 - val_loss: 0.5237 - val_accuracy: 0.8476
Epoch 19/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5336 - accuracy: 0.8439 - val_loss: 0.5222 - val_accuracy: 0.8458
Epoch 20/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5282 - accuracy: 0.8449 - val_loss: 0.5289 - val_accuracy: 0.8406
Epoch 21/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5264 - accuracy: 0.8443 - val_loss: 0.5182 - val_accuracy: 0.8492
Epoch 22/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5247 - accuracy: 0.8461 - val_loss: 0.5171 - val_accuracy: 0.8478
Epoch 23/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5229 - accuracy: 0.8462 - val_loss: 0.5252 - val_accuracy: 0.8398
Epoch 24/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5207 - accuracy: 0.8451 - val_loss: 0.5241 - val_accuracy: 0.8471
Epoch 25/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5199 - accuracy: 0.8471 - val_loss: 0.5108 - val_accuracy: 0.8494
Epoch 26/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5186 - accuracy: 0.8467 - val_loss: 0.5243 - val_accuracy: 0.8424
Epoch 27/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5174 - accuracy: 0.8475 - val_loss: 0.5068 - val_accuracy: 0.8522
Epoch 28/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5139 - accuracy: 0.8487 - val_loss: 0.5056 - val_accuracy: 0.8496
Epoch 29/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5140 - accuracy: 0.8482 - val_loss: 0.5112 - val_accuracy: 0.8437
Epoch 30/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5141 - accuracy: 0.8477 - val_loss: 0.4981 - val_accuracy: 0.8556
Epoch 31/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5110 - accuracy: 0.8493 - val_loss: 0.5083 - val_accuracy: 0.8455
Epoch 32/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5107 - accuracy: 0.8480 - val_loss: 0.4986 - val_accuracy: 0.8576
Epoch 33/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5124 - accuracy: 0.8478 - val_loss: 0.4894 - val_accuracy: 0.8577
Epoch 34/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5084 - accuracy: 0.8496 - val_loss: 0.5056 - val_accuracy: 0.8526
Epoch 35/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5092 - accuracy: 0.8498 - val_loss: 0.5481 - val_accuracy: 0.8308
Epoch 36/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5079 - accuracy: 0.8486 - val_loss: 0.5030 - val_accuracy: 0.8491
Epoch 37/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5087 - accuracy: 0.8505 - val_loss: 0.5156 - val_accuracy: 0.8479
Epoch 38/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5058 - accuracy: 0.8503 - val_loss: 0.5046 - val_accuracy: 0.8511
Epoch 39/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5068 - accuracy: 0.8485 - val_loss: 0.4917 - val_accuracy: 0.8546
Epoch 40/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5049 - accuracy: 0.8499 - val_loss: 0.4946 - val_accuracy: 0.8568
Epoch 41/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5044 - accuracy: 0.8509 - val_loss: 0.5051 - val_accuracy: 0.8460
Epoch 42/60
1313/1313 [==============================] - 3s 2ms/step - loss: 0.5031 - accuracy: 0.8509 - val_loss: 0.5136 - val_accuracy: 0.8415
Epoch 43/60
1313/1313 [==============================] - 3s 3ms/step - loss: 0.5029 - accuracy: 0.8512 - val_loss: 0.4988 - val_accuracy: 0.8569- 기존 모델 vs 드롭 아웃
diff_history(history, history5)
결과 : overfitting 방지가 잘 됨
- L2 규제보다 -> 드롭아웃이 더 좋은 결과를 보임
diff_history(history4, history5)
- 드롭아웃 적용 모델 평가 결과
model.evaluate(x_test, y_test)
배치 정규화
- Dense 레이어 다음 BatchNormalization 레이어 추가
- 그 이후 활성화 함수 레이어 추가
model = models.Sequential()
model.add(layers.Input(shape=(784, )))
model.add(layers.Dense(512, ))
model.add(layers.BatchNormalization())
model.add(layers.Activation('relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
optimizer='SGD',
metrics=['accuracy'])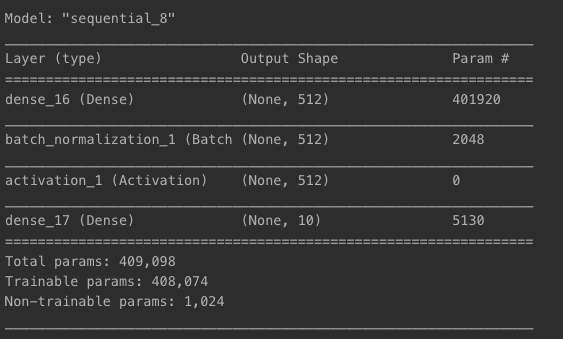
history6 = model.fit(x_train, y_train,
epochs=60,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb])Epoch 1/60
1313/1313 [==============================] - 5s 3ms/step - loss: 0.5645 - accuracy: 0.8077 - val_loss: 0.4471 - val_accuracy: 0.8396
Epoch 2/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.4146 - accuracy: 0.8519 - val_loss: 0.4021 - val_accuracy: 0.8573
Epoch 3/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3783 - accuracy: 0.8655 - val_loss: 0.3838 - val_accuracy: 0.8658
Epoch 4/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3512 - accuracy: 0.8750 - val_loss: 0.3641 - val_accuracy: 0.8711
Epoch 5/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3321 - accuracy: 0.8812 - val_loss: 0.3505 - val_accuracy: 0.8771
Epoch 6/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3165 - accuracy: 0.8878 - val_loss: 0.3456 - val_accuracy: 0.8788
Epoch 7/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3018 - accuracy: 0.8926 - val_loss: 0.3813 - val_accuracy: 0.8617
Epoch 8/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2890 - accuracy: 0.8988 - val_loss: 0.3318 - val_accuracy: 0.8846
Epoch 9/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2777 - accuracy: 0.9021 - val_loss: 0.3287 - val_accuracy: 0.8877
Epoch 10/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2669 - accuracy: 0.9060 - val_loss: 0.3272 - val_accuracy: 0.8873
Epoch 11/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2589 - accuracy: 0.9088 - val_loss: 0.3555 - val_accuracy: 0.8758
Epoch 12/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2482 - accuracy: 0.9130 - val_loss: 0.3272 - val_accuracy: 0.8871
Epoch 13/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2421 - accuracy: 0.9153 - val_loss: 0.3350 - val_accuracy: 0.8831
Epoch 14/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2314 - accuracy: 0.9180 - val_loss: 0.3477 - val_accuracy: 0.8781
Epoch 15/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2254 - accuracy: 0.9205 - val_loss: 0.3212 - val_accuracy: 0.8893
Epoch 16/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2169 - accuracy: 0.9244 - val_loss: 0.3520 - val_accuracy: 0.8788
Epoch 17/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2080 - accuracy: 0.9273 - val_loss: 0.3218 - val_accuracy: 0.8893
Epoch 18/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2016 - accuracy: 0.9296 - val_loss: 0.3292 - val_accuracy: 0.8871
Epoch 19/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.1955 - accuracy: 0.9320 - val_loss: 0.3256 - val_accuracy: 0.8893
Epoch 20/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.1902 - accuracy: 0.9341 - val_loss: 0.3371 - val_accuracy: 0.8861
Epoch 21/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.1836 - accuracy: 0.9361 - val_loss: 0.3434 - val_accuracy: 0.8867
Epoch 22/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.1771 - accuracy: 0.9392 - val_loss: 0.3380 - val_accuracy: 0.8856
Epoch 23/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.1718 - accuracy: 0.9408 - val_loss: 0.4006 - val_accuracy: 0.8709
Epoch 24/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.1664 - accuracy: 0.9439 - val_loss: 0.3476 - val_accuracy: 0.8856
Epoch 25/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.1600 - accuracy: 0.9461 - val_loss: 0.3673 - val_accuracy: 0.8758- 기존 모델 vs 배치 정규화
- 학습이 빠름
diff_history(history, history6)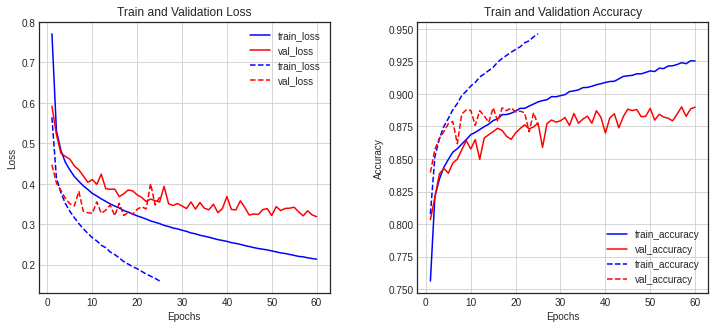
- 배치 정규화 적용 모델 평가 결과
model.evaluate(x_test, y_test)
배치 정규화 + 드롭아웃
- 기존 배치 정규화 적용 모델 + Activation 이후 Dropout 레이어 추가
model = models.Sequential()
model.add(layers.Input(shape=(784, )))
model.add(layers.Dense(512, ))
model.add(layers.BatchNormalization())
model.add(layers.Activation('relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])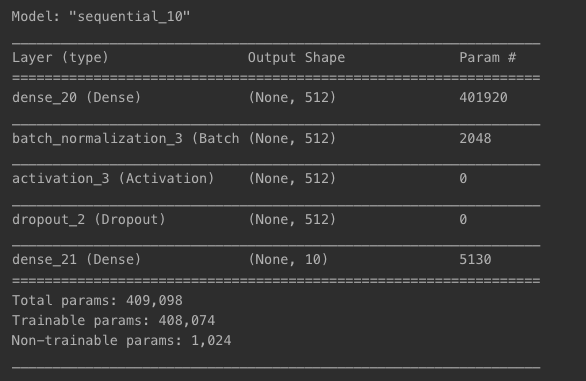
history7 = model.fit(x_train, y_train,
epochs=60,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb])Epoch 1/60
1313/1313 [==============================] - 5s 3ms/step - loss: 0.5695 - accuracy: 0.7984 - val_loss: 0.4520 - val_accuracy: 0.8414
Epoch 2/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.4390 - accuracy: 0.8422 - val_loss: 0.4110 - val_accuracy: 0.8509
Epoch 3/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.4081 - accuracy: 0.8509 - val_loss: 0.3965 - val_accuracy: 0.8547
Epoch 4/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3837 - accuracy: 0.8598 - val_loss: 0.3682 - val_accuracy: 0.8689
Epoch 5/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3692 - accuracy: 0.8638 - val_loss: 0.3492 - val_accuracy: 0.8754
Epoch 6/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3511 - accuracy: 0.8721 - val_loss: 0.3561 - val_accuracy: 0.8733
Epoch 7/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3425 - accuracy: 0.8748 - val_loss: 0.3778 - val_accuracy: 0.8657
Epoch 8/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3286 - accuracy: 0.8785 - val_loss: 0.3437 - val_accuracy: 0.8776
Epoch 9/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3221 - accuracy: 0.8826 - val_loss: 0.3378 - val_accuracy: 0.8807
Epoch 10/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3125 - accuracy: 0.8831 - val_loss: 0.3468 - val_accuracy: 0.8740
Epoch 11/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.3026 - accuracy: 0.8886 - val_loss: 0.3345 - val_accuracy: 0.8822
Epoch 12/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2991 - accuracy: 0.8886 - val_loss: 0.3221 - val_accuracy: 0.8862
Epoch 13/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2884 - accuracy: 0.8931 - val_loss: 0.3506 - val_accuracy: 0.8811
Epoch 14/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2835 - accuracy: 0.8945 - val_loss: 0.3442 - val_accuracy: 0.8789
Epoch 15/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2778 - accuracy: 0.8970 - val_loss: 0.3268 - val_accuracy: 0.8892
Epoch 16/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2707 - accuracy: 0.9011 - val_loss: 0.3160 - val_accuracy: 0.8919
Epoch 17/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2674 - accuracy: 0.9013 - val_loss: 0.3448 - val_accuracy: 0.8793
Epoch 18/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2627 - accuracy: 0.9041 - val_loss: 0.3256 - val_accuracy: 0.8914
Epoch 19/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2533 - accuracy: 0.9048 - val_loss: 0.3304 - val_accuracy: 0.8861
Epoch 20/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2516 - accuracy: 0.9055 - val_loss: 0.3113 - val_accuracy: 0.8970
Epoch 21/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2464 - accuracy: 0.9074 - val_loss: 0.3359 - val_accuracy: 0.8876
Epoch 22/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2448 - accuracy: 0.9095 - val_loss: 0.3292 - val_accuracy: 0.8891
Epoch 23/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2422 - accuracy: 0.9098 - val_loss: 0.3335 - val_accuracy: 0.8889
Epoch 24/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2374 - accuracy: 0.9115 - val_loss: 0.3318 - val_accuracy: 0.8903
Epoch 25/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2315 - accuracy: 0.9131 - val_loss: 0.3073 - val_accuracy: 0.8971
Epoch 26/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2245 - accuracy: 0.9148 - val_loss: 0.3255 - val_accuracy: 0.8922
Epoch 27/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2250 - accuracy: 0.9158 - val_loss: 0.3359 - val_accuracy: 0.8922
Epoch 28/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2222 - accuracy: 0.9180 - val_loss: 0.3228 - val_accuracy: 0.8940
Epoch 29/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2204 - accuracy: 0.9172 - val_loss: 0.3311 - val_accuracy: 0.8943
Epoch 30/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2163 - accuracy: 0.9190 - val_loss: 0.3329 - val_accuracy: 0.8932
Epoch 31/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2116 - accuracy: 0.9207 - val_loss: 0.3339 - val_accuracy: 0.8926
Epoch 32/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2111 - accuracy: 0.9212 - val_loss: 0.3439 - val_accuracy: 0.8907
Epoch 33/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2066 - accuracy: 0.9239 - val_loss: 0.3358 - val_accuracy: 0.8961
Epoch 34/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2037 - accuracy: 0.9246 - val_loss: 0.3373 - val_accuracy: 0.8926
Epoch 35/60
1313/1313 [==============================] - 4s 3ms/step - loss: 0.2008 - accuracy: 0.9246 - val_loss: 0.3448 - val_accuracy: 0.8959- 기존 vs 배치 정규화 + 드롭아웃
diff_history(history, history7)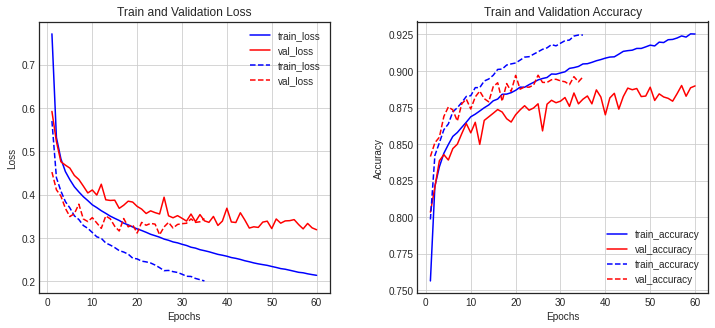
결과 : 안정적인 학습 + overfitting을 잘 줄임
- 배치 정규화 + 드롭아웃 모델 평가 결과
model.evaluate(x_test, y_test)
모델 결과 분석
- 랜덤으로 데이터 선택 -> 최종 모델 분류 결과
num_rows = 8
num_cols = 4
num_images = num_rows * num_cols
random_num = np.random.randint(10000, size=num_images)
plt.figure(figsize=(2 * 2 * num_cols, 2 * num_rows))
for idx, num in enumerate(random_num):
plt.subplot(num_rows, 2 * num_cols, 2 * idx + 1)
plot_image(num, pred_ys, y_test, x_test.reshape(-1, 28, 28))
plt.subplot(num_rows, 2 * num_cols, 2 * idx + 2)
plot_class(num, pred_ys, y_test)
plt.show()
- 최적화한 모델 분류 결과 -> 클래스별로 성능 지표 보기
from tensorflow.keras import utils
from sklearn.metrics import classification_report
y_test_cat = utils.to_categorical(y_test)
print(classification_report(np.argmax(y_test_cat, axis=-1),
np.argmax(pred_ys, axis=-1),
target_names=class_names))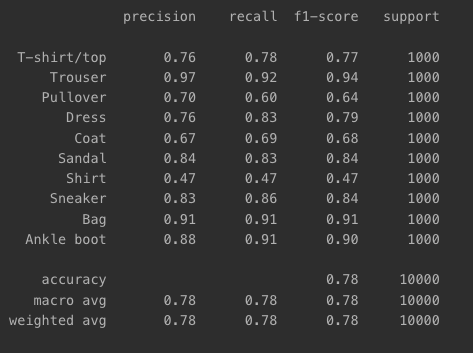
- 모델 결과 혼동 행렬로 시각화
import seaborn as sns
from sklearn.metrics import confusion_matrix
plt.figure(figsize=(8, 8))
cm2 = confusion_matrix(np.argmax(y_test_cat, axis=-1), np.argmax(pred_ys, axis=-1))
sns.heatmap(cm2, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()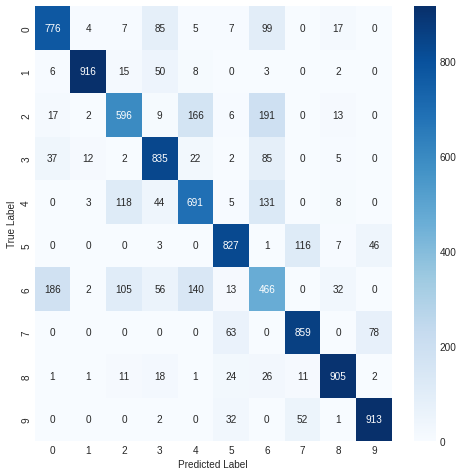
결과
- 최적화를 통해 기존 모델보다는 높은 성능을 보임
- 다만, 여전히 모델 평가 결과는 90%를 넘기기는 어려움

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️