
-
10. OSI 7계층에 대해 설명해 주세요.
답
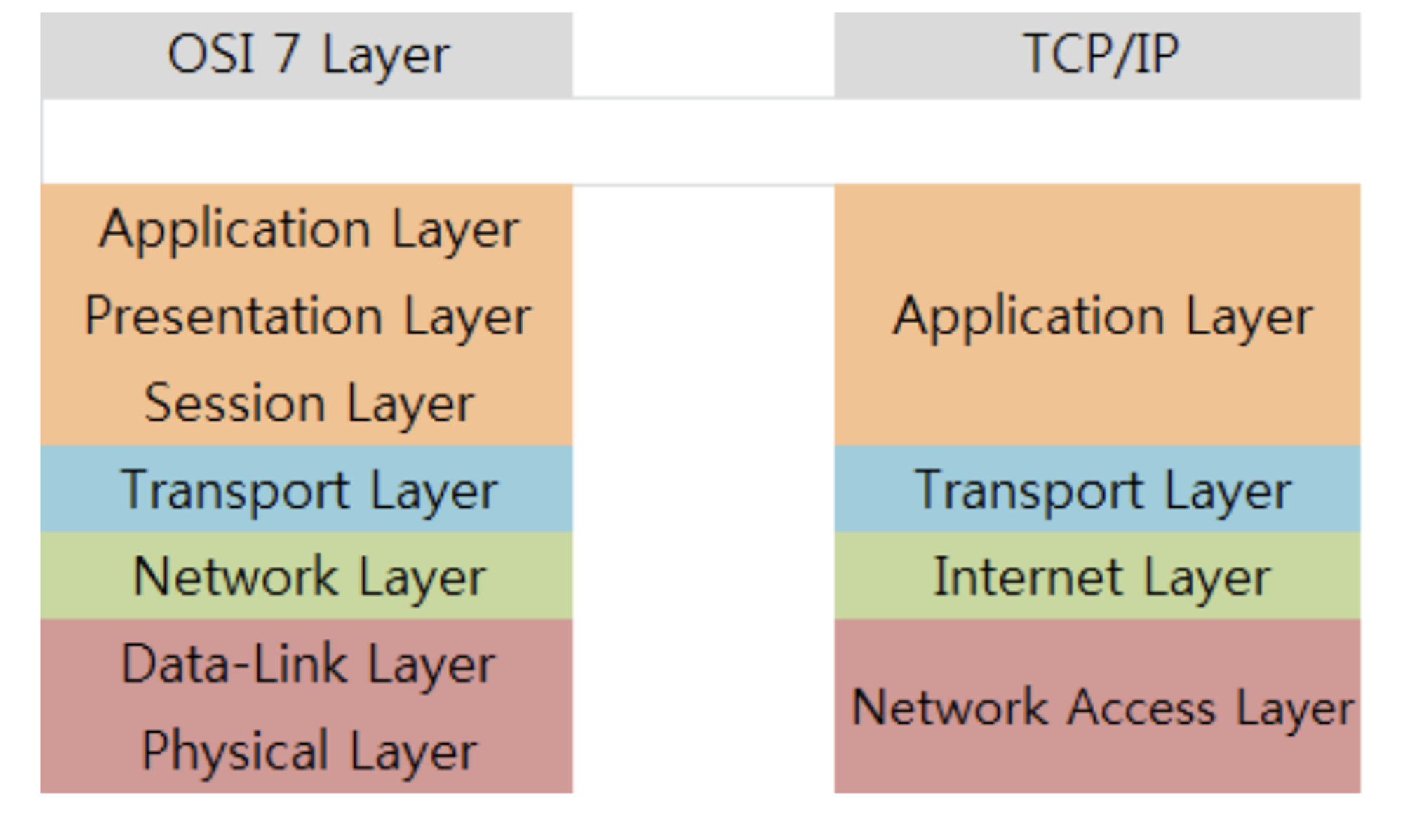
- 물리 계층 (Physical Layer)
- 물리적인 매체(케이블, 리피터, 허브)를 통해 데이터를 전기적, 기계적, 기능적 신호로 변환하여 전송하는 역할을 함
- 데이터 링크 계층으로 부터 받은 데이터를 비트(bit) 단위로 변환하여 전달
- 데이터 링크 계층 (Data Link Layer)
- 물리 계층을 통해 송수신되는 정보의 오류와 흐름을 관리하여 통신에서의 오류를 찾고, 재전송하는 기능을 가지고 있음
- 프레임 단위로 데이터를 처리하며, MAC 주소를 사용하여 장치를 식별
- 네트워크 계층 (Network Layer)
- 다양한 네트워크 간의 데이터 전송을 담당
- 데이터 패킷을 목적지까지 라우팅하는 역할을 하며, IP 주소를 사용하여 장치를 식별
- 전송 계층 (Transport Layer)
- 통신 세션에서 데이터의 전송을 관리
- 데이터의 분할, 전송, 재조합을 담당하며, TCP, UDP 와 같은 프로토콜을 사용하여 신뢰성 있는 데이터 전송을 보장
- 세션 계층 (Session Layer)
- 네트워크 상의 두 시스템 간의 세션을 관리
- 세션의 설정, 유지, 종료를 담당하여 데이터 교환 과정에서의 동기화와 연결을 유지
- 표현 계층 (Presentation Layer)
- 데이터의 표현 형식을 처리
- 데이터를 암호화하거나 압축하는 등의 변환 작업을 수행하여 애플리케이션 계층과 데이터 링크 계층 사이에서 데이터를 변환
- 응용 계층 (Application Layer)
- 사용자와 바로 연결되어 사용자의 네트워크 서비스 요구를 충족시킴
- 웹 브라우저, 이메일 클라이언트, 파일 전송 프로토콜(FTP)과 같은 응용 프로그램에 서비스를 제공
- 물리 계층 (Physical Layer)
-
Transport Layer와, Network Layer의 차이에 대해 설명해 주세요.
답
차이점
- 네트워크 계층은 패킷의 목적지까지 라우팅을 담당하고, 전송 계층은 데이터의 신뢰성 있는 전송을 보장
- 네트워크 계층은 패킷, 전송 계층은 세그먼트(TCP), 데이터그램(UDP) 를 사용
Transport Layer
- TCP, UDP가 대표적
- Application 계층에서 받은 메시지를 기반으로 세그먼트 또는 데이터그램으로 데이터를 쪼개고 데이터가 오류 없이 순서대로 전달되도록 도움을 주는 층
Network Layer
- IP, ICMP, ARP가 대표적
- 한 노드에서 다른 노드로 Transport 계층에서 받은 세그먼트 또는 데이터그램을 패킷화 하여 목적지로 전송하는 역할을 담당
-
L3 Switch와 Router의 차이에 대해 설명해 주세요.
답
차이점
- L3 스위치는 고속의 내부 네트워크 트래픽 처리에 최적화된 반면, 라우터는 네트워크 간의 연결과 복잡한 라우팅 정책을 처리하는 데에 초첨을 맞추고 있음
- L3 스위치는 주로 대량의 데이터를 빠르게 처리해야 하는 LAN 내에서 사용되고, 라우터는 인터넷 접속이나 WAN 환경에서의 데이터 전송을 담당
L3 Switch
- L2 스위치의 기능(고속 패킷 전달 기능) + 라우팅을 하는 장비
- 라우팅 테이블을 참조해서 IP 패킷에 IP 주소를 담아 보냄
Router
- 라우팅 : 하나 이상의 네트워크에서 경로를 선택하는 프로세스
- 라우팅을 하는 장비를 라우터(Router)라고 함
- 다른 네트워크에 존재하는 장치끼리 서로 데이터를 주고받을 때
패킷소모 최소화,경로 최적화하는 장비
-
각 Layer는 패킷을 어떻게 명칭하나요? 예를 들어, Transport Layer의 경우 Segment라 부릅니다.
답
- 물리 계층 : 비트
- 데이터링크 계층 : 프레임
- 네트워크 계층 : 패킷, 데이터그램
- 전송 계층 : 세그먼트
- 세션 계층 : 메시지, 데이터
- 표현 계층 : 메시지, 데이터
- 응용 계층 : 메시지, 데이터
-
각각의 Header의 Packing Order에 대해 설명해 주세요.
답
- 물리 계층
- 헤더 : 없음
- 데이터 링크 계층
- 헤더 : 송신지 MAC 주소, 수신지 MAC 주소, 이더타입
- 패킷 순서와 직접적 관련 정보 없음
- 네트워크 계층
- 헤더 : 송신지 IP 주소, 수신지 IP 주소, TTL, 프로토콜 타입
- 패킷 순서와 관련된 특정 헤더 없음
- 전송 계층
- 헤더 : 송신지 포트 번호, 수신지 포트 번호, 시퀀스 번호, 프로토콜 타입
- 전송 계층의 헤더는 패킷 순서 지정에 중요 역할을 함
- TCP : 헤더에 시퀀스 번호가 포함되어 수신자가 패킷을 올바르게 재정렬
- UDP : 패킷 순서 지정에 대한 것은 없으며, 수신자는 패킷이 도착하면 처리
- 세션 계층
- 패킷 순서와 관련된 특정 헤더 없음
- 표현 계층
- 패킷 순서와 관련된 특정 헤더 없음
- 응용 계층
- 헤더 : 없음
- 물리 계층
-
ARP에 대해 설명해 주세요.
답
ARP (Address Resolution Protocol)
- 논리적인 주소인 IP 주소를 물리적 주소인 MAC 주소로 변환하기 위한 프로토콜
- 그 반대로는
RARP가 있음 - 동작 과정
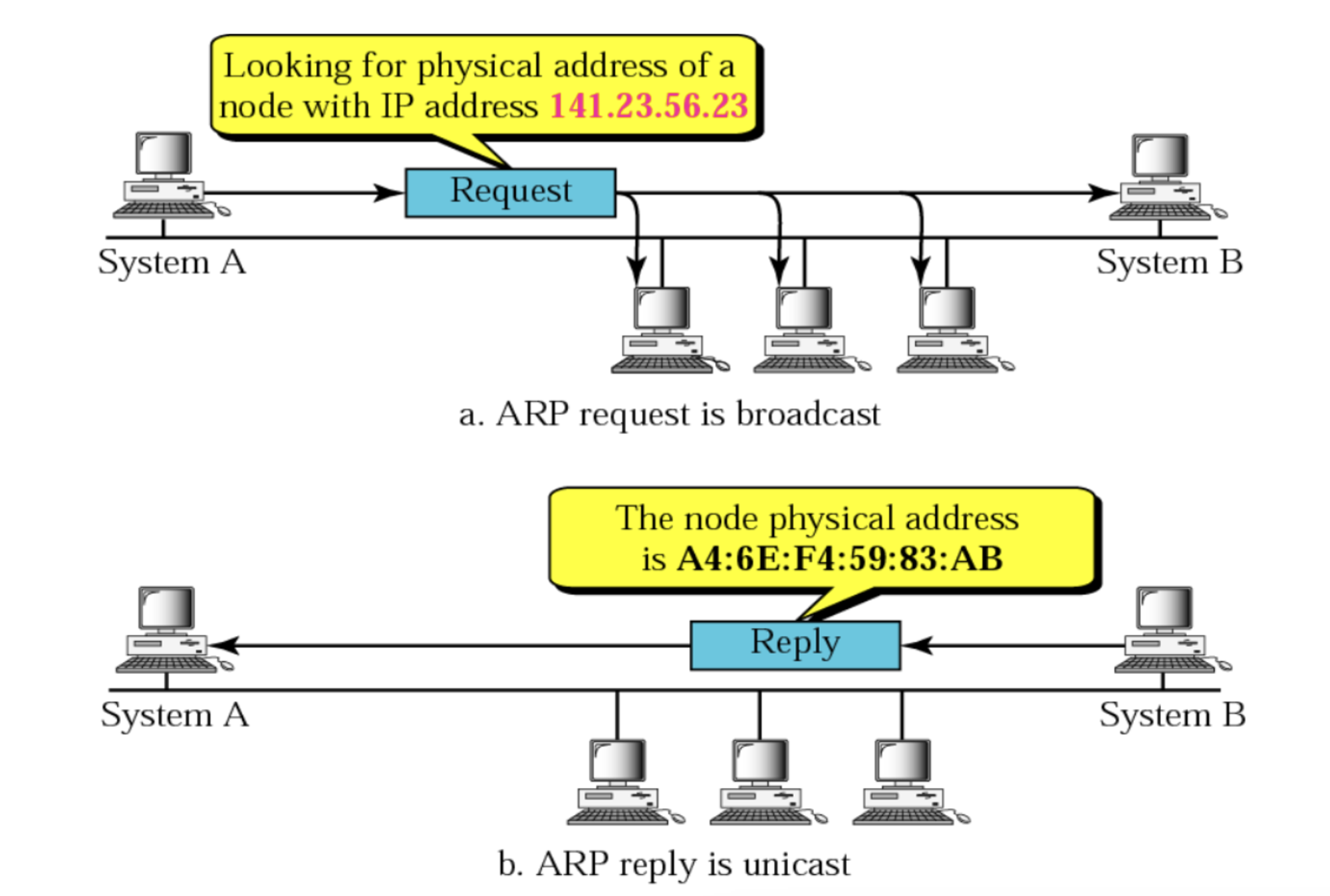
- 해당 IP 주소에 맞는 MAC 주소를 찾기 위해 해당 데이터를
브로드캐스팅을 통해 연결된 네트워크에 있는 장치한테 모두 보냄 - 맞는 장치가 있으면 해당 장치는 보낸 장치에게
유니캐스트로 데이터를 전달해 주소를 찾게 됨
- 해당 IP 주소에 맞는 MAC 주소를 찾기 위해 해당 데이터를
-
11. 3-Way Handshake에 대해 설명해 주세요.
답
3-Way Handshake
- TCP에서 안정적인 통신을 하기 위해 연결하는 절차
- 주고 받는 Flag 값을 바탕으로 3단계로 이루어지기 때문에 3-Way Handshake라고 불림
- 동작 과정
- Client는 Server에게 SYN 플래그를 보냄
- SYN 플래그를 받은 Server는 연결이 가능하다면 SYN 플래그와 ACK 플래그를 함께 보냄
- 연결이 가능하다는 플래그를 받은 Client가 다시 ACK 플래그를 전송함으로서 연결이 맺어짐
-
ACK, SYN 같은 정보는 어떻게 전달하는 것 일까요?
답
패킷을 통해 전달됨
패킷
- 데이터 전송의 기본 단위
- 헤더와 바디로 구성됨
- 헤더 : 목적지 IP 주소, 출발지 IP 주소, 포트 번호, 프로토콜 번호, 체크섬(Checksum) 등의 정보 포함
- 바디 : 실제 전송할 데이터 저장
TCP 패킷 전달 방식
- 플래그를 이용한 정보 전달
- TCP 패킷의 헤더에는 6개의 플래그(URG, ACK, PSH, RST, SYN, FIN)가 있음
- 플래그를 이용하여 ACK, SYN 등의 정보를 전달
- 시퀀스 번호를 이용한 정보 전달
- TCP 패킷의 헤더에는 시퀀스 번호가 포함됨
- 시퀀스 번호 : 데이터 전송 순서를 나타내는 번호
- 시퀀스 번호를 이용하여 데이터 전송 상태를 파악하고, 데이터 전송 오류를 수정할 수 있음
- 체크섬을 이용한 오류 검사
- TCP 패킷의 헤더에는 체크섬이 포함됨
- 체크섬 : 전송된 데이터가 손상되거나 위조되지 않았는지 검사하는 데 사용
- 체크섬 값이 일치하지 않으면, 전송된 데이터가 손상된 것으로 간주하고 재전송을 요청
-
2-Way Handshaking 를 하지 않는 이유에 대해 설명해 주세요.
답
- 2-Way Handshaking은 한 번에 하나의 연결만 설정할 수 있는 반면에 3-Way Handshaking은 여러 개의 연결을 동시에 설정할 수 있음
- 2-Way Handshaking은 연결 설정 과정에서 오류가 발생하면 재시도를 해야 하는 반면에 3-Way Handshaking은 오류가 발생하면 해당 연결을 취소하고 새로운 연결을 설정할 수 있음
-
두 호스트가 동시에 연결을 시도하면, 연결이 가능한가요? 가능하다면 어떻게 통신 연결을 수행하나요?
답
연결 가능함
TCP가 경쟁 윈도우(Contention Window)라는 개념을 사용하여 두 호스트가 동시에 전송할 수 있는 데이터의 양을 제한하여 전송하도록 함
-
SYN Flooding 에 대해 설명해 주세요.
답
SYN Flooding
- 공격자가 서버에 SYN 패킷을 대량으로 전송하여 서버의 자원을 고갈시키는 공격
- 서버가 SYN 패킷을 처리하는 데 많은 시간과 자원을 소모하게 하여 서버의 성능을 저하시키거나 마비시킬 수 있음
-
위 질문과 모순될 수 있지만, 3-Way Handshake의 속도 문제 때문에 이동 수를 줄이는 0-RTT 기법을 많이 적용하고 있습니다. 어떤 방식으로 가능한 걸까요?
답

-
12. 4-Way Handshake에 대해 설명해 주세요.
답
4-Way Handshake
- TCP에서 안정적으로 통신을 끝내고 연결을 끊기 위해 실행되는 프로세스
- 3-Way Handshake와 마찬가지로 Flag 값을 바탕으로 이루어지지만 4단계로 이루어짐
- 전송 순서
- FIN 패킷 전송
- 클라이언트가 서버에 연결 종료를 요청하기 위해 FIN 패킷을 전송
- ACK 패킷 전송
- 서버는 클라이언트의 FIN 패킷을 수신하고, ACK 패킷을 전송
- FIN 패킷 전송
- 서버가 클라이언트에게 연결 종료를 요청하기 위해 FIN 패킷을 전송
- ACK 패킷 전송
- 클라이언트는 서버의 FIN 패킷을 수신하고, ACK 패킷을 전송
- FIN 패킷 전송
-
패킷이 4-way handshake 목적인지 어떻게 파악할 수 있을까요?
답
FIN 플래그를 통해 알 수 있음
-
빨리 끊어야 할 경우엔, (즉, 4-way Handshake를 할 여유가 없다면) 어떻게 종료할 수 있을까요?
답
Abrupt connection release
- RST 세그먼트가 전송되면 갑작스러운 연결 해제가 수행됨
- ACK를 보내거나 기다리는 작업이 필요하지 않고 바로 연결 종료
- RST 비트를 1로 설정한 세그먼트를 전송 → 송신자는 패킷을 보내고 연결을 종료, 수신자는 패킷을 받으면 바로 연결을 종료
RST를 사용해 연결을 종료하는 경우
- 보안 위반의 경우
- 악성 코드가 존재한다고 판단되면 연결을 즉시 종료하여 보호할 수 있음
- 자원이 부족해 자원 할당을 해제해야 하는 경우
- TCP 연결에 장애가 발생한 경우
- 즉시 연결을 끊고 새로운 연결을 시도해 정상적인 통신으로 돌아올 수 있음
-
4-Way Handshake 과정에서 중간에 한쪽 네트워크가 강제로 종료된다면,
반대쪽은 이를 어떻게 인식할 수 있을까요?답
일정 시간 이후 자동으로 해제함, Time wait 상태로 인식
TIME_WAIT 상태
- 연결이 종료된 후, 일정 시간 동안 유지되는 상태
- 이전 연결에서 사용된 포트 번호가 재사용되지 않도록 대기
- 만약 4-Way Handshake 과정에서 중간에 강제로 종료되면, 반대쪽은 해당 연결이 정상적으로 종료되지 않았다고 인식하고, TIME_WAIT 상태를 유지
- TIME_WAIT 상태는 일정 시간(일반적으로 200초)이 지나면 자동으로 해제됨
-
왜 종료 후에 바로 끝나지 않고, TIME_WAIT 상태로 대기하는 것 일까요?
답
TIME_WAIT 상태 대기 이유
- 중복 전송 방지
- 이전 연결에서 사용된 포트 번호가 재사용될 경우, 중복 전송될 수 있음
- 재연결 가능성 유지
- 이전 연결에서 전송된 데이터가 상대방의 버퍼에 남아있을 수 있음 → 상대방이 데이터를 수신하지 못하고 재전송을 요청할 수 있음
- TIME_WAIT 상태를 유지하면 재전송 요청에 대한 응답을 할 수 있음
- 이전 연결에서 전송된 데이터가 상대방의 버퍼에 남아있을 수 있음 → 상대방이 데이터를 수신하지 못하고 재전송을 요청할 수 있음
- 포트 번호 재사용 가능성 확보
- TIME_WAIT 상태에서는 이전 연결에서 사용된 포트 번호가 재사용되지 않음 → 다른 연결이 해당 포트 번호를 사용하는 것을 방지하기 위함
- TIME_WAIT 상태에서는 이전 연결에서 사용된 포트 번호가 재사용되지 않음 → 다른 연결이 해당 포트 번호를 사용하는 것을 방지하기 위함
- 중복 전송 방지
-
13. www.github.com을 브라우저에 입력하고 엔터를 쳤을 때, 네트워크 상
어떤 일이 일어나는지 최대한 자세하게 설명해 주세요.답
- www.github.com을 IP 주소로 변환하기 위해 DNS 쿼리 수행
- DNS 서버에서 도메인 이름에 맞는 IP 주소 반환
- DNS 연결을 통해 얻은 IP 주소를 기반으로 TCP 연결 설정
- TCP 연결은 3-Way Handshake 과정을 통해 이루어짐
- TCP 연결이 설정되면 클라이언트는 HTTP 요청을 서버에 전송
- 서버는 HTTP 요청을 수신하고, 해당 요청에 대한 HTTP 응답을 클라이언트에게 전송
- 클라이언트는 HTTP 응답을 수신하고, 해당 응답의 바디에 있는 데이터를 추출하여 화면에 출력 or 저장 or 처리
- 더 이상 전송할 데이터가 없으면 TCP 연결 종료
- TCP 연결 종료는 4-Way Handshake 과정을 통해 이루어짐
- www.github.com을 IP 주소로 변환하기 위해 DNS 쿼리 수행
-
DNS 쿼리를 통해 얻어진 IP는 어디를 가리키고 있나요?
답
- 쿼리를 통해 요청한 도메인 이름에 맞는 서버의 IP를 가리키고 있음
- 해당 도메인 이름을 가진 웹사이트나 서버의 실제 위치를 나타냄
-
Web Server와 Web Application Server의 차이에 대해 설명해 주세요.
답
차이점
Web Server Web Application Server 주로 정적인 콘텐츠 제공에 특화되어 있음 동적인 컨텐츠 생성 및 애플리케이션 로직 실행에 특화되어 있음 Apache HTTP Server, Nginx … Apache Tomcat, JBoss, IBM WebSphere, Oracle WebLogic Web Server
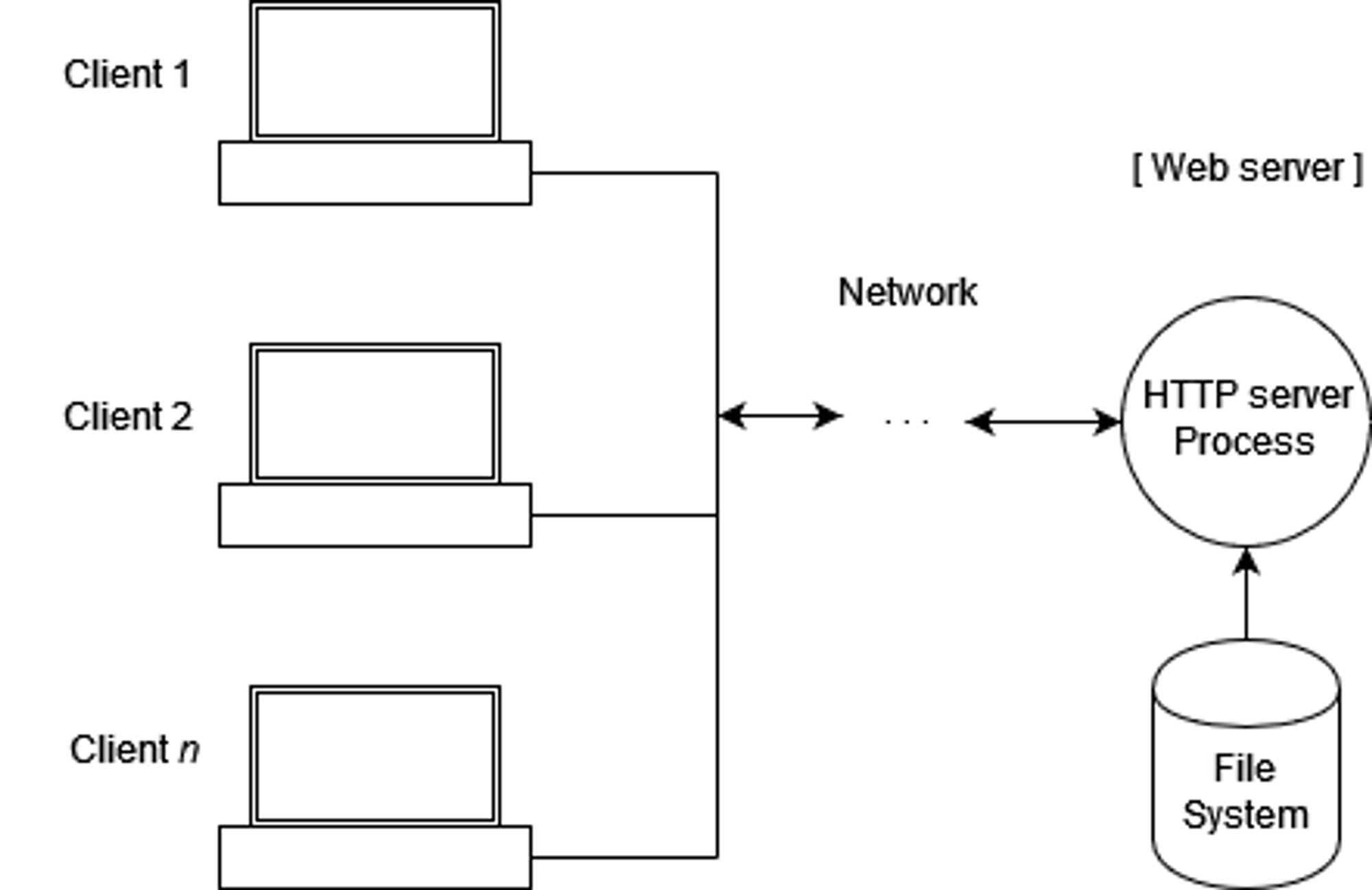
- 클라이언트로부터 HTTP 요청을 받아 정적인 웹 페이지를 제공
- HTML, CSS, JavaScript, 이미지 등 정적인 콘텐츠를 제공
- HTTP 프로토콜 기반으로 동작하며, 클라이언트와의 요청 및 응답을 처리
Web Application Server
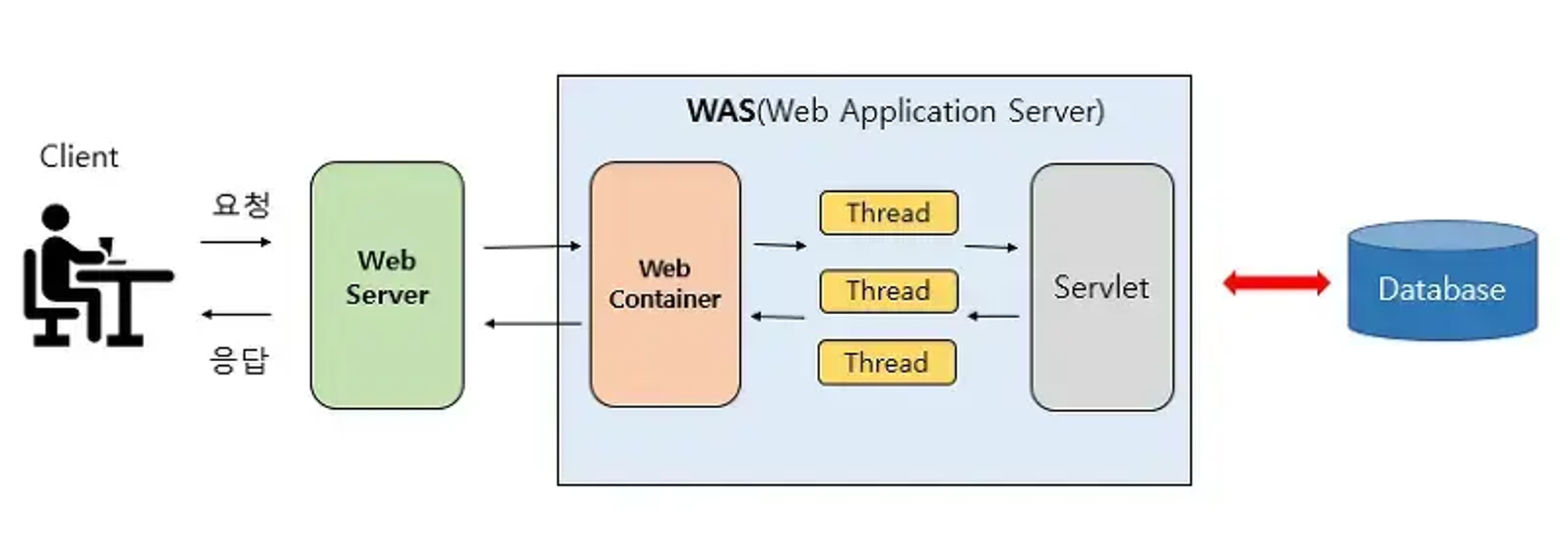
- 동적인 웹 애플리케이션을 실행하고 관리
- 애플리케이션 로직 실행, 데이터베이스 연동, 트랜잭션 관리, 보안, 세션 관리 등을 처리
- Java EE(Enterprise Edition) 기반의 애플리케이션 서버로, JSP, Servlet 등의 개발을 지원
-
URL, URI, URN은 어떤 차이가 있나요?
답
URL (Uniform Resource Locator)
- 자원의 위치를 나타내는 문자열
- 자원에 접근하기 위한 경로를 제공
URI (Uniform Resource Identifier)
- 자원을 식별하기 위한 문자열
- URL과 URN을 포함하는 개념
- 자원을 식별하기 위한 식별자를 제공
URN (Uniform Resource Name)
- 자원의 이름을 나타내는 문자열
- 영구적인 식별자를 제공
- 자원의 이름을 나타냄
- 자원이 이동하거나 변경되어도 동일한 자원을 참조할 수 있음
ex) urn:isbn:978-3-16-148410-0
-
14. DNS에 대해 설명해 주세요.
답
DNS (Domain Name Server)
- 각 도메인에 실질적으로 매핑되는 IP 주소를 반환해주는 서버
- 특정 웹을 사용함에 있어서 해당 웹의 어려운 IP 주소를 사용하는게 아니라 간편하게 도메인을 사용할 수 있게 해주는 역할을 하는 Server
- DNS에 없는 도메인은 DNS의 DNS에 요청될 수 있음
-
DNS는 몇 계층 프로토콜인가요?
답
- 3계층 프로토콜임
- 네트워크 계층(Network Layer)에서 동작
- DNS 서버와 클라이언트 간의 통신을 통해 도메인 이름을 IP 주소로 변환
-
UDP와 TCP 중 어떤 것을 사용하나요?
답
- UDP(User Datagram Protocol) 사용
- 도메인 이름을 IP 주소로 변환하는 작업이 빠르게 이루어져야 하기 때문에 UDP를 사용하여 빠른 응답 속도 보장
-
DNS Recursive Query, Iterative Query가 무엇인가요?
답
Recursive Query
- DNS 서버가 자신이 가지고 있는 정보를 이용하여 IP 주소를 찾지 못하면 상위 DNS 서버에 재귀적으로 쿼리를 보내는 방식
Iterative Query
- DNS 서버가 자신이 가지고 있는 정보를 이용하여 IP 주소를 찾지 못하면 클라이언트에게 상위 DNS 서버의 주소를 알려주고, 클라이언트가 직접 상위 DNS 서버에 쿼리를 보내는 방식
-
DNS 쿼리 과정에서 손실이 발생한다면, 어떻게 처리하나요?
답
- 클라이언트는 일정 시간이 지난 후 요청을 재전송 시도 → 재전송 횟수는 제한되어 있으며, 제한된 횟수 내에 응답 받지 못하면 오류로 처리함
- 클라이언트는 일정 시간이 지난 후 요청을 재전송 시도 → 재전송 횟수는 제한되어 있으며, 제한된 횟수 내에 응답 받지 못하면 오류로 처리함
-
캐싱된 DNS 쿼리가 잘못 될 수도 있습니다. 이 경우, 어떻게 에러를 보정할
수 있나요?답
- 캐시 정보의 TTL(Time-To-Live) 값이 만료되면 자동으로 삭제하고 새로운 요청이 발생했을 때 최신 정보를 다시 조회하여 캐시를 갱신하는 방식으로 에러 보정
- 관리자가 수동으로 DNS 캐시를 클리어하여 에러 보정
-
DNS 레코드 타입 중 A, CNAME, AAAA의 차이에 대해서 설명해주세요.
답
- A : 도메인 이름을 IPv4 주소로 매핑
- CNAME : 도메인 이름을 다른 도메인 이름으로 매핑 (주로 별칭 설정 때 사용)
- AAAA : 도메인 이름을 IPv6 주소로 매핑
-
hosts 파일은 어떤 역할을 하나요? DNS와 비교하였을 때 어떤 것이 우선순위가 더 높나요?
답
Hosts 파일
- 운영체제가 도메인 이름을 IP 주소로 변환할 때 참조하는 로컬 파일
- 이 파일에 특정 도메인 이름과 해당 IP 주소를 직접 매핑할 수 있음
- DNS 조회 전에 hosts 파일을 먼저 확인 → hosts 파일에 정의된 매핑이 DNS 서버에서 제공하는 정보보다 우선적으로 적용됨 → 테스트 환경 구성이나 특정 사이트 차단과 같은 목적으로 사용될 수 있음
-
15. SOP 정책에 대해 설명해 주세요.
답
SOP (Same-Origin Policy) 정책
- 웹 보안의 핵심 원칙 중 하나
- 웹 브라우저가 다른 출처의 리소스와 상호작용하는 방법을 제한하는 정책
- 출처 : 프로토콜, 호스트(도메인), 포트 세 가지 조합으로 정의
- 스크립트는 동일 출처에서만 리소스를 요청하거나 상호작용 할 수 있으며, 다른 출처의 리소스에는 접근할 수 없음
- XSS, CSRF와 같은 보안 취약점을 방지하는데 도움됨
-
CORS 정책이 무엇인가요?
답
CORS (Cross-Origin Resource Sharing) 정책
- SOP 정책의 제한을 완화하기 위해 도입된 메커니즘
- 웹 서버가 다른 출처의 웹페이지에서 자신의 리소스에 대한 접근을 허용할 수 있도록 하는 규칙과 헤더 정의
- 서버는 Access-Control-Allow-Origin과 같은 HTTP 헤더를 사용하여 특정 출처에서 자신의 리소스에 접근하는 것을 허용하거나 거부할 수 있음 → 개발자는 안전한 방식으로 다른 출처의 리소스를 요청할 수 있음 ++ 웹 애플리케이션의 통합성과 상호 운용성을 높일 수 있음
-
Preflight에 대해 설명해 주세요.
답
Preflight
- CORS 정책을 따르는 웹 애플리케이션에서 실제 요청을 보내기 전에 서버에 보내는 사전 요청
- OPTIONS 메소드를 사용하여 수행됨
- 실제 요청에서 사용될 HTTP 메소드와 헤더 등을 포함함
- 주로 안전하지 않은 요청을 보내기 전에 수행됨 → 서버는 실제 요청을 처리하기 전에 출처와 HTTP 메소드의 유효성을 검사할 수 있음
- 불필요한 네트워크 트래픽과 잠재적인 보안 위험을 줄이기 위해 사용
-
16. Stateless와 Connectionless에 대해 설명해 주세요.
답
Stateless (상태 비저장)
- 서버가 이전에 받았던 요청의 정보나 상태를 저장하지 않고 각 요청을 독립적으로 처리하는 방식
- 클라이언트와 서버 간의 통신 요청이 서로 독립적이며 서버는 과거의 요청에 대한 정보를 유지하지 않음
Connectionless (비연결성)
- 통신하는데 있어서 세션을 유지하지 않고 각 메시지를 독립된 패킷으로 처리하는 방식
- 각 패킷은 다른 패킷과 독립적이며, 메시지를 전송하기 위해 미리 연결을 설정할 필요 없음
-
왜 HTTP는 Stateless 구조를 채택하고 있을까요?
답
- 단순성과 확장성
- 서버가 클라이언트의 상태를 추적하거나 저장할 필요가 없기 때문에 구현이 단순해지고 서버의 부담이 줄어듬 ⇒ 웹 서비스의 확장성을 크게 향상시킴
- 서버가 클라이언트의 상태를 추적하거나 저장할 필요가 없기 때문에 구현이 단순해지고 서버의 부담이 줄어듬 ⇒ 웹 서비스의 확장성을 크게 향상시킴
- 무상태성에 따른 독립성
- 각 요청이 독립적으로 처리되기 때문에 서버의 처리 과정에서 발생할 수 있는 의존성 문제를 방지할 수 있음
- 캐싱 용이성
- Stateless 구조는 응답을 캐싱하기 쉽게 만듬 → 네트워크 트래픽과 서버 부하를 줄이는데 도움 됨
- Stateless 구조는 응답을 캐싱하기 쉽게 만듬 → 네트워크 트래픽과 서버 부하를 줄이는데 도움 됨
- 단순성과 확장성
-
Connectionless의 논리대로면 성능이 되게 좋지 않을 것으로 보이는데, 해결 방법이 있을까요?
답
- HTTP Keep-Alive 사용
- 여러 HTTP요청과 응답을 하나의 TCP 연결을 통해 전송할 수 있게 함으로써, 연결 설정과 해제에 따른 오버헤드를 줄이고 전체적인 통신 성능을 향상 시킴
- HTTP Keep-Alive 사용
-
TCP의 keep-alive와 HTTP의 keep-alive의 차이는 무엇인가요?
답
차이점
- TCP Keep-Alive는 연결의 유효성을 확인하는데 초점을 맞춘 반면, HTTP Keep-Alive는 성능 최적화와 연결 오버헤드를 줄이는데 사용됨
TCP Keep-alive
- TCP 수준에서 연결이 여전히 활성 상태인지 확인하기 위해 사용되는 기능
- 일정 시간동안 데이터 교환이 없을 경우, Keep-Alive 패킷을 송수신하여 연결이 유효한지 검사함
HTTP Keep-Alive
- HTTP 프로토콜 수준에서 동작하며, 클라이언트와 서버 간에 여러 HTTP 요청/응답을 하나의 TCP 연결을 통해 처리할 수 있도록 함
- TCP 연결의 설정과 해제에 따른 지연과 오버헤드를 줄여 성능을 향상시킴
-
17. 라우터 내의 포워딩 과정에 대해 설명해 주세요.
답
Forwarding(포워딩)
- 라우터 내에서 이루어지는 패킷 처리 과정
- 라우터가 수신한 패킷을 목적지 주소에 기반하여 다음 홉(next hop)으로 전달하는 과정을 말함
- 과정
- 패킷 수신 : 라우터의 인터페이스는 네트워크로부터 패킷 수신
- 목적지 주소 확인 : 라우터는 패킷의 헤더에서 목적지 IP 주소 확인
- 포워딩 테이블 조회 : 라우터는 내부의 포워딩 테이블을 조회하여, 해당 목적지 주소에 대한 최적의 경로 결정
- 패킷 전달 : 결정된 다음 홉으로 패킷을 전달하기 위해, 패킷은 적절한 인터페이스로 전송
-
라우팅과 포워딩의 차이는 무엇인가요?
답
라우팅
- 네트워크 전체의 경로를 결정하는 과정
- 라우터가 전체 네트워크의 구조를 이해하고, 다양한 가능 경로 중 특정 목적지로 가는 최적의 경로를 선택하는 과정 포함
- 라우팅 프로토콜을 통해 이루어짐
- 라우팅을 통해 생성된 정보는 포워딩 테이블에 저장됨
포워딩
- 실제로 패킷을 수신하여 목적지로 전달하는 과정
- 라우터가 포워딩 테이블을 참조하여 수행하는 더 빠르고 효율적인 절차
-
라우팅 알고리즘에 대해 설명해 주세요.
답
- 정적 라우팅: 네트워크 관리자가 수동으로 경로 설정
- 동적 라우팅 : 라우팅 프로토콜을 사용하여 상태 변경에 따라 경로 자동 조정
- 거리 벡터 라우팅 : 각 라우터가 인접한 라우터와 거리(비용) 정보를 교환하여 경로 설정
- 링크 상태 라우팅 : 네트워크의 전체적인 상태를 바탕으로 최적의 경로 결정
-
포워딩 테이블의 구조에 대해 설명해 주세요.
답
포워딩 테이블
- 라우터가 패킷을 전달할 때 참조하는 데이터 베이스
- 구조
- 목적지 네트워크 주소 : 패킷의 목적지 IP 주소 또는 네트워크 주소 범위
- 다음 홉 주소 : 해당 목적지로 가는 경로에서 다음으로 전달해야 할 라우터 주소
- 출구 인터페이스 : 패킷이 전송된 라우터 인터페이스
- 메트릭 : 목적지까지의 경로 비용을 나타내는 값
-
18. 로드밸런서가 무엇인가요?
답
로드 밸런서 (Load Balancer)
- 여러 서버에 걸쳐 인터넷 트래픽이나 네트워크 요청을 분산 시켜주는 장치 또는 소프트웨어
- 시스템의 가용성과 내구성을 높이는 것을 목적으로 함
- 한 서버에 과부하가 발생하는 것을 방지하고, 모든 사용자 요청에 대해 높은 처리 성능을 유지함
-
L4 로드밸런서와, L7 로드밸런서의 차이에 대해 설명해 주세요.
답
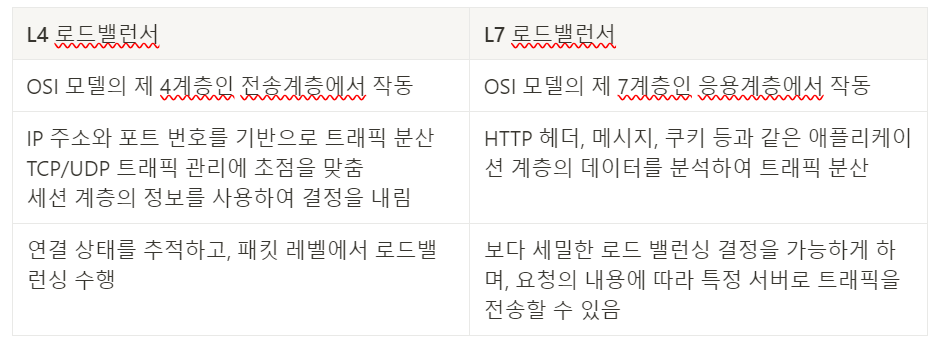
-
로드밸런서 알고리즘에 대해 설명해 주세요.
답
- 라운드 로빈
- 요청을 순차적으로 각 서버에 분배
- 가장 단순하고 균등한 분배 방식
- 가중 라운드 로빈
- 각 서버의 처리 능력에 가중치를 부여하고, 가중치에 따라 요청 분배
- 최소 연결
- 현재 연결 수가 가장 적은 서버에 요청 할당
- 동적인 트래픽에 적합함
- IP 해시
- 클라이언트의 IP 주소를 해싱하여 특정 서버에 요청을 지속적으로 할당
- 세션 유지에 유리함
- 라운드 로빈
-
로드밸런싱 대상이 되는 장치중 일부 장치가 문제가 생겨 접속이 불가능하다고 가정해 봅시다. 이 경우, 로드밸런서가 해당 장비로 요청을 보내지 않도록 하려면 어떻게 해야 할까요?
답
- 헬스 체크 기능을 통해 서버의 가용성을 모니터링
- 서버에 문제가 생겨 접속이 불가능한 경우, 해당 서버는 로드밸런싱 대상에서 제외되고 요청은 가용성이 확인된 다른 서버로 전송됨
-
로드밸런서 장치를 사용하지 않고, DNS를 활용해서 유사하게 로드밸런싱을 하는 방법에 대해 설명해 주세요.
답
DNS 로드밸런싱
- DNS 서버가 도메인 이름에 대한 요청에 응답할 때 여러 서버의 IP 주소 중 하나를 선택하여 반환
- 비교적 간단하게 구현할 수 있지만 DNS 캐싱으로 인해 로드밸런싱의 민감도가 떨어질 수 있음
- DNS 쿼리에 기반한 헬스 체크나 세밀한 트래픽 제어가 어려움
-
19. 서브넷 마스크와, 게이트웨이에 대해 설명해 주세요.
답
서브넷 마스크 (Subnet Mask)
- IP 주소를 네트워크 주소와 호스트 주소로 구분하는 데 사용되는 숫자
- 서브넷 마스크를 통해 하나의 큰 네트워크를 여러 개의 작은 서브넷으로 나눌 수 있음 → IP 주소의 할당을 더욱 효율적으로 관리할 수 있음
- IP 주소와 동일한 형식으로 표현됨
- 네트워크 부분을 나타내는 비트에는 1, 호스트 부분을 나타내는 비트에는 0 사용
게이트웨이 (Gateway)
- 서로 다른 네트워크 간의 통신을 가능하게 해주는 네트워크 포인트
- 로컬 네트워크에서 인터넷과 같은 외부 네트워크로 데이터를 전송하거나 그 반대의 경우에 게이트웨이 통과
- 가정이나 사무실에서 사용하는 라우터는 게이트웨이의 역할을 함
- 로컬 네트워크 기기들이 인터넷에 접속할 수 있도록 중계함
-
NAT에 대해 설명해 주세요.
답
NAT (Network Address Translation)
- 로컬 네트워크에서 사용하는 사설 IP 주소를 외부 네트워크에서 사용하는 공개 IP 주소로 변환하는 과정
- 주로 IP 주소의 부족 문제를 해결하고, 내부 네트워크의 보안을 강화하기 위해 사용됨
-
서브넷 마스크의 표현 방식에 대해 설명해 주세요.
답
- 점 표기법 (Dot-decimal notation)
- IP 주소와 유사하게 점으로 구분된 4개의 8비트 숫자로 표현됨
- CIDR 표기법 (Classless Inter-Domain Routing notation)
- / 뒤에 네트워크 부분의 비트 수를 나타내는 숫자를 붙여 표현함
- 점 표기법 (Dot-decimal notation)
-
그렇다면, 255.0.255.0 같은 꼴의 서브넷 마스크도 가능한가요?
답
- 일반적으로 서브넷 마스크는 연속적인 1 뒤에 연속적인 0이 오는 형태로 구성되어야 함
- 255.0.255.0 같은 형태는 표준적인 서브넷 마스크로 사용되지 않음 → 네트워크 주소와 호스트 주소를 명확하게 구분하지 못하게 만듦 → 네트워킹 장비나 소프트웨어에서 오류나 예기치 않은 동작을 일으킬 수 있기 때문
-
20. 멀티플렉싱과 디멀티플렉싱에 대해 설명해 주세요.
답
멀티플렉싱 (Multiplexing)
- 여러 개의 신호나 데이터 스트림을 하나의 통신 채널이나 매체를 통해 동시에 전송하는 과정
- 효율적인 데이터 전송을 가능하게 하며, 통신 네트워크에서 널리 사용됨
- 대표적으로 시분할 멀티플렉싱(TDM), 주파수 분할 멀티플렉싱(FDM), 코드 분할 멀티플렉싱(CDM) 등이 있음
디멀티플렉싱 (Demultiplexing)
- 멀티플렉싱된 신호나 데이터 스트림을 받아 원래의 개별 신호나 데이터 스트림으로 분리하는 과정
- 수신 측에서 이루어지며, 멀티플렉싱 과정을 역으로 수행하여 각 신호나 데이터 스트림을 원래의 독립된 채널로 복원함
-
디멀티플렉싱의 과정에 대해 설명해 주세요.
답
- 수신
- 멀티플렉싱을 통해 복합된 신호나 데이터 스트림을 수신
- 식별
- 수신된 복합 신호에서 각 개별 신호나 데이터 스트림을 식별할 수 있는 정보를 분석
- 분리
- 식별된 정보를 기반으로 복합 신호를 개별 신호나 데이터 스트림으로 분리
- 사용 기술
- TDM에서의 디멀티플렉싱 : 시간 슬롯에 따라 신호 분리
- FDM에서의 디멀티플렉싱 : 주파수 필터를 사용하여 주파수 대역 분리
- CDM에서의 디멀티플렉싱 : 각 신호에 할당된 고유 코드를 사용하여 분리
- 복원
- 분리된 각 신호나 데이터 스트림을 원래의 형태로 복원하여 적절한 출력 채널로 전송
- 수신
-
21. XSS에 대해서 설명해 주세요.
답
XSS(Cross-Sitd Scripting)
- 웹 애플리케이션의 보안 취약점 중 하나
- 공격자가 사용자의 브라우저에서 실행될 수 있는 스크립트를 삽입하는 공격
- 분류
- 저장된 XSS : 공격자가 웹 애플리케이션에 악의적인 스크립트 저장
- 반사된 XSS : 사용자로부터 받은 입력을 즉시 웹페이지에 반영할 때 악의적인 스크립트 실행, 주로 링크를 통해 사용자에게 전달
- DOM 기반 XSS : DOM 취약점을 이용하여 악의적인 스크립트 실행
-
CSRF랑 XSS는 어떤 차이가 있나요?
답
차이점
- XSS는 공격자가 사용자 측에서 스크립트를 실행하여 사용자의 데이터를 탈취하거나 조작하는 공격이며, CSRF는 사용자가 이미 인증된 상태에서 공격자가 준비한 악의적인 행위를 서버에 요청하게 만드는 공격
- XSS는 클라이언트 사이드에서 발생하는 반면, CSRF는 서버 사이드에서 발생
CSRF (Cross-Site Request Forgery)
- 사용자가 이미 로그인한 세션을 이용하여 사용자의 의지와 무관하게 공격자가 준비한 악의적인 행위를 웹 애플리케이션에 요청하게 만드는 공격
- 사용자 인증 정보를 이용하여 악의적인 변경을 요청하는 공격
-
XSS는 프론트엔드에서만 막을 수 있나요?
답
- 프론트와 백엔드 양쪽에서 모두 막을 수 있음
- 방어 기법
- 입력 검증 및 살균 (Sanitization)
- 사용자 입력을 적절히 검증하고, 스크립트나 HTML 태그 같은 위험 요소를 제거하거나 무해화 함
- 콘텐츠 보안 정책 (CSP)
- 웹 서버에서 CSP 헤더를 설정하여, 웹 페이지에서 실행할 수 있는 스크립트의 출처를 제한함
- HTTPOnly 쿠키
- 쿠키에 HTTPOnly 속성을 설정하여 JavaScript를 통한 쿠키의 접근을 방지함
- 출력 인코딩
- 데이터를 웹 페이지에 출력할 때 HTML 엔티티 인코딩을 사용하여 스크립트가 실행되지 않도록 함
- 입력 검증 및 살균 (Sanitization)
해당 글은 보초님 깃허브의 질문을 가지고 작성한 글입니다.
출처
https://velog.io/@98soonrok/CS공부-네트워크-3
https://velog.io/@opixxx/네트워크-OSI-7-계층
https://datacook.tistory.com/107
https://blog.naver.com/solinsystem/222424413049
https://velog.io/@dbghwns11/CS-정리-11
https://iuboost.tistory.com/entry/XSSCross-Site-Scripting

잘 봤습니다 :)