
-
Key (기본키, 후보키, 슈퍼키 등등...) 에 대해 설명해 주세요.
답
키(Key)
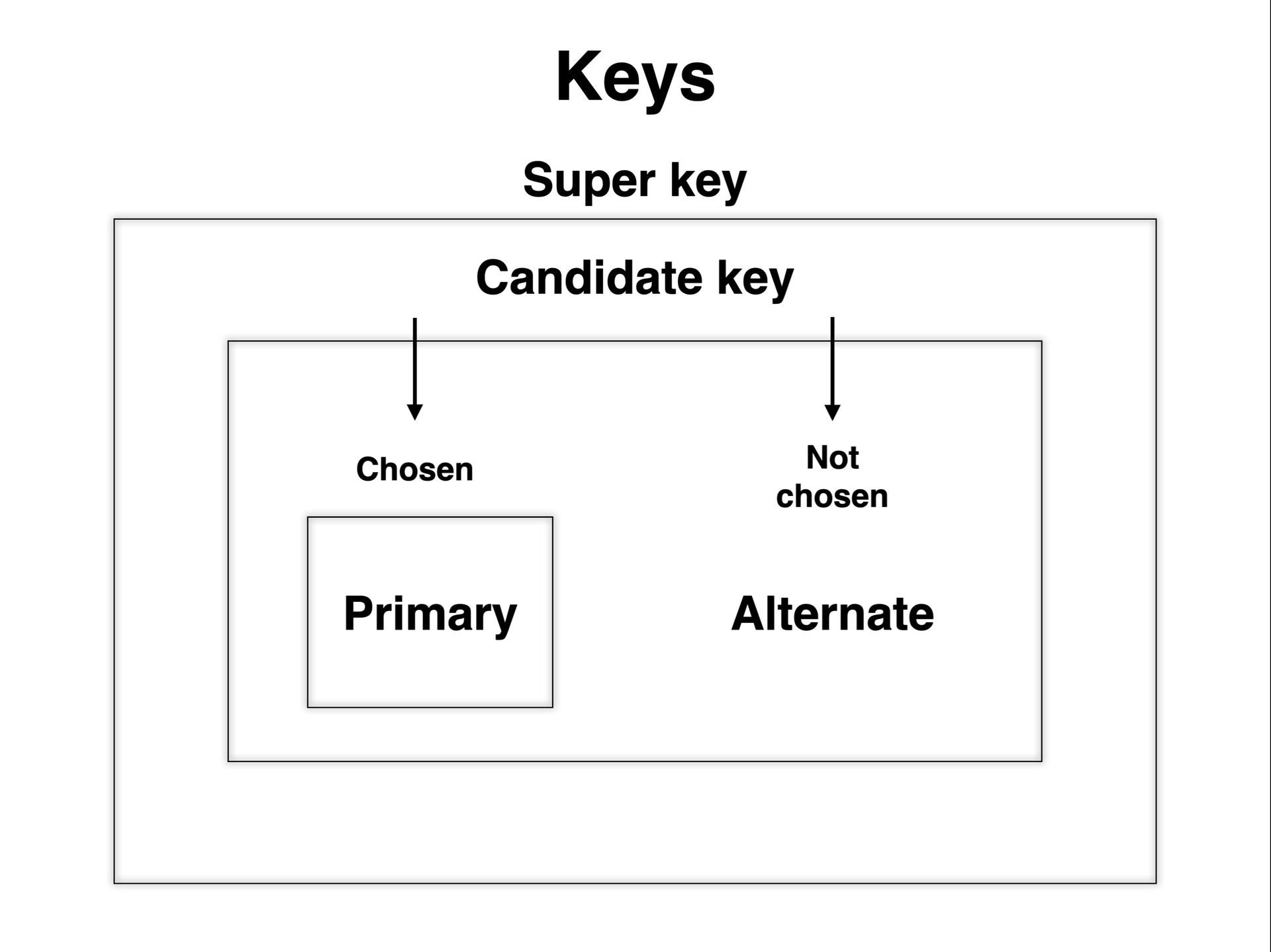
- 데이터베이스에서 조건에 맞는 튜플을 찾거나 순서대로 정렬할 때 기준이 되는 속성
- 특정 데이터를 검색하거나 정렬하고 싶을 때 키를 통해 원하는 값을 얻고 식별할 수 있음
- 종류
- 기본키(Primary key) : 유일무이한 값을 가진 키
- 후보키(Candidate key) : 기본키의 부분집합
- 대체키(Alternate key) : 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키
- 외래키(Foreign key) : 두 개의 테이블을 연결해 관계를 맺어주는 기준이 되는 키
- 슈퍼키(Super key) : 튜플을 고유하게 식별하는 키
- 복합키(Composite key) : 튜플을 식별할 수 있는 두 개 이상의 속성들로 구성된 후보키
- 기본키는 수정이 가능한가요?
답
연관관계가 존재하지 않는 기본키는 수정이 가능하지만, 잦은 수정은 지양하는 것이 좋음
- 사실 MySQL의 경우, 기본키를 설정하지 않아도 테이블이 만들어집니다. 어떻게 이게 가능한 걸까요?
답
MySQL에서 자체적으로 테이블의 속성 중 값에 NULL이 없고, 레코드마다 값이 고유한 첫 속성을 골라 클러스터형 인덱스로 지정하기 때문임
→ 기본키 또는 적절한 고유값의 인덱스가 존재하지 않는다면, InnoDB가 자체적으로 클러스터형 인덱스를 생성함
- 외래키 값은 NULL이 들어올 수 있나요?
답
들어올 수 있다.
- 어떤 칼럼의 정의에 UNIQUE 키워드가 붙는다고 가정해 봅시다. 이 칼럼을 활용한 쿼리의 성능은 그렇지 않은 것과 비교해서 어떻게 다를까요?
답
초반에 값을 추가할 때는 전체 칼럼을 검색해야 하기 때문에 느릴 수 있다. 하지만 추후에는 유니크 값이 보장되므로 빠르게 검색할 수 있다.
-
RDB와 NoSQL의 차이에 대해 설명해 주세요.
답
RDB (Relational Database)
- 관계형 데이터 모델에 기초를 둔 데이터베이스
- 데이터의 독립성이 높음
- RDBMS는 관계형 데이터베이스를 생성하고 수정하고 관리하는 소프트웨어
NoSQL (Not Only SQL)
- RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미
- RDBMS와 달리 테이블 간 관계를 정의하지 않음
- 일반적으로 테이블 간 Join 불가능
- NoSQL의 강점과, 약점이 무엇인가요?
답
NoSQL의 특징
- UPDATE/DELETE을 잘 사용하지 않음 → Insert로 대체
- 강한 Consistency를 요구하지 않음
- 노드의 추가/삭제 및 데이터 분산에 유연함
- 모델링이 유연함
- 쿼리가 유연함
NoSQL의 강점
- 스키마가 없어서 유연하고 자유로운 데이터 구조를 가짐 → 언제든지 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있음
- 데이터 분산이 용이함
- 성능 향상을 위해 Scale-up과 Scale-out 둘 다 활용이 가능함
NoSQL의 약점
- 데이터 중복이 발생할 수 있음
- 데이터 무결성, 정합성이 보장되지 않음
- 중복된 데이터가 변경되면 수정을 모든 컬렉션에서 수행해야 함
- 스키마가 없어서 명확한 데이터 구조를 보장할 수 없음
- RDB의 어떠한 특징 때문에 NoSQL에 비해 부하가 많이 걸릴 "수" 있을까요? (주의: 무조건 NoSQL이 RDB 보다 빠르다라고 생각하면 큰일 납니다!)
답
테이블 간의 관계를 맺고 있는 특징 때문에 시스템이 커졌을 때 Join문이 많아져 NoSQL에 비해 부하가 많이 걸릴 수 있음
- NoSQL을 활용한 경험이 있나요? 있다면, 왜 RDB를 선택하지 않고 해당 DB를 선택했는지 설명해 주세요.
답
없음
-
트랜잭션이 무엇이고, ACID 원칙에 대해 설명해 주세요.
답
트랜잭션 (Transaction)
- 데이터베이스의 상태를 변화시키기 위해 수행하는 작업의 단위
ACID 원칙
- Atomicity (원자성)
- 트랜잭션이 데이터베이스에 모두 반영되거나, 전혀 반영되지 않아야 함
- 트랜잭션의 원자성은 롤백 세그먼트에 의해 보장됨
- Consistency (일관성)
- 트랜잭션이 진행되는 동안에 데이터베이스가 변경되더라도 처음에 참조한 데이터베이스로 트랜잭션을 수행 → 업데이트된 데이터베이스는 사용하지 않음
- 사용자는 일관성있는 데이터를 볼 수 있음
- Isolation (고립성)
- 둘 이상의 트랜잭션이 동시에 실행되고 있는 경우, 각각 다른 트랜잭션의 연산에 끼어들 수 없음
- 이 트랜잭션이 완료될 때까지 다른 트랜잭션은 이 트랜잭션의 결과를 참조할 수 없음
- Durability (지속성)
- 트랜잭션이 성공적으로 완료됐을 경우, 결과는 영구적으로 반영되어야 함
- ACID 원칙 중, Durability를 DBMS는 어떻게 보장하나요?
답

- 트랜잭션을 사용해 본 경험이 있나요? 어떤 경우에 사용할 수 있나요?
답
사용해본적 없음
하나의 엔티티에 여러 작업이 동시에 수행될 가능성이 존재하면 사용할 수 있음
작업이 한 번에 반영되야 하는 것을 보장해야할 때 사용하는 것이 좋음
ex) 은행 이체
- 읽기에는 트랜잭션을 걸지 않아도 될까요?
답
읽기 연산만 일어나면 데이터의 변경이 일어나지 않으므로 트랜잭션을 걸지 않아도 됨
하지만 상황에 따라 트랜잭션을 걸어야 하는 경우도 있음
트랜잭션을 걸어야 하는 읽기 작업
- 읽기 작업에서 읽어온 데이터가 다른 사용자에 의해 변경될 가능성이 있는 경우
- 읽기 작업에서 읽어온 데이터를 다른 작업에서 사용하는 경우
- 등등
-
트랜잭션 격리 레벨에 대해 설명해 주세요.
답
트랜잭션 격리 레벨(Transaction Isolation Level)
- 데이터베이스에서 트랜잭션이 실행될 때, 다른 트랜잭션이 실행하는 데이터에 접근하는 방식을 결정하는 개념
- 트랜잭션 수준 읽기 일관성을 지키기 위해 필요
- 종류
- Read Uncommitted
- 가장 낮은 격리 레벨
- 다른 트랜잭션이 커밋하지 않은 데이터를 볼 수 있음
- 데이터 일관성이 보장되지 않을 수 있음
- Read Committed
- 다른 트랜잭션이 커밋한 데이터만 볼 수 있음
- 데이터 일관성이 보장됨
- Repeatable Read
- 트랜잭션이 시작될 때 읽은 데이터는 트랜잭션이 끝날 때까지 변하지 않음
- 데이터 일관성이 보장됨
- Serializable
- 가장 높은 격리 레벨
- 트랜잭션이 실행되는 동안 다른 트랜잭션이 동일한 데이터를 변경할 수 없음
- 데이터 일관성이 가장 높게 보장됨
- Read Uncommitted
-
모든 DBMS가 4개의 레벨을 모두 구현하고 있나요? 그렇지 않다면 그 이유는 무엇일까요?
답

-
만약 MySQL을 사용하고 있다면, (InnoDB 기준) Undo 영역과 Redo 영역에 대해 설명해 주세요.
답
Undo 영역
- 트랜잭션 실행 후 롤백 시 언두 로그를 참조에 이전 데이터로 복구할 수 있도록 로깅한 영역
- Undo Record 영역 : 로그 버퍼에 기록된 Undo Log 영역
- 언두 로그는 체크포인트에만 디스크에 기록되는데, 너무 긴 트랜잭션이나 무거운 롤백을 주의해야함
Redo 영역
- Redo Log : 데이터베이스 장애 발생시 복구에 사용되는 로그
- 데이터 변경이 있으면 Redo Log에 기록하는데, 이는 DML, DDL, TCL 등 데이터 변경이 일어나는 모든 것을 기록한다는 뜻
- 체크포인트 발생 전에 버퍼풀에 있던 데이터는 유실되지만 마지막 체크포인트 수행 시점까지의 데이터가 Redo Log File로 남아있어 이 파일을 사용해 데이터를 복구할 수 있음
-
그런데, 스토리지 엔진이 정확히 무엇을 하는 건가요?
답
스토리지 엔진
- 물리적 저장장치에서 데이터를 읽어옴
- 서버 엔진과 다르게 여러 개를 동시 사용할 수 있고, 각 테이블이 사용할 스토리지 엔진을 지정할 수 있음
- 스토리지 엔진마다 성능 차이가 있어 사용 엔진 선택이 매우 중요
- 종류
- InnoDB
- MyISAM
- Archive
서버 엔진
- 클라이언트의 쿼리 요청을 받아 쿼리 파싱과 스토리지 엔진 데이터를 요청하는 작업을 수행
-
인덱스가 무엇이고, 언제 사용하는지 설명해 주세요.
답
인덱스 (Index)
- 추가적인 쓰기 작업과 저장 공간을 활용해 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
- 컬럼에 대해 색인을 부여해 빠르게 검색이 가능
- 인덱스를 활용하면 데이터 조회/수정/삭제의 성능이 향상됨
- 컬럼의 데이터를 정렬한 후 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장
- 규모가 큰 테이블, 수정이 적은 컬럼, 조회가 잦은 컬럼이 효율적
-
일반적으로 인덱스는 수정이 잦은 테이블에선 사용하지 않기를 권합니다. 왜 그럴까요?
답
인덱스의 효과를 누리려면 인덱스를 항상 최신의 정렬 상태로 유지해야 해서, INSERT/UPDATE/DELETE문으로 인덱스가 적용된 컬럼이 수정되면 연산을 추가적으로 해야되는 오버헤드가 발생함 → INSERT/DELETE/UPDATE가 빈번하게 발생하는 속성에 인덱스를 걸면 성능이 오히려 저하될 수 있음
⇒ UPDATE과 DELETE은 기존의 인덱스를 삭제하지 않고 '사용하지 않음' 처리를 해서 실제 데이터보다 인덱스가 더 많이 존재하게 될 수 있음
-
앞 꼬리질문에 대해, 그렇다면 인덱스에서 사용하지 않겠다고 선택한 값은 위 정책을 그대로 따라가나요?
답
인덱스에서 사용하지 않겠다고 선택한 값은 위의 정책을 그대로 따라가지 않음
→ 인덱스에서 특정 값을 사용하지 않도록 설정하면, 해당 값을 검색할 때는 인덱스를 사용하지 않고 테이블 전체를 검색하게 됨
→ 해당 값을 수정할 때도 마찬가지
⇒ 인덱스에서 사용하지 않겠다고 선택한 값은 수정이 잦은 테이블에서도 그대로 유지되지만, 해당 값을 검색할 때는 인덱스를 사용하지 않으므로 수정 작업의 성능 저하를 방지할 수 있음
-
ORDER BY/GROUP BY 연산의 동작 과정을 인덱스의 존재여부와 연관지어서 설명해 주세요.
답
인덱스가 없는 경우
- ORDER BY 연산
- 테이블의 모든 데이터를 읽어와서 정렬
- 데이터를 한 번씩 읽어와야 하기 때문에, 데이터의 양이 많은 경우에는 성능이 저하될 수 있음
- GROUP BY 연산
- 테이블의 모든 데이터를 읽어와서 그룹화
- 그룹화된 결과를 얻기 위해 추가적인 계산이 필요하며, 이 역시 데이터의 양이 많은 경우에는 성능이 저하될 수 있음
인덱스가 있는 경우
- ORDER BY 연산
- 인덱스를 이용하여 데이터를 빠르게 정렬할 수 있음
- 인덱스는 데이터를 정렬된 순서로 저장하기 때문에, ORDER BY 연산은 인덱스를 이용하여 데이터를 빠르게 검색하고 정렬할 수 있음
- GROUP BY 연산
- 인덱스를 이용하여 그룹화된 결과를 빠르게 얻을 수 있음
- 그룹화된 데이터를 빠르게 검색하고, 그룹화 된 결과를 빠르게 계산할 수 있음
- ORDER BY 연산
-
기본키는 인덱스라고 할 수 있을까요? 그렇지 않다면, 인덱스와 기본키는 어떤 차이가 있나요?
답
일반적으로 DBMS에서는 기본키가 자동으로 인덱스 적용이 되지만 기본키를 인덱스라고 할 수 없음
기본키는 개념적인 값으로 레코드의 유일성을 보장하지만 물리적으로 저장되지는 않음
인덱스는 레코드의 유일성을 보장하지 않고, 단지 탐색을 빠르게 해주는 역할임
또한 별도의 디스크 공간에 저장됨
-
그렇다면 외래키는요?
답
외래키는 참조 무결성(Referential Integrity)을 유지하는 데 중요한 역할을함
외래키를 가진 테이블에 인덱스를 생성하면 외래키를 빠르게 검색할 수 있음
하지만 인덱스를 자동으로 적용하는 것은 아님
-
인덱스가 데이터의 물리적 저장에도 영향을 미치나요? 그렇지 않다면, 데이터는 어떤 순서로 물리적으로 저장되나요?
답

-
우리가 아는 RDB가 아닌 NoSQL (ex. Redis, MongoDB 등)는 인덱스를 갖고 있나요? 만약 있다면, RDB의 인덱스와는 어떤 차이가 있을까요?
답
인덱스를 가짐
NoSQL의 인덱스는 RDBMS 인덱스와는 달리 두 데이터의 구조와 특성에 따라 다양한 방식으로 구현될 수 있음
ex) MongoDB
- 자동으로 생성되는 기본 인덱스(default index)와 사용자가 생성하는 사용자 정의 인덱스(user-defined index)를 지원
- 기본 인덱스는 모든 필드에 대해 생성되며, 사용자 정의 인덱스는 특정 필드에 대해서만 생성할 수 있음
-
(A, B) 와 같은 방식으로 인덱스를 설정한 테이블에서, A 조건 없이 B 조건만 사용하여 쿼리를 요청했습니다. 해당 쿼리는 인덱스를 탈까요?
답

-
RDBMS, NoSQL에서의 클러스터링/레플리케이션 방식에 대해 설명해 주세요.
답
RDBMS의 적용
- Replication으로 구축하면 master-slave 구조로 구성해서 마스터는 DML만 처리하고 slave는 읽기만 수행
- 사용자 증대 등으로 인해 부하가 증가하면 slave를 증설
- slave를 증설하면 부하 분산으로 인해 로드밸런서를 구축해야 함
- Clustering으로 구축하면 management node, data node, SQL node로 구성
- 권장 : Management node 2대, Data node 2대, SQL node 2대
- 공유디스크나 락에 대한 성능 저하는 발생하지 않음
- Data node를 초기에 구축하면 데이터 증가로 인한 노드 추가시 시스템 전체 정지 후 재구축해야 하는 단점 존재
NoSQL의 적용
- Replication으로 구축하면 RDBMS의 적용과 같음
- (MongoDB) Clustering으로 구축하면 많은 데이터를 여러 노드에 분산 저장하는 방식으로 3종류 서버로 구성
- Mongod, Mongod configsvr, mongs
- 장점: 수평적 확장성, 읽기/쓰기 연산 성능 향상
클러스터링 (Clustering)
- 여러개의 데이터베이스를 수평적인 구조로 구축하는 방식
- 분산환경을 구성하여 single point of failure와 같은 문제를 해결할 수 있는 Fail Over 시스템을 구축하는 것을 목적으로 함
- 동기 방식으로 노드들 간 데이터를 동기화
레플리케이션 (Replication)
- 여러 개의 데이터베이스를 권한에 따라 수직적인 구조 (Master-Slave)로 구축하는 방식
- 마스터 노드는 쓰기 작업만 처리하고, 슬레이브 노드는 읽기 작업만 처리
- 비동기 방식으로 노드들 간의 데이터를 동기화함 → 마스터와 슬레이브 간의 데이터 무결성 검사를 하지 않음
- Replication으로 구축하면 master-slave 구조로 구성해서 마스터는 DML만 처리하고 slave는 읽기만 수행
- 이러한 분산 환경에선, 트랜잭션을 어떻게 관리할 수 있을까요?
답
2Phase Commit (2PC) 알고리즘
- 분산 시스템에서 트랜잭션을 변경할 수 있는 기능을 제공
- 일반적으로 수명이 짧은 작업에만 사용하는 것을 권장함
- 투표 단계
- Coordinator가 트랜잭션의 일부가 될 모든 대상 서비스에 직접 연결해서 상태 변경이 가능한지 확인 요청
- 투표가 됐다고 변경사항이 즉시 적용되지는 않음
- 투표에 동의한 서비스의 변경이 나중에 이루어질 수 있도록 반영 결과에 대해 락을 걸어둠
- 커밋 단계
- 모든 서비스에 정확히 동시에 변경이 적용된다고 보장할 수는 없음
Saga Pattern
- 단일 데이터베이스에서 장시간 동작하는 트랜잭션을 지원하는 메커니즘으로 계획됐지만, 여러 서비스에 걸친 트랜잭션 관리에도 적합함
- 분산 트랜잭션 처리를 지원하지 않는 경우에도 Saga Pattern을 이용해서 데이터 일관성을 보장받을 수 있음
- 각 서비스의 로컬 트랜잭션을 순차적으로 처리해서, 각 로컬 트랜잭션은 데이터베이스를 업데이트한 다음 Saga 내의 다음 로컬 트랜잭션을 트리거하는 메시지/에빈트를 게시함
- 트랜잭션이 실패해서 롤백이 필요한 경우 이전 로컬 트랜잭션이 작성한 변경 사항을 취소하는 일련의 보상 트랜잭션을 통해 전체의 일관성을 유지
- 마스터, 슬레이브 데이터 동기화 전 까지의 데이터 정합성을 지키는 방법은 무엇이 있을까요?
답
완벽하게 동기화를 구현하기는 어렵기 때문에 실시간성을 보장해야 하는 쿼리는 마스터로 처리
- 다중 트랜잭션 상황에서의 Deadlock 상황과, 이를 해결하기 위한 방법에 대해 설명해 주세요.
답
교착상태 (Deadlock)
- 두 개 이상의 트랜잭션이 특정 자원의 락을 획득한 채 다른 트랜잭션이 소유하고 있는 락을 요구하면 아무리 기다려도 상황이 바뀌지 않는 상태
- 해결 방안
- 예방 기법
- 각 트랜잭션이 실행되기 전에 필요한 모든 자원을 락
- 일정 시간이 지나면 쿼리를 취소
- 회피 기법
- 자원을 할당할 때 타임스탬프를 활용해서 교착상태가 일어나지 않도록 회피하는 방법
- Wait-Die 방식 : 먼저 들어온 트랜잭션이면 대기, 나중에 들어오면 포기
- Wound-Wait 방식 : 먼저 들어온 트랜잭션이 선점, 나중에 들어오면 대기
- 자원을 할당할 때 타임스탬프를 활용해서 교착상태가 일어나지 않도록 회피하는 방법
- 낙관적 병행 제어 기법
- 트랜잭션이 실행되는 동안에는 검사를 수행하지 않고, 트랜잭션이 커밋된 후에 데이터에 문제가 있다면 롤백
- 판독 > 확인 > 기록의 단계를 따름
- 확인 단계를 성공적으로 거친 트랜잭션만 기록 단계를 수행할 수 있음
- 빈도 줄이기 기법
- 예방 기법
- 샤딩 방식은 무엇인가요? 만약 본인이 DB를 분산해서 관리해야 한다면, 레플리케이션 방식과 샤딩 방식 중 어떤 것을 사용할 것 같나요?
답
샤딩(Sharding)
- 데이터베이스 트래픽을 분산할 수 있는 중요한 수단
- 각 DB 서버에서 데이터를 분할해 저장하는 방식
- 해당 데이터에 접근할 때는 샤딩키를 사용하여 동적으로 DB서버를 매핑하는 과정 필요
- 특정 DB의 장애가 전면 장애로 이어지는 것을 방지할 수 있음
- 필요할 때
- 애플리케이션 데이터의 양이 단일 데이터베이스 노드의 스토리지 한계를 초과할 때
- 쓰기/읽기 양이 단일 노드가 핸들링할 수 있는 수준을 넘어설 때
- 하나의 데이터베이스 노드에 가능한 네트워크 대역폭을 초과할 때
-
정규화가 무엇인가요?
답
정규화
- 이상현상(Anomaly)이 있는 릴레이션을 분해해 이상현상을 없애는 과정
- 정규형이 높아질 수록 이상현상은 줄어듬
- 3 원칙
- 정보의 무손실 : 분해된 릴레이션이 표현하는 정보는 분해 전 정보를 모두 포함해야 함
- 최소 데이터 중복 : 이상현상을 제거하고, 데이터 중복을 최소화해야 함
- 분리의 원칙 : 하나의 독립된 관계성은 하나의 독립된 릴레이션으로 분리해서 표현해야 함
- 정규화를 하지 않을 경우, 발생할 수 있는 이상현상에 대해 설명해 주세요.
답
삽입 이상 (Insertion Anomaly)
- 튜플 삽입 시 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
삭제 이상 (Deletion Anomaly)
- 튜플 삭제 시 같이 저장된 다른 정보까지 연쇄적으로 삭제되는 현상
갱신 이상 (Update Anomaly)
- 튜플 갱신 시 중복된 데이터의 일부만 갱신되어 일어나는 데이터 불일치 현상
- 각 정규화에 대해, 그 정규화가 진행되기 전/후의 테이블의 변화에 대해 설명해 주세요.
답
- 제1정규화(1NF)
- 비정규화된 테이블에서 반복되는 속성을 분리하여 독립적인 테이블로 만듦
- 레코드가 하나의 값만 가지는 단일 속성으로 구성된 테이블을 만들 수 있음
- 제2정규화(2NF)
- 제1정규화된 테이블에서 부분 함수 종속을 제거하여 독립적인 테이블로 만듦
- 테이블 간의 관계를 보다 명확하게 정의할 수 있음
- 제3정규화(3NF)
- 제2정규화된 테이블에서 이행적 함수 종속을 제거하여 독립적인 테이블로 만듦
- 테이블 간의 불필요한 조인을 방지하고, 데이터의 중복을 최소화할 수 있음
- 보이스-코드 정규화(BCNF)
- 제3정규화된 테이블에서 결정자가 후보키가 아닌 함수 종속을 제거하여 독립적인 테이블로 만듦
- 테이블 간의 관계를 더욱 명확하게 정의하고, 데이터의 일관성을 유지할 수 있음
- 제4정규화(4NF)
- 제4정규화는 제3정규화에서 다치 종속을 제거하여 독립적인 테이블로 만듦
- 테이블 간의 불필요한 조인을 방지하고, 데이터의 중복을 최소화할 수 있음
- 제5정규화(5NF)
- 제5정규화는 제4정규화에서 조인 종속성을 제거하여 독립적인 테이블로 만듦
- 데이터의 중복을 최소화하고, 데이터의 일관성을 유지할 수 있음
- 제1정규화(1NF)
- 정규화가 무조건 좋은가요? 그렇지 않다면, 어떤 상황에서 역정규화를 하는게 좋은지 설명해 주세요.
답
무조건 좋은 것이 아님
역정규화 (De-normalization)
- 시스템의 성능 향상을 위해 정규화된 데이터 모델을 통합하는 작업
- 데이터 통합/분할/추가, 중복 속성 추가 등으로 구현할 수 있음
- 테이블이 단순해져서 관리 효율성이 증가
- 데이터의 일관성/무결성은 보장되지 않을 수 있음
- 필요할 때
- 수행 속도가 현저히 느릴 때
- 테이블의 조인 연산이 지나치게 많이 필요해서 데이터를 조회하는 것이 어려울 때
- 테이블에 많은 데이터가 있고, 다량의 범위 혹은 특정 범위를 자주 처리해야 하는 경우
-
View가 무엇이고, 언제 사용할 수 있나요?
답
뷰(View)
- 기본 테이블로부터 유도된 가상/임시 테이블
- 저장장치 내에 물리적으로 존재하지 않음
- 뷰를 사용해서 JOIN문을 최소화하여 사용상의 편의성을 향상시킬 수 있음
- 장점
- 논리적 데이터 독립성을 제공
- 동일 데이터에 대해 동시에 여러 사용자의 상이한 요구를 지원
- 사용자의 데이터관리가 쉬워짐
- 접근 제어를 통한 보안을 제공함
- 단점
- 독립적인 인덱스를 가질 수 없음
- 변경이 필요하면 삭제 후 재생성해야 함
- 뷰로 구성된 내용에 대한 연산에 제약이 따름
- 그렇다면, View의 값을 수정해도 실제 테이블에는 반영되지 않나요?
답
네, 실제 테이블에 반영되지 않음
해당 글은 보초님 깃허브의 질문을 가지고 작성한 글입니다.
출처
데이터베이스
[Database] 키(Key) 개념과 종류
DB - 트랜잭션 관리
Index와 Primary Key의 차이점
Foreign Key에도 index가 걸릴까?
MySQL의 동작 방식
CS 정리 - 13
