1. Image Classification
-
Image Classification : 이미지 분류는 Computer Vision에서 필수적인 작업이다.

-
Challenges : 이미지 분류 과정에서 어려움을 겪게하는 여러가지 요소가 존재한다.
-
Illumination (조명) : 조명의 변화는 이미지의 명암과 색상 분포에 큰 영향을 미쳐, 동일한 객체라도 다른 조명 조건에서 매우 다르게 보여질 수 있다.

-
Deformation (변형) : 객체의 형태가 일정하지 않고 변형될 수 있는 상황을 의미한다. 예를 들면, 고양이가 다양한 자세를 취하거나, 여러가지 각도에서 보여지는 등.

-
Occlusion (가림) : 객체의 일부가 다른 물체에 의해 가려지는 상황을 의미한다.

-
Background clutter (배경 혼잡) : 이미지 배경이 복잡하여 객체를 분리하기 어려운 상황을 의미한다.

-
-
-
Machine Learning, Data-Driven Approach : 이미지 분류 작업은 주로 데이터 기반 접근법을 사용하여 수행된다.
-
머신 러닝의 데이터 접근법 과정은 다음과 같다.
-
데이터 셋 수집 : 다양한 클래스에 속하는 이미지와 해당 이미지의 레이블을 수집한다.
-
모델 학습 : 수집한 데이터를 사용해 머신 러닝 모델을 학습시킨다. 학습 과정에선 이미지의 특징을 추출하고, 이 특징을 기반으로 각 클래스에 대한 예측 모델을 생성한다.
-
모델 평가 : 학습한 모델을 테스트 데이터셋에 적용하여 성능을 평가한다. 성능의 지표는 정확도, 정밀도, 재현율 등이다.
-
테스트 데이터 셋 예시

-
-
1-1. Extract Image Features
-
Image Patch : 이미지 패치는 이미지의 특정 부분을 나타내며, 이 부분의 픽셀 값을 사용하여 템플릿 매칭(이미지 내에 존재하는 특정 패턴이나 객체를 찾는 것)을 수행한다. 이 방법은 이미지의 특징을 추출하는 데 유용하다.
-
이미지 패치의 픽셀 값을 벡터 형태로 변환하여 템플릿 매칭에 활용할 수 있다.

-
이미지 패치의 단점
-
절대적인 강도 값에 민감하여, 조명이나 명암 변화에 취약하다.
-
패치의 위치나 크기 변형에 취약하다.
-
-
-
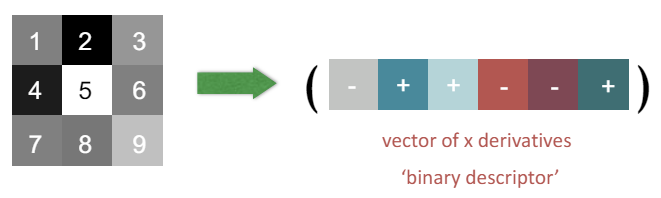
Image gradients : 픽셀 간의 차이를 사용하여 이미지의 특징을 추출하는 방법이다. 이 방법은 이미지의 밝기 변화에 대해 민감하지 않다.
-
이미지 패치의 각 픽셀 간의 차이를 계산하여 그래디언트를 구한다.
-
그래디언트의 단점
-
변형(Deformation)에 취약하다.
-
이미지의 기하학적 변화를 반영하지 못할 수 있다.
-
-
-
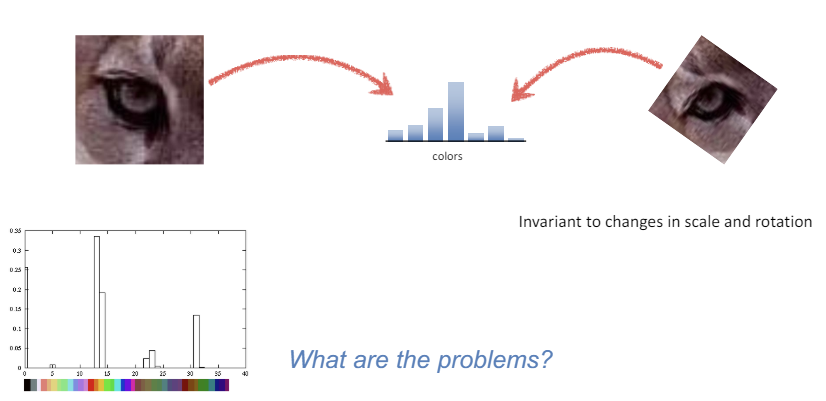
Color Histogram : 색상 히스토그램은 이미지에서 색상의 분포를 표현하는 방법이다. 즉, 이미지 내에 존재하는 각 색상의 빈도를 나타내는 그래프이다. 색상 히스토그램은 이미지의 크기나 회전 변화에 대해 민감하게 반응하지 않는다.
-
색상 히스토그램의 단점
-
이미지 내 색상의 위치 정보를 고려하지 않기 때문에, 두 이미지가 색상 분포만 같고 전혀 다른 배치를 가진 경우에도 동일한 히스토그램을 갖는다.
-
조명 변화에 취약하다.
-
이미지의 세부 구조나 형태를 반영하지 못한다.
-
-
-
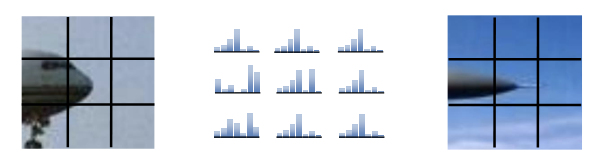
Spatial Histogram : 공간 히스토그램은 이미지의 공간적 분포를 고려하여 특징을 추출하는 방법이다. 이미지를 여러 개의 작은 셀로 나누고, 각 셀에서 히스토그램을 계산한 후, 이를 하나로 결합하여 이미지의 전체적인 특징을 표현한다.
-
공간 히스토그램의 단점
-
이미지가 매우 복잡한 경우, 공간 히스토그램은 여전히 세부적인 구조를 충분히 표현하기 어렵다.
-
계산이 복잡하고, 연산에 드는 시간 비용이 크다.
-
색상 히스토그램과 마찬가지로, 조명 변화에 여전히 취약하다.
-
-
-
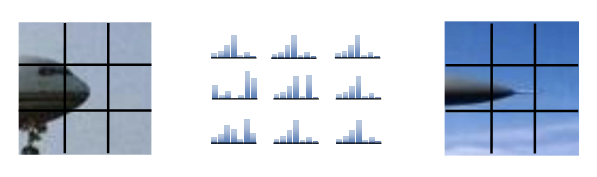
Orientation Histogram : 방향 히스토그램은 이미지의 각 픽셀에서 계산된 그래디언트의 방향 분포를 나타낸다. 이는 객체의 모양과 경계를 효과적으로 표현할 수 있다.
-
방향 히스토그램의 단점
-
여전히 조명 변화에 취약하다.
-
계산이 복잡하고, 연산에 드는 비용이 크다.
-
-
-
GIST Descriptor : GIST 설명자는 이미지의 전체적인 장면을 요약하는 데 사용되는 특징 추출 기법이다. 이는 이미지의 전체적인 공간적 배치를 추출하는 데 유용하다.
-
GIST 생성 과정
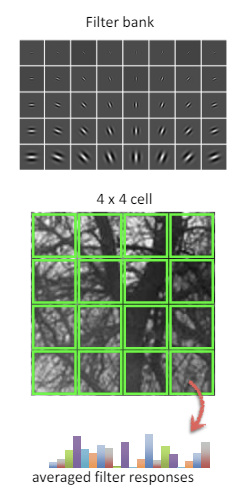
1). 필터 응답 계산 : Gabor 필터 뱅크를 사용하여 이미지의 필터 응답을 계산한다. Gabor 필터는 주로 다양한 주파수와 방향에서 이미지의 정보를 추출하는 데 사용한다.
2). 이미지 패치를 4 4 셀로 분할 : 이미지를 4 4 크기의 셀로 분할하여 각 셀에 대한 필터 응답을 계산한다. 이는 이미지의 공간적 정보 유지에 도움이 된다.
3). 각 셀의 필터 응답 평균 계산 : 각 셀에서 계산된 필터 응답의 평균을 구한다.
4). GIST의 크기 : 최종 GIST의 크기는 4 4 N이다. N은 필터 뱅크의 크기(사용된 Gabor 필터의 개수)이다. 예를 들어, 16개의 셀이 존재하고, 각 셀에 8개의 필터 응답을 계산하면 GIST의 크기는 4 4 8 = 128이다.
5). 결과

-
GIST의 장점
-
이미지의 전체적인 공간에 대한 특징을 요약하여 표현한다.
-
상대적으로 간단한 계산으로도 이미지의 중요 정보를 추출할 수 있다.
-
-
GIST의 단점
-
세부 정보(세부적인 객체나 특징)는 다소 부족할 수 있다.
-
조명 변화에 취약하다.
-
-
2. Convolution Neural Networks
-
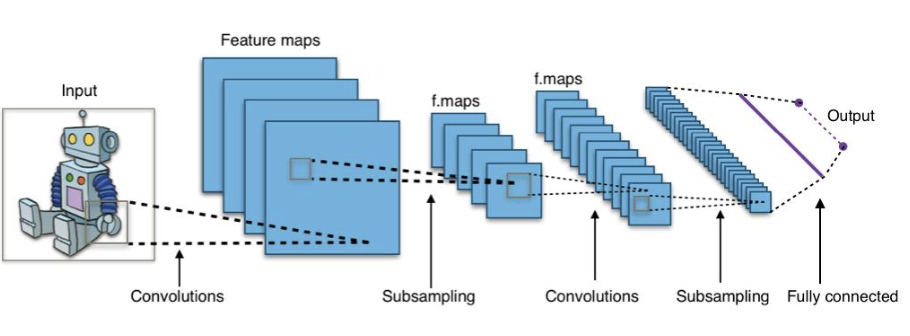
Convolution Neural Networks (CNN) : CNN은 이미지에서 점진적으로 더 복잡하고 추상적인 특징을 학습한다. 이는 이미지 분류, 객체 인식 등 다양한 컴퓨터 비전 과제에서 높은 성능을 발휘하게 한다.
-
동작 과정
1). Input Layer : 이미지를 입력받는다.
2). Convolution Layer : 이미지에 필터를 적용하여 특징 맵(Feature maps)을 생성한다. 이는 이미지의 중요한 패턴을 추출하는 데 유용하다.
3). Subsampling Layer or Pooling Layer : 컨볼루션 층에서 생성된 특징 맵을 다운샘플링하여 크기를 줄인다. 이는 연산량을 줄이기 위함이다.
4). Convolution Layer : 추가적인 필터를 적용하여 더 높은 수준의 특징을 추출한다.
5). Subsampling Layer : 다시 특징 맵을 다운샘플링한다.
6). Fully Connected Layer : 최종적인 특징 맵을 일렬로 펼쳐서 하나의 벡터로 만든 후, 완전 연결층에 전달한다. 이 층에서 이미지 분류 등의 최종 작업을 수행한다.
7). Output Layer : 최종 결과를 출력한다.
-
2-1. Convolution Layer
-
Convolution Layer : 컨볼루션 레이어는 이미지나 기타 다차원 데이터를 처리하는 신경망 구조의 핵심이다. 이를 통해 이미지의 공간적 패턴을 효율적으로 학습할 수 있다.
-
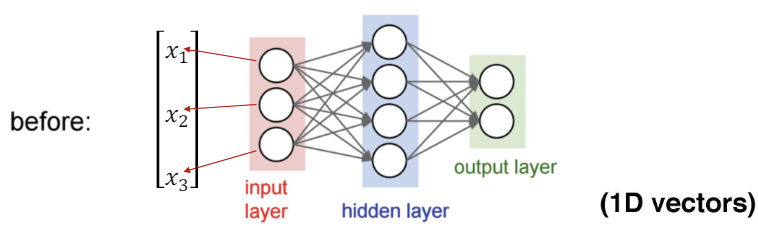
전통적 신경망 (Tranditional Neural Networks) : 전통적 신경망에선 입력 데이터가 1D 벡터 형태로 처리된다. 입력 레이어, 숨겨진 레이어, 출력 레이어로 구성되며, 모든 노드가 서로 연결되어 있다.
-
입력 레이어 : 벡터 형태의 입력 데이터가 주어진다.
-
숨겨진 레이어 : 입력 데이터가 각 노드에 전달되고, 각 노드에서 가중치와 편향이 적용된 후 활성화 함수가 적용된다. 이때 모든 입력 노드는 모든 숨겨진 노드에 연결되어 있다.
-
출력 레이어 : 숨겨진 레이어의 출력을 받아 최종 출력을 생성한다.
-
-
컨볼루션 신경망 (Convolution Neural Networks, CNN) : CNN에서는 입력 데이터가 3D 배열 형태로 처리된다. 이는 이미지 데이터의 공간적 구조를 유지하며, 중요한 패턴을 효과적으로 학습할 수 있다.
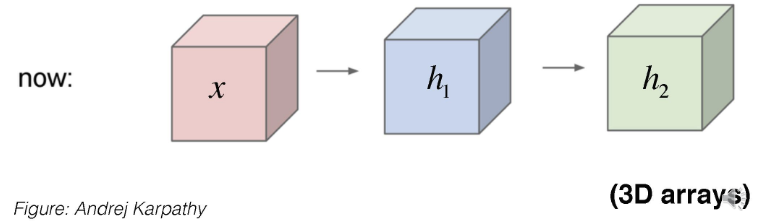
-
-
Convolution Layer Process
-
3차원 입력 : 입력으로 주어지는 이미지 데이터는 3차원 배열로 표현된다. 예를 들어, CIFAR-10 이미지 데이터셋은 3(depth) 32(width) 32(height) 형태이다.
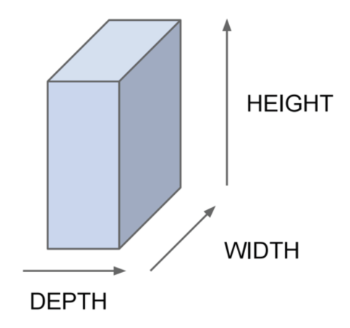
-
활성화
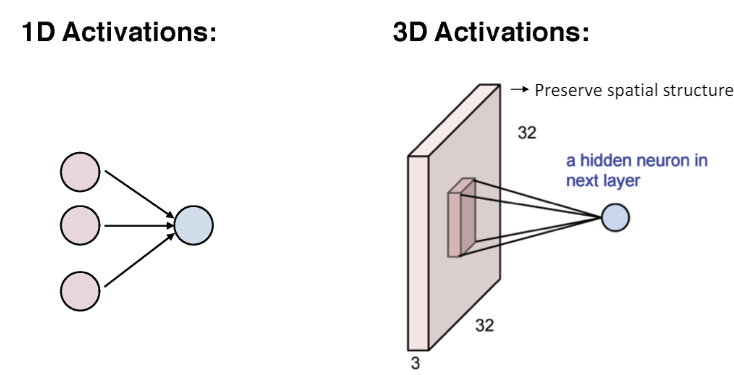
-
1D 활성화 : 전통적 신경망에선 입력이 모든 출력과 연결된다.
-
3D 활성화 : 컨볼루션 레이어에서는 입력 데이터의 공간적 구조를 유지하며 데이터 처리가 진행된다.
-
-
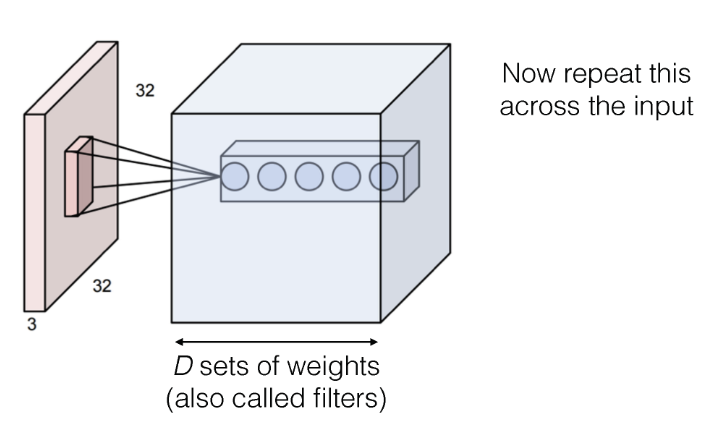
필터(커널) 적용 (Convolution 연산) : 필터는 작은 크기의 행렬로, 입력 이미지 위를 이동하며 각 위치에서 필터와 이미지의 내적을 계산한다. 이 과정을 거치며 필터는 이미지의 특정 패턴이나 특징을 강조한 특징 맵(활성화 맵)을 생성한다.
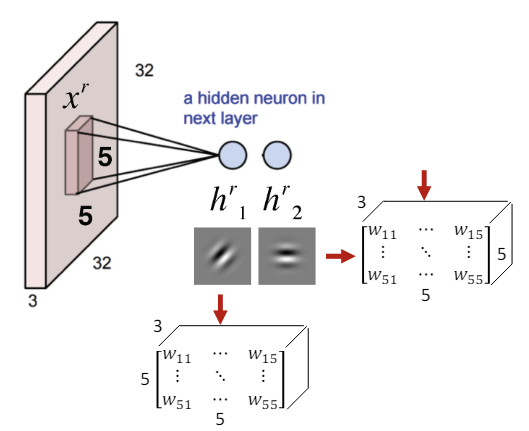
-
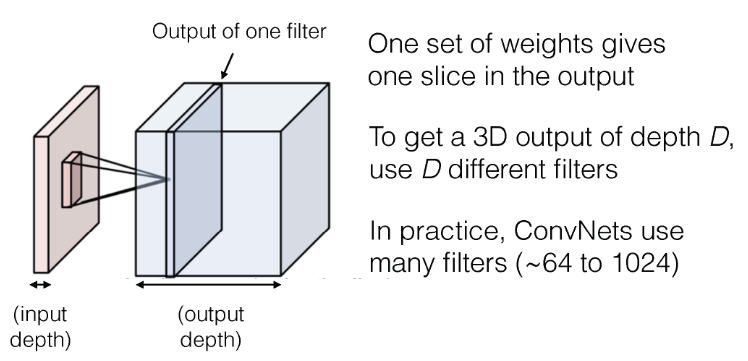
다중 필터 사용 : 여러 필터를 사용하여 이미지의 다양한 패턴을 감지하고, 이로부터 여러가지 특징 맵을 생성한다.
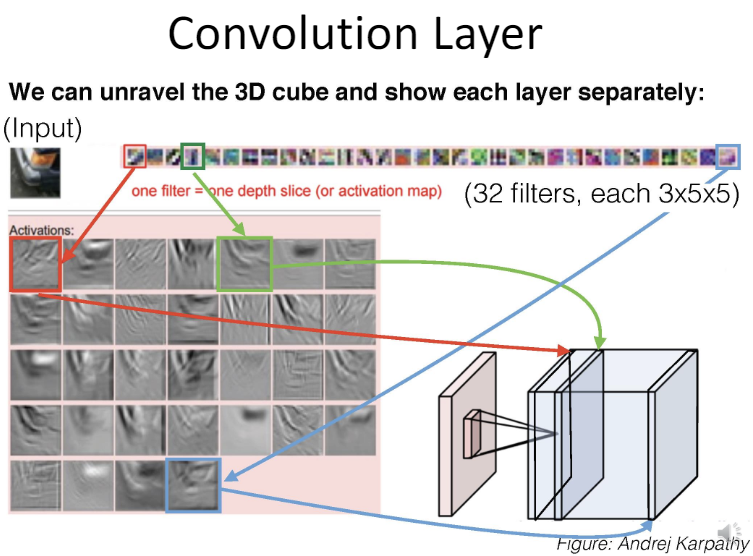
-
이렇게 여러 필터가 적용된 특징 맵들을 층으로 쌓아 최종적인 출력 이미지를 생성해간다. 이때 출력 깊이는 사용된 필터의 수에 따라 결정(개의 필터를 사용하면 출력 깊이는 )된다.
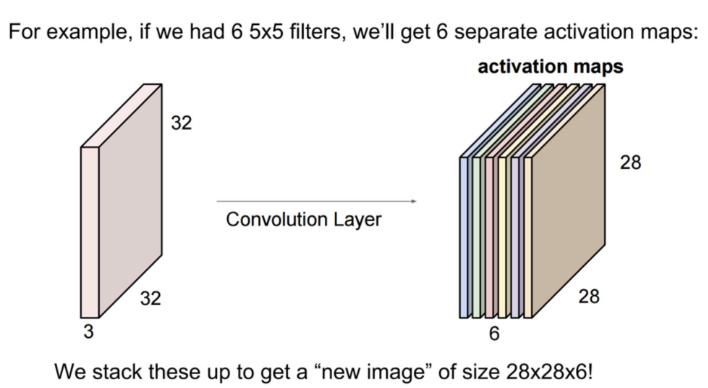
- 위 예시에선 6가지의 필터를 사용했으며, 각 필터마다 별도의 활성화 맵이 생성된다. 따라서 각 활성화 맵은 분리되어 있다.
-
-
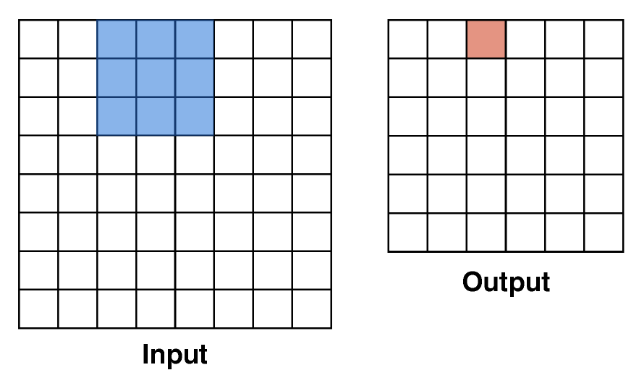
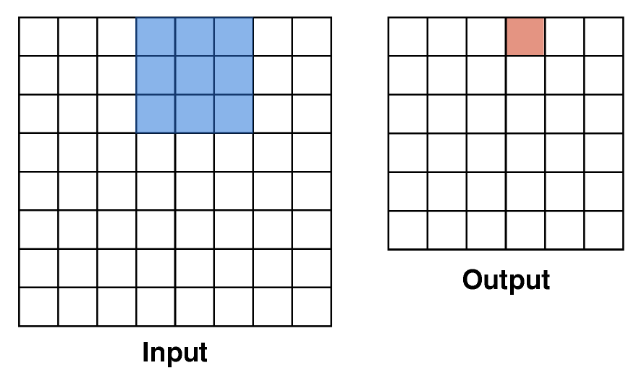
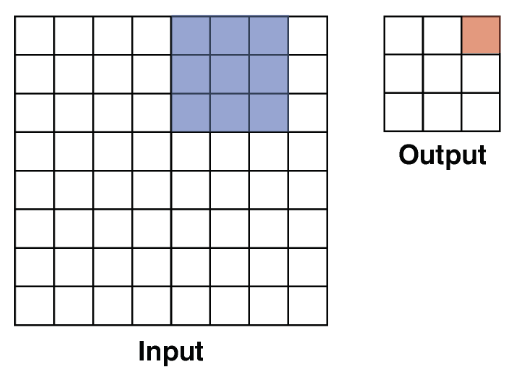
Convolution - Stride : 스트라이드는 필터가 입력 이미지 위를 이동하는 간격을 의미한다. 필터가 이동하며 연산을 수행한 결과는 출력 이미지의 해당 위치에 저장된다.
-
Stride = 1
-
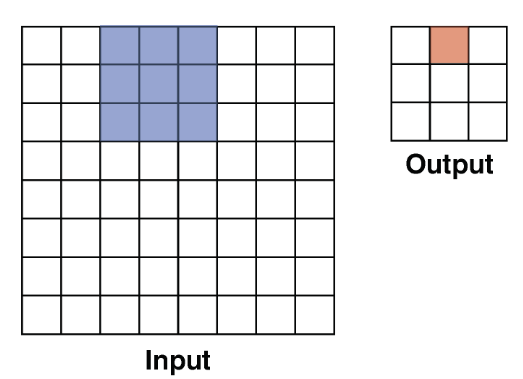
Stride = 2 : 스트라이드가 1인 경우보다 출력 크기가 더 작아진다.
-
특정 스트라이드 값 설정 시, 입력된 이미지의 모든 영역에 대한 연산을 진행하지 못할 수 있다.
-
즉, 스트라이드를 조절함으로써 출력 이미지의 크기와 특징 추출의 밀도를 조절할 수 있다는 의미이다.
-
스트라이드가 커질수록 계산량은 줄어들지만, 디테일한 특징을 추출하기 어렵다.
-
-
Convolution - Padding : 패딩 값에 따라 입력 이미지의 가장자리에 0으로 채워지는 두께를 조절할 수 있다. 즉, 패딩을 사용함으로써 입력 이미지의 가장자리까지 정보를 반영하여 결과를 출력할 수 있다.
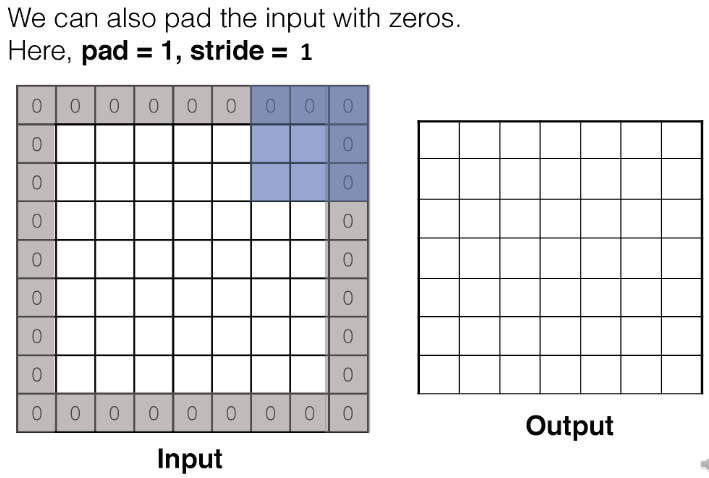
2-2. Pooling
-
Pooling : 풀링을 한마디로 표현하자면, 특징 맵의 특징 맵이라고 할 수 있다. 다운샘플링을 통해 특징 맵의 용량을 줄이고, 각 특징맵을 다시 쌓아올려 만드는 과정이다.
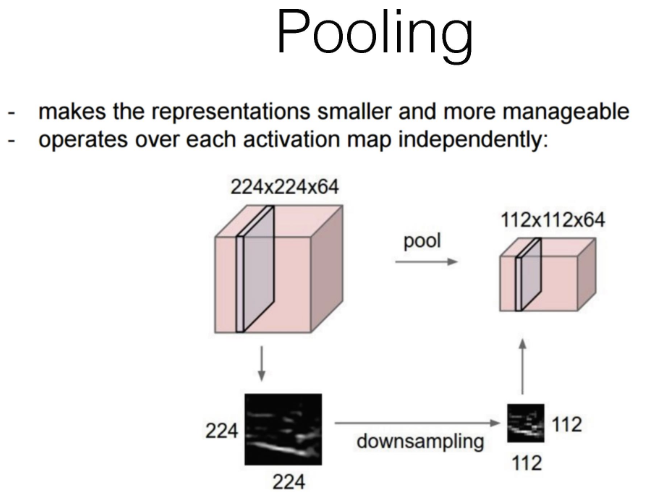
-
Max Pooling : 주어진 영역에 존재하는 최대값을 선택하는 Pooling 방법이다.
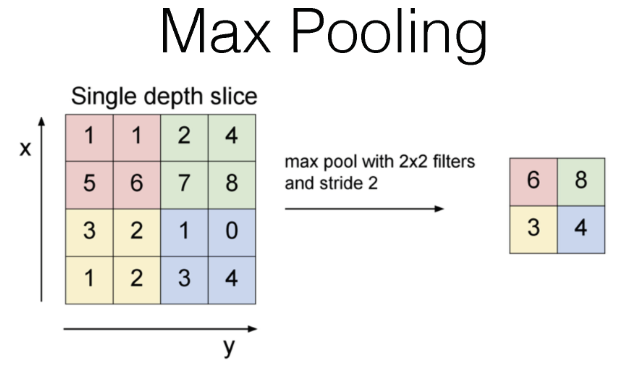
-
예시에 대한 진행 과정
-
입력 데이터는 4 * 4 크기의 행렬
-
2 * 2 크기의 필터를 사용해 Max Pooling을 수행.
-
스트라이드는 2로 설정되어, 필터가 두 칸씩 이동한다.
-
결과적으로, 16 / 4 부분으로 나뉜 영역에 대한 최대 값을 추출한다.
-
-
-
-
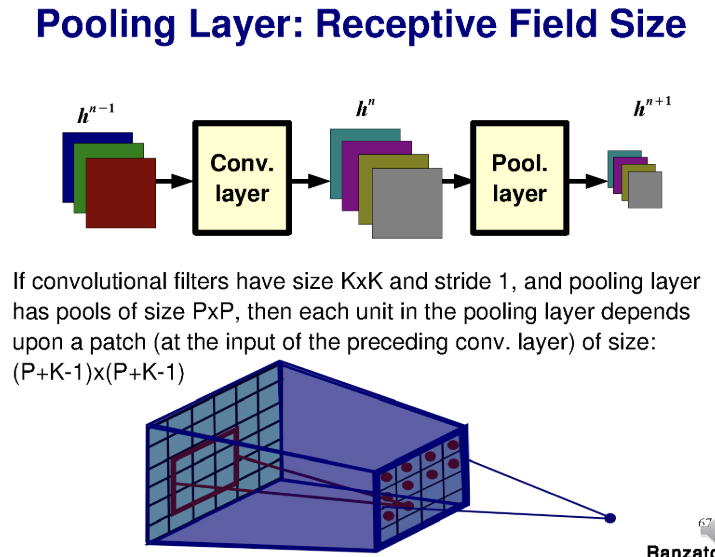
Pooling Layer - Receptive Field Size
-
Receptive Field : 풀링 층의 각 출력은 이전 컨볼루션 레이어의 필터 크기에 영향을 받는다.
-
예를 들어, 컨볼루션 필터의 크기가 이고, 스트라이드가 1인 경우
-
풀링 레이어의 필터 크기가 인 경우
-
풀링 층의 각 출력은 크기의 필터에 의존한다.
-
-
3. Deep Learning Models
-
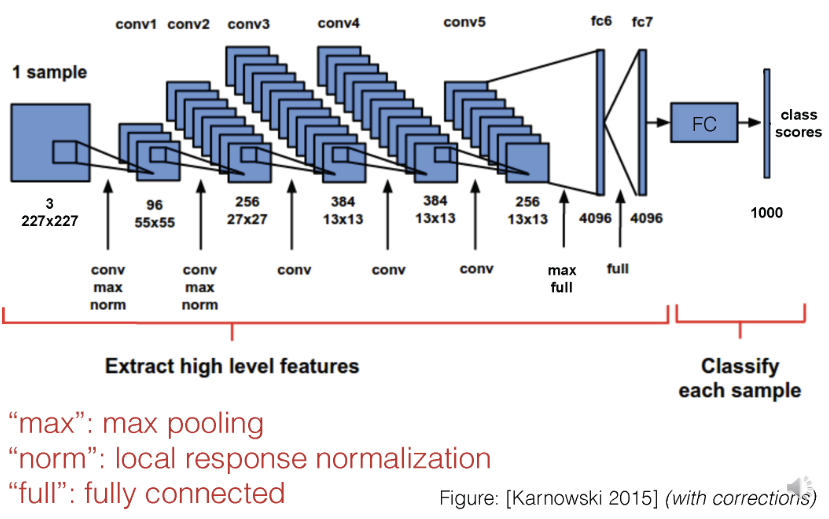
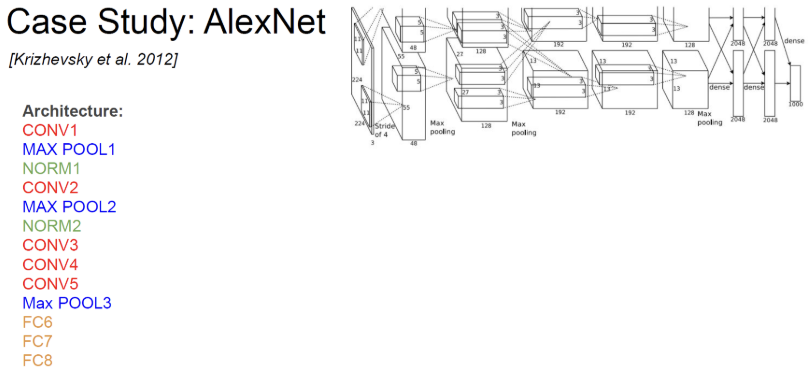
AlexNet : CNN 모델을 사용한 대표적인 이미지 분류 작업 모델. CNN 베이스로 모델로서 처음으로 우승을 차지하였다. 연산량이 적지만, 메모리 사용량이 높고 정확도도 가장 낮다.
-
8개의 레이어로 구성됨.
-
오류율은 16.4%
-
-
ZFNet : AlexNet의 하이퍼 파라미터를 개선한 모델이다.
-
8개의 레이어로 구성
-
오류율은 11.7%
-
-
VGGNet : 더 작은 필터를 사용하며, 더 깊은 네트워크를 구축한 모델이다. 높은 연산량과 메모리 사용량으로 인해 복잡도가 높지만, 정확도가 높다.

-
3 3 Stride 1, Pad 1 필터를 사용 : 해당 필터를 사용하여 3개의 층을 쌓으면, 하나의 7 7 컨볼루션 레이어와 동일한 효과적 수용 영역을 갖는다. 이를 통해 네트워크의 깊이를 증가시키면서도 계산 효율성을 유지할 수 있다.
-
2 * 2 Stride 2 MAX POLL을 사용한다.
-
16 ~ 19 레이어로 깊이가 증가.
-
오류율이 7.3%로 크게 감소.
-
-
GoogLeNet : 인셉션 모듈을 사용한 모델. 가장 효율적인 모델로 평가됨.
-
인셉션 모듈
-
네트워크의 깊이와 폭을 동시에 확장하는 구조
-
여러 크기의 필터(1 * 1, 3 * 3, 5 * 5)를 병렬로 적용하여 다양한 스케일의 특징을 추출
-
-
22개의 레이어로 구성
-
오류율은 6.7%
-
-
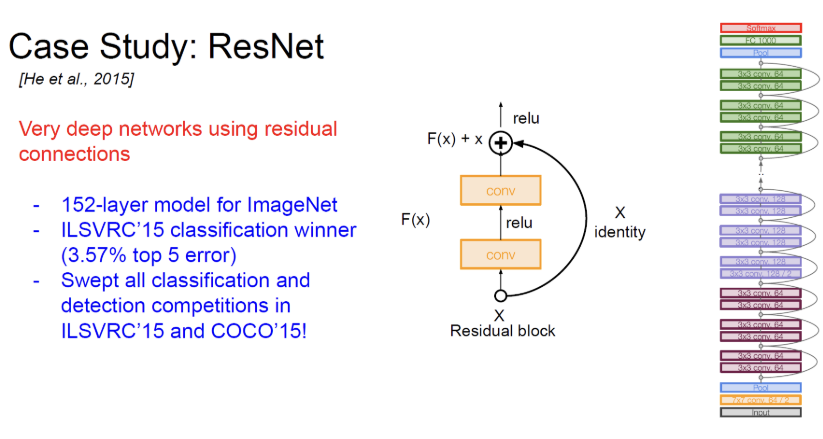
ResNet : Residual Connection을 사용하여 매우 깊은 네트워크를 구성함. 레이어 구성에 따라 효율성이 다르며, 가장 정확도가 높다.
-
152 레이어 사용
-
오류율은 3.57%
-
ResNet은 34, 50, 101, 152 레이어와 같은 다양한 깊이로 구성 가능.
-
