나는 오픈서치를 사용한 이유가 log 모니터링을 위해서였다.
그래서 오늘은 어플리케이션 로그를 어떻게 오픈서치 클러스터로 넘기는 지에 대해서 포스팅하려고 한다.
구조
오픈 서치로 데이터를 적재하는 방법은 여러가지가 있겠지만 나는 아래 구조를 사용해서 데이터를 적재했다.
cloudwatch에 로그 적재
-> lambda에서 로그를 json으로 가공 후 opensearch cluster로 전달
-> opensearch에서 로그 확인 / 시각화
1. cloudwatch에 데이터 적재하기
그럼 첫번 째 cloudwatch에 로그를 어떻게 적재하느냐다.
우리 서버는 쿠버네티스기 때문에 쿠버네티스 기준으로 설명한다.
cloudwatch-agent라는 게 있다 이걸 쿠버네티스에 설치하고 설정해주면 콘솔에 로그가 찍히면 알아서 가져가서 cloudwatch에 적재를 해준다.
{
"time": "2024-04-30T08:22:07.475087542Z",
"stream": "stdout",
"_p": "F",
"log": "|[log_level = INFO ]||[timestamp = 2024-04-30 08:22:07.474][OPENSEARCH]|[requestId = abcd]||[status_code = 200]|",
"kubernetes": {
"pod_name": "",
"namespace_name": ""
}
}그러면 대충 이런식으로 json 형태로 cloudwatch에서 로그를 확인할 수 있을 거다. 저기서 log 부분에 우리가 콘솔로 찍은 로그가 들어가게 된다. log말고 나머지는 쿠버네티스 에이전트 설치하고 설정하면 자동으로 들어가는 필드들이다.
2. Lambda에서 Opensearch 접근 권한 주기
다음은 람다에 어떻게 opensearch에 접근할 수 있는 권한을 부여하는가 이다.
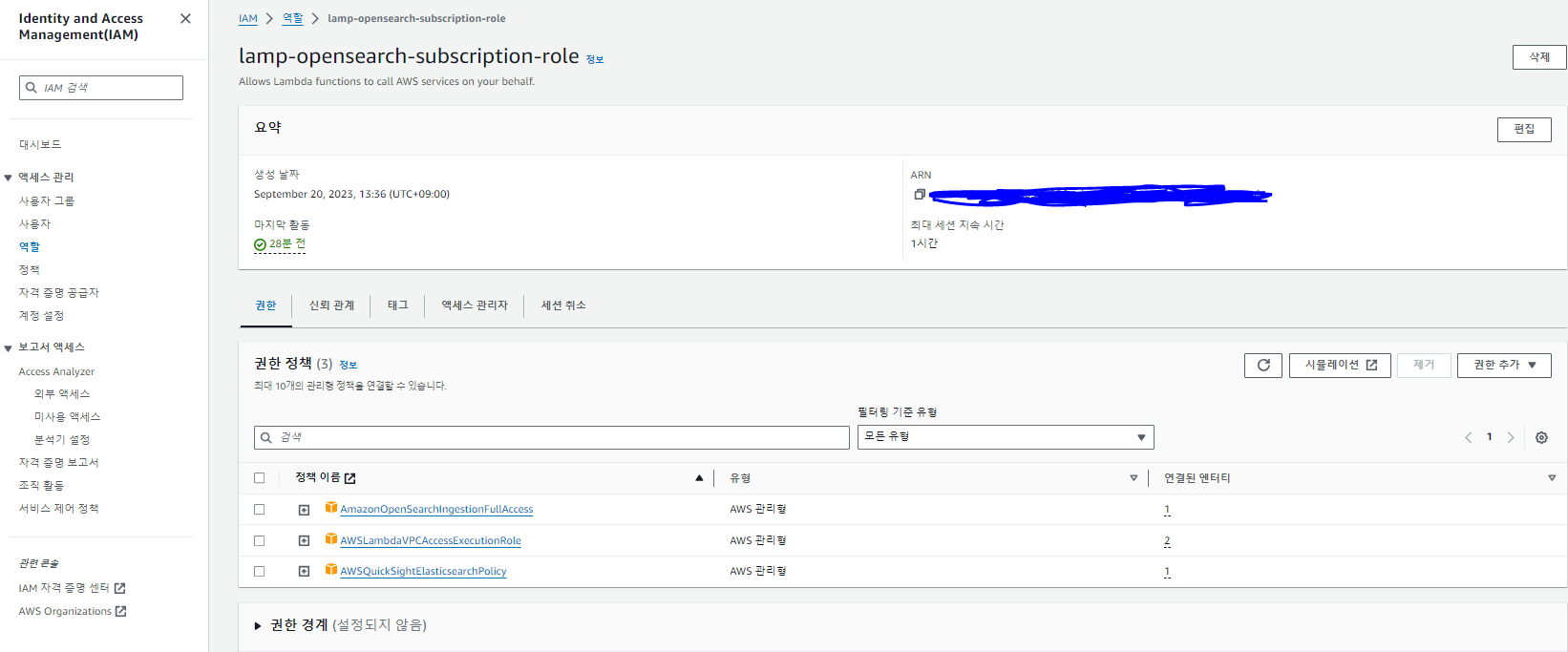
우선 aws iam에서 저 세개 권한을 추가한 역할을 만들어준다.
사실 저 세개가 최소 권한인 지는 확실치 않다.
불필요한 권한이 있을 수 있으니 여러분들은 좀 더 확인해보길 바란다.
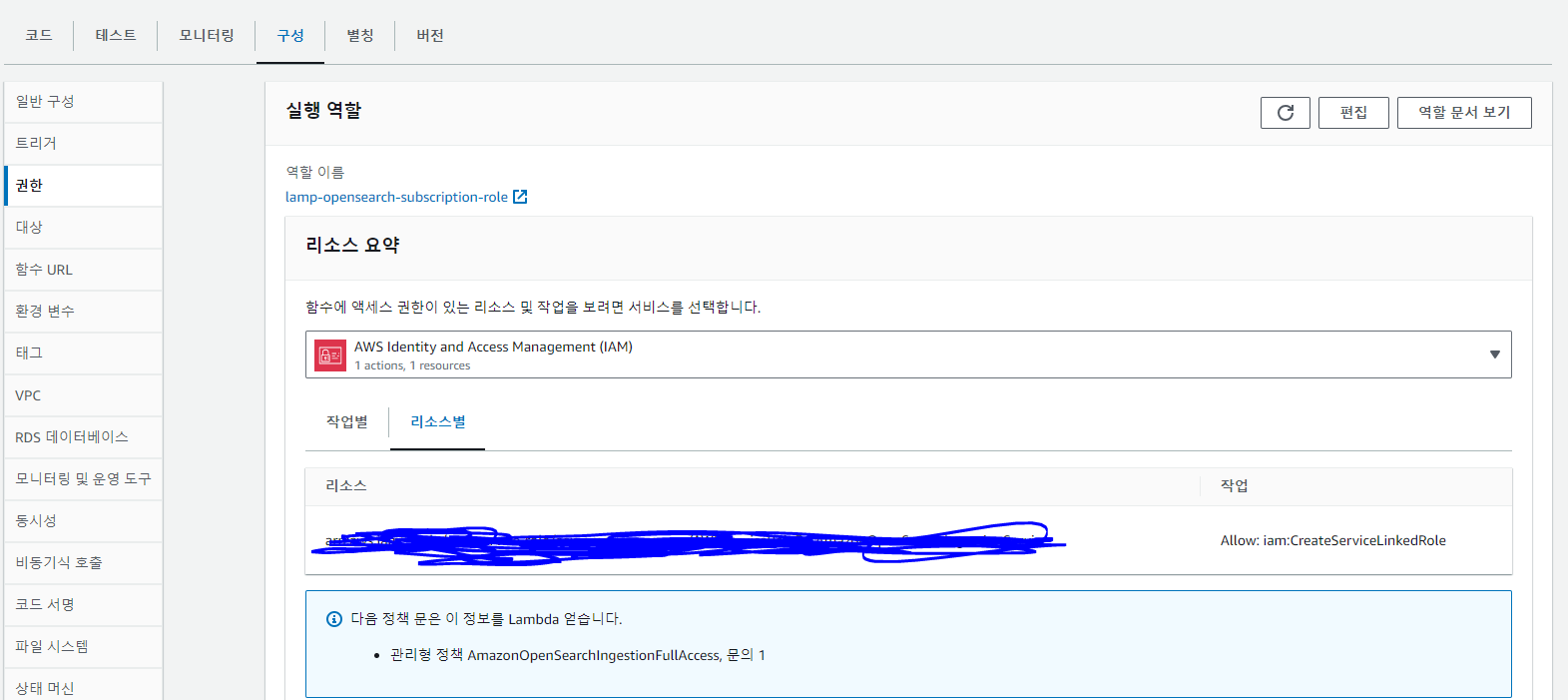
그리고 구독 필터 람다로 들어가서 해당 iam을 연결해준다.
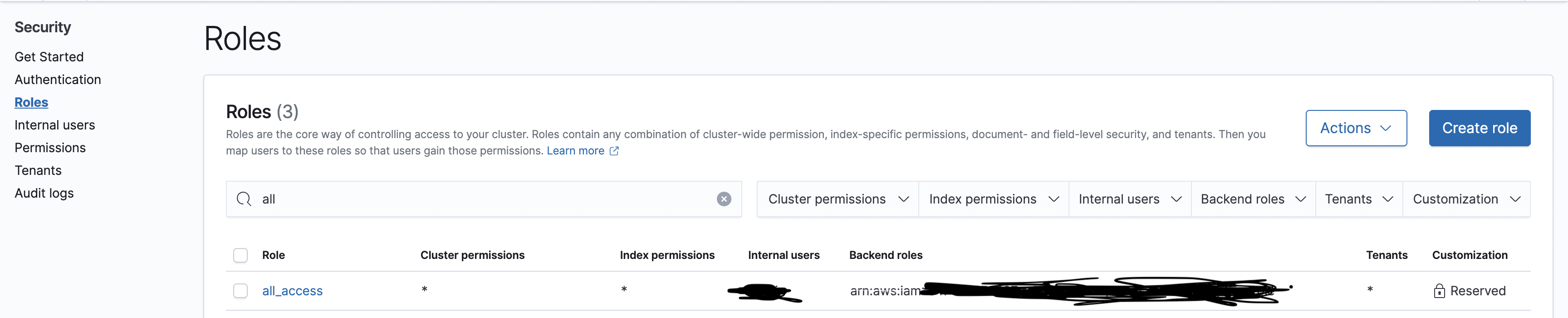
그 다음에 opensearch 대시보드의 roles로 들어가서 원하는 역할을 선택해서 iam을 또 매핑해주면 된다.
나는 all_access로 했는데 최소권한만 주고 싶으면 적당한 거 찾아서 연결해주면 된다.
연결하는 방법은 저 역할을 클릭하고

mapped users 탭으로 이동한 다음에 manage mapping을 선택한다.
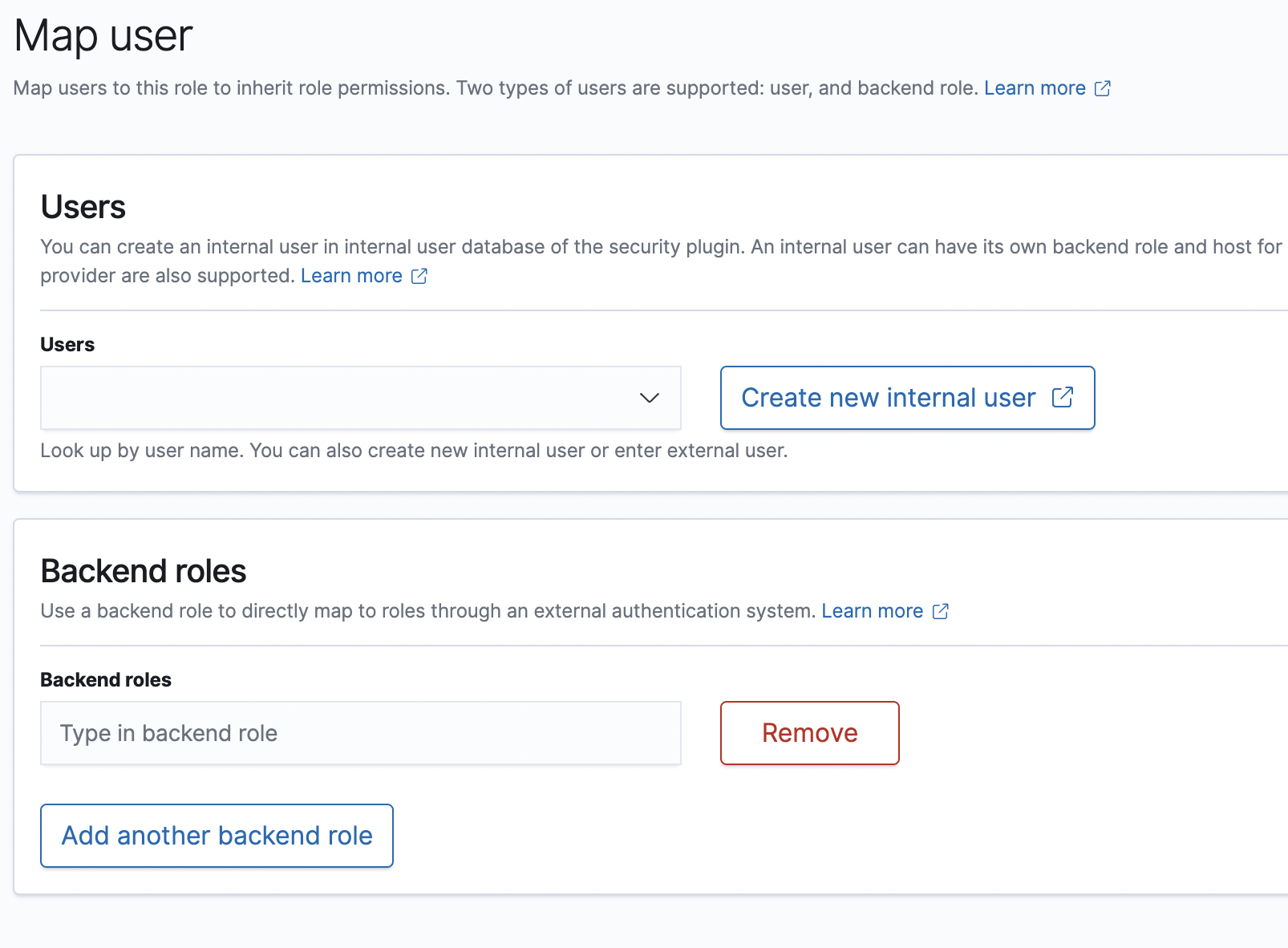
그리고 밑에 backend roles에 iam의 arn을 복사해 붙여넣으면 끝이다.
3. Lambda로 로그 가공해서 전송하기
그 다음으로는 어떻게 lambda에서 로그를 가공해서 전달하느냐다.
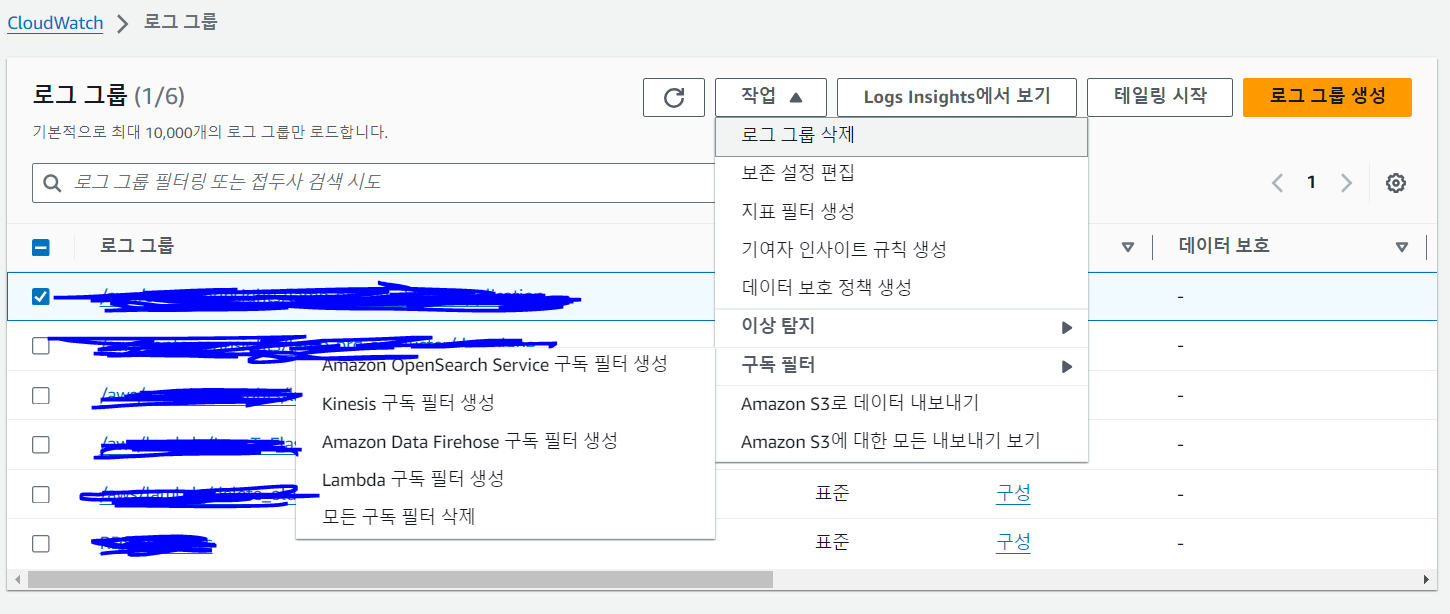
그건 cloudwatch에서 로그가 저장되고 있는 로그 그룹을 선택하고 구독필터 -> Amazon Opensearch Service 구독 필터 생성을 누르면 자동으로 Lambda 함수를 거의 다 짜준다.
어느 정도냐면 cloudwatch에서 데이터를 가져와서 그대로 opensearch cluster에 전송하는 거 까지 다 짜준다.
{
"time": "2024-04-30T08:22:07.475087542Z",
"stream": "stdout",
"_p": "F",
"log": "|[log_level = INFO ]||[timestamp = 2024-04-30 08:22:07.474][OPENSEARCH]|[requestId = abcd]||[status_code = 200]|",
"kubernetes": {
"pod_name": "",
"namespace_name": ""
}
}
그러니까 딱 이대로 opensearch 클러스터에 전송이 된다.
근데 이제 log쪽도 json으로 만들어서 넘겨줘야 opensearch에서 인덱스 관리가 된다.
그러니까 우리가 할 일은 그냥 그 람다 코드를 보고 흐름을 좀 파악하고 중간에 어플리케이션 로그를 잘 파싱해서 json형태로 만들어서 전송하는 것만 적절하게 추가하면 된다.
그리고 이렇게 어플리케이션 로그를 잘 파싱하기 위해서는 아무래도 로그를 찍을 때 규칙적으로 찍는 게 좋다.
나같은 경우에는
|[log_level = INFO ]||[timestamp = 2024-04-30 08:22:07.474][OPENSEARCH]|[requestId = abcd]||[status_code = 200]|로그형태를 |[key = value]| 이런 식으로 통일하고
람다에서 정규식으로
var regex = /\|\[(.+?) = (.+?)\]\|/g;
var match;
while ((match = regex.exec(logString)) !== null) {
var key = match[1];
var value = match[2];
result[key] = value;
}요런식으로 key value를 추출해서 json에 저장하도록 했다.
그리고 최대한 유니크한 패턴을 만들어서 적용 하자
예를 들어 [key = value] 이런 패턴으로 하면 로그에 배열 같은 걸 출력할 일이 있으면 파싱이 제대로 되지 않을 위험이 있다.
[list = [1,2,3]] 이렇게 돼있으면 key가 list, value가 [1,2,3 이런식으로 출력될 것이다.
여기 까지 하면 아래 처럼 json이 만들어져서 opensearch cluster로 전달될거다. (실제로는 필드가 훨씬 더 많겠지만..)
{
"time": "2024-04-30T08:22:07.475087542Z",
"stream": "stdout",
"_p": "F",
"log": {
"log_level": "INFO",
"timestamp": "2024-04-30 08:22:07.474",
"requestId": "abcd",
"status_code": "200"
},
"kubernetes": {
"pod_name": "",
"namespace_name": ""
}
}여기서 opensearch 클러스터에서 확인할 필요없는 값은 람다 코드에서 제거하고 보내든가 하면 된다.
자 그러면 이제 우리는 opensearch에서 이 값들을 확인하거나 시각화 할 수 있게된다.
