회사에서 msk 인프라를 구축하고 스프링부트에서 사용해야 하는 일이 있었는데, 이거 관련해서 자료가 많이 없어서 고생했었다.. 특히 서버리스는 더..ㅠ..
한 이틀은 새벽까지 해서 겨우 어느정도 이해하고 사용할 수 있었다. 나는 aws도 잘 몰랐고 카프카도 잘 몰랐었고 사내에서도 사용해 본 사람이 한 명도 없었기 때문에 정말 막막하고 힘들었는데.. 나같은 사람이 또 있을까 싶어 늦었지만 포스팅 해보려고 한다.
MSK serverless 사용하기
1. 서버리스 카프카 생성

우선 msk 탭으로 들어가서 서버리스로 클러스터를 생성해준다.
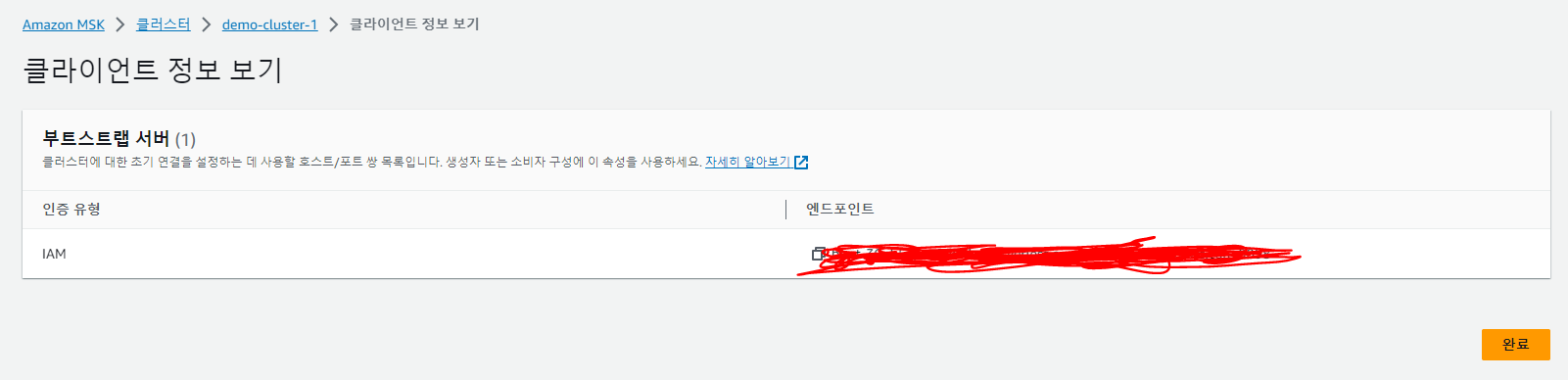
그리고 나서 클라이언트 정보보기를 하면 위와 같이 부트랩서버의 엔드포인트가 뜬다. 우린 이걸 통해서 카프카에 접근할 수 있다.
이제 여기 접근하는 게 문젠데... 같은 vpc 내에 있는 서버에서만 접근할 수 있고, 또 서버리스는 iam 기반 인증밖에 안되기 때문에 iam 쪽 설정을 해줘야 한다.
2. iam 정책 구성
속성 > 보안 설정 쪽에 보면 iam 정책 구성이라고 있는데 그거 눌러보면 아래 처럼 나온다.
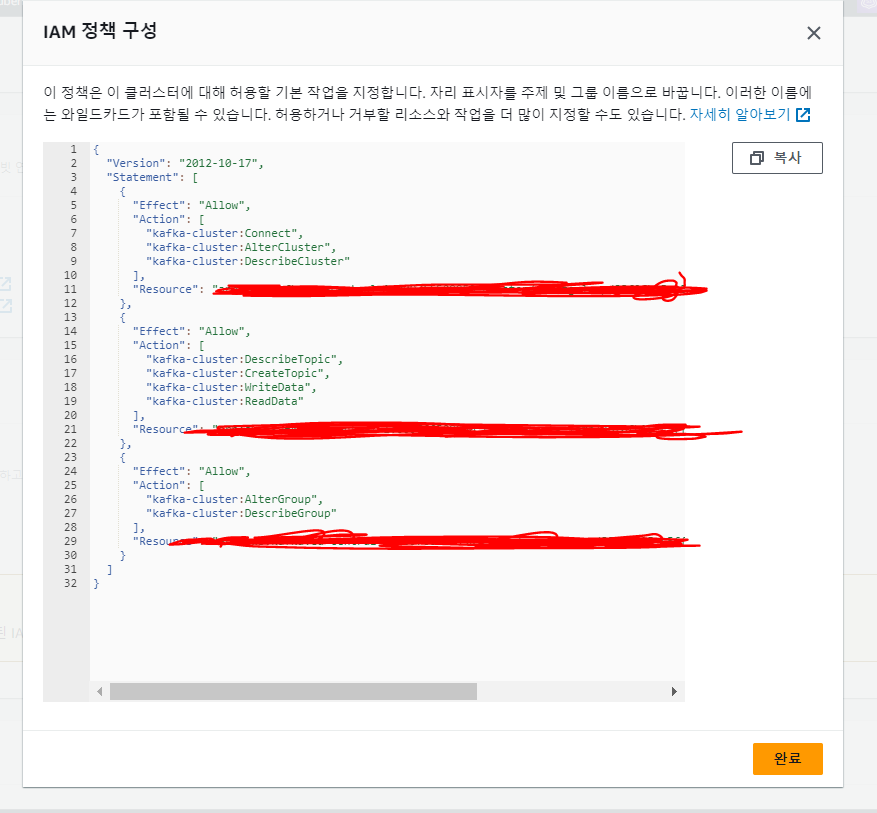
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:Connect",
"kafka-cluster:AlterCluster",
"kafka-cluster:DescribeCluster"
],
"Resource": "arn:~~~"
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:DescribeTopic",
"kafka-cluster:CreateTopic",
"kafka-cluster:WriteData",
"kafka-cluster:ReadData"
],
"Resource": "arn:~~~/<TOPIC_NAME_HERE>"
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:AlterGroup",
"kafka-cluster:DescribeGroup"
],
"Resource": "arn:~~~/<GROUP_NAME_HERE>"
}
]
}이런 형식일텐데 권한 추가하고 싶은 거 있으면 추가하고 iam 정책을 구성하러 가면된다. 나는 이대로 사용했고 뒤에 <TOPIC_NAME_HERE> 나 <GROUP_NAME_HERE> 이거는 * 로 설정했다 (모든 토픽, 그룹에 대해 권한 부여) 뭔가 커스텀이 필요하다면 적절히 구성해주면 된다.
이제 iam > 정책 > 정책 생성으로 이동한다.
그리고 여기서 json을 선택하고 위에서 설정한 걸 그대로 복붙해서 생성해주면 된다.
그리고 iam > 사용자 > 사용자 생성으로 이동해서 해당 권한을 추가한 iam 유저를 만들어 준다. 우리는 이 유저로 자격 증명을 해서 카프카에 접근할 수 있다.
3. 스프링 부트에서 접근하기
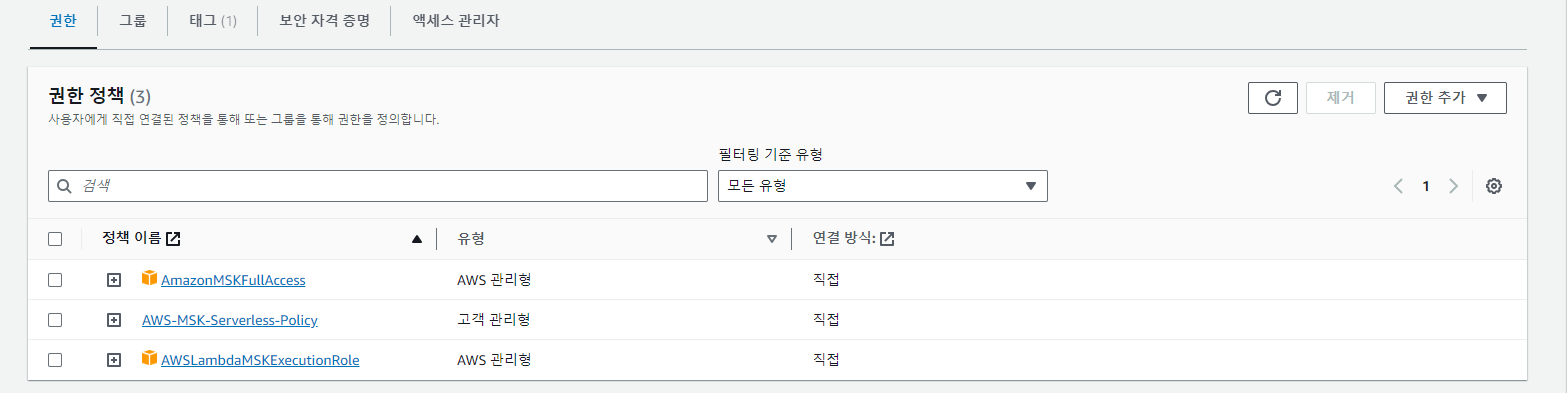
나는 다른 권한도 몇 개 추가해줬다.
그리고 보안자격 증명 탭으로 들어가서 새로운 액세스 키를 만들어준다.
그러면 이제 액세스 키와 시크릿 키가 나오는데 이걸 스프링 부트에 적용하면 된다.

적용하는 법은 여러 개 있는 것 같던데, 나는 yml에 환경별로 키를 정의해놓고 받아와서 이렇게 시스템 프로퍼티에 추가해서 사용했다.
spring:
kafka:
properties:
security.protocol: SASL_SSL
sasl.mechanism: AWS_MSK_IAM
sasl.jaas.config: software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class: software.amazon.msk.auth.iam.IAMClientCallbackHandler그리고 또 추가적으로 iam으로 접근하게 하기 위해서는 스프링 부트에서 위의 설정을 추가해줘야 한다...ㅎ
스프링부트에서 자동으로 등록해주는 빈을 사용하고 있다면 위에 처럼 yml에 설정하면 되고, 따로 카프카 프로듀서나 컨슈머를 커스텀해서 빈으로 등록해서 사용하고 있다면 아래처럼 등록해줘야한다.
public SenderOptions<String, Object> senderOptions() {
Map<String, Object> props = new HashMap<>();
props.put("security.protocol", securityProtocol);
props.put("sasl.mechanism", sasllMehanism);
props.put("sasl.jaas.config", jaasConfig);
props.put("sasl.client.callback.handler.class", saslCallbackHandler);
return SenderOptions.create(props);
}
@Bean
public ReactiveKafkaProducerTemplate<String, Object> reactiveKafkaProducerTemplate(SenderOptions<String, Object> senderOptions) {
System.setProperty("aws.accessKeyId", awsAccessKey);
System.setProperty("aws.secretKey", awsSecretKey);
return new ReactiveKafkaProducerTemplate<>(senderOptions);
}대충 이런식으로...
그러면 이제 스프링부트에서 설정이 끝났다!!
이제 같은 vpc 상의 서버에 올려서 접근되는 지 확인 해 보면 된다. 로컬에선 같은 vpc가 아니라 접속이 안될 거다.
뭔가 무한으로 로그가 뜬다거나 메모리 초과가 나거나(연결이 안돼서 무한으로 시도하다가 메모리 초과가 나는 것 같다. 메모리 부족한 줄 알고 괜히 힙 메모리 늘려봤자 소용없다.) 하면 실패다. 다시 설정을 살펴보길 바란다.
번외. 토픽 생성하기
혹시나 해서 토픽 생성하는 법도 남겨둔다.
일단 카프카랑 같은 vpc에 있는 ec2에 접속한다.
그리고 aws configure 명령어를 쳐서 액세스 키랑 시크릿 키를 등록해준다.
위에서 만든 iam의 키를 사용하면 될 줄 알았는데 안돼서...
나는 루트 계정의 보안자격 증명의 키를 만들어서 사용했다.
그리고 카프카를 설치한다. 그리고 설치 경로의 bin으로 들어가서 아래 명령어로 토픽을 생성해주면 된다.
./kafka-topics.sh --bootstrap-server $BS --command-config client.properties --create --topic <토픽명> --partitions 3여기서 중요한 건 --command-config를 빠트리면 접속이 안된다. client.properties는 아래처럼 설정해서 저장해두고 사용하면 된다.
security.protocol=SASL_SSL
sasl.mechanism=AWS_MSK_IAM
sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler여기 까지 알아 낼 때 까지 정말.. 힘들었었어서 이 글이 누군가에게... 도움이 됐으면 좋겠다.
그래도 이렇게 한 번 해보니까 iam, 보안 그룹이런 거에 대해서 거의 몰랐는데 감이 잡혔고 신입이 하기 힘든 좋은 경험이었다.
