개요
3주차 미션을 진행하면서 그 때 그 때 궁금한 점과 고민을 해결하는 과정을 정리해보려고 한다.
🔎 테스트 메소드 이름을 어떻게 지어야할까
@DisplayName으로 테스트의 의도는 전달이 되겠지만 그와 별개로 메소드의 이름을 붙여줘야하기에
일단 어두에 check_를 붙이고 테스트할 메소드 이름을 붙이는 방식으로 해보고 리뷰를 통해 함께 이야기해보려고 한다!
🔎 READ.ME에 리팩토링 항목, 고민 항목 정리
지난주의 경우 리팩토링을 한다고는 했으나 빠뜨린 점이 꽤나 많았다.
이유를 생각해보면, 그냥 전체 파일 돌면서 닥치는 대로 리팩토링을 하다보니 빠뜨리는 것들이 생기는 것 같다.
그래서 이번주는 리팩토링 항목, 고민 항목을 기능 구현 목록처럼 READ.ME에 작성해두고
항목별로 차근차근 리팩토링 해보는 방식을 시도해보려고 한다!
🔎 모든 메소드를 테스트해야할까? 어떤 기준으로 테스트를 해야할까?
TDD 기반으로 미션을 진행해보고 있는 중이기 때문에 처음에는 대부분의 메소드에 대해 테스트가 작성되게 된다. 하지만 기능을 구현해가며 private 메소드가 되는 경우도 있어서 그러한 메소드들의 테스트는 삭제하는 과정을 거치게 된다.
그러면서 지난주에는 호출만 하는 메소드인데도 테스트가 작성되어있고, 삭제하는 과정에서 오히려 필요한 기능에 대한 테스트가 빠진 경우도 있었다.
그러면서 질문이 들게 되었다.
모든 메소드를 테스트하는 것이 TDD에 충실한 것일까?
아니라면, 내가 테스트를 작성하고, 삭제하고, 남기는 나의 기준은 무엇일까?
우선, 어차피 삭제될 테스트 케이스에 대한 테스트를 작성해놓았으니 불필요한 일을 한 걸까?
아니라고 생각한다. TDD의 원칙에서 테스트 코드를 통해 프로덕션 코드를 작성한다는 부분의 목적에 대해 동의한다. 이로써 입력, 출력을 명확하게 알고 프로덕션 코드를 작성하기 때문에 이 방법이 합리적이라고 생각한다! 즉, 삭제될 테스트 케이스더라도 작성하는 것은 의미가 있다!
두번째로, 테스트를 남기는 나의 기준은
1. 다른 기능들과 연결되어 기능 실행 확인에 필요한 경우는 상세하게 테스트하고,
2. 단순히 호출만하는 경우라면 간단하게 결과 확인정도로만 할 수 있을 것 같다.
- 테스트 케이스마다 중요도가 다르다.
- 테스트 역시 비용이기에 구분할 필요가 있다.
- 모든 메소드에 대응하는 1대1 테스트를 만들 필요는 없다.
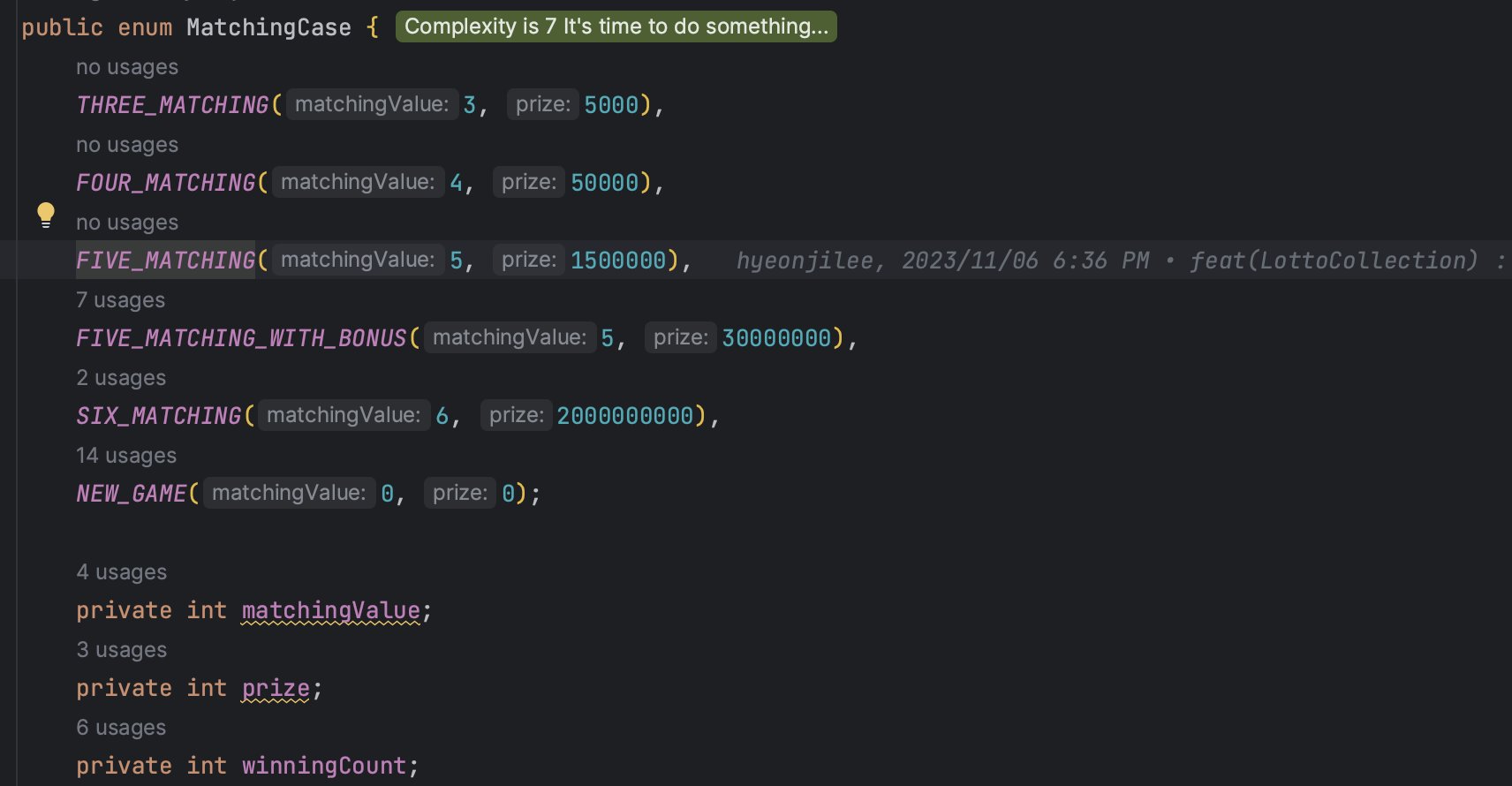
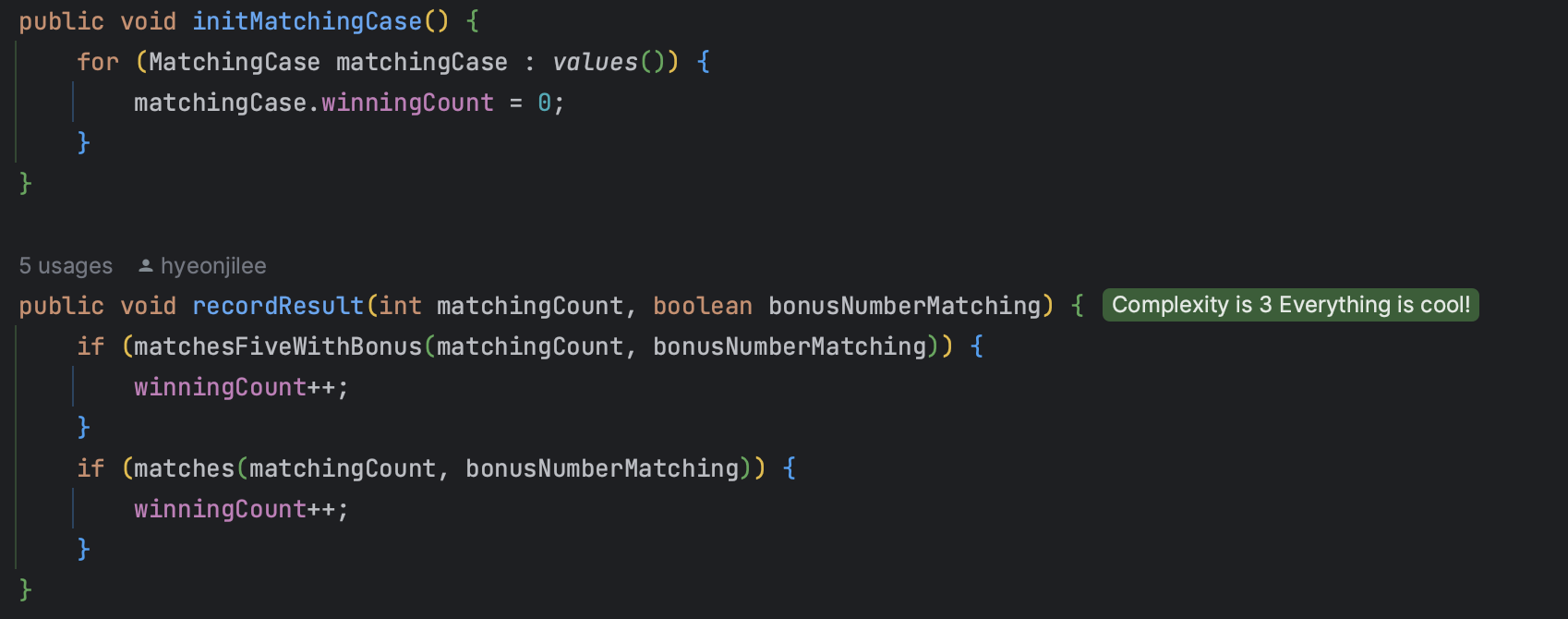
🔎 enum을 객체처럼 써서, 결과를 담게해도 될까?
현재 그런 방법으로 하고 있는데 하나하나 테스트 할 때는 문제가 없었지만
전체 테스트를 돌리니 결과를 담는 게 중첩되다 보니 제대로 나오지 않았다.
그래서 초기화 메소드를 enum 자체에 넣어주어 해결했는데,
이게 적절한 방식인지... 이렇게 하면서 enum을 쓰는 게 맞는지 하는 생각이 들었다.
리뷰어 분들과 이야기 나눠봐야할 부분!
🔎 String.format 소수점 자리수 출력!
실수형, 정수형 숫자 형식을 설정하는 방법을 계속 까먹는 것 같아서 다시 한 번 정리!
%f
(Floating point Formatting)
System.out.println(String.format("%.3f", 123.45678)); // 123.456- 소수점 아래 3자로 반올림하여 나타내라
%d
(Integer Formatting)
System.out.println(String.format("%05d", 123)); // 00123- 빈자리값은 0으로 채워서 5자리로 나타내라
🔎 View에서의 출력 문구의 상수화 필요?
어느새 관습적으로 view에서 사용되는 출력 문구는 모두 상수화를 하고 있었다.
하지만 지난 리뷰 때 받은 애플리케이션 내의 모든 문자열이 매직 스트링이고 하드 코딩일까요?라는 질문 이후로 이 부분도 다시 생각해보게되었다.
- 상수화가 가독성에 도움이 되는가? NO
파악하기 쉽게 네이밍을 했으나, 직접 문구가 표출되는 것보다 이해가 빠를 수는 없다. - 상수화가 유지보수와 관리에 도움이 되는가? 재사용성이 높은가? NO
입, 출력에 쓰이는 문자열은 한 번만 쓰고 사용되지 않는다.
상수화가 더 효과적이지 않다는 결론을 내리고 이번에는 문자열 그대로 주입시켜줬다!
🔎 과도한 불변성 적용?
지난 미션 때 파라미터의 final 키워드와 unmodifiableList를 처음 적용해보면서
말 그대로, 붙일 수 있는 모든 곳에 다 붙였다(?)😂
하지만 그렇게 하니 생길 수 있는 문제점에 대해서 생각이 들었다.
- 읽는 사람 입장에서 파라미터에 final 키워드가 붙었다는 것은, 조심해야하는 데이터라는 추가 해석의 여지를 준다.
- 설계가 변경되었을 때 오류를 발생시킬 수 있는, 즉, 설계의 유연성을 떨어뜨린다.
단, getter로 리스트 레퍼런스를 그대로 반환하는 경우나,
Dto와 같이 무결성, 불변성이 보장되어야하는 클래스의 경우 유용하게 적용할 수 있을 것 같다!
- 참고할만한 포스팅 : https://cobi-98.tistory.com/59
🔎 객체 Validate의 새로운 도입!
사실 그동안 객체의 검증은 해당 객체 부생성자에서 호출하여 객체 내에 존재하였다.
하지만 이 방식을 사용하면서 몇가지 이유로 찝찝함이 있었다.
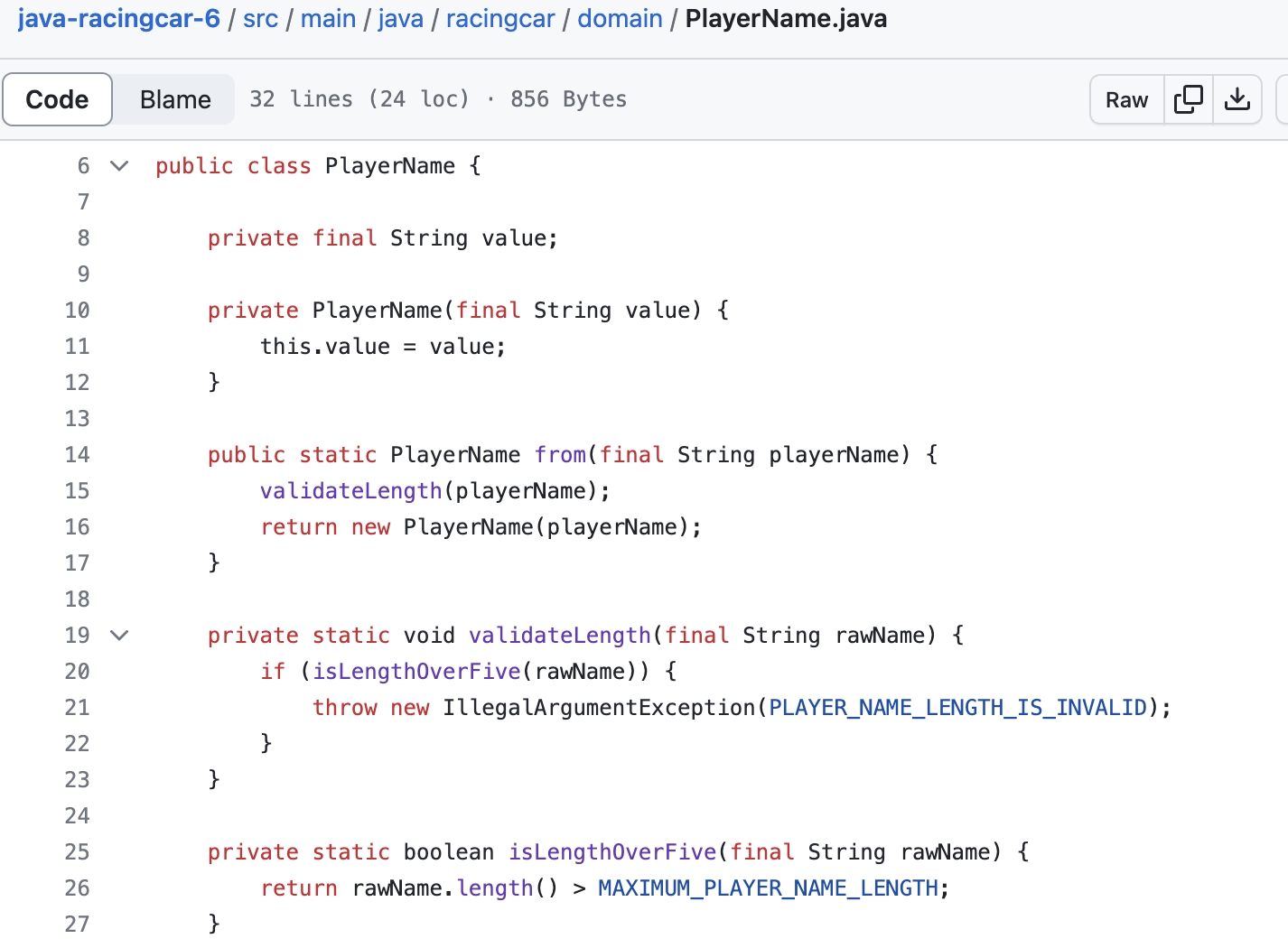
- 검증이 복잡한 경우 객체의 많은 부분을 차지하고, 객체와 관련된 비즈니스 로직과의 구분이 어려워진다.
- 검증은 객체 안에서만 일어나기때문에 private지만 static 부생성자에서 호출되기 때문에 static 메소드이다.
그렇게 이번주 리뷰를 다니다가 흥미로운 방식을 발견했다!
새로운 방식
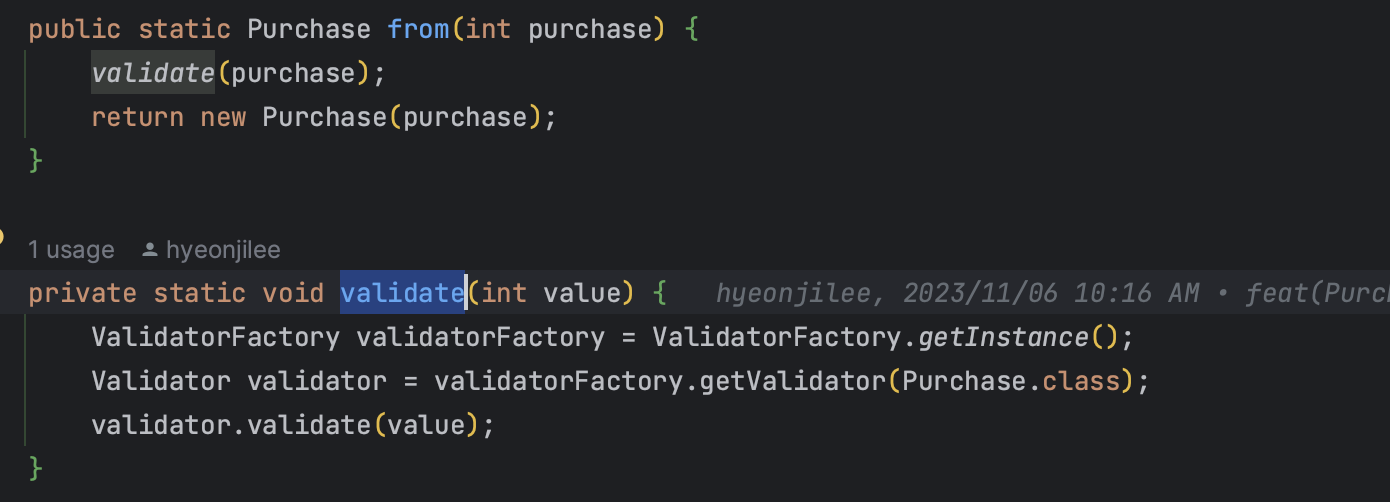
ValidatorFactory.getInstance를 통해ValidatorFactory는 전체 프로그램을 통틀어서 딱 한 번 생성된다 → 싱글톤 패턴- 그리고 거기서
getValidator는 검증을 원하는 클래스에 해당되는validator를 반환해준다. - 그 해당
Validator를 갖고validate를 진행한다.
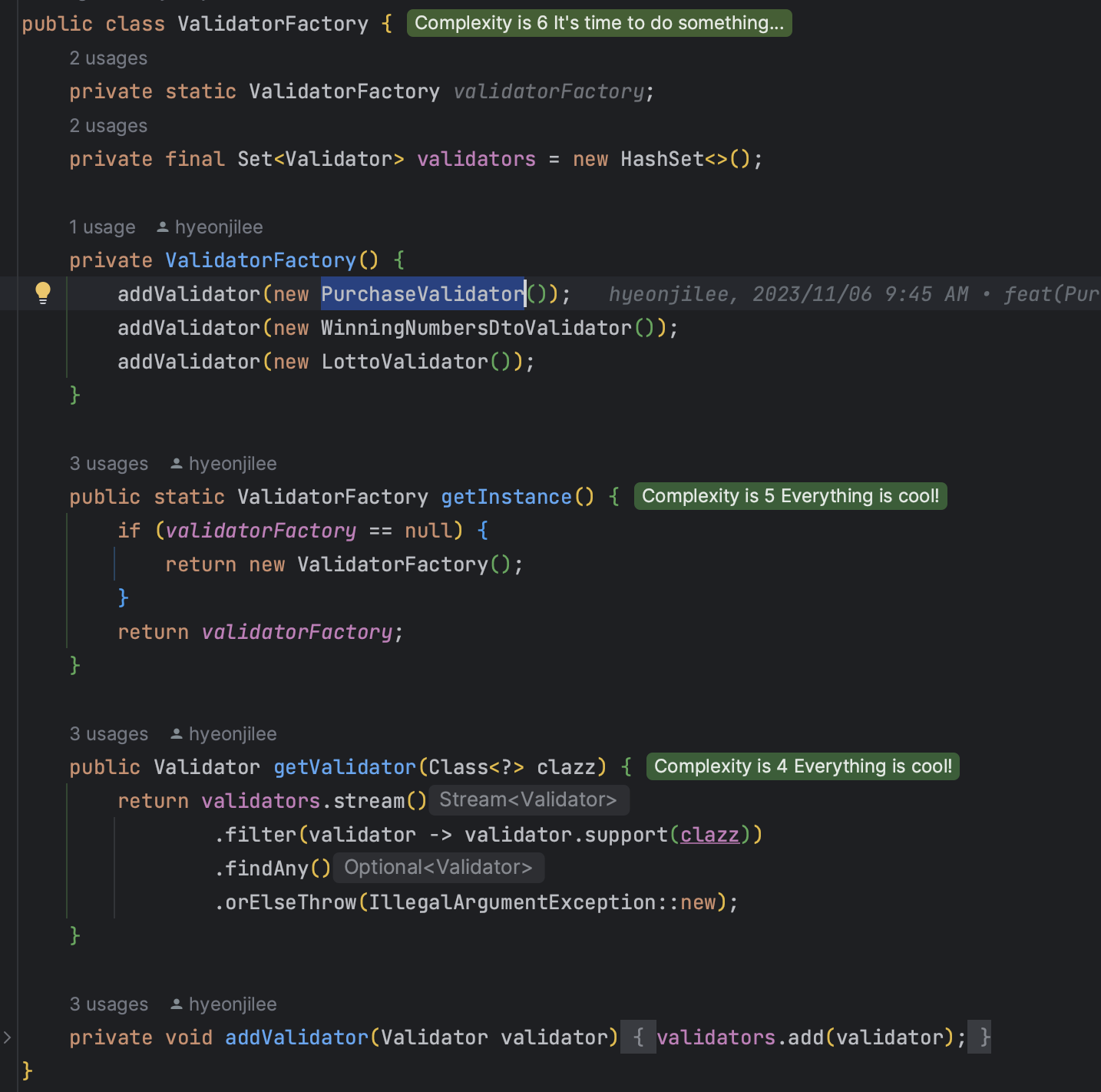
- 각 클래스에 대응하는
Validator는Validator를 상속받고 팩토리 클래스 생성시 딱 한 번만 생성되어 팩토리 클래스가 갖고있다가 호출이 오면 클래스에 맞는 Validator를 반환해준다.
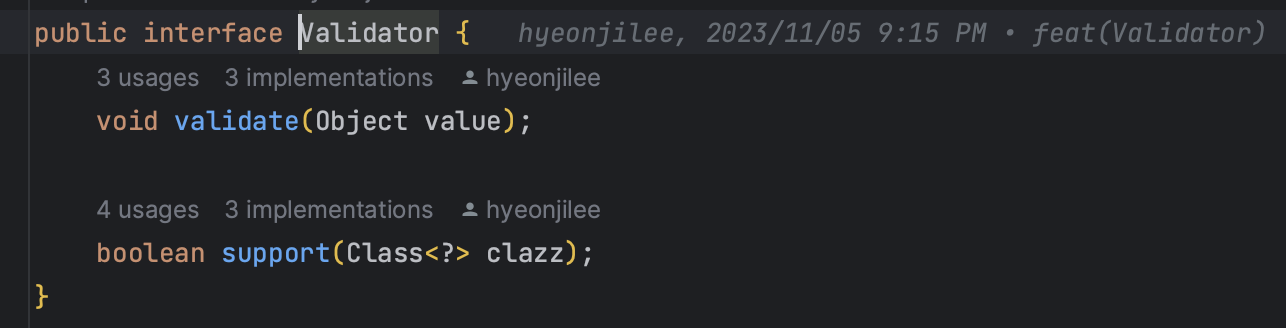
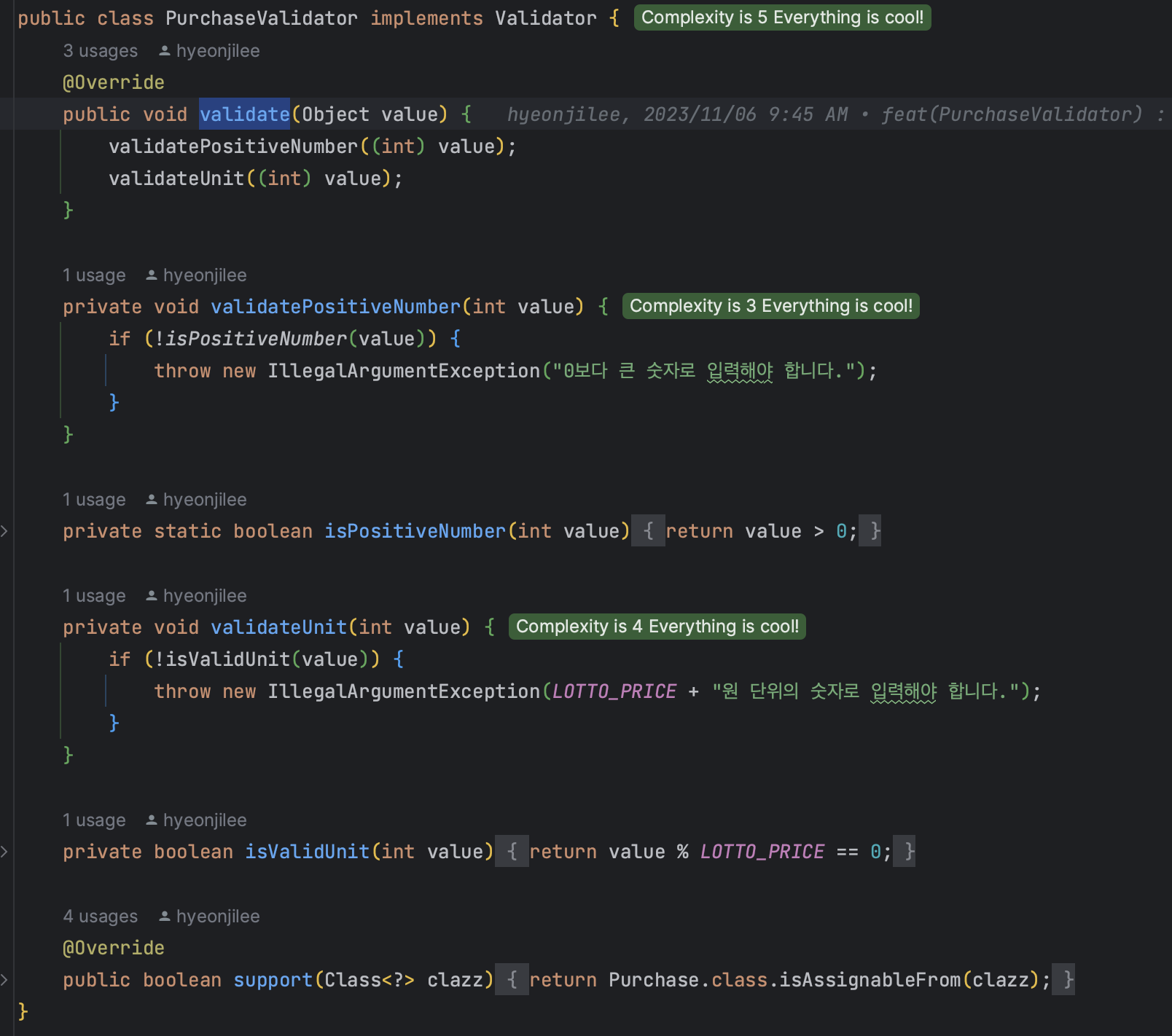
- 객체별
Validator에 필요한 검증 메소드를 다 넣어주면 된다!
기존 방식과 비교
성능 상?
- 객체별
validator를 반환해주는ValidatorFactory는?
: 이건 프로그램 전체에 있어서 딱 한번만 생성된다. OK! - 객체별
validator는?
:ValidatorFacotry가 생성될 때, 딱 한 번 생성되어서 멤버변수로 갖고 있는다. OK!
그 외 장, 단점?
- 객체 내 직접 검증 방식 (기존 방식)
- 장점
- 코드가 단순하다.
- 별도의 인터페이스,
Factory클래스가 필요하지 않아 복잡성이 낮다.
- 단점
- 객체 내의 검증 메소드로 다른 비즈니스 메소드와 구분이 어렵다.
Validator Factory방식 (새로운 방식 )
- 장점
- 유효성 검사 로직이 분리되므로 객체 내에는 순수 비즈니스 로직만 남게된다.
- 유효성 검사가 복잡해져도 따로 관리되므로 괜찮다.
- 좀 더 객체 지향적이며 확장 가능한 구조를 가진다.
- 단점
- 별도의 인터페이스,
Factory클래스가 필요해 복잡성이 올라간다.
- 별도의 인터페이스,
- 결론?
작은 규모에서는 직접 검증도 괜찮지만, 규모가 더 커지거나 확장성이 중요한 경우에는 Validator Factory 방식이 더 효율적이다!
- 변경된 validate 방식에 따른 테스트


🔎 콘솔 출력, 입력, 검증 과정 반복의 메소드화!
저번주의 InputView 코드를 보면 아래와 같이
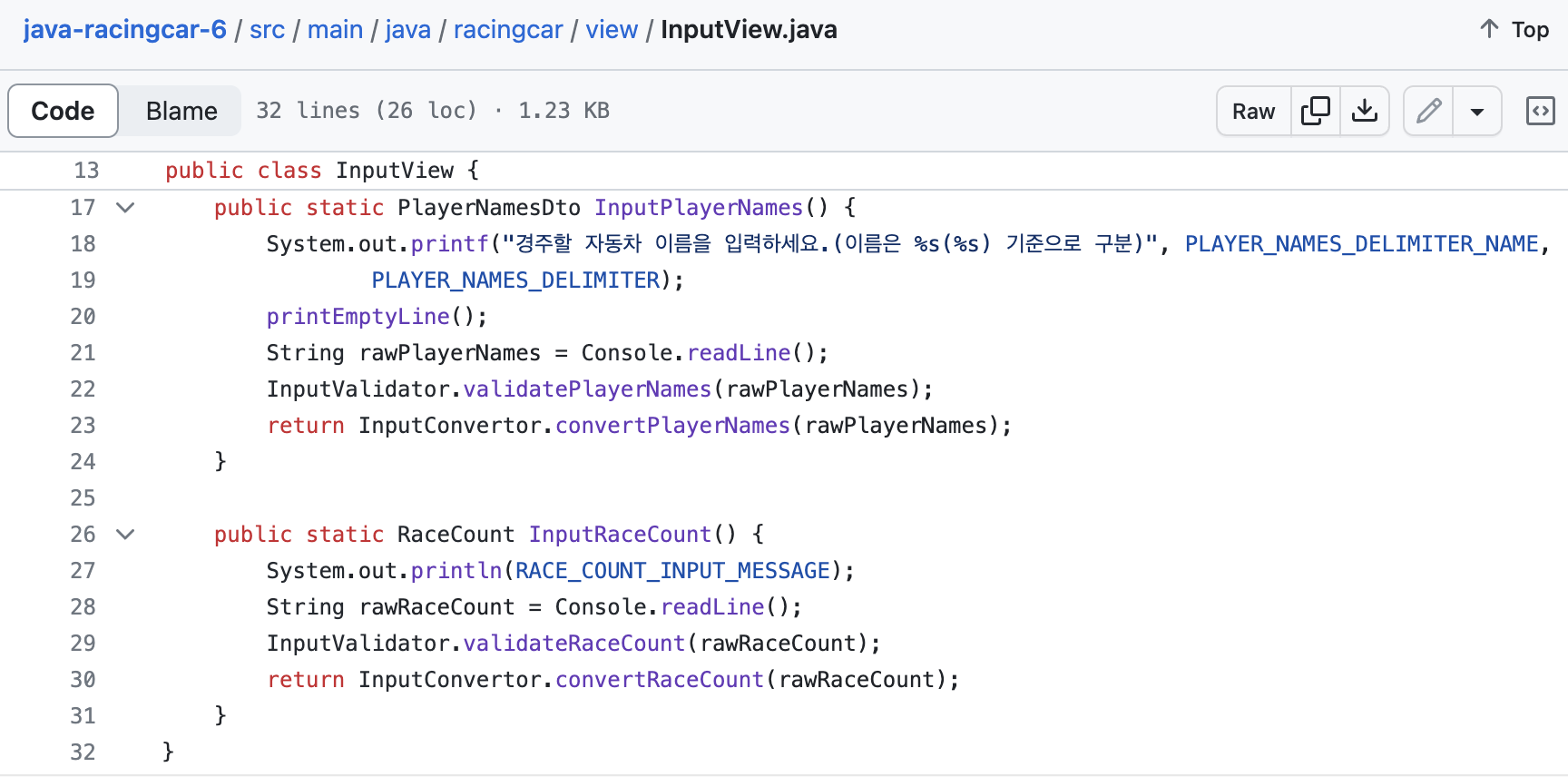
- 콘솔에 입력 문구를 출력하고
- 입력값을 읽어오고
- 입력값에 대한 공백 검증
- (숫자의 경우) 숫자 형식 검증
이 과정이 계속 반복된다는 것을 발견할 수 있었다. 그렇다면... 메소드 분리 출동!!
결과적으로, 이렇게 3(or 4)개의 과정을 메소드로 분리해줌으로써 input 메소드들이 간단해질 수 있었다!
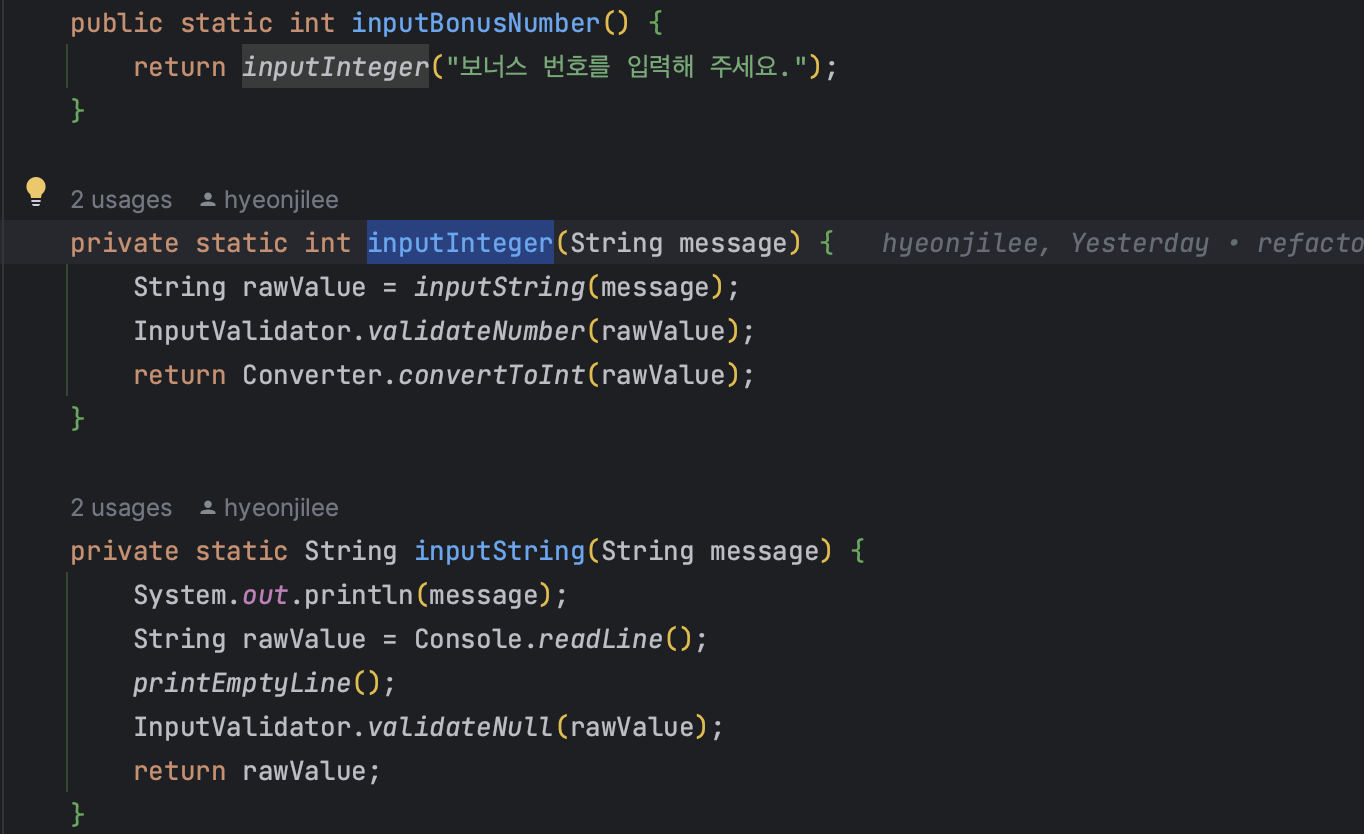
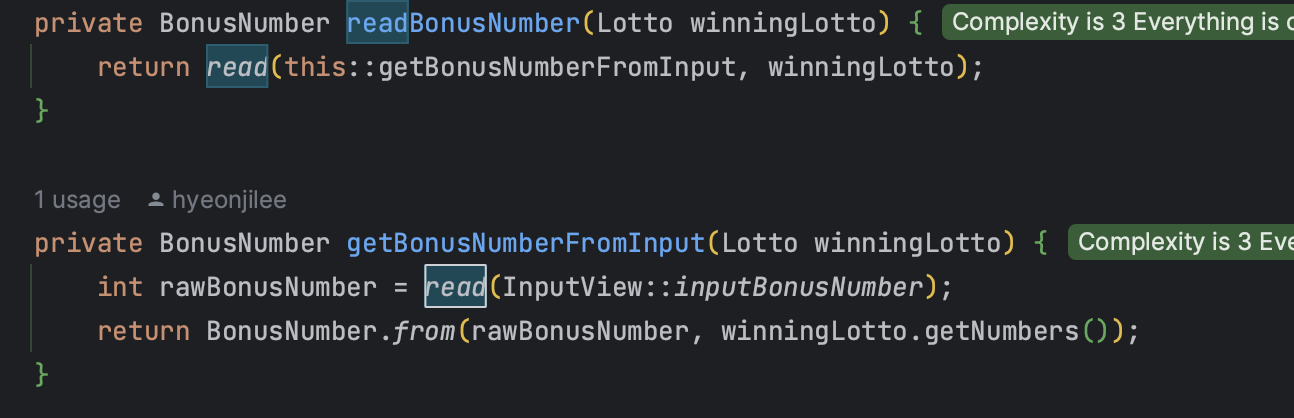
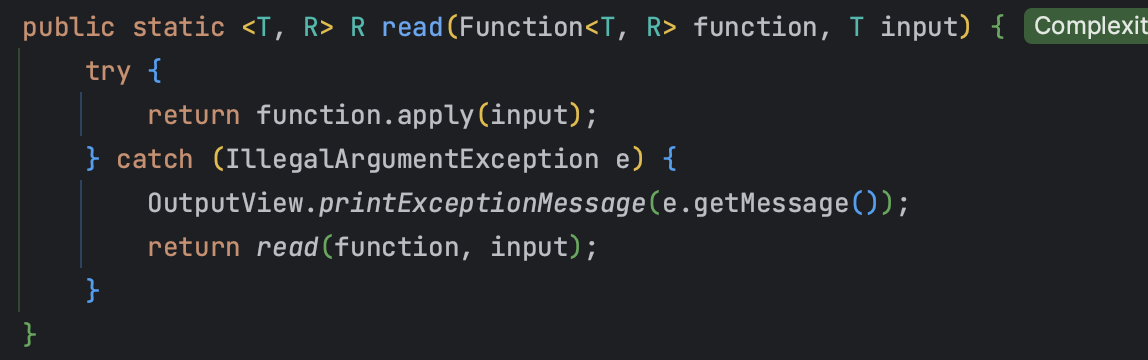
🔎 재입력 read 메소드의 사용!
이번 요구 사항에는 사용자가 잘못된 값을 입력할 경우 ... 에러 메시지를 출력 후 그 부분부터 입력을 다시 받는다. 의 내용이 있었기 때문에 예외 발생시 재입력을 받는 로직이 필요했다.
그리하여 적용하게 된 RetryUtil!
이 read 메소드는 파라미터에 따라 2가지이다.
- 그냥 input 받아서(
Supplier<T>) 예외시 예외메시지 출력 후read반복

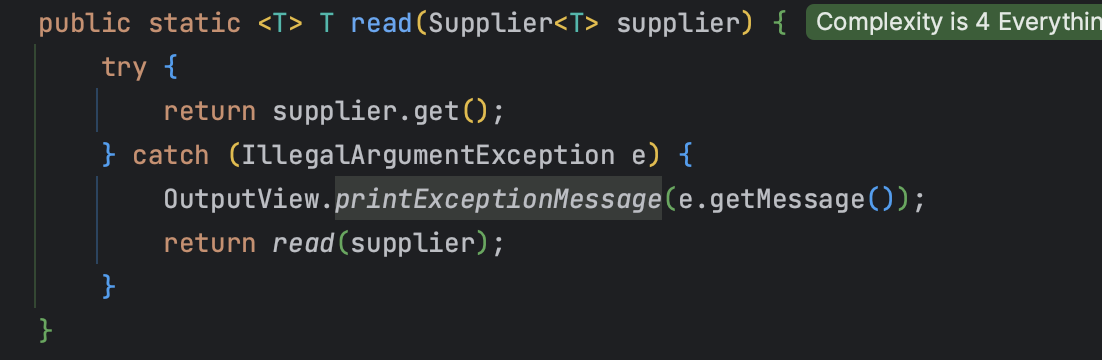
- 입력값을 넣어서(
T input) input을 받아서(Function<T, R>) 예외시 예외메시지 출력 후read반복
🔎 View 클래스들의 정적 메소드화 vs 싱글톤 객체화?
그동안 View의 메소드를 컨트롤러에서 호출할 때,
1. 싱글톤 패턴으로 객체를 생성해서 호출하거나
2. 정적 메소드로 선언해서 객체 생성없이 유틸처럼 호출하곤 했다.
1, 2주차 각각 다른 방식을 썼고 현재는 2번 방식을 쓰고있다.
그러면서 두 방식의 장, 단점과 어떤 걸 쓰는 것이 좋은지에 대한 고민이 들었다.
- 싱글톤 패턴 방식
- 장점
- 의존
- 캡슐화해서 관리가 된다.
- 의존성 주입을 통해 Mock을 주입하여 테스트를 할 수 있다. (? 아직 필요성 못 느낌)
- 단점
- 싱글톤 패턴은 항상 메모리에 상주하므로 메모리 부담이 있다.
- 컨트롤러에 Input, OutputView까지 해서 생성자로 주입되 선언된 멤버 변수가 2개가 추가된다.
- 싱글톤 구현을 위한 코드가 늘어나서 복잡성이 증가한다.
- 정적 메소드 방식
- 장점
- 호출이 간단하다.
- 의존성 관리가 쉽다. 의존성이 최소화된다.
- 단점
- 확장성이 제한된다.
결론
복잡한 프로그램, UI가 다른 객체와 상호작용하면서 의존성 관리와 테스트가 필요한 경우
UI의 확장성이 필요한 경우
-> 싱글톤 방식
단순한 프로그램이기에 상호작용이 많지 않고, 의존성 관리를 쉽게 하고 싶은 경우
-> 정적 메소드 방식
🔎 의존관계, 연관관계 그려보기!
2주차 미션 때, 의존성이 강하게 생기는 클래스들이 서로 생기다보니 리팩토링하면서 그 의존성을 끊어주는 것이 상당히 까다로웠다.
따라서, 이번주에는 구상 단계에서부터 의존성... 의존성... 하면서 의존 관계를 최소화하려고 노력했다.
하지만, 객체 간의 의존성을 파악하는 것부터가 어려웠다.
짜고 나니 너무 의존성이 강한 것은 알겠는데, 그래서 어떻게 구상해야 필요한 값을 사용하면서도 객체간의 의존성을 낮출 수 있는 거지...
그러다가 객체간의 의존성에 대한 강의도 들으며 의존관계, 연관관계에 대한 개념을 잡고
: [우아한테크세미나] 190620 우아한객체지향 by 우아한형제들 개발실장 조영호님
강의에서 나왔던 것 처럼 그림으로 의존관계, 연관관계를 그려보면서 계속해서 점검하려고 했다!
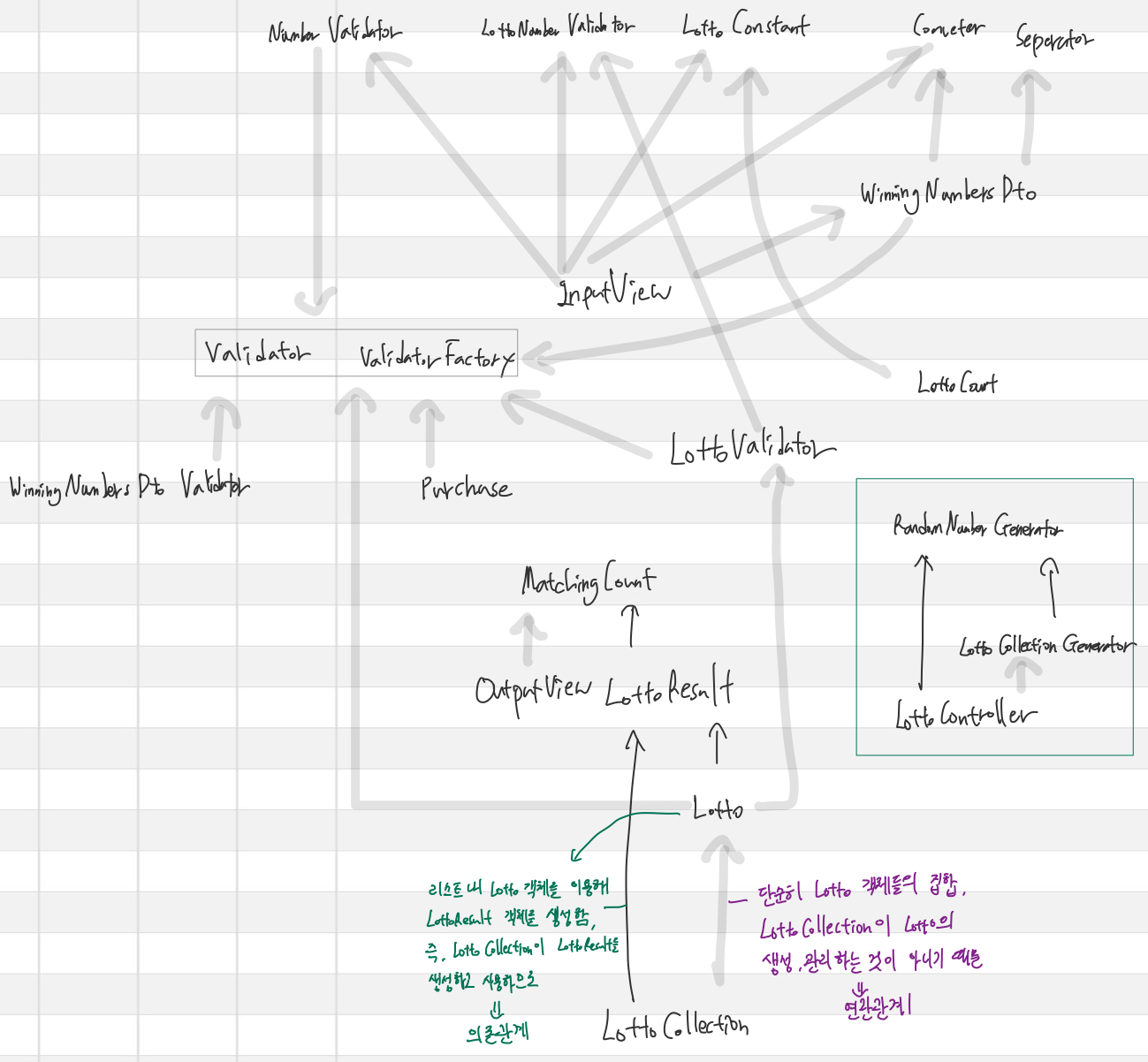
용어 정리
- 의존 관계
한 클래스가 다른 클래스의 인스턴스를 생성하거나 사용하는 경우에 발생- 연관 관계
한 클래스가 다른 클래스와 어떤 방식으로 상호 작용하는지 클래스 간의 관련성을 나타냄
🔎 PR 본문 작성해보기!
PR을 읽는 사람들이 어떤 점을 중점으로 보았으면 하는지를 추가하고 싶었고,
리뷰 중 발견한 KPT 회고 방식으로 작성해보았다!
🔎 프로젝트 시작 전 적용할 것 정리해두기!
개행이나 자동 import 삭제 등이 미션을 새로 할 때마다 설정이 리셋되어 정리해두어야겠다!
- 사용하지 않는 import 자동 삭제
File - Settings - Editor - General - Auto Import -" Optimize imports on the fly" - Gradle - InteliJ IDEA
- Gradle - jdk 17
- project structure - jdk 17
- editor - wootech style
