개요
3주차 역시 리뷰를 보다보니 '이렇게 할걸!' 하는 점들과 새로운 방식을 시도해봐야겠다는 점이 많았다. 다 정리해보자!
📬 공통 피드백
띵동. 3주차 행운의 메일이 도착했습니다!
1. 함수(메서드) 라인에 대한 기준
: 프로그래밍 요구사항을 보면 함수 15라인으로 제한하는 요구사항이 있다. 발생할 수 있는 예외 상황에 대해 고민한다
2. 정상적인 경우를 구현하는 것보다 예외 상황을 모두 고려해 프로그래밍하는 것이 더 어렵다. 예외 상황을 고려해 프로그래밍하는 습관을 들인다.
3. 비즈니스 로직과 UI 로직을 분리한다
4. 연관성이 있는 상수는 static final 대신 enum을 활용한다
5. final 키워드를 사용해 값의 변경을 막는다
6. 객체의 상태 접근을 제한한다
: 인스턴스 변수의 접근 제어자는 private으로 구현한다.
7. 객체는 객체스럽게 사용한다
8. 필드(인스턴스 변수)의 수를 줄이기 위해 노력한다
9. 성공하는 케이스 뿐만 아니라 예외에 대한 케이스도 테스트한다
: 특히 프로그램에서 결함이 자주 발생하는 부분 중 하나는 경계값이므로 이 부분을 꼼꼼하게 확인해야 한다.
10. 테스트 코드도 코드다
:테스트 코드도 코드이므로 리팩터링을 통해 개선해 나가야 한다. 특히 반복적으로 하는 부분을 중복되지 않게 만들어야 한다.
11. 테스트를 위한 코드는 구현 코드에서 분리되어야 한다
테스트를 위한 편의 메서드를 구현 코드에 구현하지 마라.
12. 단위 테스트하기 어려운 코드를 단위 테스트하기
13. private 함수를 테스트 하고 싶다면 클래스(객체) 분리를 고려한다
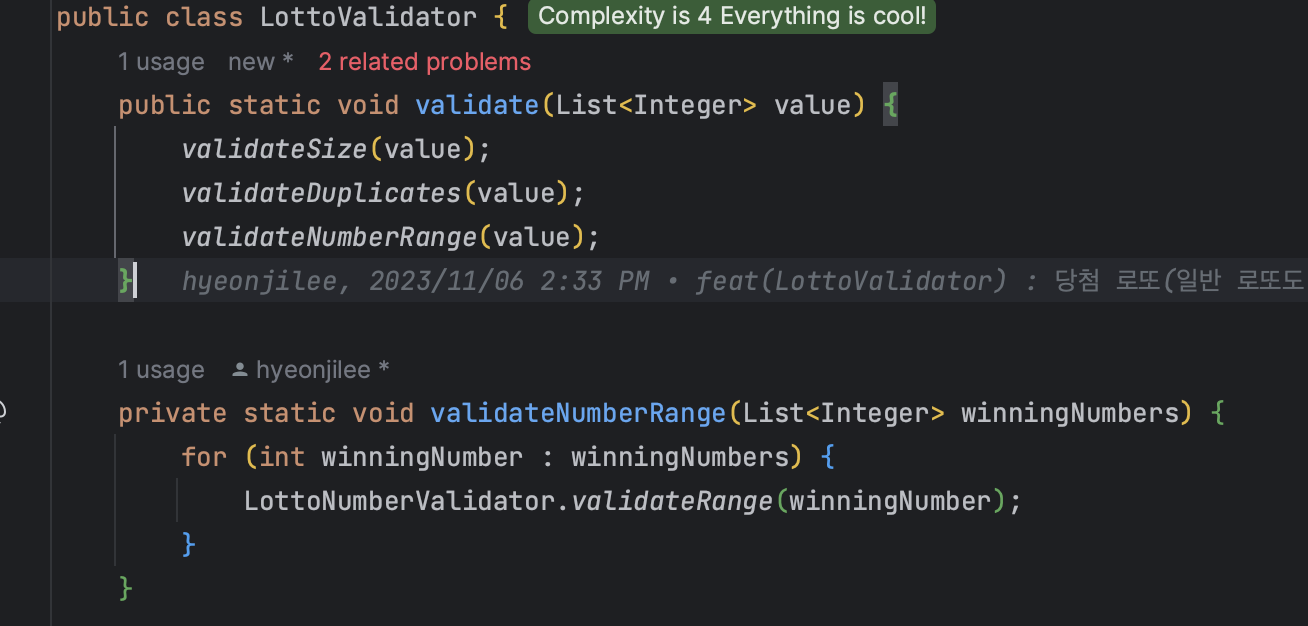
📌 Validator 팩토리, 계속 쓸까?
결론부터 말하자면,
validator 팩토리를 통해 Validator를 가져오게 했던 지난주의 방식을 다시 바꿔서 객체별 Validator를 만들어 정적 메소드를 호출해서 쓰기로 했다.
이렇게 결론을 내렸던 과정을 정리해보려고 한다.
0. 원했던 Validator의 조건
- 객체의 비즈니스 로직과 분리되어 외부에 있으면 좋겠다.
- 근데 상관없는 객체가 어떤 검증에 접근할 수 없게 해당 객체에만 검증할 수 있게 제한되면 좋겠다.
- 복잡도가 너무 증가하지 않았으면 좋겠다. 검증에 해당하는 객체에서 바로 접근할 수 있었으면.
1번 조건은 두 방식 모두 충족한다. 관건은 2, 3번 조건이 각각 다르게 충족된다는 것!
1. Validator 팩토리 방식
장점
2번 조건: 해당 객체에만 검증할 수 있게 제한 을 충족한다
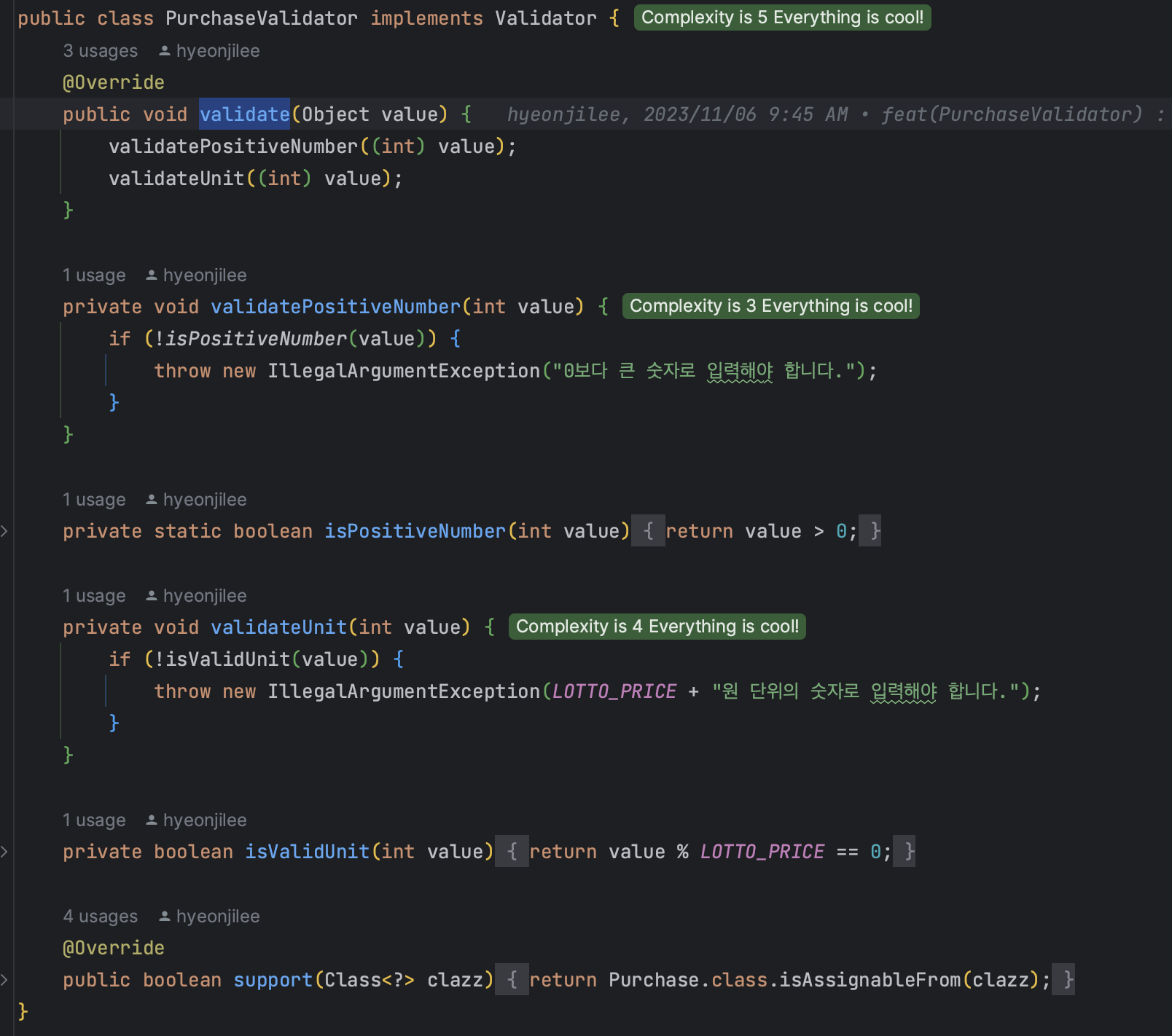
특히, 각 validator 당 하나의 객체에서만 호출될 수 있게 되어있어서 상관없는 객체에서 다른 객체의 검증 클래스를 가져다 쓰는 것을 제한할 수 있었다.
단점
- 가장 큰 문제는 팩토리 패턴 이용으로 인한 복잡도 상승이다.
- 객체에서 validate, validator로 직접 이동이 어렵다.
팩토리에 가서 해당하는 validator를 찾아서 이동하는 것이 최선이다.
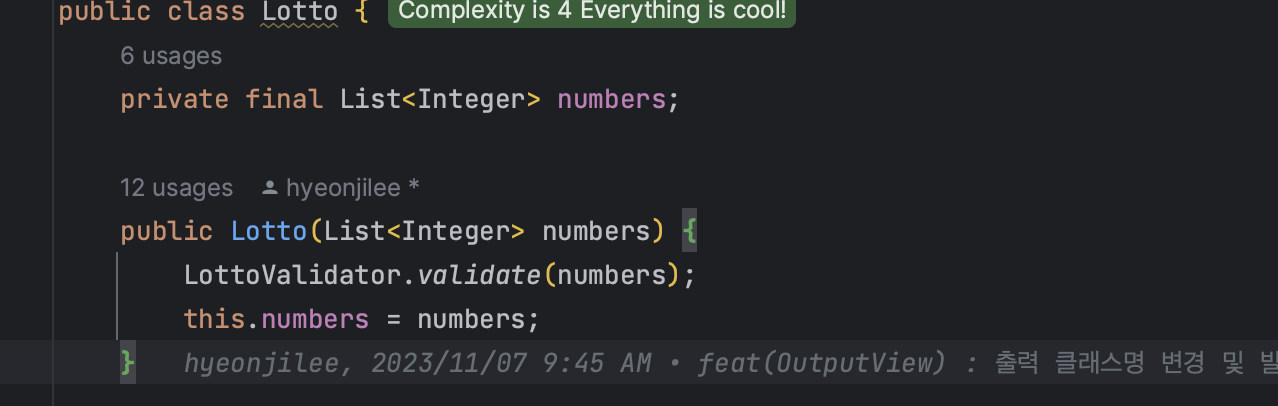
객체별 Vaidator 정적 메소드 호출 방식
장점
3번 조건인 복잡도가 낮음 을 충족한다. 객체에서 선언된 validator로 바로 이동하여 검증 클래스의 확인이 가능하다.
단점
- 다른 객체에서도 상관없는 객체의 검증 클래스를 호출하여 사용할 수 있다.
예) Purchase 클래스에서 LottoValidator.validate 호출해서 사용 가능
결론
관련없는 객체에서의 호출 제한 vs 복잡성 낮아짐,
이 두 장점의 트레이드 오프를 생각해봐야하는 상황이라고 할 수 있다.
나는 최대한 직관적인 프로그램을 만드는 것이 중요하다고 결론을 내렸고, 객체별 validator에서 정적 메소드 호출 방식으로 진행해보기로 결정하였다!
시행착오
사실 그 과정 중에 여러 방식을 시도해보았다.
1. 생성자에서 validator의 getInstance를 호출하는 방식을 처음에 생각했는데
- LottoValidator가 변경되는 클래스가 아니기에 계속해서 새로운 객체를 생성할 필요가 없기에
- 객체에 해당하는 validator 클래스를 싱글톤 패턴으로 주입하는 방식으로 구현해보았다.
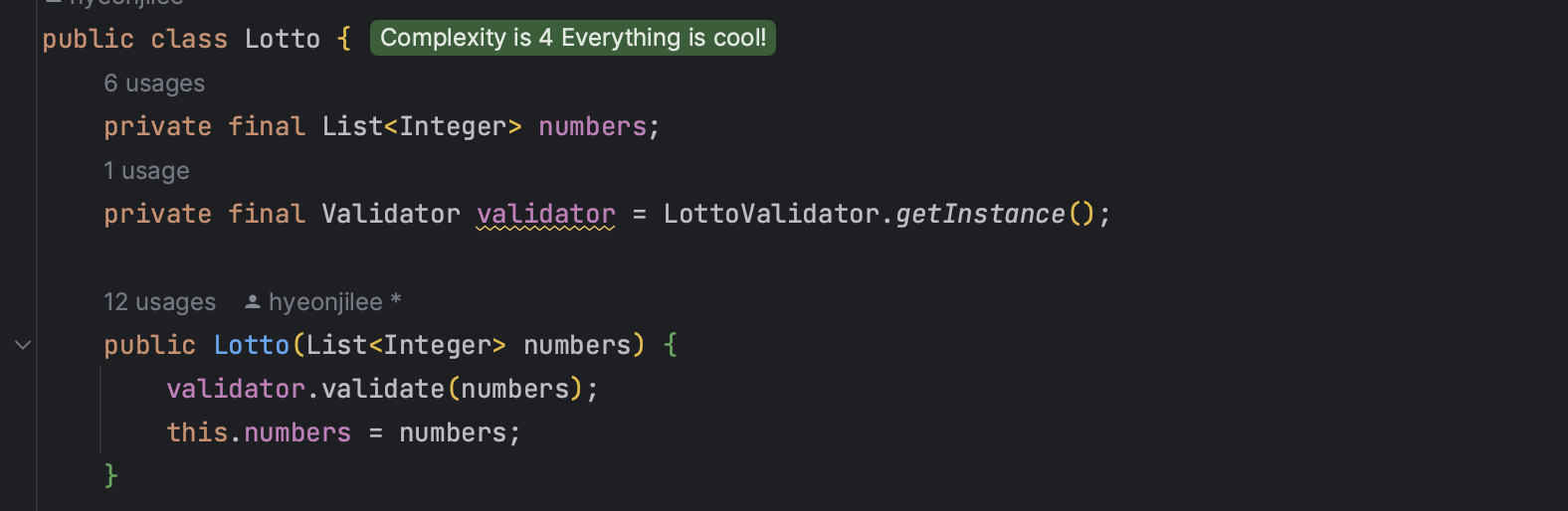
하지만, 이 방식의 주의점이 걸려서 결국 선택하지는 않았다.- 보편적으로 사용하지 않는 방식
- 결합도: 객체와 해당하는 validator 클래스 간의 결합도가 매우 높아진다.
- 이외, 유연성과 테스트 용이성 등도
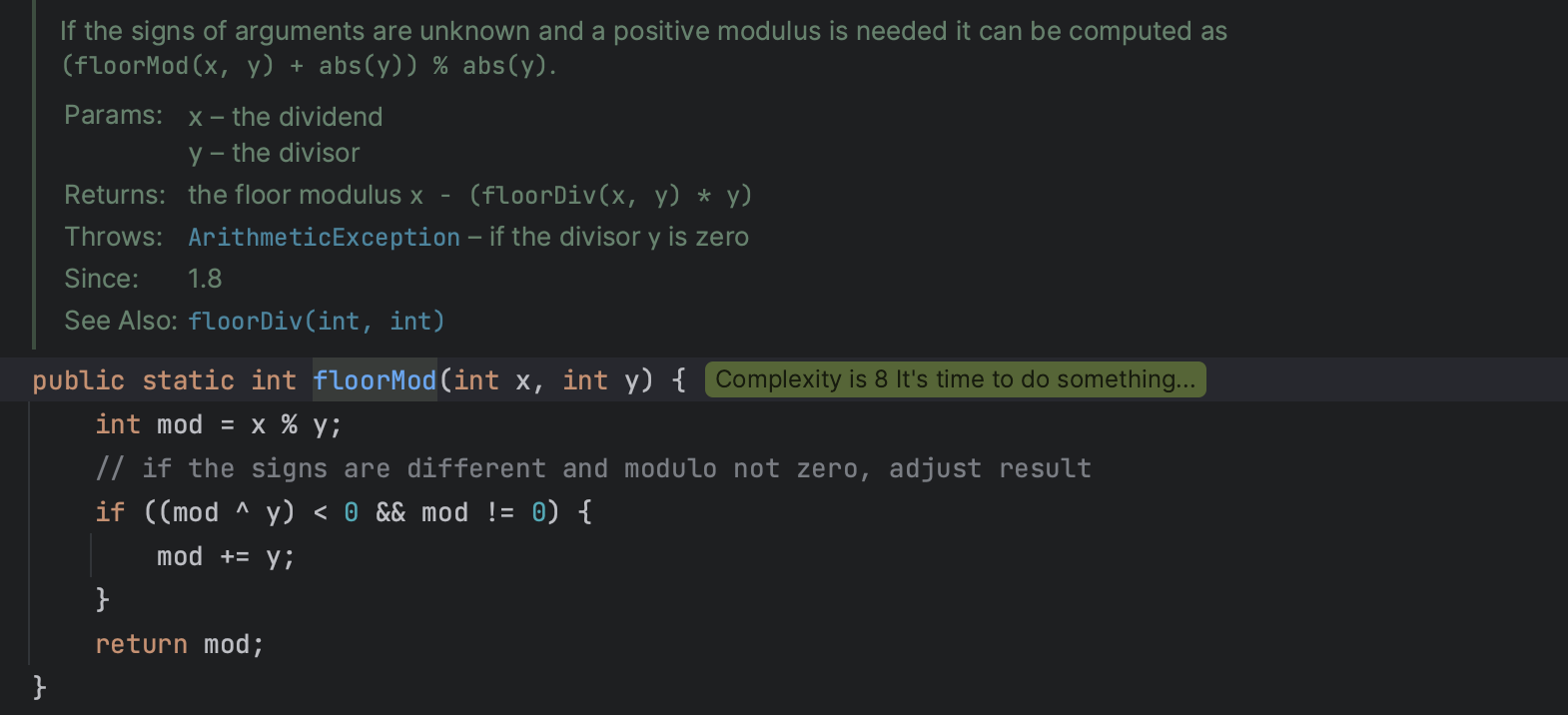
📌 나누기 나머지를 확인하는 Math.floorMod!

이렇게 내장 메소드를 활용해볼 수도 있겠다!
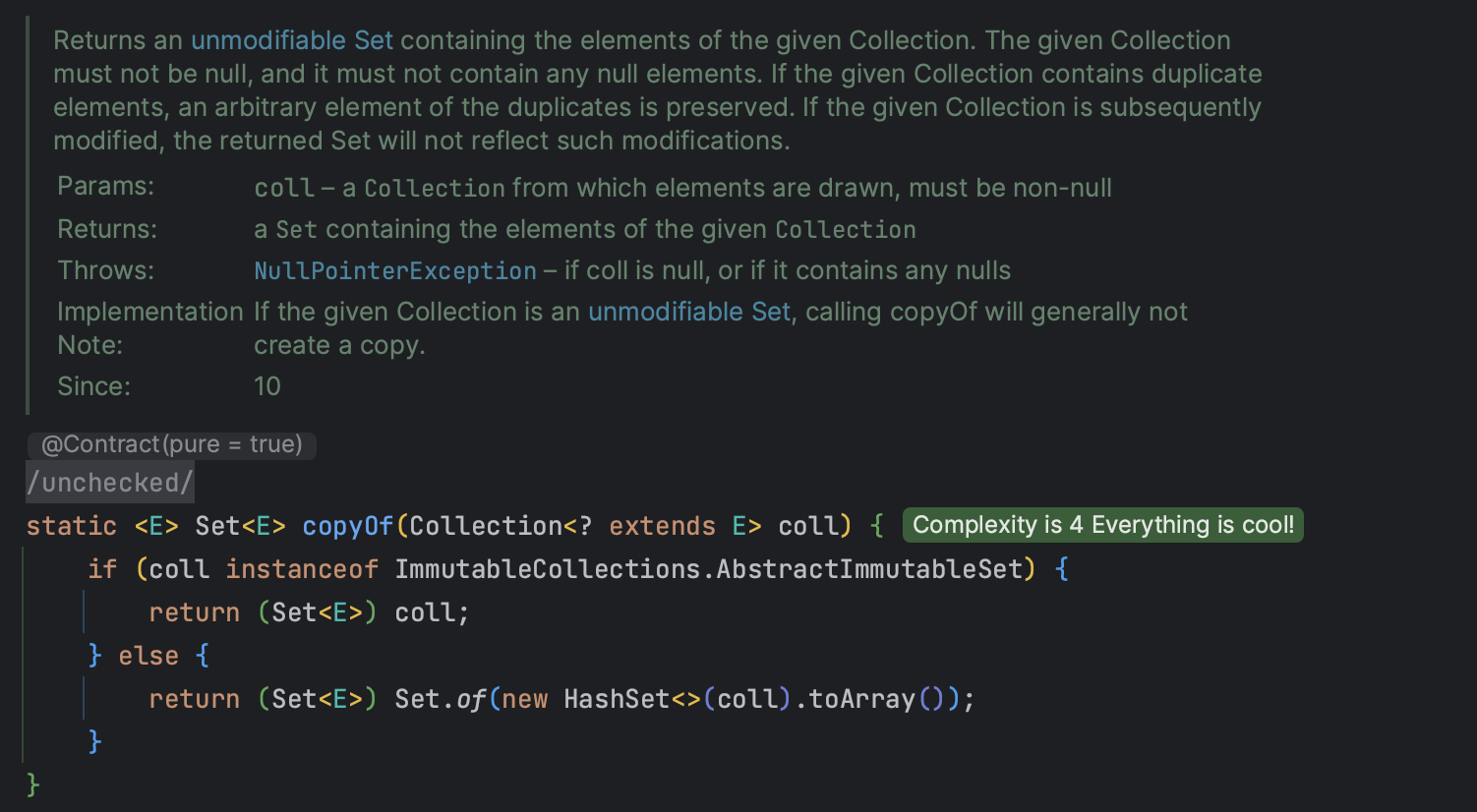
📌 Set.copyOf으로 중복 확인 간략화!

알아서 입력된 컬렉션을 복사해서 new HashSet을 만들어준다!
📌 상수들의 모아놓는 방식의 기준2: enum vs 정적 final 모음
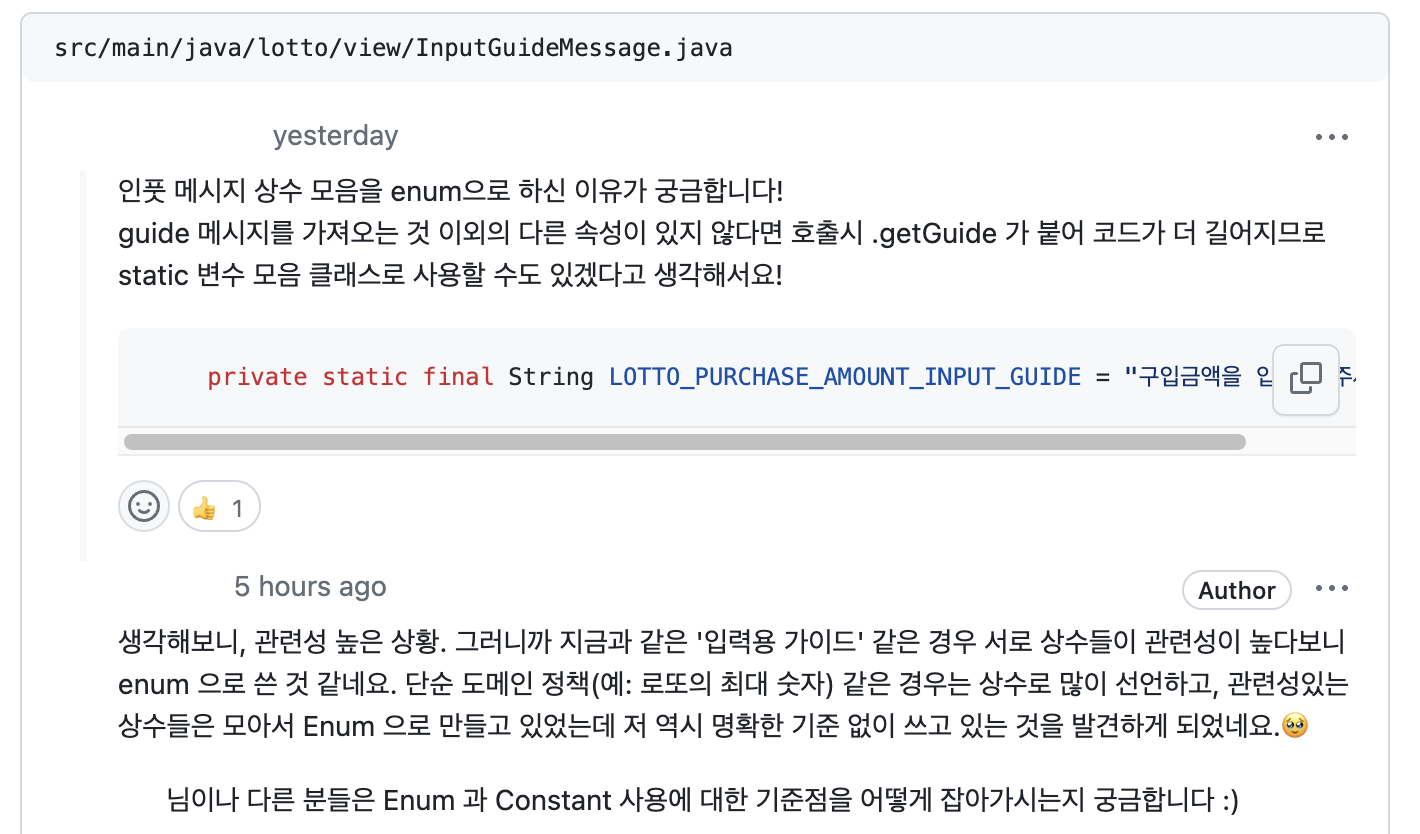
저번주에도 고민을 하고 나름 기준이 생겼다고 생각했지만, 리뷰를 하면서 기준의 모호함이 있다는 생각이 들어 다시 고민이 들었다!
피드백 메일에서의 enum 언급
이번 3주차 공통 피드백에 이런 내용이 있었다.

연관성이 있는 상수는 static final 대신 enum을 활용한다._3주차 공통 피드백 중
여기서 연관성이 있다.의 각자의 해석에 따라 enum을 활용할지 아님 그냥 static final을 활용할지가 달라질 것 같다.
나의 사용 기준
나의 enum vs static final 방식 사용 기준은
- 가독성 2. 연관성
이라고 할 수 있는데 아래의 예시로 정리해보려고한다.
우선, 해당 상수 클래스는 static final 방식을 선택했다.
왜 enum으로 하지 않았는가? 한다면
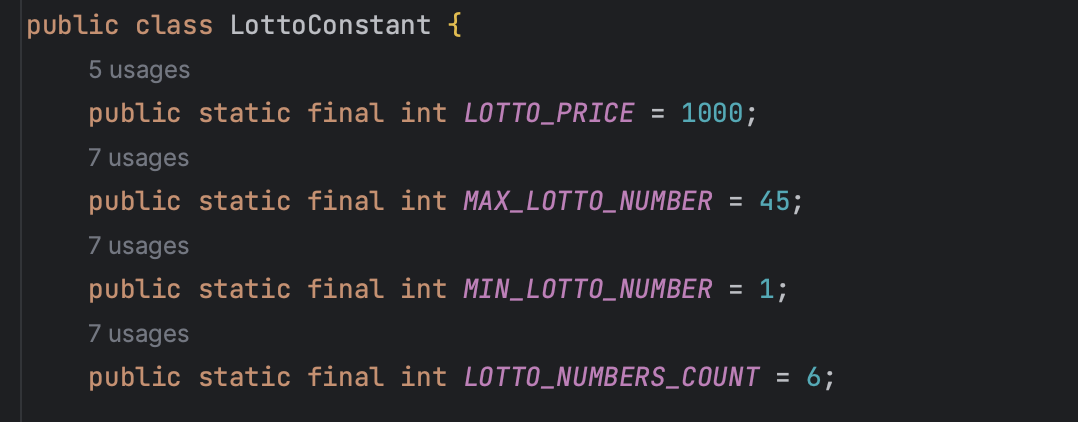
우선, 1. 연관성을 따져보았다.
- 나는 로또 가격, 로또 숫자 범위, 로또 갯수 기준이 연관성이 있는 상수들이 아니라고 생각한다.
- 다 로또와 관련된 상수이니까 연관성이 있는 거 아니야? 하고 물을 수도 있는데, 연관성이 있으나 약한 상수들이라고 할 수 있다.
- 그 이유는, 만약 해당 상수들이 1대1 매칭되는 클래스가 있었다면 거기에 넣어줬을텐데 딱 매칭되는 클래스가 없어서 모아둔 상수이다.
OK, 일단 연관성이 없진 않고 약하다.
이 때, 하나 더 고려할 수 있는 것은 2. 가독성이다.
- enum 방식으로 가져오게 된다면 .getValue 등의 호출이 붙게된다.
- 그렇다면 코드는 길어지고 가독성은 떨어지게 된다.
이렇게 연관성과 가독성을 실제 코드에 적용해 따져보았을 때,
나는 상수 간의 낮은 연관성, static 방식의 가독성을 생각해 enum 방식이 아닌 static final 방식을 채택하게 되었다!
// final static 방식
private static int calculateCount(int purchase) {
return purchase / LOTTO_PRICE;
}
// enum 방식
private static int calculateCount(int purchase) {
return purchase / LOTTO_PRICE.getValue();
}
-----------------------------------------------------------------------
// final static 방식
private List<Integer> generateSortedLottoNumbers() {
List<Integer> rawLottoNumbers = numberGenerator.generate(MIN_LOTTO_NUMBER, MAX_LOTTO_NUMBER, LOTTO_NUMBERS_COUNT);
}
// enum 방식
private List<Integer> generateSortedLottoNumbers() {
List<Integer> rawLottoNumbers = numberGenerator.generate(MIN_LOTTO_NUMBER.getValue(), MAX_LOTTO_NUMBER.getValue(), LOTTO_NUMBERS_COUNT.getValue());
}
-----------------------------------------------------------------------
// final static 방식
private void validateSize(List<Integer> winningNumbers) {
if (!isValideSize(winningNumbers)) {
throw new IllegalArgumentException("당첨 번호는 " + LOTTO_NUMBERS_COUNT + "개가 입력되어야 합니다.");
}
}
// enum 방식
private void validateSize(List<Integer> winningNumbers) {
if (!isValideSize(winningNumbers)) {
throw new IllegalArgumentException("당첨 번호는 " + LOTTO_NUMBERS_COUNT.getValue() + "개가 입력되어야 합니다.");
}
}그럼 enum은 언제?
관련성 높은 상황. 그러니까 '입력 메시지' 같은 경우는 해당될 수 있을 것 같다. (해로님 코드 참고)

📌 상수를 특정 클래스에 두는 경우
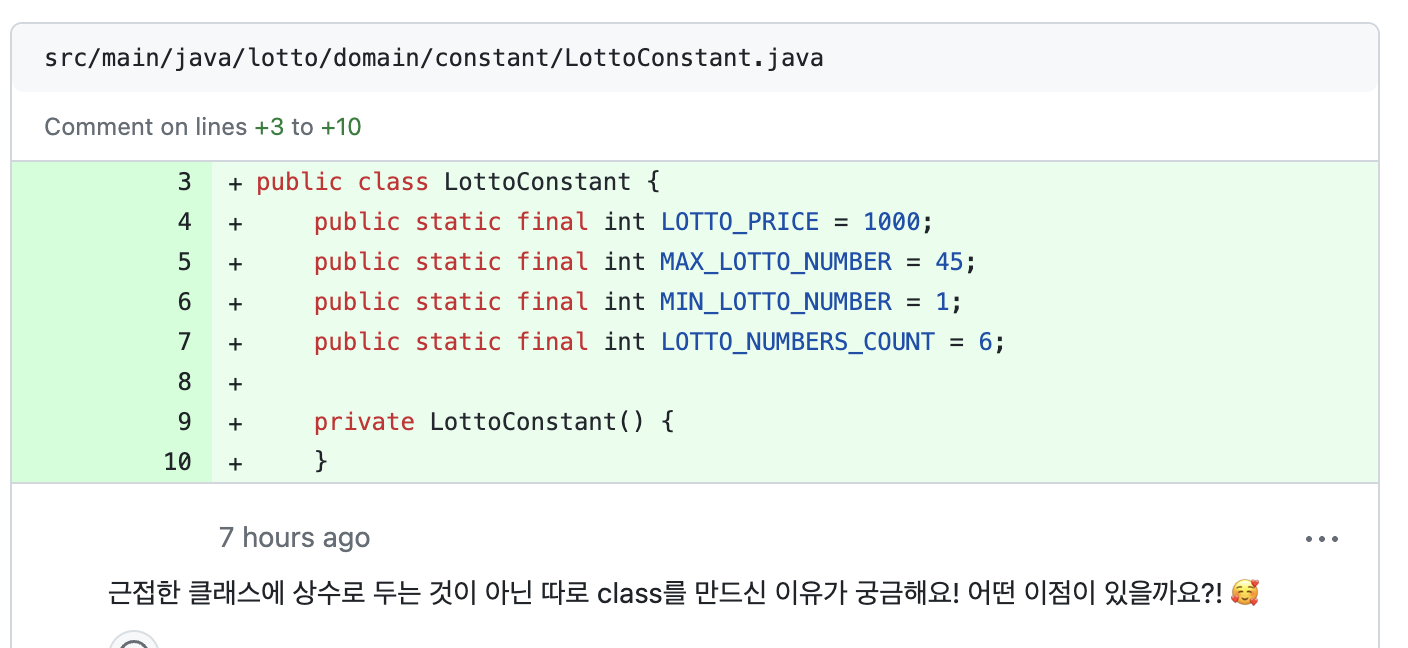
생각해보면 LOTTO_PRICE의 경우 LottoCount 클래스와 PurchaseValidator에서 사용된다. 그리고 해당 validator가 LottoCount 클래스의 상수를 호출해 쓰는 것이 이상한 일이 아니기에 이 상수는 LottoCount에 두는 것도 자연스러웠을 것 같다는 생각을 하게되었다!

나머지 상수들은 오-만곳에서 다 쓰이기 때문에 공통 상수 클래스에 남기는 것이 맞다고 생각한다!
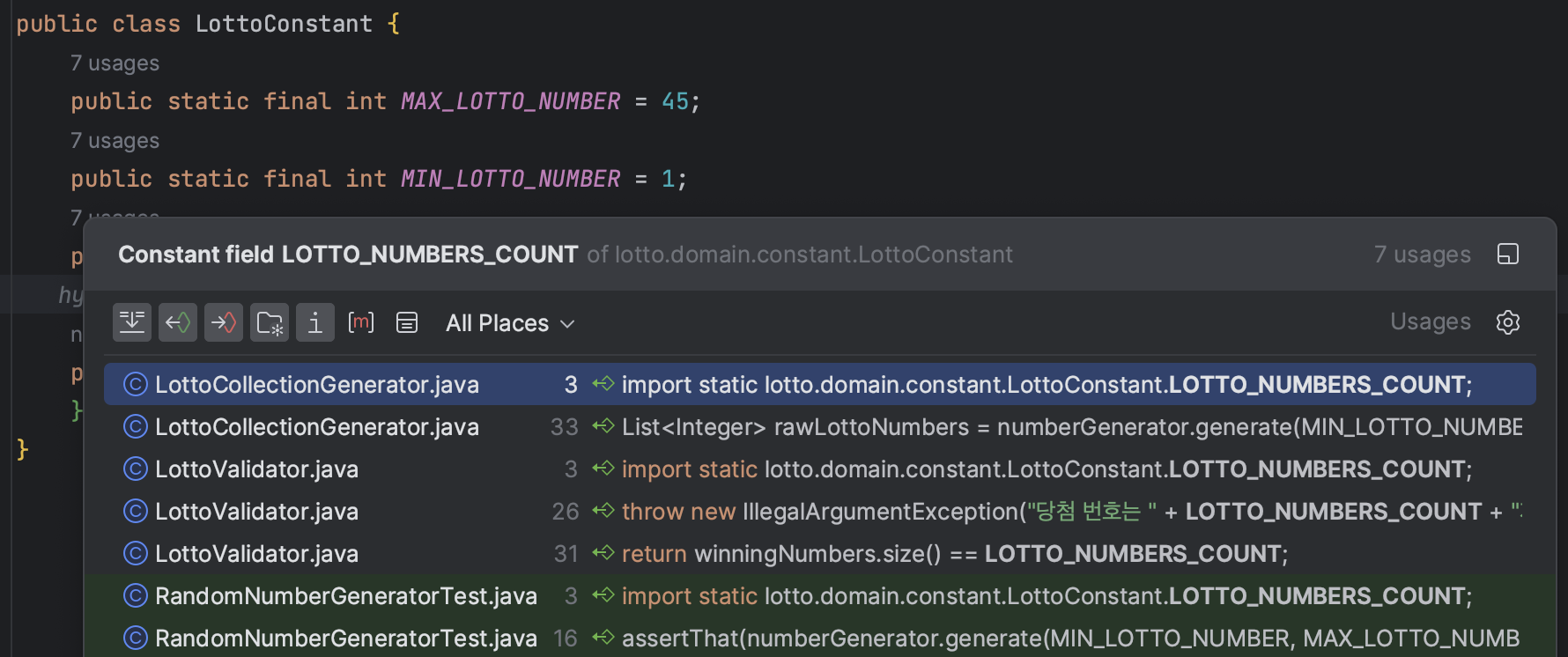
📌 검증 필드를 메시지에 표출하기!
다른 분들의 코드를 보다보니 확장성을 고려해
각각 같은 검증 메소드에 보내면서 상황에 따라 다르게 출력하게 개선하고 싶었다.
구입 금액에 공백은 입력할 수 없습니다.
당첨 번호에 공백은 입력할 수 없습니다.
같은 검증 메소드를 이용하면서 각각 이렇게 다르게 출력되게 하기위해
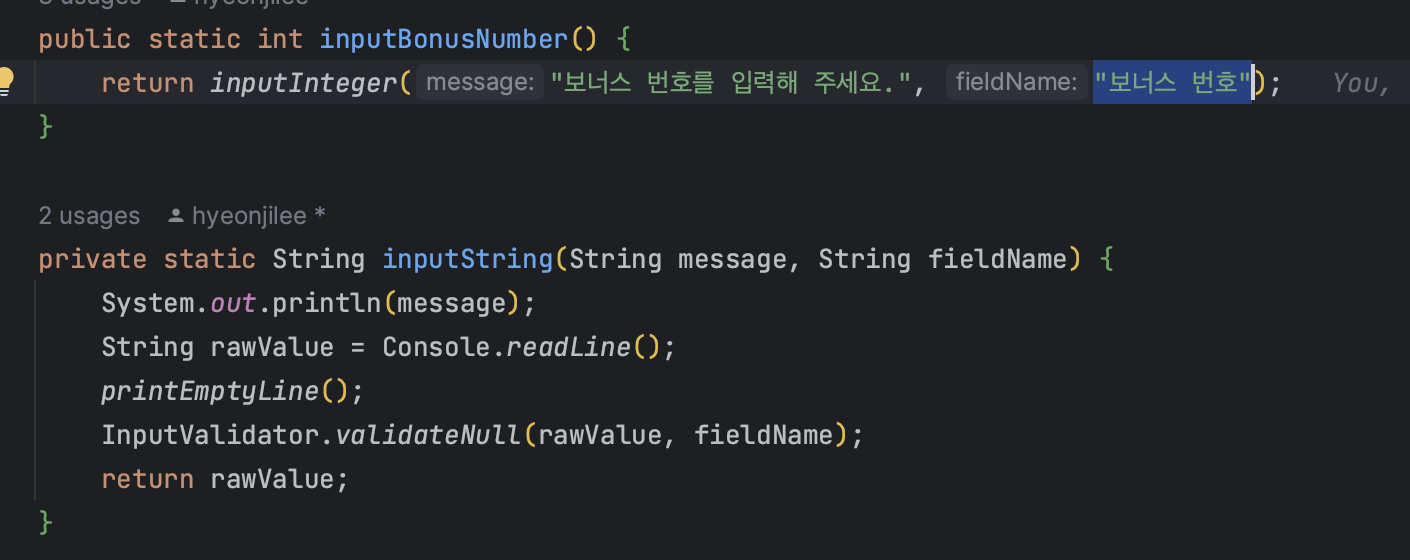

이렇게 리팩토링해 보았다!
돈이나 정밀한 값을 다루는 BigDecimal 타입!
활용?
돈, 소수점을 다룰 때
장점?
- 숫자를 정밀하게 저장하고 표현할 수 있는 유일한 방법
- 소수점을 저장할 수 있는 가장 크기가 큰 타입인 double은 소수점의 정밀도에 있어 한계가 있어 값이 유실될 수 있기때문
- 타입만으로 금액, 소수 등 정밀성을 요하는 작업임을 유추
- 금액과 관련한 도메인들 사이에서 협력하면서 불필요한 타입캐스팅을 유발하지 않기위해(?)
단점?
- 느린 속도와 2. 기본 타입보다 불편한 사용법
나누고 소수점 처리하는 새로운 방식!
- divide
-RoundingMode.HALF_UP (내장)

3자리 콤마 format 적용
Decimal Format에서 #대신 0을 쓰면 수가 없을때 0을 채워줌!
예) #,##0.0%


📌 네이밍의 의인화를 통한 이해 UP!
클래스든 메소드 네이밍이 항상 어려웠는데 아래와 같은 네이밍 의인화가 이해도를 높여줄 수 있을 것 같다! (해로님 코드 발췌)
📌 스트림 활용
Collectors.joining
: 문자열 연결 기능

속에서 compare, toString
배울 점이 많다! (수찬님 코드 발췌)
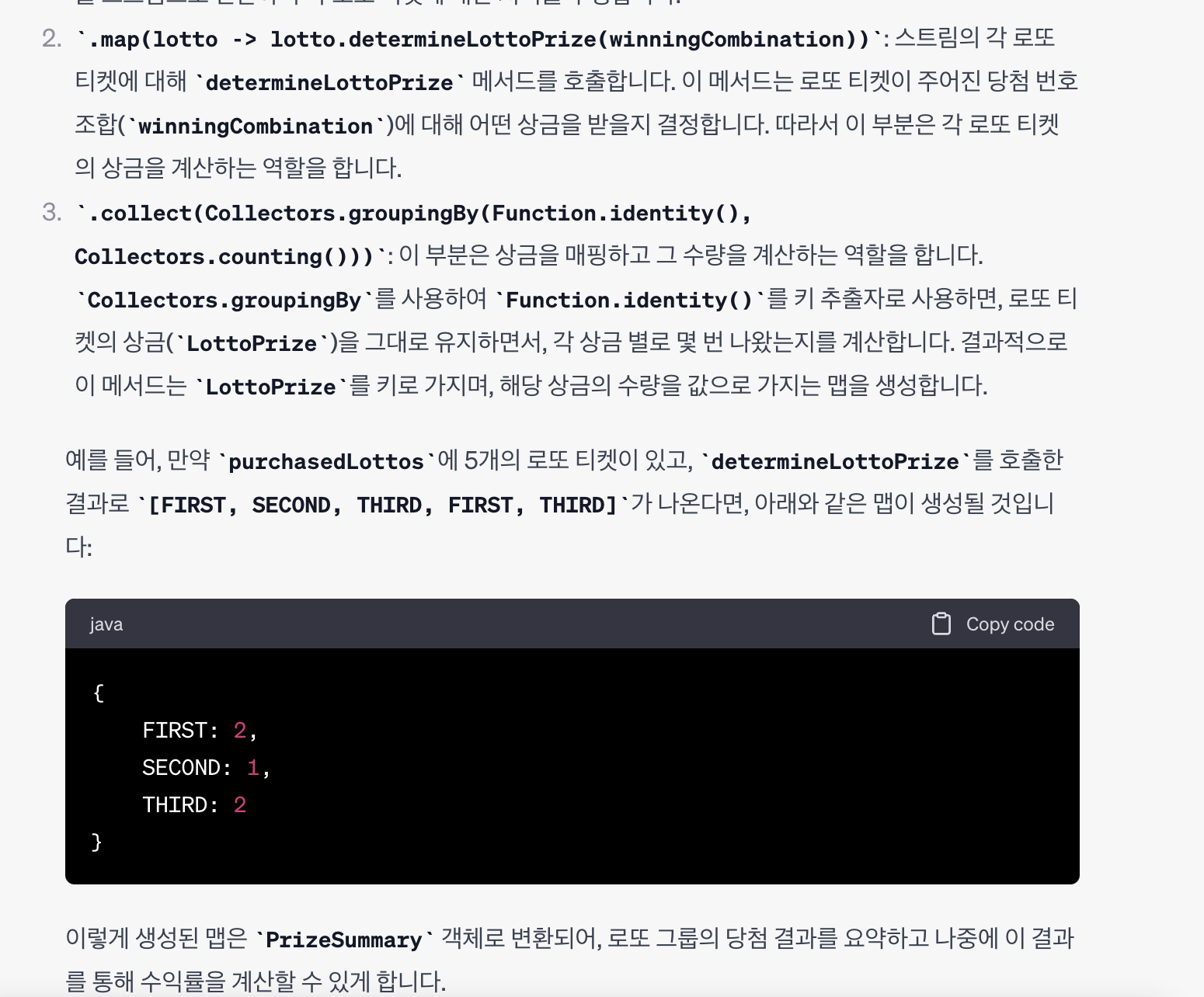
Collectors.groupingBy
상당히 재밌는 방식이네! 탐구 필요!
Collectors.groupingBy(Function.identity(), Collectors.counting())
📌 기본 assertJ 적극 활용!
assertThatIllegalArgumentException

assertThatCode.doesNotThrowAnyException()

이전에 jupiter의 assertDoesNotThrow를 쓰곤했는데 기본 AssertJ의 메소드들을 적극 활용해보려고한다!
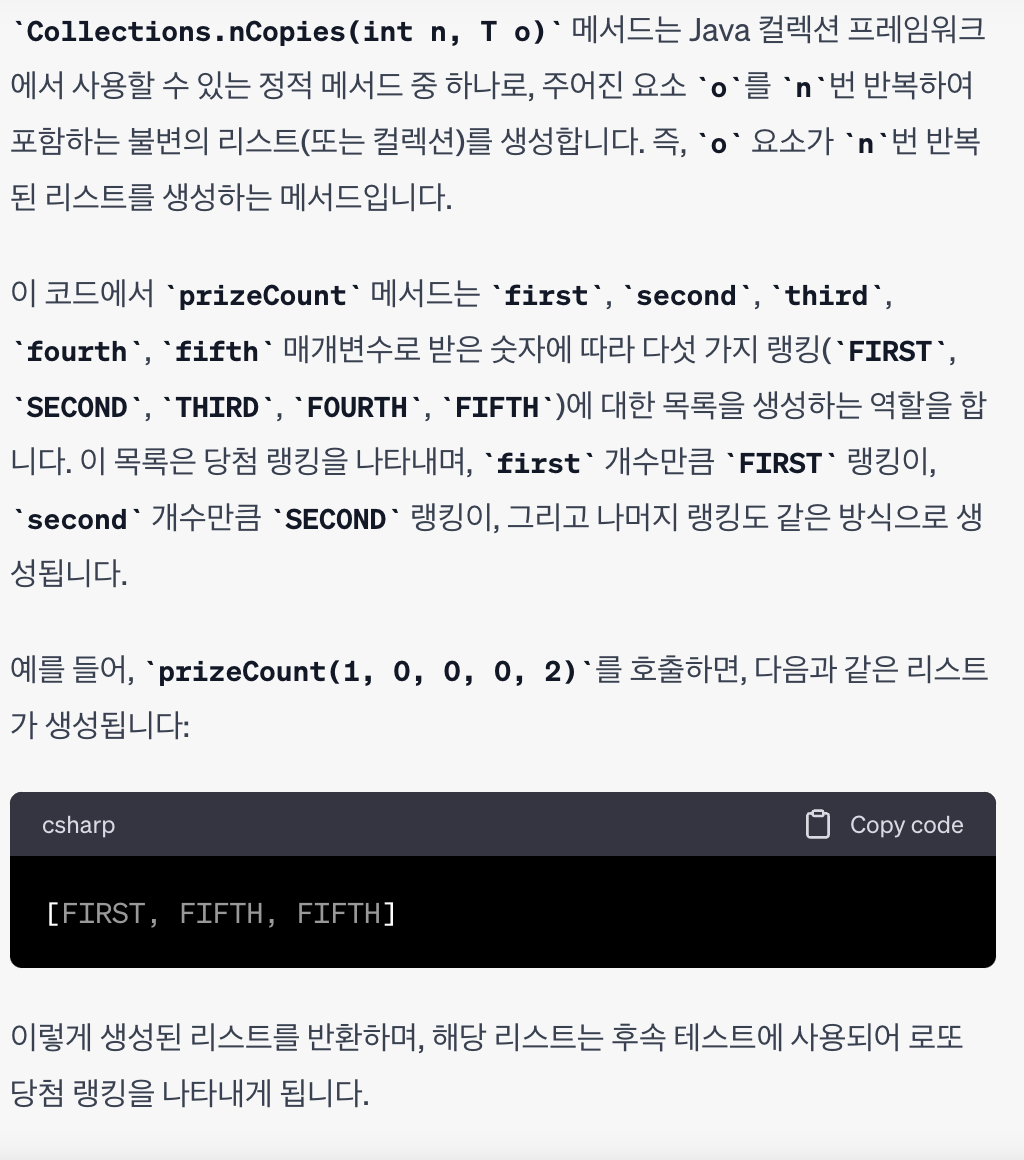
📌 리스트 반복 생성기Collections.nCopies
Collections.nCopies(int 횟수, 반복 생성할 리스트)
로 불변 컬렉션을 반복 생성할 수가 있구나!
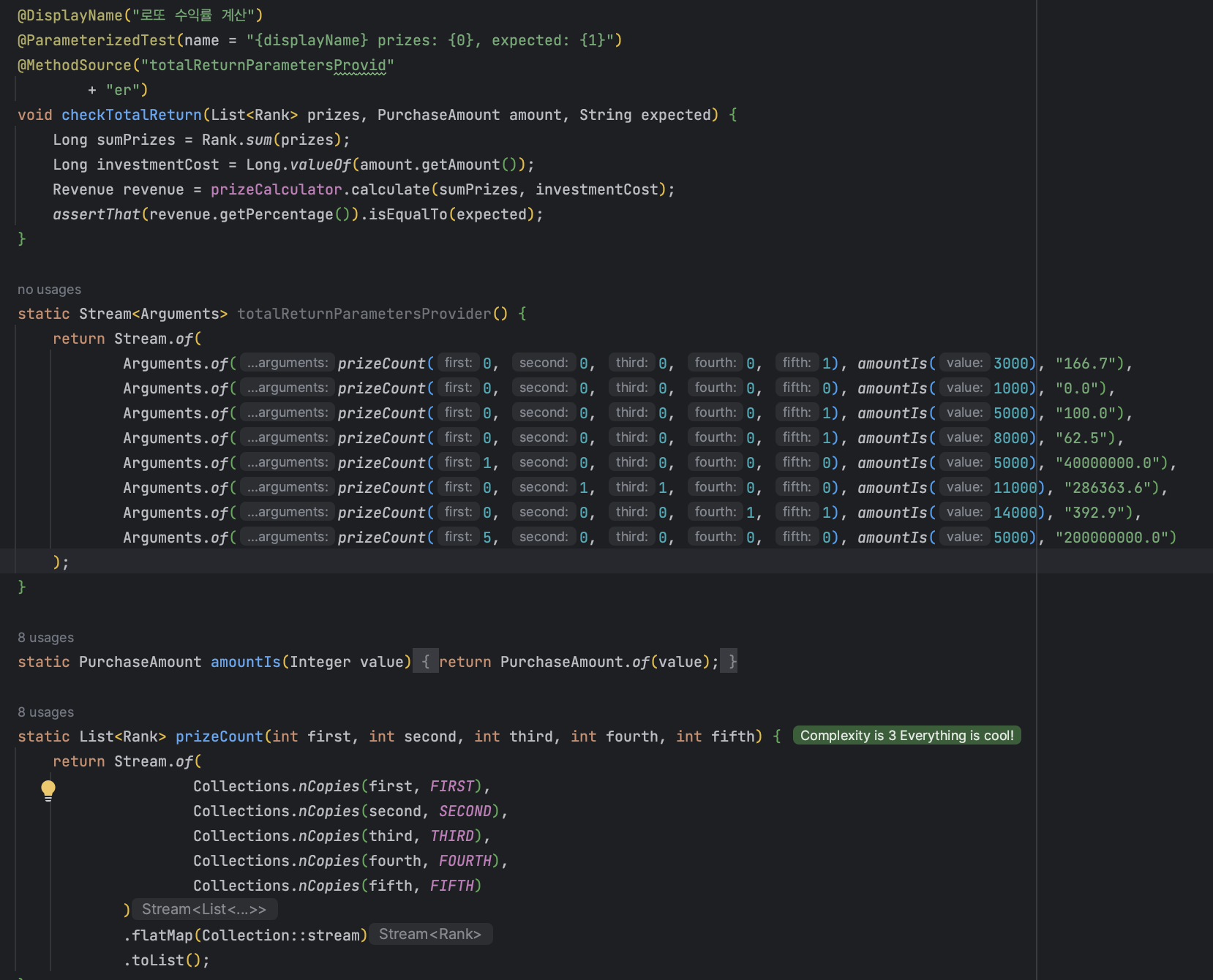
(동근님 코드 발췌)
📌 forEach 메소드와 람다의 메소드 레퍼런스

반복문에 forEach 메소드를 적용해보면서
- for 반복문을 쓰는 기본 방식과
- 람다, 메서드 레퍼런스(::)를 쓰는 방식의
성능 차이가 궁금했는데 찾아보니 람다 표현식을 사용하는 경우,
- 내부적으로는 익명 클래스가 생성되어야 하기 때문에 일부 오버헤드가 발생할 수 있지만,
- 최근 Java 버전에서는 이러한 오버헤드도 최소화되어 성능적으로 큰 차이를 보이지 않는 경우가 많다고 한다.
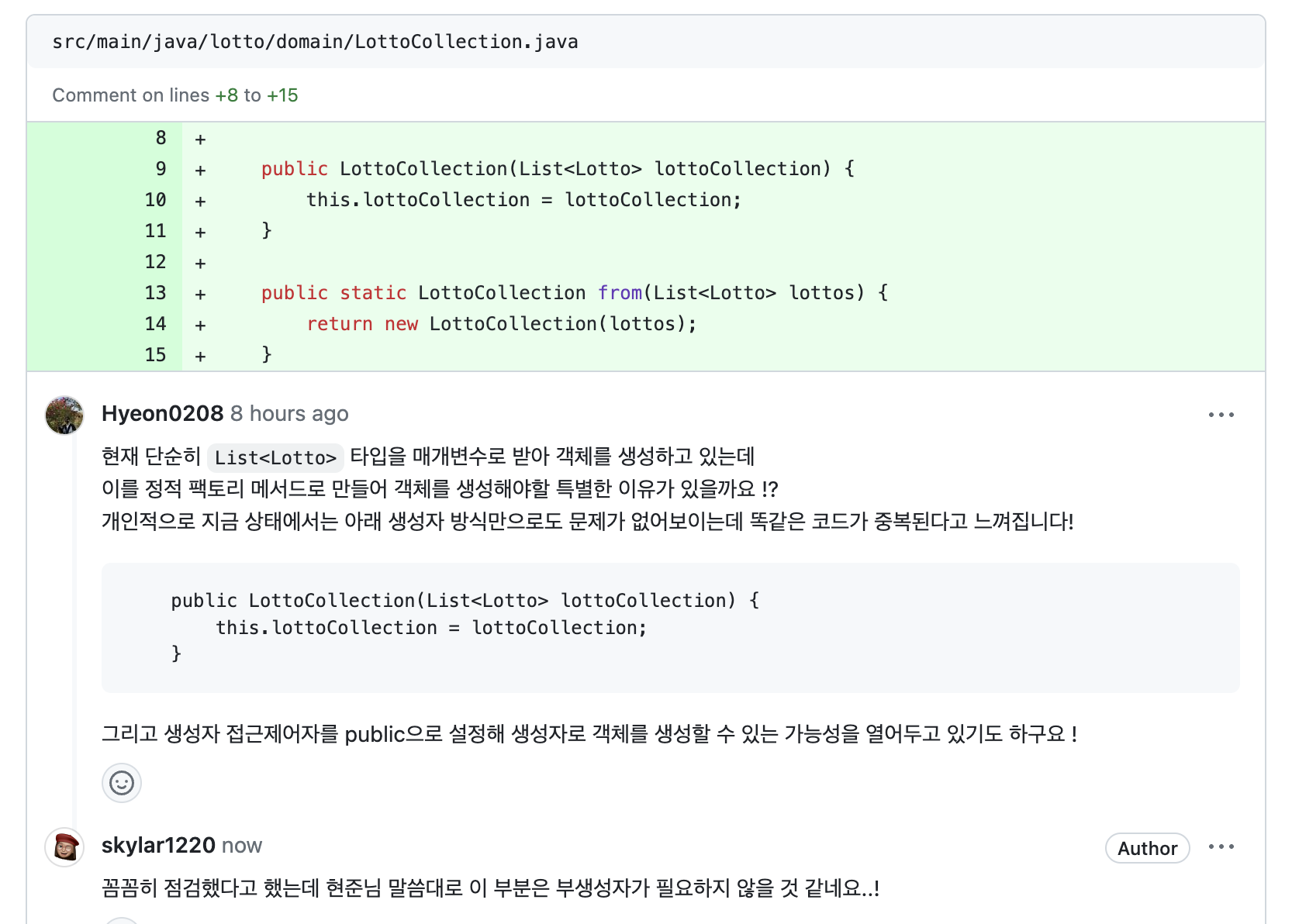
📌 부생성자 불필요 경우 잘 체크하기!
validate, convert 과정 없이 바로 객체 생성하는 경우 처럼 부생성자가 불필요한 부분 다시 한번 체크하기!
- 부생성자 존재시 생성자 private 선언도!!
📌 static 임포트 생략 지양?
언젠가부터 가독성이 좋다는 이유로 근거 없이 static 임포트를 하며 클래스명을 생략해왔었다.
물론 아래의 가이드가 상세하진 않지만 특별한 이유가 있는 게 아니라면 명시적으로 표기해주는 것이 좋을 것 같다는 생각을 새로 하게되었다.
📌 범용성 생각, 사용하는데에서 상수 넣어주기
원래 위와같이 랜덤 번호 생성기 자체에 숫자 범위와 갯수를 넣어놨었는데 다른 분들의 코드를 보면서 이 범위의 선언이 최종적으로 사용하는 곳에서 이루어지는 것이 더 명시적이고 좋겠다는 생각을 해서 수정해보았다!

📌 기능 구현 목록에 '객체 생성' 명시?
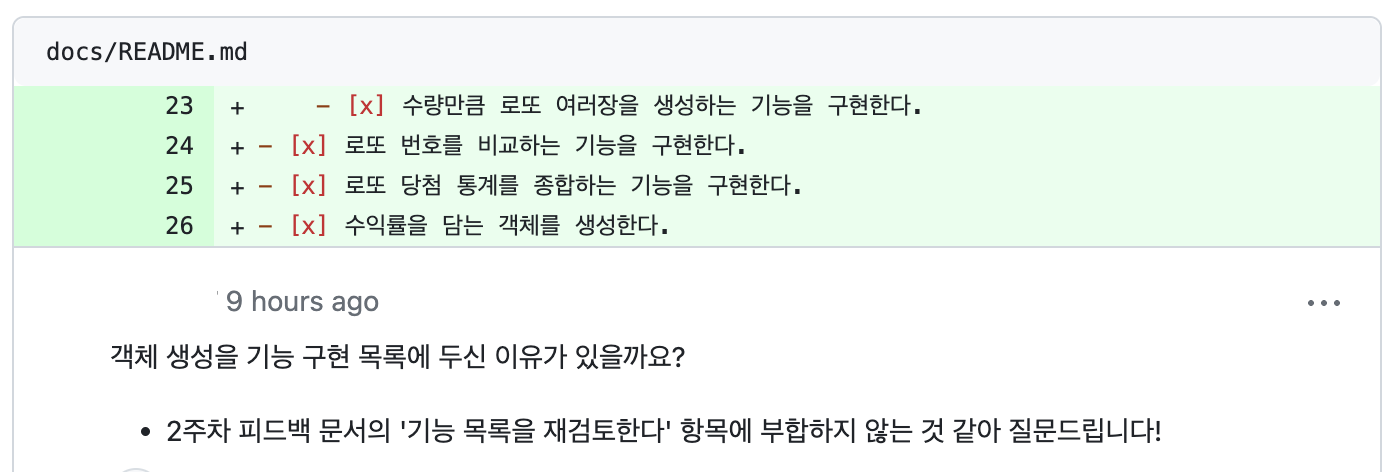
2주차 피드백 문서를 다시 읽어보았다.
기능 목록을 재검토한다
: 기능 목록을 클래스 설계와 구현, 함수(메서드) 설계와 구현과 같이 너무 상세하게 작성하지 않는다.
클래스 이름, 함수(메서드) 시그니처와 반환값은 언제든지 변경될 수 있기 때문이다. 너무 세세한 부분까지 정리하기보다 구현해야 할 기능 목록을 정리하는 데 집중한다.
'~하는 객체를 생성한다'는 변경될 수 있는 사항이기에 이것을 명시하기보다는 그 객체를 만들게된 기능 구현을 명시하는 것이 낫겠다는 생각을 하게되었다!
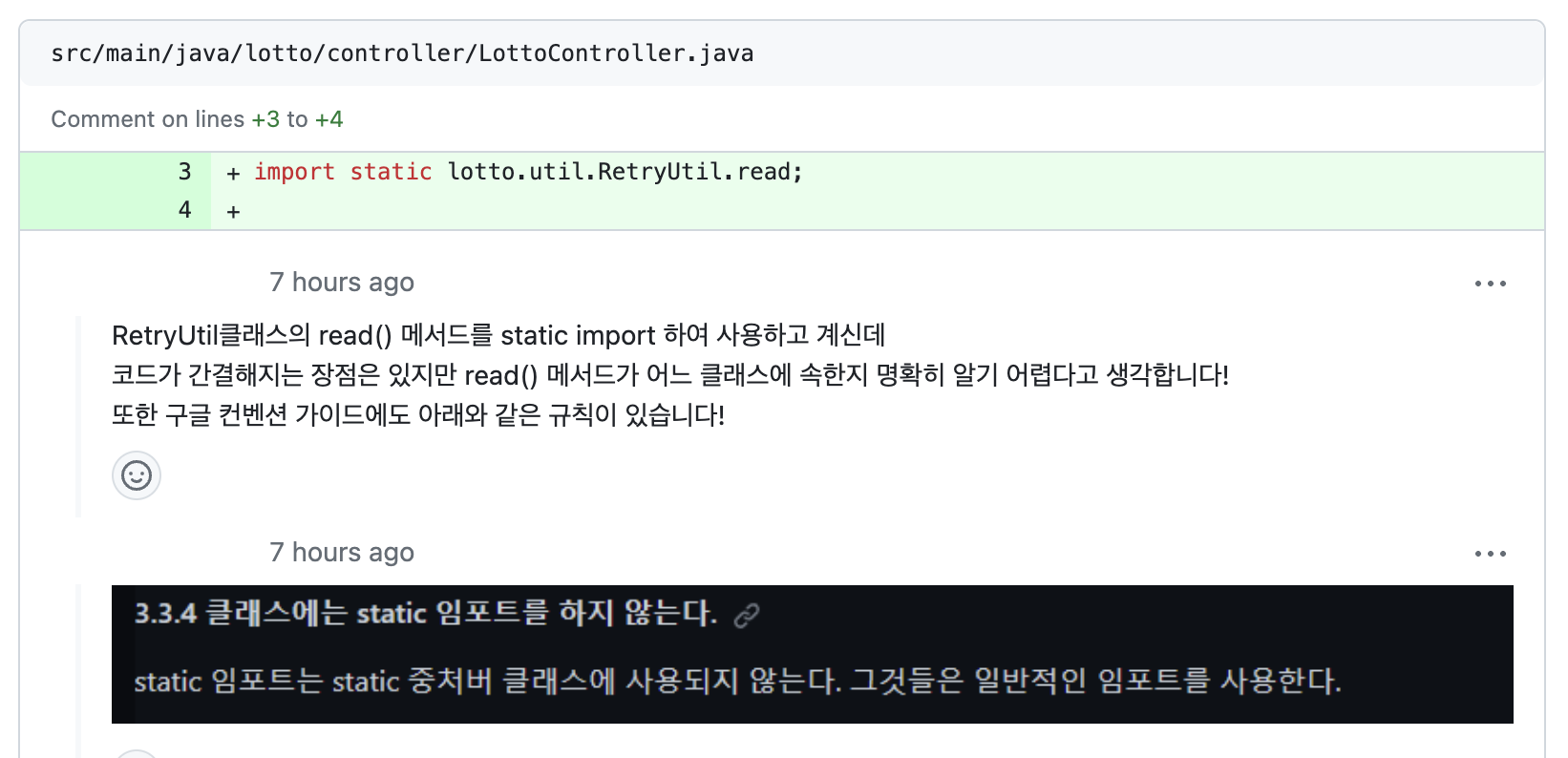
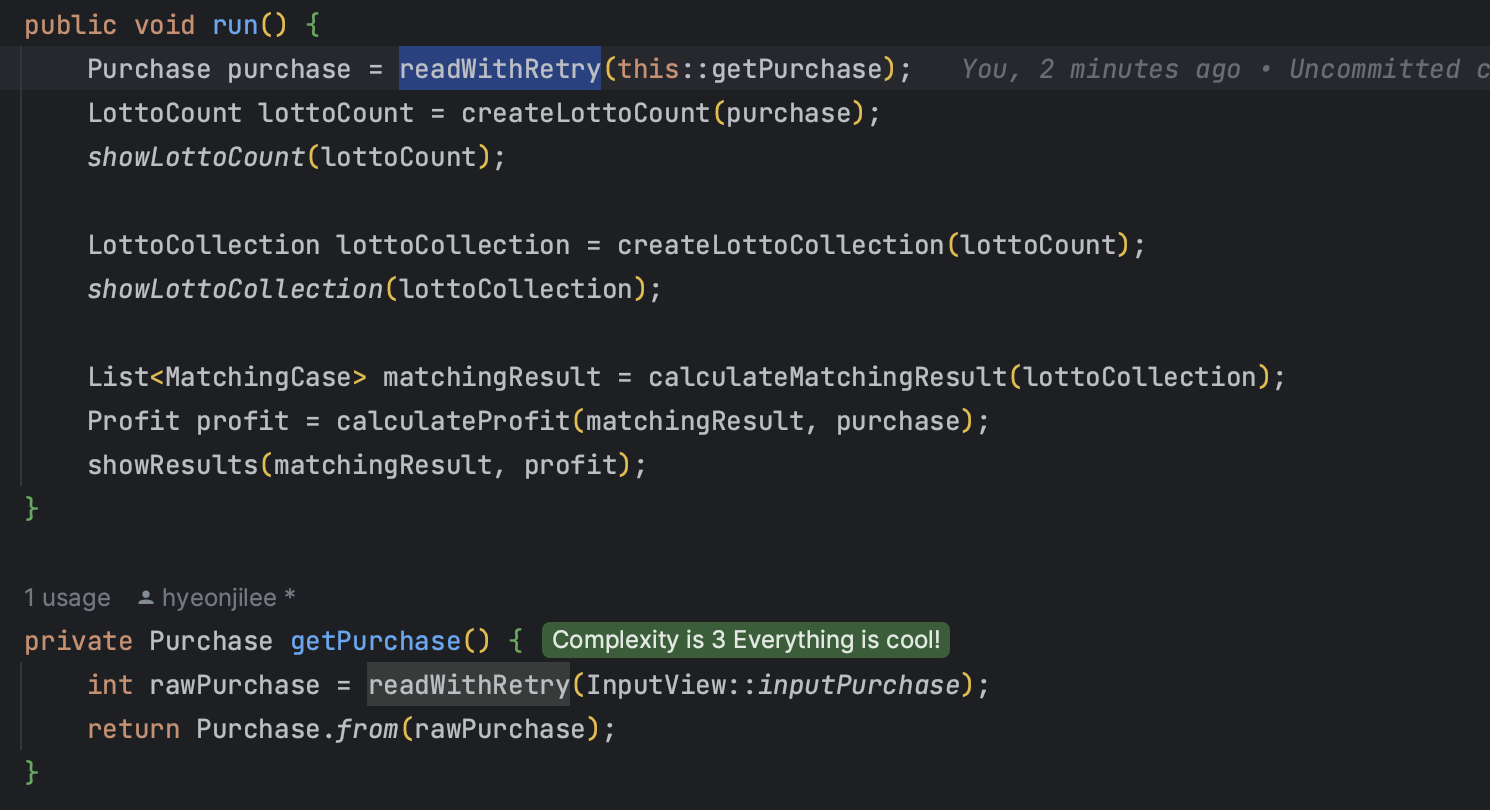
📌 RetryUtil? 함수명 read?

피드백을 반영하여 아래와 같이 수정해보았다.
- readPurchase -> getPurchase
- read -> readWithRetry
- read라는 함수가 컨트롤러 안에서만 쓰이고 있어 컨트롤러로 옯겨오고 RetryUtil 클래스 삭제
- 참고할만한 포스팅: 좋은 코드를 위한 자바 메서드 네이밍
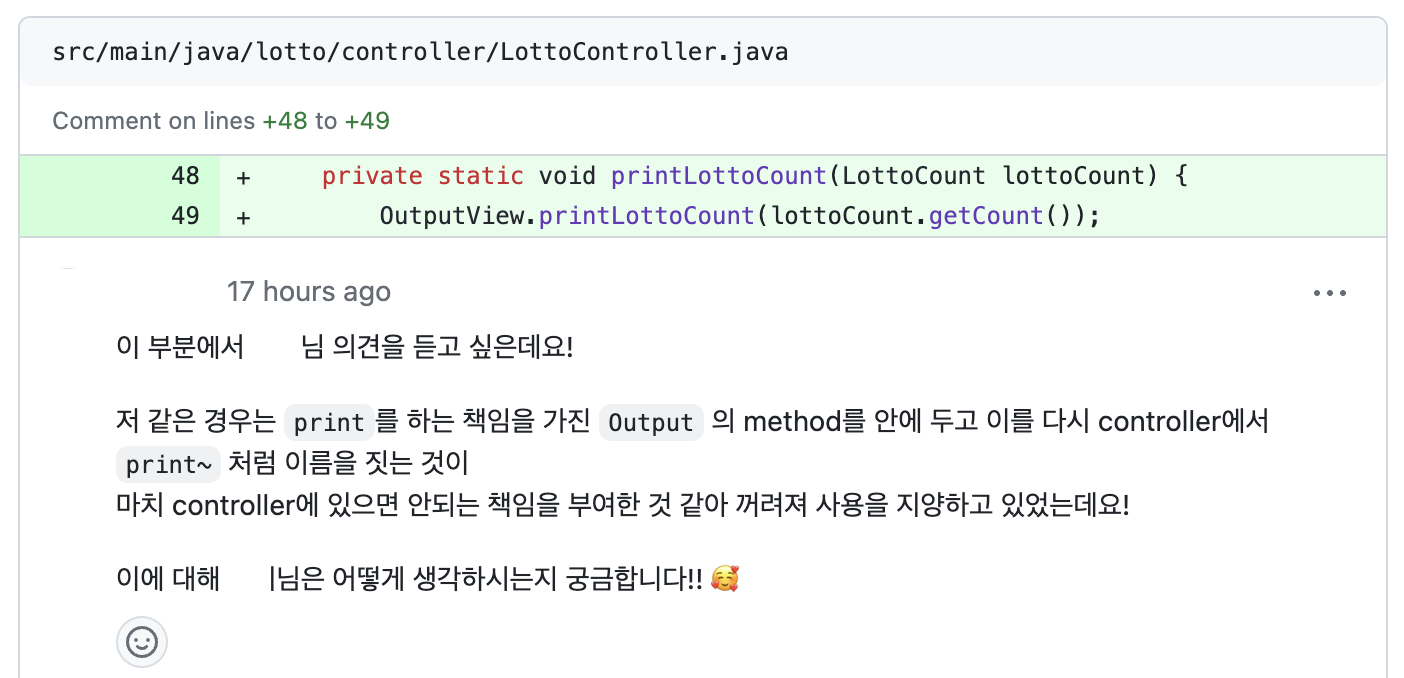
📌 컨트롤러 속 메소드명의 정리
위에서와 같이 뭔가를 받아오고, 생성하고, 출력으로 연결하는 컨트롤러의 메소드명이 일관되지 않았던 것 같아 나만의 컨트롤러 네이밍 컨벤션(?)을 정리해보려고 한다!
-
input에서 입력을 받아서 객체로 받아오는 메소드 : get

-
컨트롤러를 통해 다른 메소드에서 받은 값으로 객체를 만들어오는 메소드 : create, generate

-
출력 연결 메소드 : show (print는 outputView에서 쓰므로)

-
리스트를 일급컬렉션화 한 클래스: Group, Tickets(상황에 따라)
- Collection을 사용하면 Collection 인터페이스 이름와 관련된 것으로 오해가 생길 수 있으므로
팁: 용어 애매하면 자바 공식 문서 속 용어 넣기
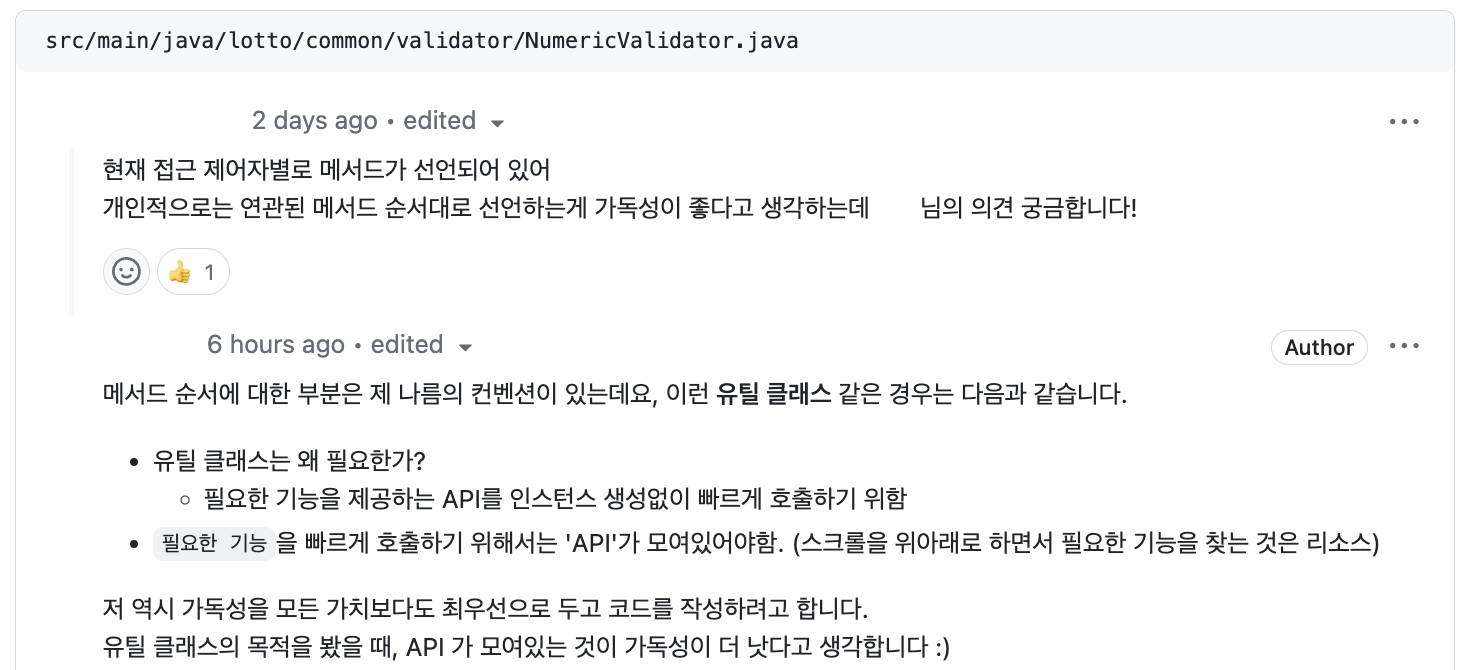
📌 유틸 클래스 메소드 순서의 새로운 시각!
일반적인 도메인 클래스 등에서 메소드 순서는 호출하는 메소드를 근처에 두는 방식을 사용하곤 했다.
그런데 해당 리뷰를 보면서 유틸 등의 클래스에서는 순서가 달리 적용될 수 있겠구나!라는 생각을 하게되었다.
역시 하나의 법칙을 모든 곳에 적용하기보다는,
항상 프로램이 진행되는 '상황'과 외부에서 볼 때의 '시각'을 생각해서 달리 적용해봐야하겠구나!
📌 의존성의 극단적인 줄임을 통해 발견한 문제들!
저번주 객체 간 의존성 문제를 제대로는 처음으로 인식하게 되어 이번주에 극단적으로(?) 의존성을 줄여가며 구현해보았는데 역시나, 리뷰들을 보면서 여러 문제점과 더불어 🚨mvc와 의존성에 대해 내가 잘못 알고 있던🚨 부분을 발견할 수 있었다.
리뷰에서 발췌한 내용에 더해서 정리해보자면,
1. 객체 간의 의존성을 줄이기 위해 컨트롤러에서 객체에 getter로 값을 받아와서 다른 객체에 넣어주는 경우
- 오히려 컨트롤러가 도메인의 값에 접근하면서 컨트롤러의 깊은 도메인 관여가 생기게 된다.
- 컨트롤러가 도메인 로직도 수행하고, 입출력 객체들한테 메시지도 보내고, 책임이 너무 많다.
2. 프로그램상 의도적으로 의존관계가 있을 필요가 있는 객체들도 있다.
- 예를들어 LottoCollectionGenerator와 LottoCount는 협력하는 객체로 정해 의존성 관계가 생길 수 있다.
3. 값을 주고 받는 과정에서 안전성에 대한 문제
- 값을 주고 받는 과정에서 원시값인 경우 안전성이 보장되지 않는다.
- 파라미터 타입이 Int 가 되면, 외부에서는 어떤 int 값이든 집어 넣어 해당 메서드를 호출할 수 있게 된다. 그럼 어떤 값이든 LottoCollectionGenerator는 역시 마음대로 수량을 발행할 수 있게된다.
4. 의존성을 아예 제거하면, 협력하고 있는 객체가 아무것도 없는 것이 아닐까?
정리 1) 필요한 의존성은 필요하다
- 필요한 의존성은 필요하며, 필요한 의존성을 제거하는 것은 절차지향과 다를 바가 없다.
정리 2) 입출력 하기 위한 정보를 수집하는 것. 딱 거기까지가 컨트롤러 역할
게임 결과를 뽑아서 view 에게 결과 객체를 던져주는 것은 컨트롤러가 담당하고 있는 부분이므로, 이 부분은 도메인 로직에 관여하며 컨트롤러의 역할을 넘어선 것.
-> 입출력 하기 위한 정보를 수집하는 것. 딱 거기까지를 컨트롤러 역할로 정의한다.
📌 view에는 값을 풀어서 보내줘야할까?
같은 맥락에서 위와 같은 질문이 들어 내가 갖고 있던 생각을 정리해보았다... 여기서 큰 발견을 하게되는데...
1. 컨트롤러에서 값을 풀어서 view로 보내면
- 장점
1. domain을 view가 의존하지 않음
2. view가 알 필요가 없는 domain의 다른 정보를 알 수 없게함
- 단점
- view로 연결되는 메소드 파라미터에 원시값을 아무값이나 넣어서 보낼 수 있는, 안전성 문제가 불거짐
- 컨트롤러가 도메인의 값에 접근하므로써 컨트롤러의 깊은 도메인 관여가 생기게 됨
2. domain인채로 view로 보내면
- 장점
- 원시값으로 데이터가 오고가지 않으므로 데이터의 안전성이 보장됨
- 단점
1. domain을 view가 의존함
3.Dto가 대안이 될 수 있지 않을까?
dto가 위의 두 방식의 단점들을 해결할 수 있을 것 같다.
1. 의존해도 유지보수 문제가 생기지 않음
- 별도의 비즈니스 로직이 추가되거나 ~~
~~- 호출 방식에 변경이 없을 예정이기 때문에
2. 값이 안전함
- 원시값을 보내는 것이 아니라 dto로 감싸서 보내기때문에 데이터의 안전성이 보장됨
잠깐, 잘못 알고 있던 부분이 있었다..!

🚨 잠시만, view가 도메인에 의존하면 안될까?
🚨mvc와 의존성에 대해 내가 잘못 알고 있던 부분
이 질문에 대답하기 위해서는 mvc 패턴에 대한 다시 이해가 필요했다.
mvc 패턴의 상세 사항에 대해 뭔가 잘못 알고 있다는 느낌이 들어 몇 개의 테코톡 영상을 찾아봤는데



아뿔사... 1, 2번을 완전 잘못 알고 있었다..!
그동안 view가 도메인에 의존하면 안된다. 라고 생각했는데 정확히는
- 도메인이 view에 의존하면 안된다.
- view는 도메인에만 의존해야한다. (컨트롤러에 의존하는 것이 아닌)
- view 내부에 모델에 관련된 코드는 있어도 상관이 없다.
DTO가 만능일까?
그리고 DTO 사용으로 해결하면 되겠다라고 생각했던 부분에 대해서도 추가로 테코톡 영상을 찾아보며 생각의 변화가 있게되었다.


view에서 모델의 데이터를 꺼내서 쓰는 방법도 프로그램 규모를 생각한다면 괜찮은 방법이고,
같은 맥락으로 프로그램 규모를 생각한다면 DTO가 필수가 아닐 수도 있겠다라는 생각을 하게되었다!
📌 초기 클래스명과 마지막 클래스의 역할 비교, 점검해보기
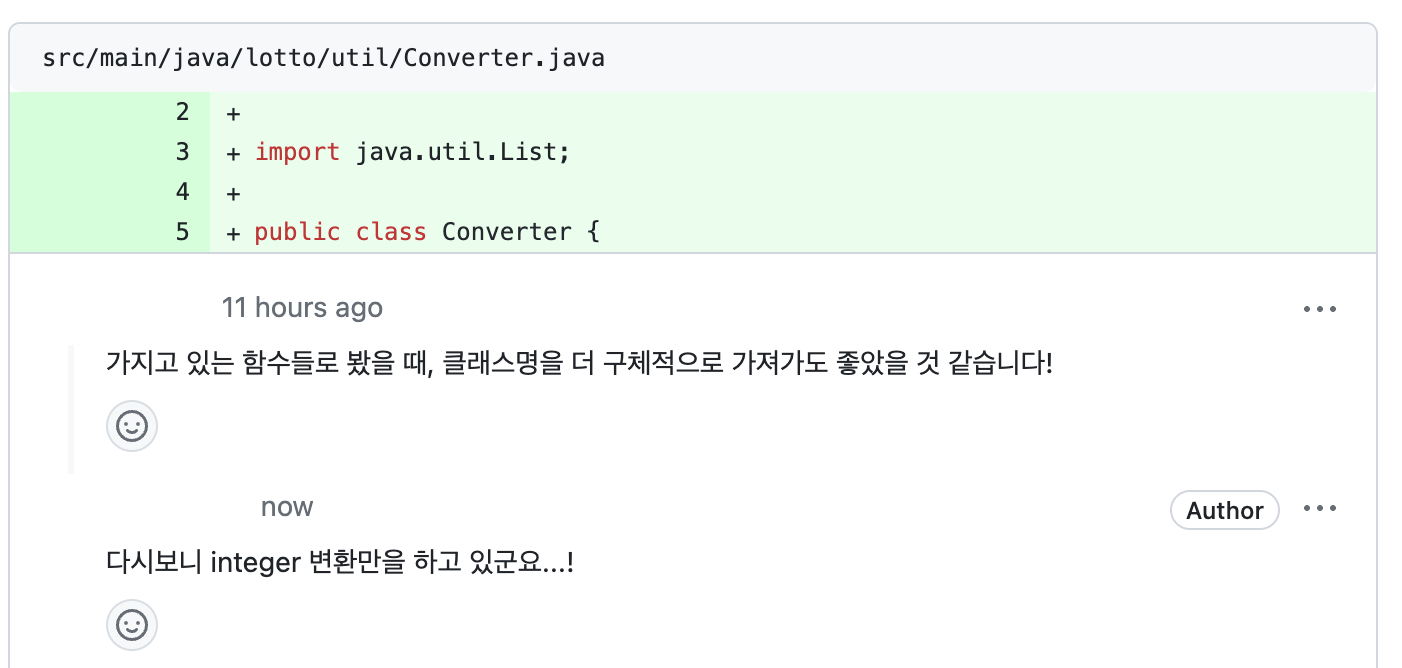
📌 validator가 util에?
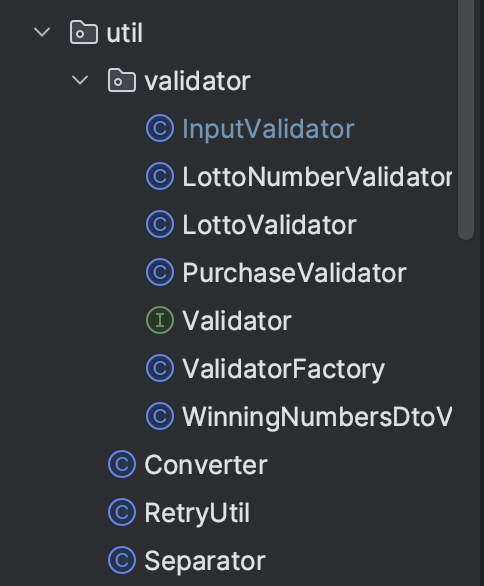
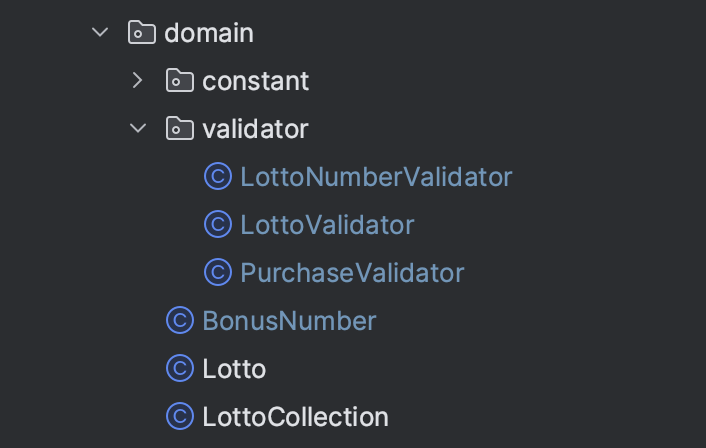
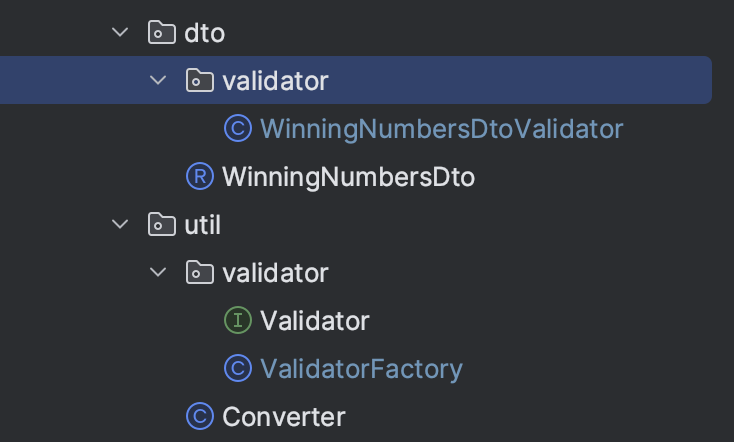
원래 이랬는데 도메인 정책을 검증하는 클래스들이 util 패키지에 있는 것에 대한 리뷰를 받고 생각해보니, 도메인에 대한 검증이면 도메인 패키지에 함께 있는 게 더 적절하다고 생각되어서 아래와 같이 바꿔보았다!
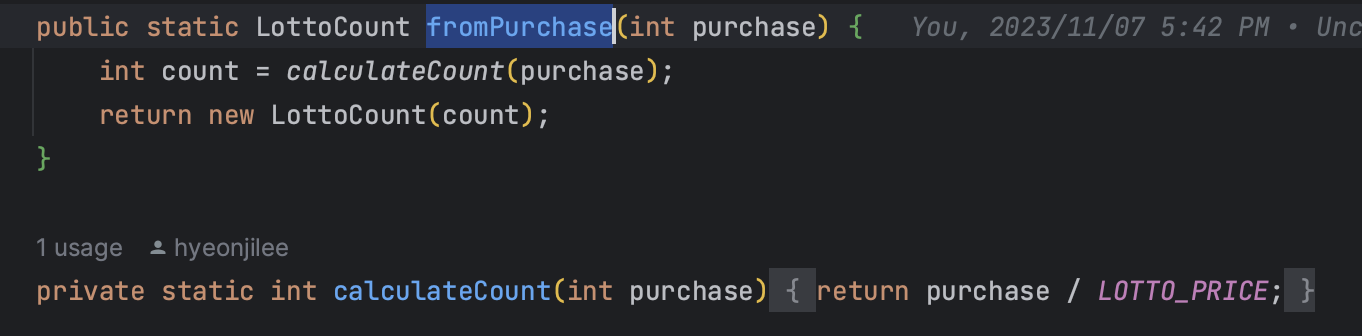
📌 부생성자에 convert 등의 기능이 들어갔다면 네이밍 고민

기존 부생성자 네이밍 컨벤션인 from, of 등을 가져가면서도 어떤형태로부터 convert 되는지 컨텍스트를 추가해주면 되겠다!
📌 seperator 클래스에서 구체적인 구분자 네이밍?
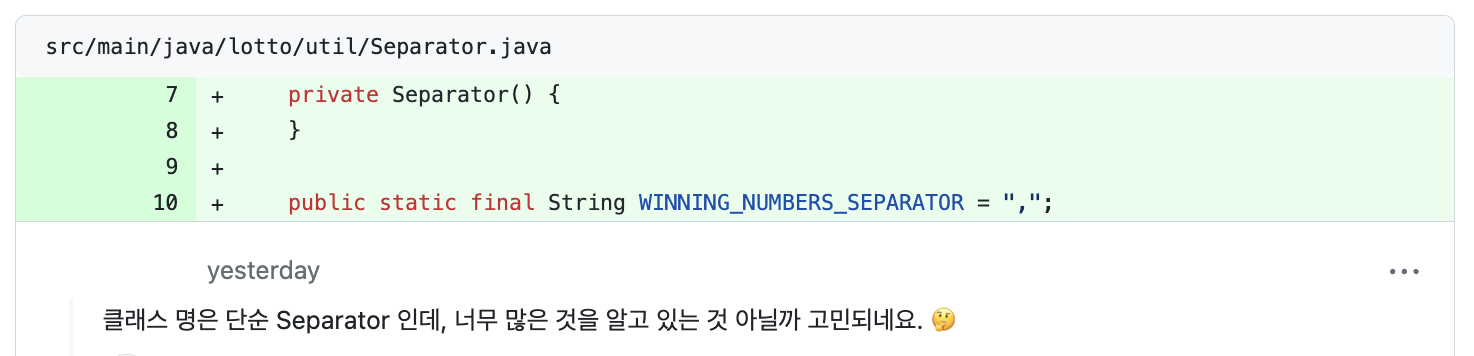
추가로 달린 코멘트의 유틸 클래스의 메서드가 어떻게 구분해야하는지 구분자를 스스로 안다.의 의미를 곰곰히 생각해보았다.
seperator는 그냥 comma라고만 알고 갖고 있고,
seperator가 어떤 메소드에 필요한 구분자인지까지 알 필요는 없기때문에,
사용하는 곳에서 가져다가 상수로 정의해서 쓰게 해야한다는 생각이 들었다!
공통 상수를 다시 클래스 상수로 선언!

📌 toString을 결과 출력에 써도 될까?
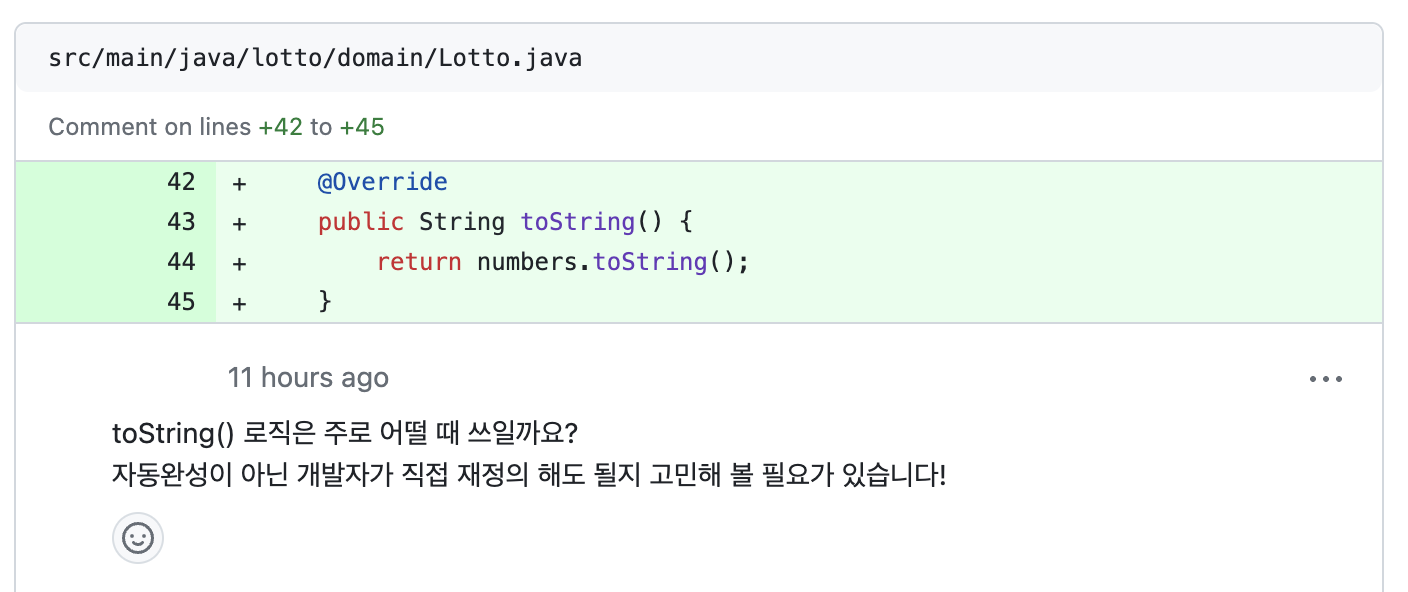
위와같은 리뷰를 보고 아차 싶어서 toString을 결과 출력에 써도 될지, 안된다면 왜 안되는지를 찾아보았다.
-
toString() 의 역할
- 객체의 문자열 표현을 반환하는 역할을 하며,
- 객체의 디버깅, 로깅 또는 사용자 인터페이스 출력과 같은 특별한 상황에서 주로 사용된다고 한다.
- 즉, 결과값 출력을 위한 메소드가 아니라는 것
-
왜 결과값 출력에 적절하지 않을까?
- toString은 객체의 내부 상태를 문자열로 변환하는 역할을 한다.
- 즉, 그 자체로 값을 추출하는 목적이 아니다.
-
따라서, 객체의 값을 가져올 때는 해당 객체의 메서드나 속성(필드)을 사용하는 것이 더 바람직하고, toString에 포함되어 반환되는 정보들은 전부 프로그래밍을 통해서 가져올 수 있도록 하여야 한다
-
정보 은닉과 보안 문제도 있다.
- toString으로 객체의 내부 상태를 직접 노출하는 것은 정보 은닉 원칙을 위반하기도 한다.
📌 중복 검증의 여러 방법들의 성능 비교
우선 내가 알고 있는 방법들은 이정도인데 각각 정리해보자면,
list.stream().distinct().count()
- 배열을 전부 순회해야하기 때문에 배열의 길이가 길어지면 비효율적
list.stream().anyMath()
- 중복이 검출되는 즉시 로직이 종료되어 비교적 효율적
return Set.copyOf(list).size() != list.size()
- 하나하나 순회하지는 않지만, 모든 리스트의 요소를 set에 추가하는 비용이 발생하므로 장단이 있음
결론
현재 미션 수준에서 anyMath나 set이나 성능적으로 큰 차이가 없을 것으로 보이므로 가독성을 고려해 선택하자!
📌 UI에 대한 검증이 필요할까?
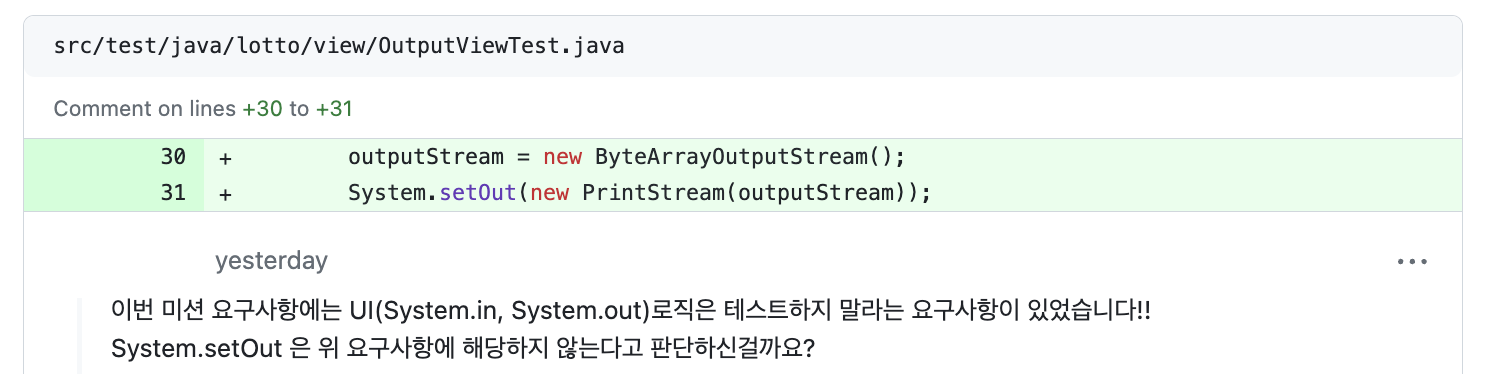
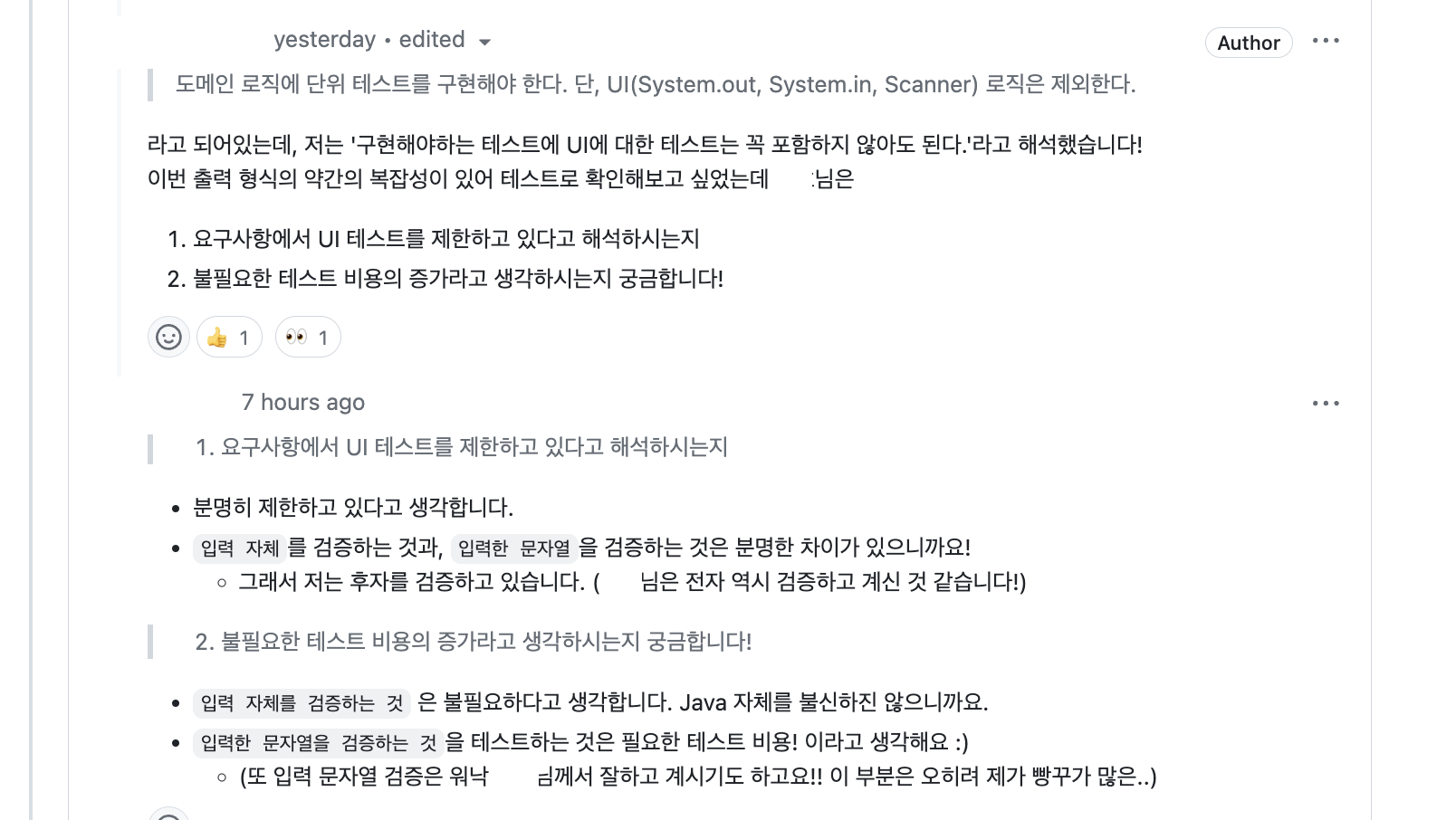
그럼 outputView에 대해 확인을 application을 돌려가며 해야하는 건가? 라는 의문이 아직 풀ㄹ리지 않았지만,
우선 입력 자체를 검증하는 게 아니라 입력한 문자열을 검증해야한다는 측면에 동의한다!
outputView에 대한 검증은 어떻게 하지..는 고민하고 정리해봐야겠다!
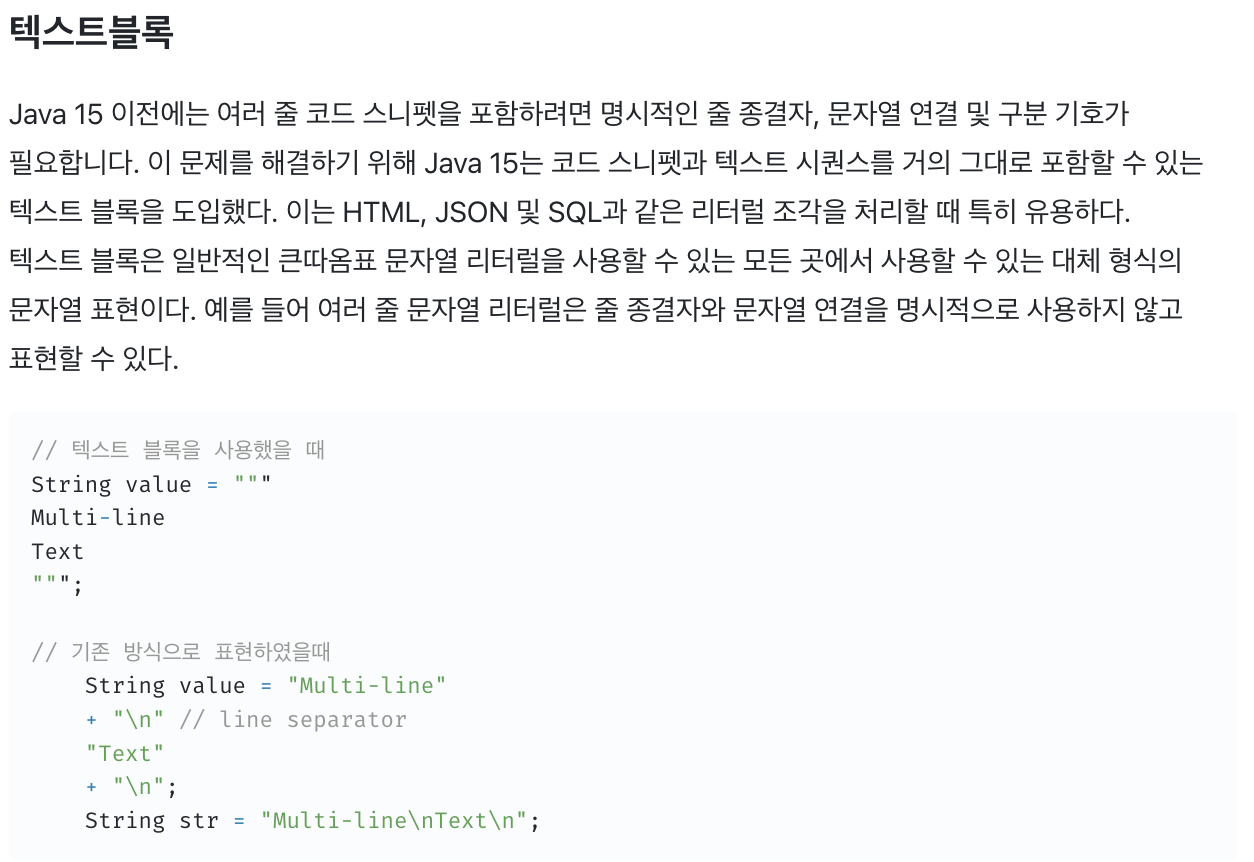
📌 자바17 텍스트 블록!
여기에 대한 리뷰가 있어 해당 부분 발췌를 첨부한다!
출처: https://velog.io/@nandong1104/Java-17로-넘어갈-시간
📌 OutputView에서 데이터 처리를 안하려면
방법1) 출력을 위해 필요한 데이터만 정리해 갖고가는 dto

방법2) dto를 사용하지 않는다면 Formatter
outputView에 복잡한 출력을 위한 처리 메소드가 있지 않으려면 outputView에 더해서 Formatter 사용이 필요할 것 같다.
📌 새로운 방식의 입, 출력 구조
위의 고민과 함께 이런 리뷰를 받아왔기에 이번주야 말로 inputView에서의 print 분리를 시도해볼 때라고 생각했고, 리뷰 남겨주신 리뷰어 분의 포맷을 이용해 적용해보려고 한다!
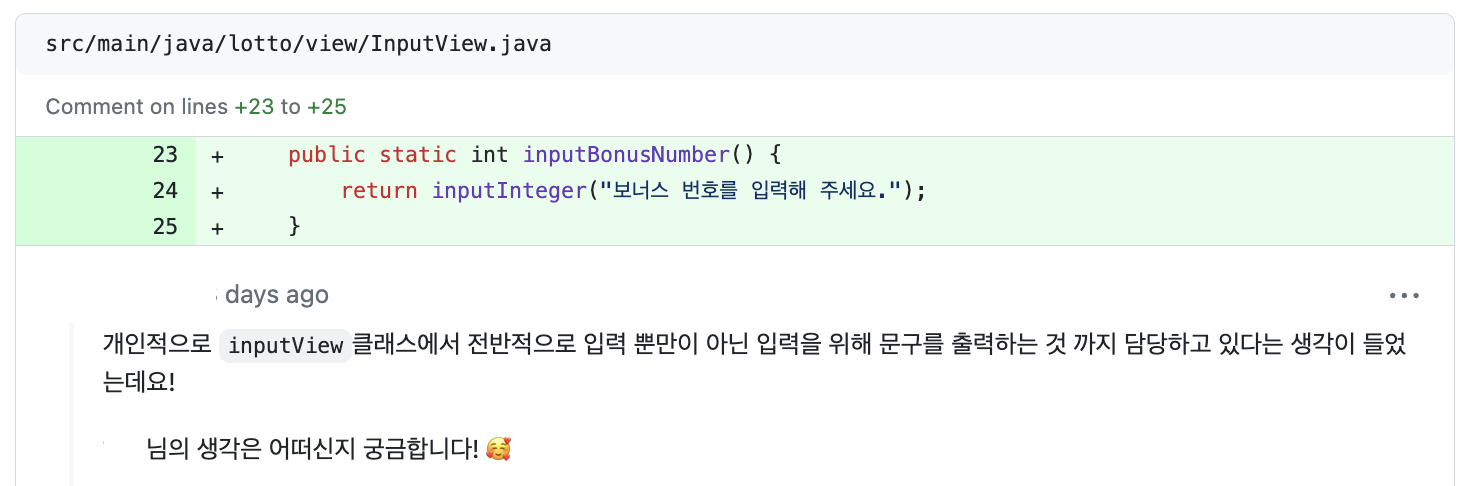
InputView와 OutputView에서 입력, 출력을 담당하는 부분만을 분리하고자 한 이유는
- 리뷰로 지적받은 것 처럼 InputView에 출력 기능이 있는 것을 분리하기위해서와
- 입, 출력 방식의 변경을 고려한 것이라고 할 수 있다.
만약 출력 방식이 System.out이 아니라 다른 방식으로 바뀌게 된다면?
입력 받는 방식이 Console.realLine이 아닌 다른 방식으로 바뀌게 된다면?
Input, Output의 모든 부분을 바꿔줘야할 것이다.
코드 살펴보기
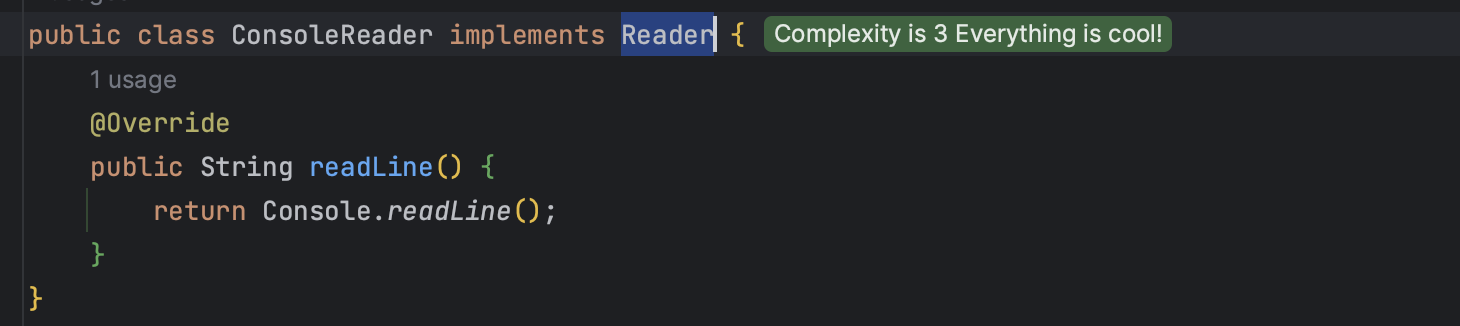
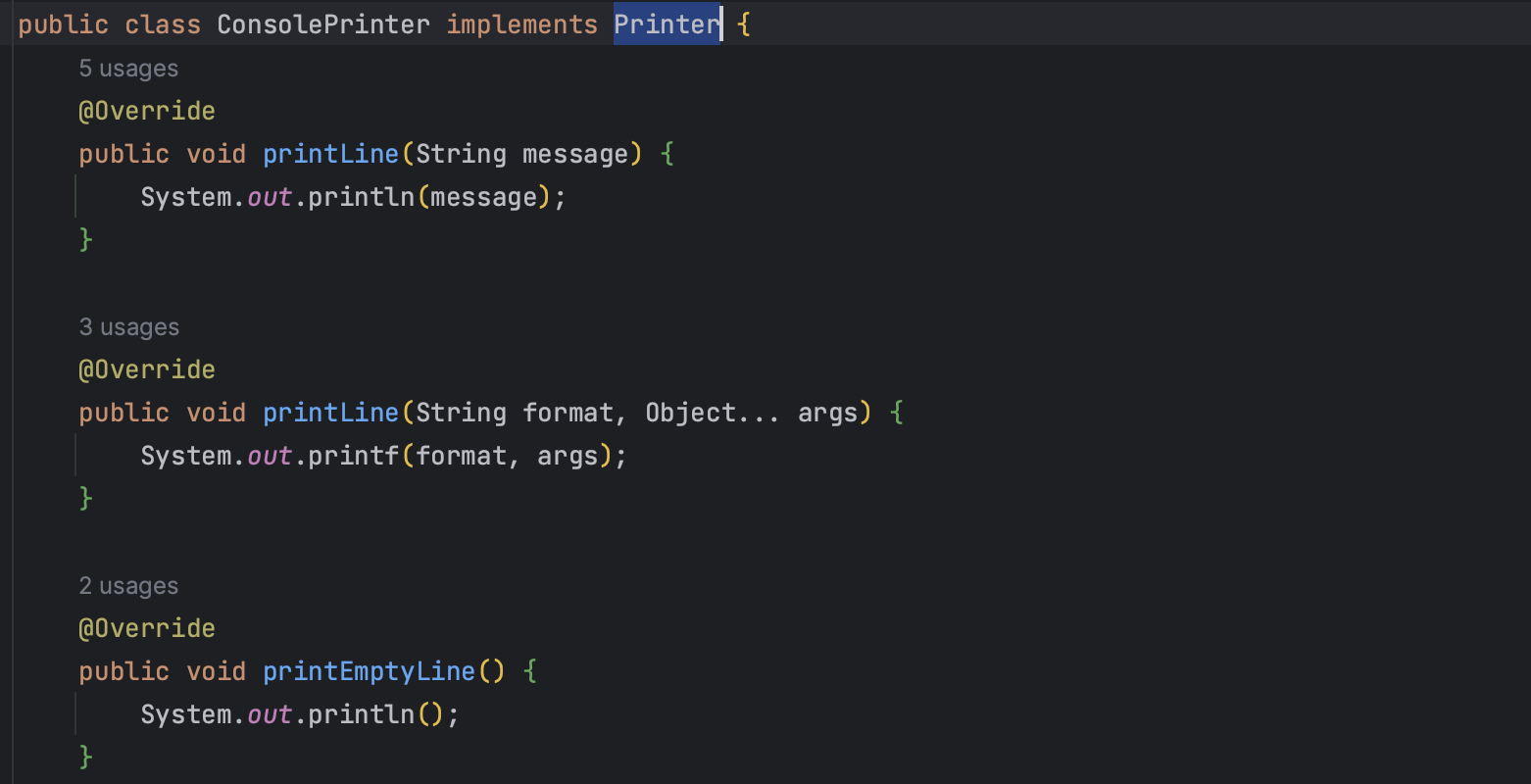
System.out, Console.realLine 입, 출력 메소드를 Reader, Printer 클래스로 분리한다.
여기서 각각 구현체로 상속받아 구현하는 이유는
- reader, printer 모두 InputView 테스트를 위해 필요하므로 mock 객체를 만들어주기 위해서라고 할 수 있다.
그리고 각각의 reader와 printer는 InputView와 OurputView에 선언해두고 쓰기 위해 생성자 주입을 해준다.
이 때, OutputView에 Formatter도 주입해주는데 이건 OutputView를 보면서 설명하도록 하자.
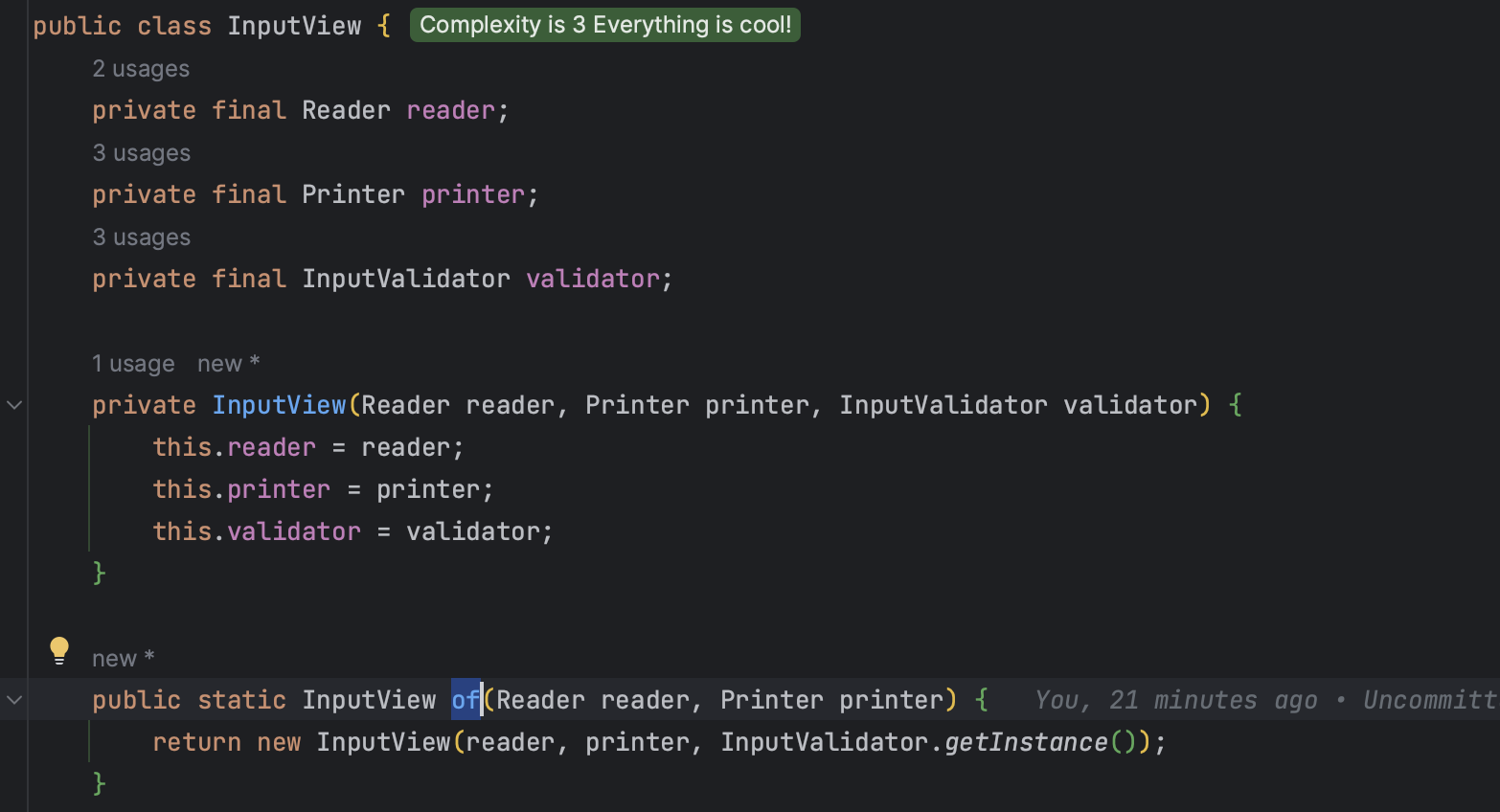
특이점이 그냥 new 생성자로 주입해도 되는데 InputView는 of 부생성자를 사용하는 이유는 InputView의 경우 Validator를 선언해두고 써야하기 때문에, 초기화 전에 주입 과정이 필요해서 부생성자를 사용한다.
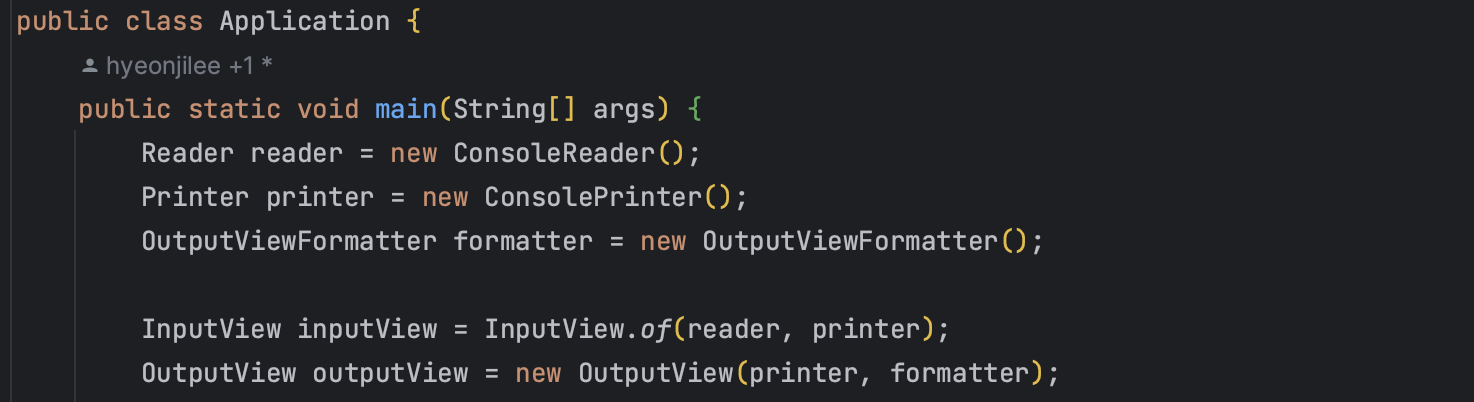
다시 Application으로 돌아와서,
이제 이렇게 생성자 주입으로 reader, printer 세팅이 된 InputView와 OutputView를 컨트롤러에 주입해준다.

이 방식도 원래는 InputView와 OutputView의 정적 메소드를 호출하는 식으로 유틸성으로 썼는데, 싱글톤 방식으로 호출 방식을 바꾸면서 캡슐화 등의 장점을 더 살려보고자 변경했다.
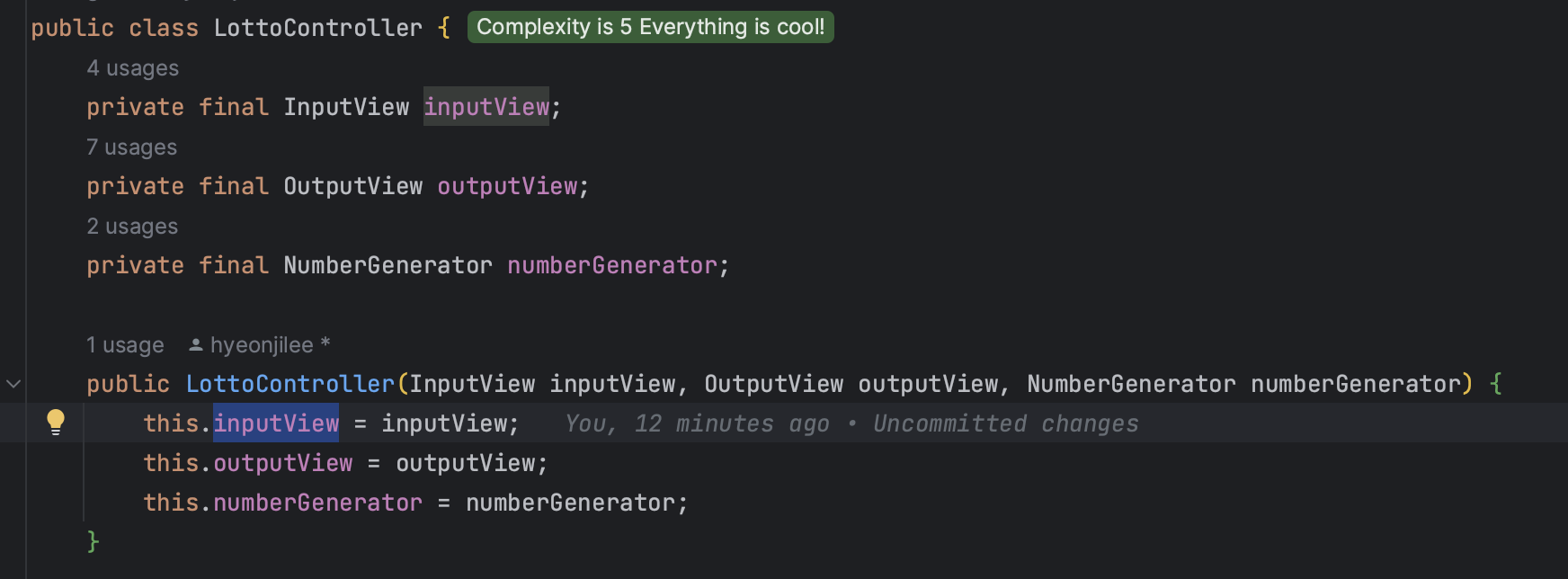
이제 InputView와 OutputView는 싱글톤 방식으로 컨트롤러에 멤버 변수로 선언되어 메소드에서 호출해서 쓸 수 있다.
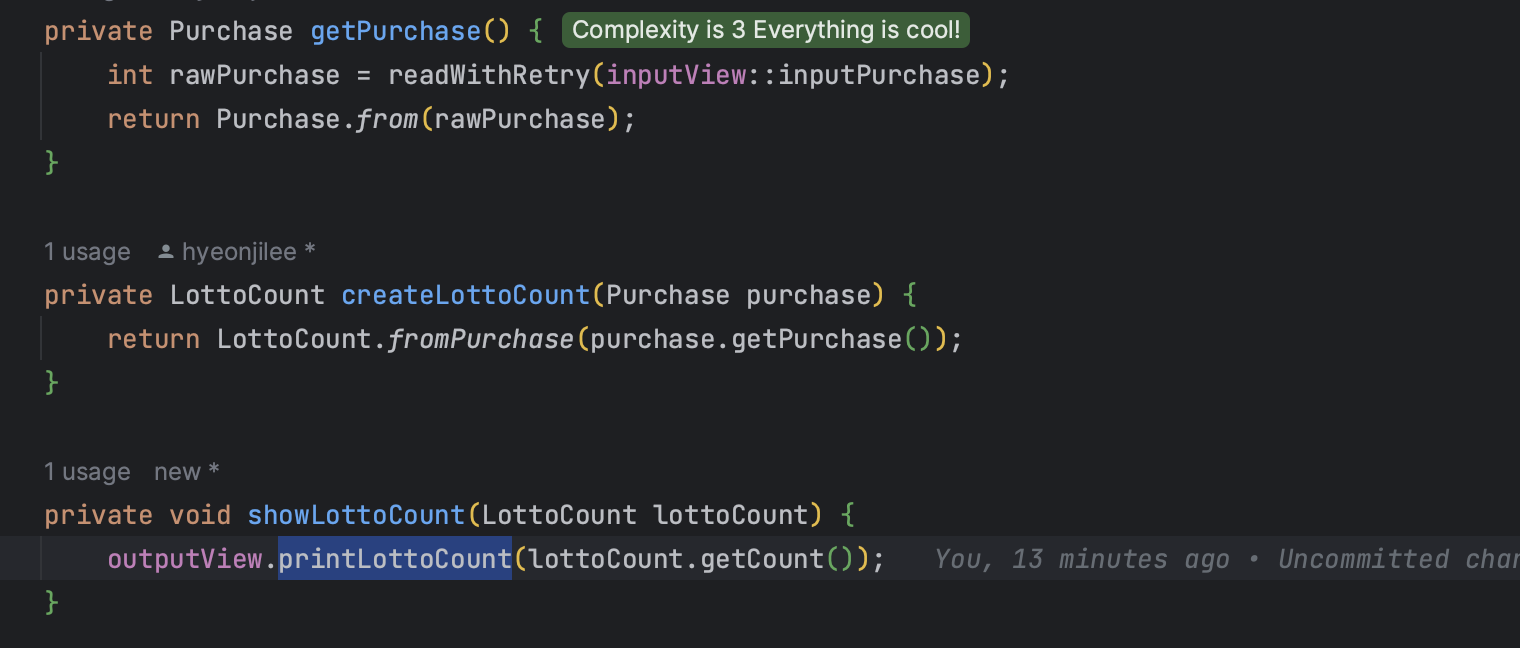
각각 InputView에서는 어떤 구조인지 살펴보면,
이전처럼 InputView에서 바로 System.out으로 출력하지 않고 갖고 있는 printer로 출력을 넘긴다. 입력을 받는 것도 Console.readLine을 직접하지 않고 reader에 넘긴다.
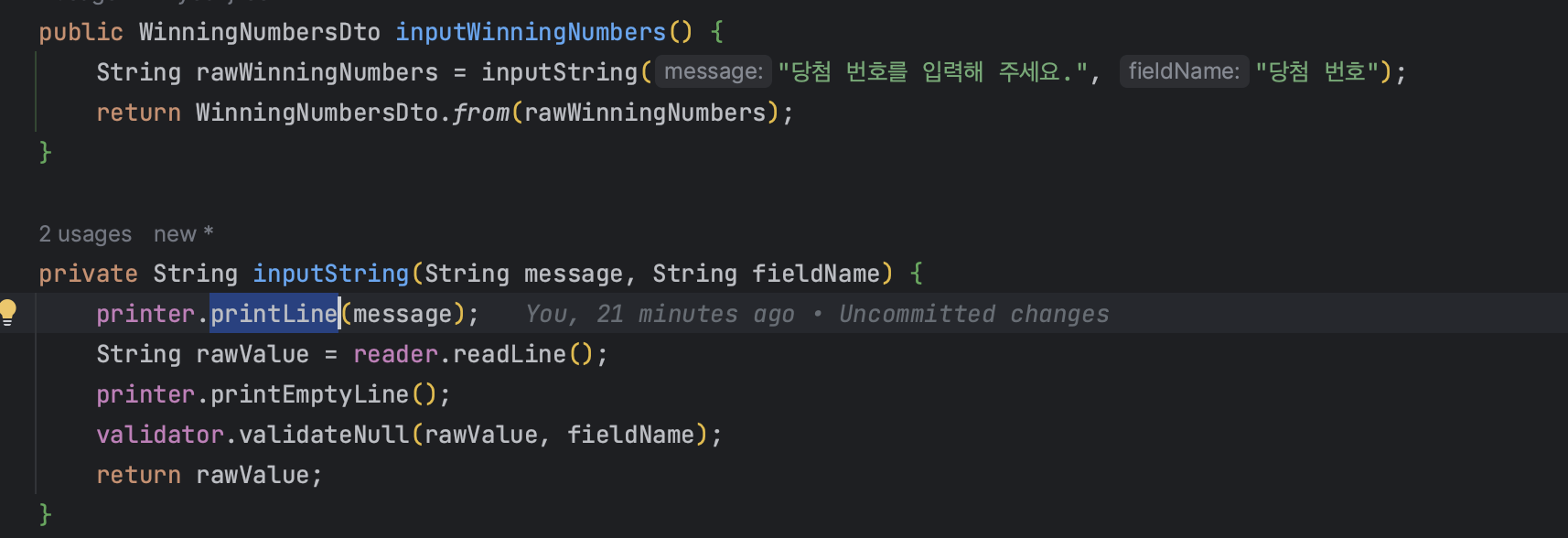
마지막으로 OutputView를 보기 전에 Application에서 OutputView에 formatter를 주입한 것을 봐야할 것 같은데
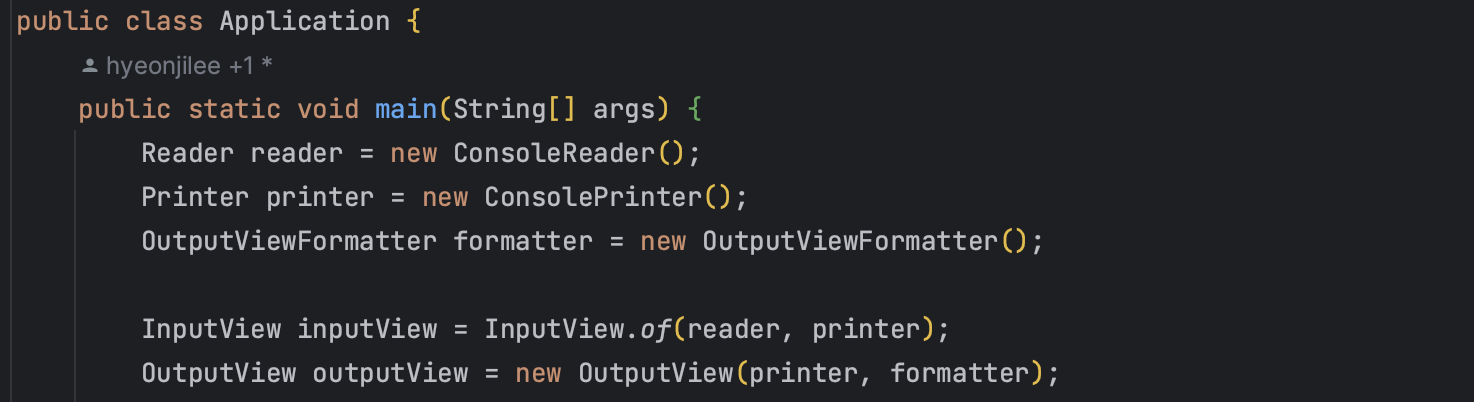
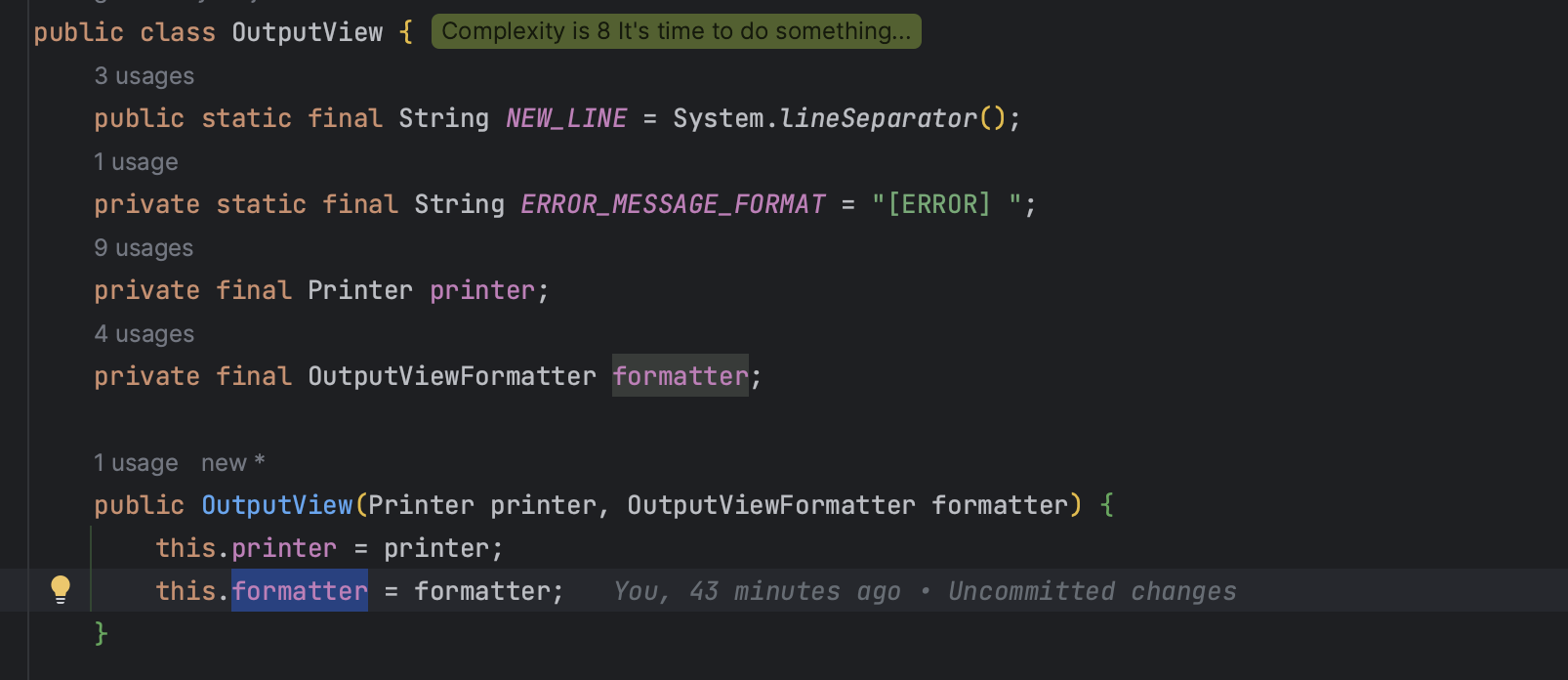
이 formatter는 전달받은 객체에서 출력에 필요한 형식으로 뽑아내는 것을 OutputView에서 분리한 것으로
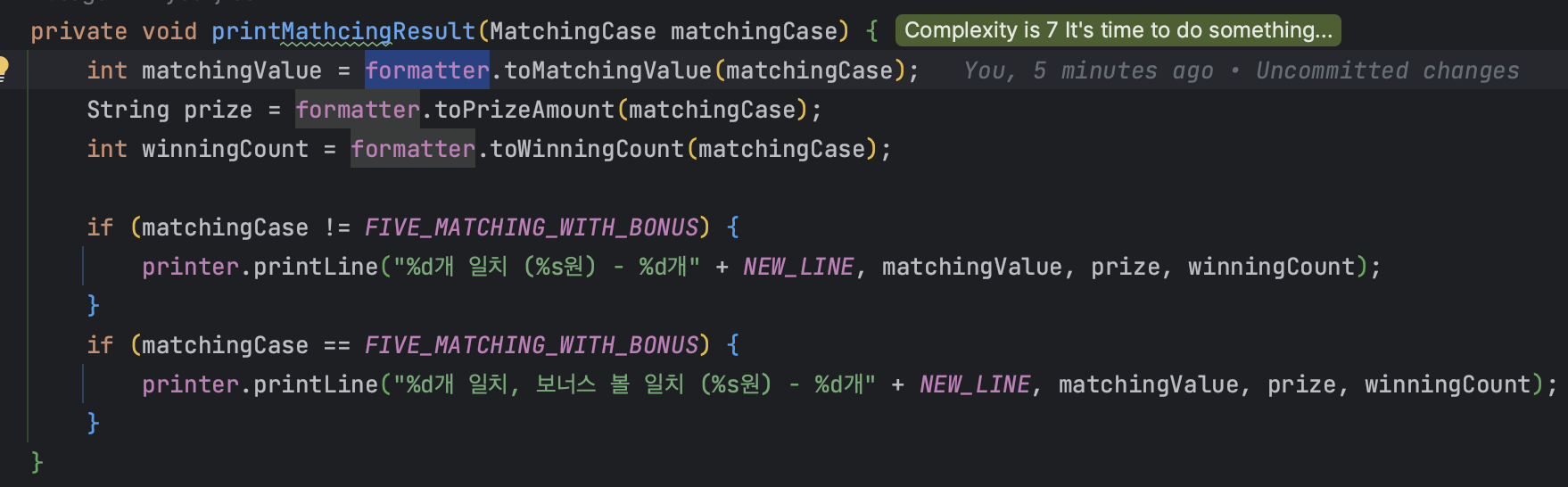
아래와 같이 필요한 형식의 값을 처리해서 보내줌으로써 OutputView이 정말 '출력'의 흐름에만 필요한 메소드로만 이루어질 수 있게 하였다고 할 수 있다.

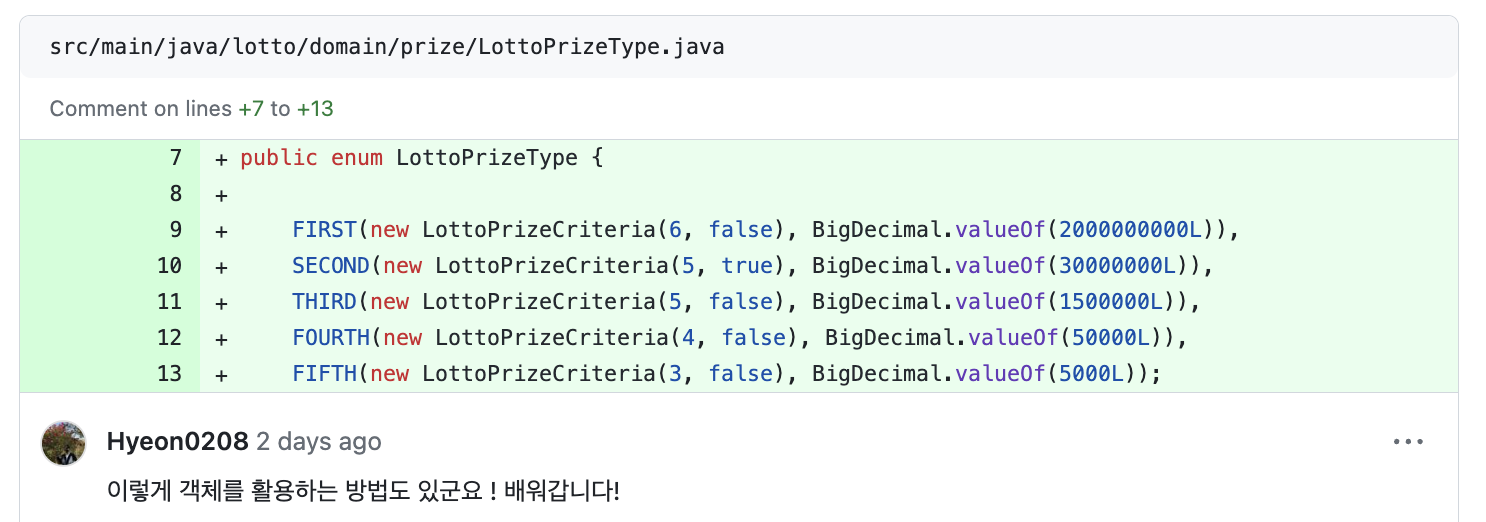
📌 enum 활용 관련!
enum 필드에 객체나 function을!
로직이 복잡하면 enum의 속성에 이렇게 주는 아이디어 좋다!
-
객체를 넣어주는 방법과!
-
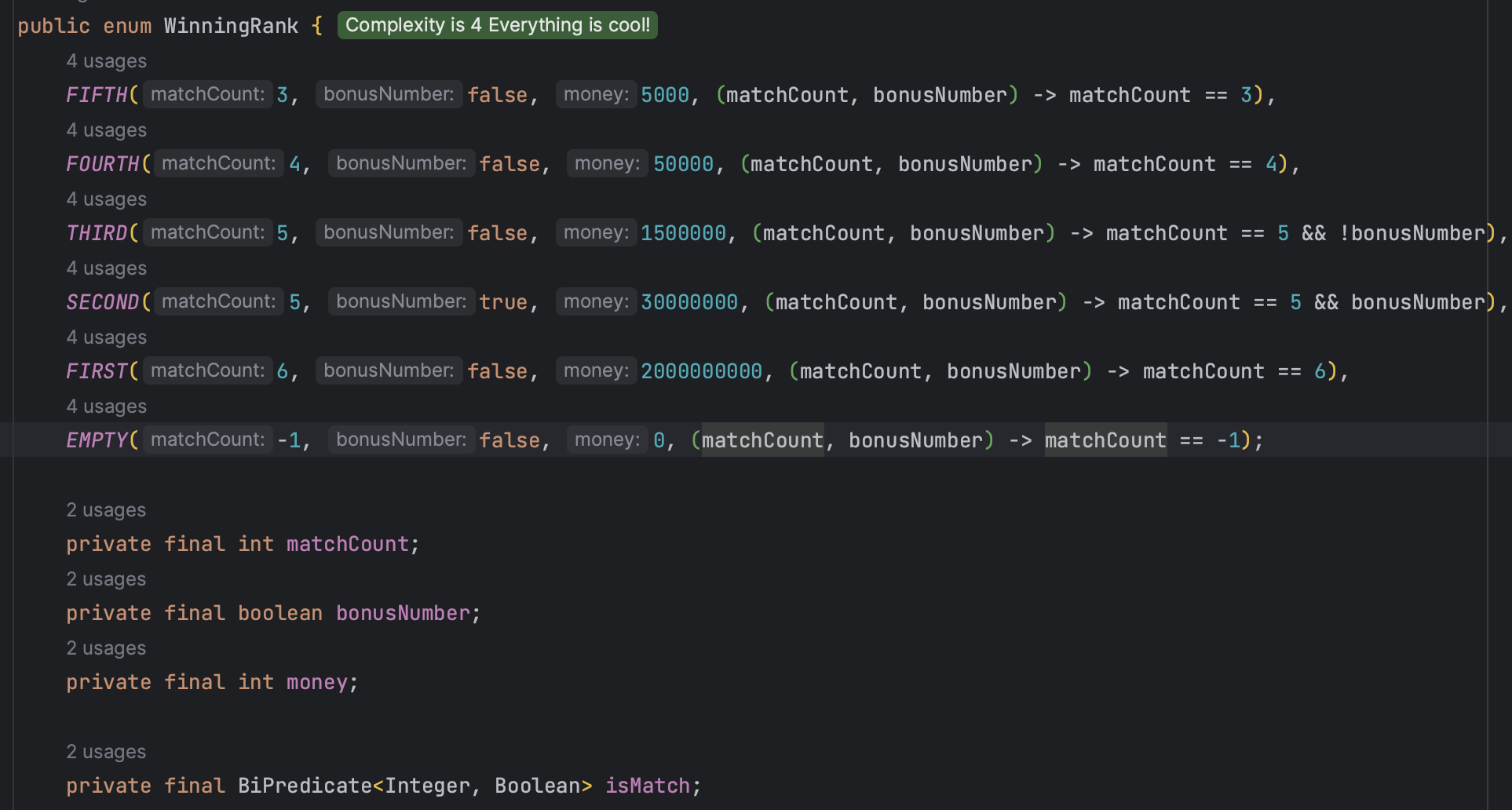
Generic? BiPredicate 등을 쓰는 방법!
boolean의 용도인 것 같은데 알아보자!
enumMap 활용!
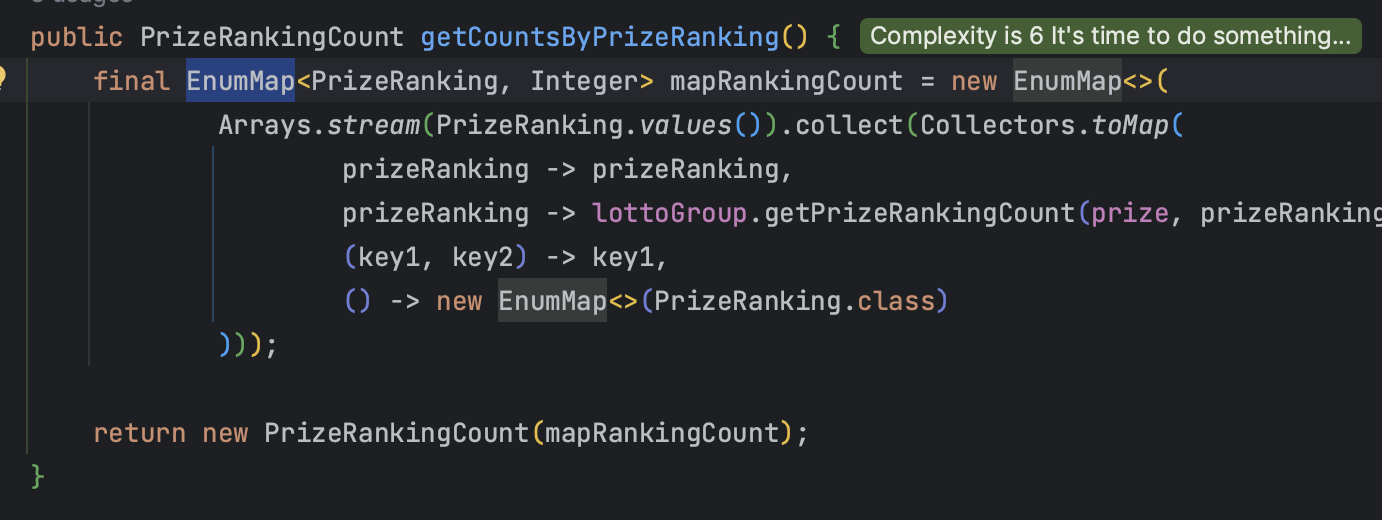

https://uhanuu.tistory.com/entry/EnumMap-%EC%A0%81%EC%9A%A9%ED%95%98%EA%B8%B0
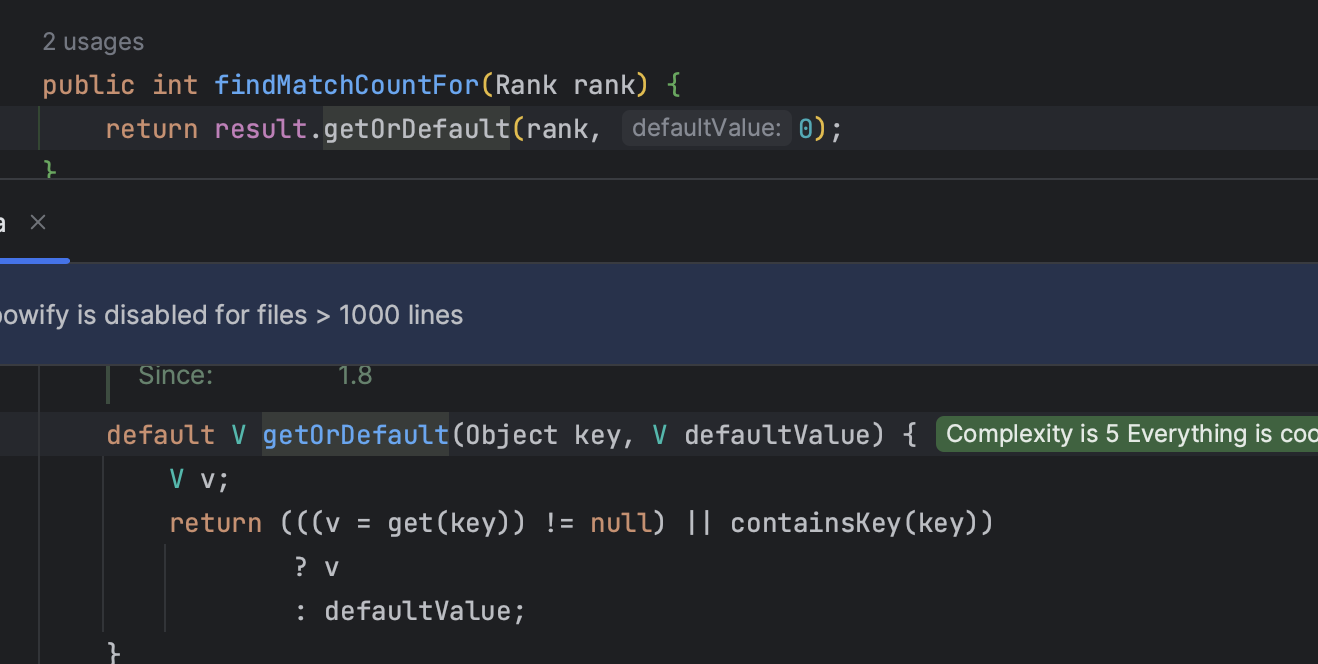
map의 getOrDefault
📌 코수타 정리
- 현재 수준에서 지나친 기능분리가 가독성을 떨어뜨릴 수 있다.
너무 파편화되어있거나 하는 경우! - 미션 제출방법 다르니 꼭꼭 잘 읽어보기!
- 맨 위에 핵심기능 한 문장 작성해놓고,
동작가능한 가장 핵심 기능을 작은 단위로 구현을 가장 먼저 하자!
