추론과 예측, 학습, 분류
예측
- 다양한 모델을 평가하며 가장 성능 좋은 모델을 선택하는 과정이다.
추론
- 추론이란 머신 러닝 모델이 학습 단계를 완료한 후에 새로운 데이터에 대해 예측을 수행하는 과정이다
학습
- 모델을 만드는 것이나 배우는 것으로 모델은 특성과 라벨의 관계를 점차적으로 학습해나간다.
- AI의 직식을 증진하는 과정이다.
분류
-
불연속적인 값의 라벨을 예측한다. 예로는 암의 유무 혹인 인종 등이 있다.
인공지능에서 학습은 데이터의 특성과 라벨의 관계를 점차적으로 학습한 후 입력하는 데이터의 라벨을 분류하고 어떤 데이터값을 넣어야 어떤 값이 도출될지 예측하고 학습단계가 완료된 후 새로운 데이터에 대한 예측을 수행하는 과정을 추론이라 한다.
지도학습
-
입력과 출력의 예제들을 학습시켜 이들간의 상관관계를 모델링하는 방식이다. 이 모델에 새로운 입력을 입력하는 예측값을 얻을 수 있다.
필기체인식 관련 인공지능
epoch
- 전체 대이터 셋에 대해서 한 번 학습을 완료한 상태이다. 순전파와 역전파가 한 번 진행된 상황.
batch
- 한 번의 batch size는 batch마다 주는 데이터 샘플의 size이다.
iteration
-
epoch를 나누어서 실행한 횟수이다.
-
메모리의 한계로 인하여 한 번의 epoch에서 모든 데이터를 한꺼번에 집어넣을 수 없으므로 데이터를 나누어줘야한다. 몇 번 나누어주었는가가 iteration, 각 iteration 마다 주는 데이터사이즈를 batch size라 한다.
-
총 데이터가 2000개이고 epochs = 20, batch size= 500이라 가정하면
1 epoch = 2000 / batch size = 4 iteration.
전체 데이터셋에 대해서는 20번의 학습이 이루어지므로 iteration 기준으로는 80번의 학습이 이루어진다.
경사하강법
- 함수 기울기를 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복하는 행위로 이를 위해서 weight 값을 조정하며 최적 파라미터를 찾는 것이 목표이다.
- 기울기가 가장 낮은 방향으로 반복적으로 조정하면서 최적의 파라미터를 찾아가는 최적화 알고리즘이다.
AlexNet
-
5개의 convolution 계층과 3개의 완전 연결 계층(fully connected layer)으로 구성되어 있으며 ReLU 활성화 함수와 드롭아웃이 적용되어있다.
CNN
-
시각적 영상을 분석하는 데 사용되는 인공신경망의 한 종류이다. 예시로는 영상 및 동영상 인식, 추천 시스템 등이 있다.
backpropagation
- 순전파 단계에서 입력값을 신경망에 통과시켜 출력값을 계산한 후 출력값과 정답 사이의 오차를 역방향으로 전파하여 오차를 줄이도록 가중치를 조정하는 과정이다.
AI
- 컴퓨터가 인간의 학습, 추론, 문제해결등의 지적능력을 모방하는 것으로 인간수준의 지능을 가지는 것을 목표로한다.
Video turing test
- 인간과 같은 인식을 하는지 실험해보는것으로 대표적예시론 captcha가있다.
필기체 인식 (MNIST)
MNIST
-
Keras : deep learning framework
-
mnist.load_date() 이용하여 로드
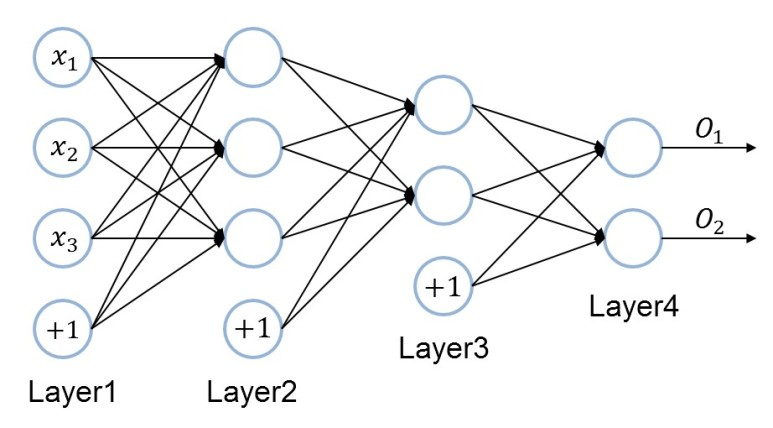
-
입력 <,,>의 기댓값(T)를 알고 있다면 Output Layer의 출력값(O)과의 차(T-O)를 계산하여 역전파를 이용해 그 차이를 최소한하는 방향으로 weight를 조정한다.
CNN (Convolutioanl Neural Network)
-
이미지의 패턴을 분석하기 좋은방법이다.
-
특징을 추출하기 위한 layer 집합과 분류하기 위한 layer의 집합이 존재하며 각각 전반부와 후반부에 위치한다.
-
특징 추출을 위해서는 Convolution layer, relu layer, pooling layer을 반복하며 neural network 구조를 쌓아간다.
train, validation, test
train
- 어떤 input 값을 넣었을 때 어떤 output 값이 나와야하는가 학습시키는 단계이다.
- 전체 데이터의 80%정도이다.
test
- 성능을 측저앟기 위한 데이터로 데이터의 20%wjdehdlek.
validation
- 직접 학습에 관여할 뿐 학습을 시키진않는다.
- train과 test 사이의 괴리를 보안하고 성능을 검증하는 기회를 제공한다.
- 검증을 통하여 더 정교해진 모델 구축이 가능해진다.
- 정확도와 손실률을 측정하여 성능을 평가한 후 최적의 결과를 얻을 때까지 반복한다.
sigmoid
- 입력값에 따라 0과 1의 값을 출력하는 s자형 함수이다.
Filtering
- 합성곱
Convolution
- 하나의 이미지를 필터된 stack으로 만든 layer
ReLU (Rectified Linear Units)
- 양수인 값은 그대로 나오고 음수는 0으로 변환되어 나온다.
- sigmoid 함수보다 빠르고 은닉층이 많아져 기울기가 0이되는 경사 손실을 덜 발생시킨다.
Pooling
-
window size와 stride를 정한 후 fileted image를 window size만큼 자르고 그 중 최댓값을 정하는 과정.
-
이미지들의 양을 줄이는 작업을 한다.
AI Prediction
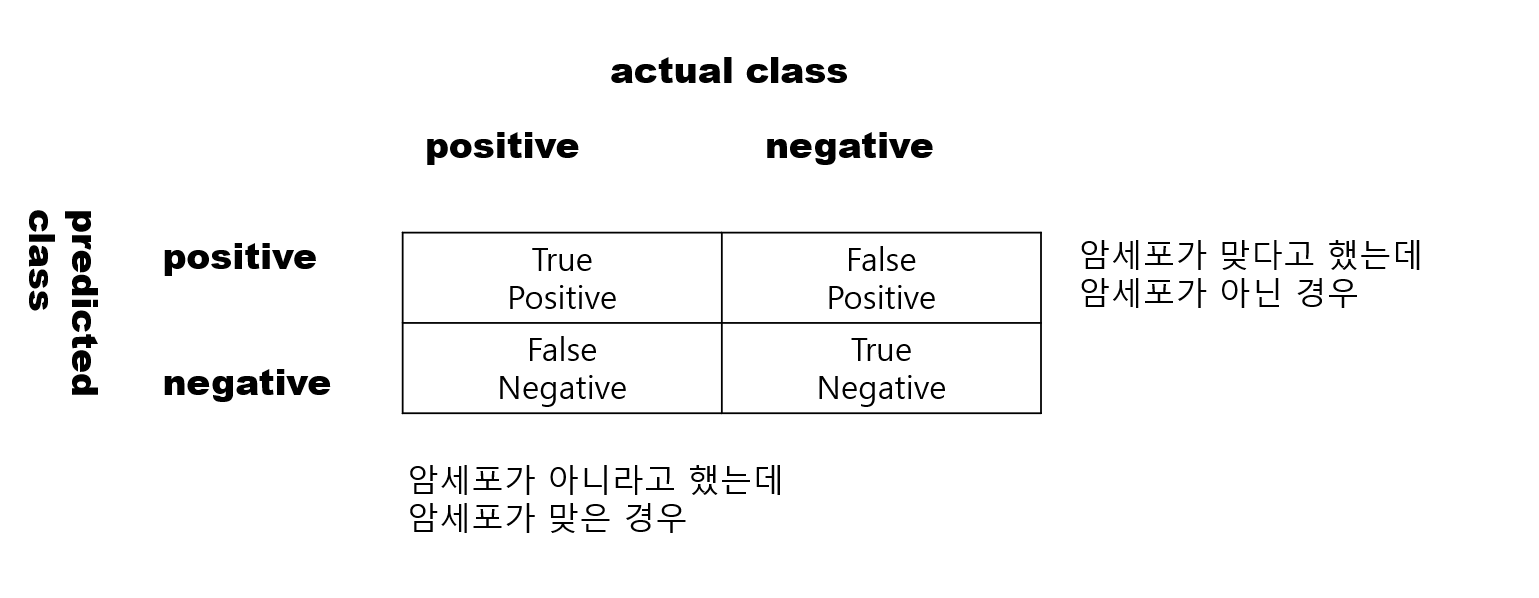
전제 : AI의 예측이 맞았는가 TRUE, 틀렸는가 FALSE
예측이 긍정이다 POSITIVE, 부정이다 NEGATIVE
Overfitting
- train set은 잘 맞추나 test set은 그러지 못한 현상으로 데이터의 양이 방대해서 예측값이 잘못도출되는 현상이다.
- 방지법
- date augmentation : 가지고있는 데이터셋을 여러방법으로 augment하여 학습 데이터셋의 규모를 키우는 방법이다.
- dropout : 훈련이 반복되는 과정중에 무작위로 해당 레이어의 뉴런을 삭제한다.
- hidden layer 크기를 줄이거나 layer의 개수를 줄인다.
