Search란?
직관적 정의
- 사용자가 Query를 입력하면
- 시스템이 Document Collection에서
- 가장 관련성 높은 문서들을 순서대로 반환하는 문제
Search가 중요한 이유
- 검색은 단순한 기능이 아니라 정보 접근의 핵심 인프라
- LLM에서도
- RAG(Retrieval-Augmented Generation)의 성능은
- 무엇을 검색해오느냐 에 크게 의존
-> Search가 약하면 LLM도 약해진다.
Search Task 정식 정의 : Ad-hoc Search
구성요소
- Document : 검색 대상 텍스트(웹페이지, 상품 설명, 논문 등)
- Collection : 전체 문서 집합
- Query : 사용자의 정보 요구를 표현한 짧은 텍스트
- index : 빠른 검색을 위한 자료구조
목표
- 각 문서에 대해 Relevance score를 계산
- Query에 가장 관련 있는 문서를 상위에 랭킹
-> Relevance는 보통 Query-Document 텍스트 유사도로 근사
검색 성능 평가 지표
Precision@N / Recall@N
-
Precision@N
상위 N개 결과 중 얼마나 많은 것이 relevant인가 -
Recall@N
전체 relevant 문서 중 얼마나 많이 찾아 냈는가Precision과 Recall 만으로는 부족한 이유 : 보통 문서는 이진 relevance(맞다/아니다)가 아님.
실제로는 graded relevance- Exact / Substitute / Complement / Irrelevant
그래서 등장한 것이 NDCG
NDCG@N
아이디어 :
- 더 관련 있는 문서일수록
- 그리고 더 위에 랭크될 수록 -> 더 큰 점수를 줘야 한다.
1) Gain : 문서의 relevance 점수
2) CG (Cumulative Gain)
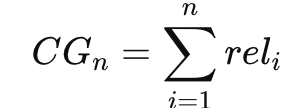
3) DCG (Discounted CG)
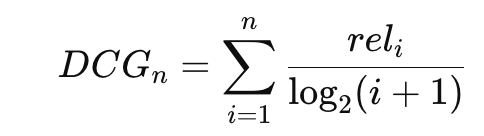
-> 아래 순위일수록 기여도 감소
4) IDCG : 이상적인 랭킹의 DCG
5) NDCG : 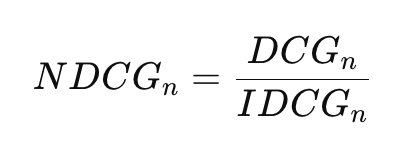
-> 서로 다른 query 간에도 공정 비교 가능
Lexical Retrieval
핵심특징
- Query와 Document를 단어 단위로 정확히 매칭
- 표현 방식 : Sparse Vector
- 대표 방법 : TF-IDF / BM25
장점
- 빠르고 단순함
- 대규모 코퍼스에 적합
- 학습 데이터 불필요
- 해석 가능성 높은
단점
- 의미(sementic)이해 불가
- 동의어, 패러프레이즈에 취약
Inverted Index (검색의 핵심 자료구조)
왜 필요한가?
- 모든 문서와 cosine similarity 계산 -> 비효율
- 대부분 문서는 query단어를 포함하지 않음
-> query 단어를 포함한 문서만 후보로 계산
Dictionary : teram -> postings list
Postings list : 해당 term이 등장하는 docID 목록 (tf,df)
Query 단어별 postings list 조회
postings의 union으로 candidate set 구성
candidate에 대해서만 TF-IDF or BM25 점수 계산
BM25(Best Match 25)
- 1995년 제안
- 지금까지도 Lucene/Elasticsearch/Solr 기본 랭커
- 학습 불필요, 빠름, 강력한 baseline
BM25 점수함수
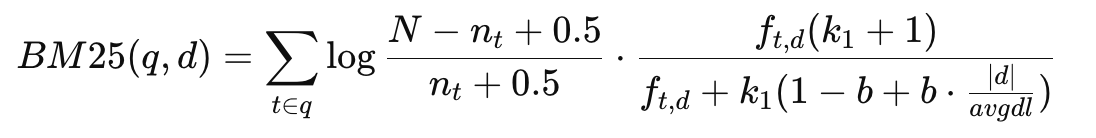
구성요소
1) IDF(smoothed)
- 극단적인 값 방지
- term이 없을 확률 vs 있을확률 관점
2) TF saturation
- k1 : TF 증가가 어디서 포화되는 제어
- 보통 1.2~2.0
3) Length normalization
- b : 문서 길이 보정 정도
- b = 0 : 길이무시 / b=1 : 완전 보정
- 실무 기본값 : 0.75


2KT