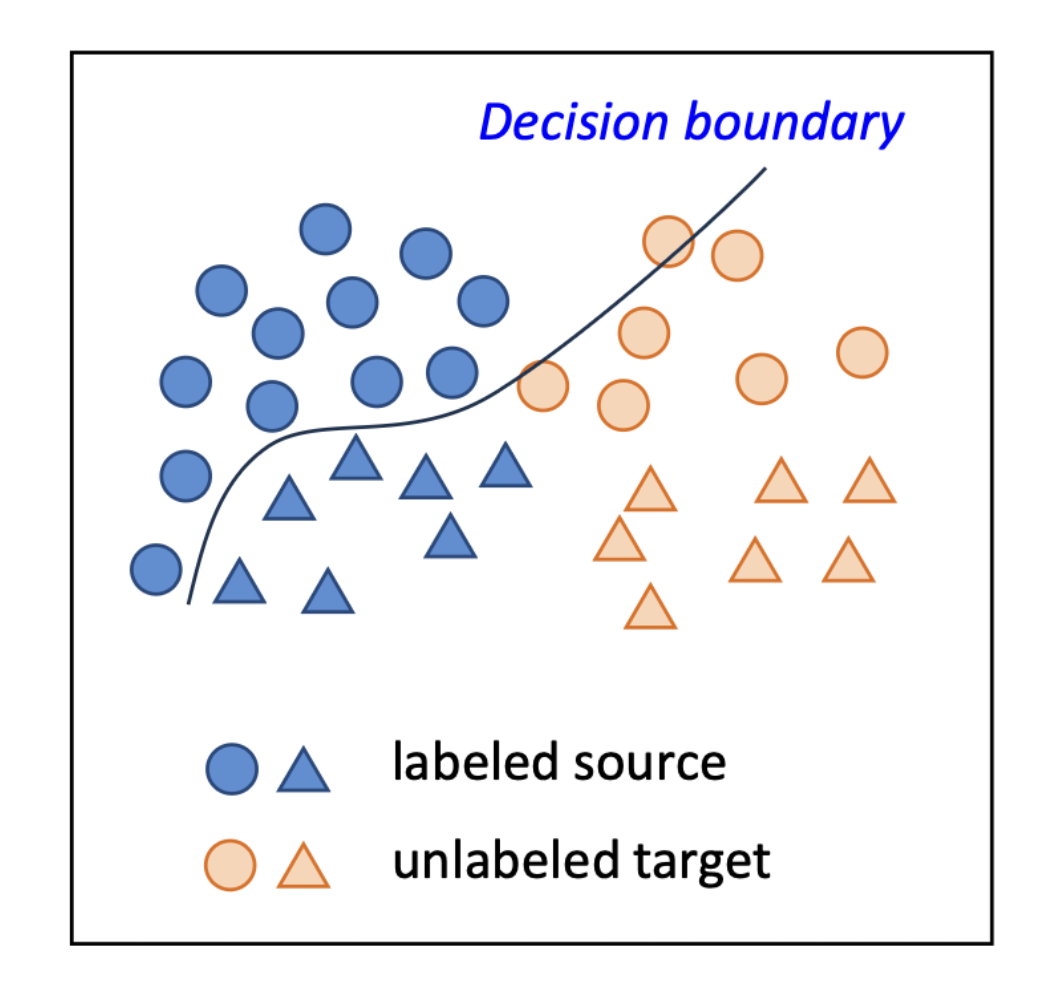
도메인 적응(domain adaptation)
- 레이블된 소스 도메인(Labeled source domain)
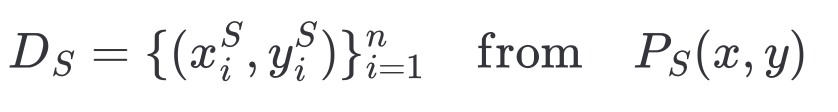
- 레이블되지 않은 타깃 도메인(unlabeled target domain)
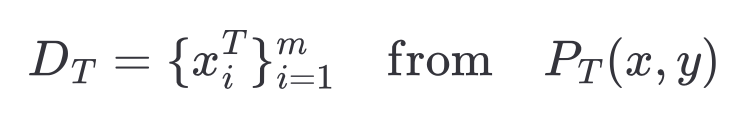
우리는 레이블된 소스 데이터(labeled source data)에 대한 오차(error)를 최소화할 수 있다
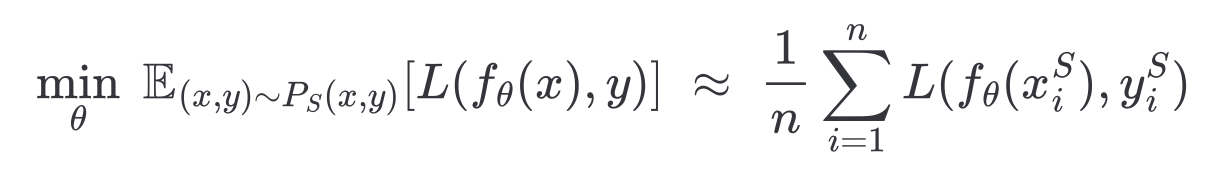
이 모델은 타깃 도메인에 대응하지 못한다. (타깃 도메인, 소스 도메인으로 부터 온 x,y 값이 다르므로)
-> 두 도메인 사이에는 입력 x를 레이블 y로 매핑하는 공통된 결정 패턴(common decision pattern) 이 존재한다는 가정. 레이블링 규칙(labeling rule)이 도메인 간 공유됨
해결책 :
1) 각 소스 샘플(source sample)이 타깃 도메인(target domain)에 얼마나 중요한지를 추정하고
2) 이를 선택적으로 반영 하는 것
-> 타깃 분포 Pt(x) 하에서 더 높은 확률(more likely)을 가지는 소스 예시의 가중치를 높인다.
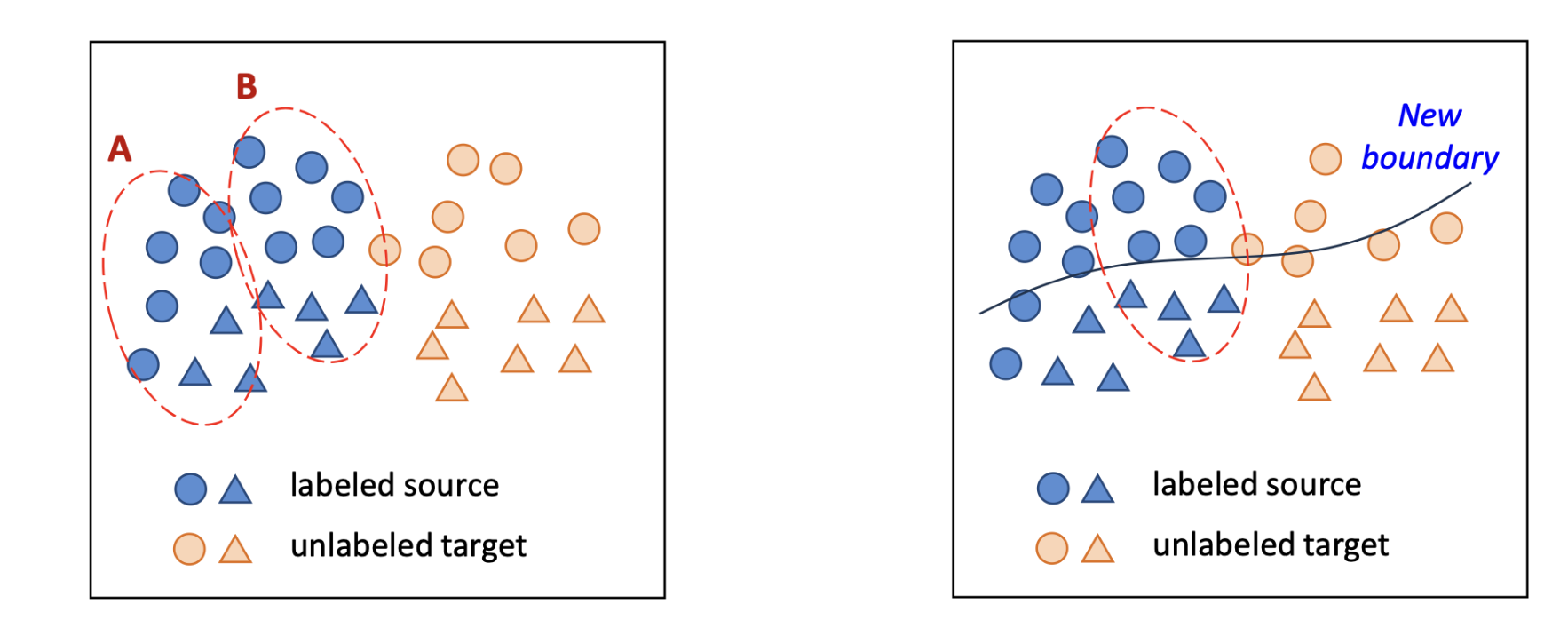
타깃 도메인과 유사한 데이터에 집중하는 것이 더 유익하다.
따라서 우리의 목표는 타깃 도메인에서의 오차(error)를 최소화 하는 것

중요도 가중치(importance weight)를 추정하기 위해서 베이즈 규칙(bayes rule)을 사용하면 가중치(weight)는 다음과 같다.

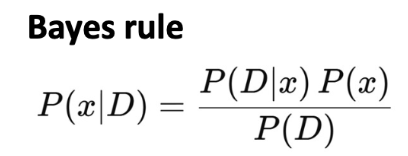
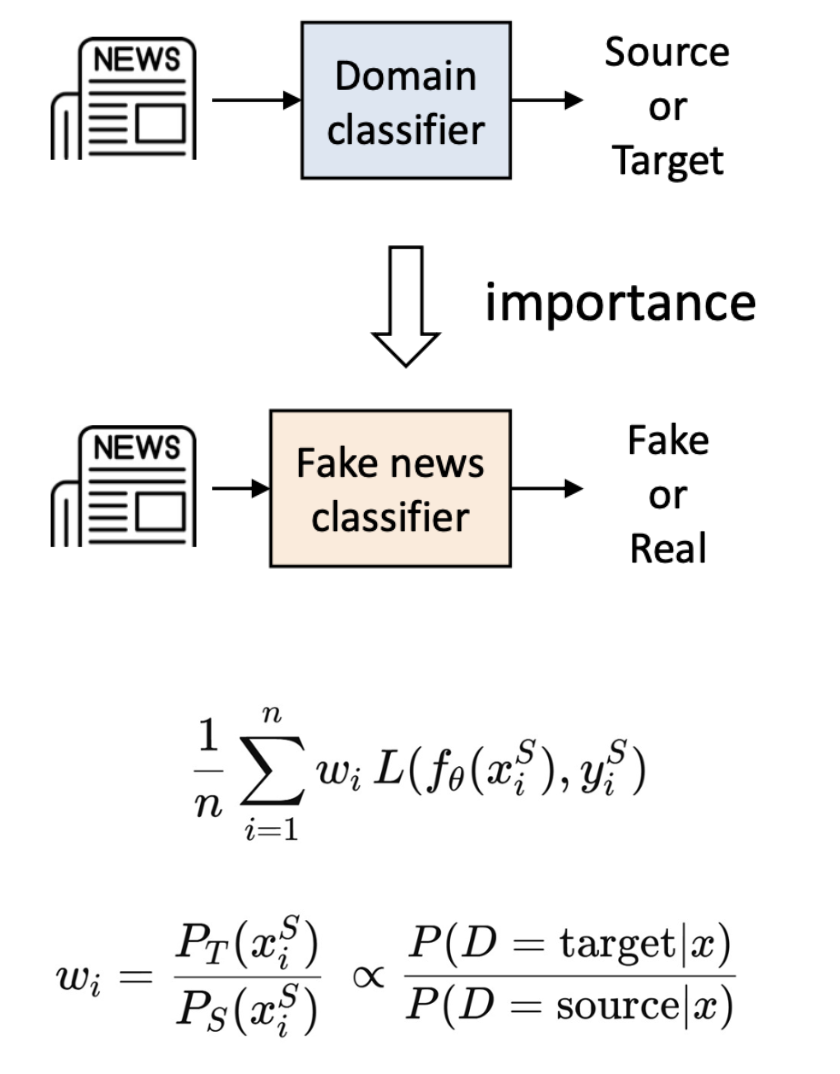
가중치는 별도의 도메인 분류기(separate domain classifier)를 사용해서 추정 -> 소스(source)와 타깃(target) 샘플을 구분하기 위한 이진 분류기(binary classifier)를 학습

정리
도메인 적응 문제에 대한 해결책 :
각 소스 샘플이 타깃 도메인에 얼마나 중요한지를 추정하고, 이를 선택적으로 반영함
절차
1) 이진 분류기(binary classifier)를 학습시켜 소스 데이터와 타깃 데이터를 구분함
2) 모든 소스 데이터 인스턴스에 대해 중요도 가중치(importance weight)를 계산
3) 가중치가 적용된 손실함수(weighted loss function)를 사용하여 타깃 분류기 를 학습
한계점(Limitation)
- 여전히, 학습에는 소스 데이터(source data)만 사용된다.
- 효과성(effectiveness)은 소스와 타깃 도메인 간의 중첩 정도 에 크게 의존함
- 다시말해, 두 도메인의 특성 공간(feature spaces›)이 잘 정렬되어야 한다.
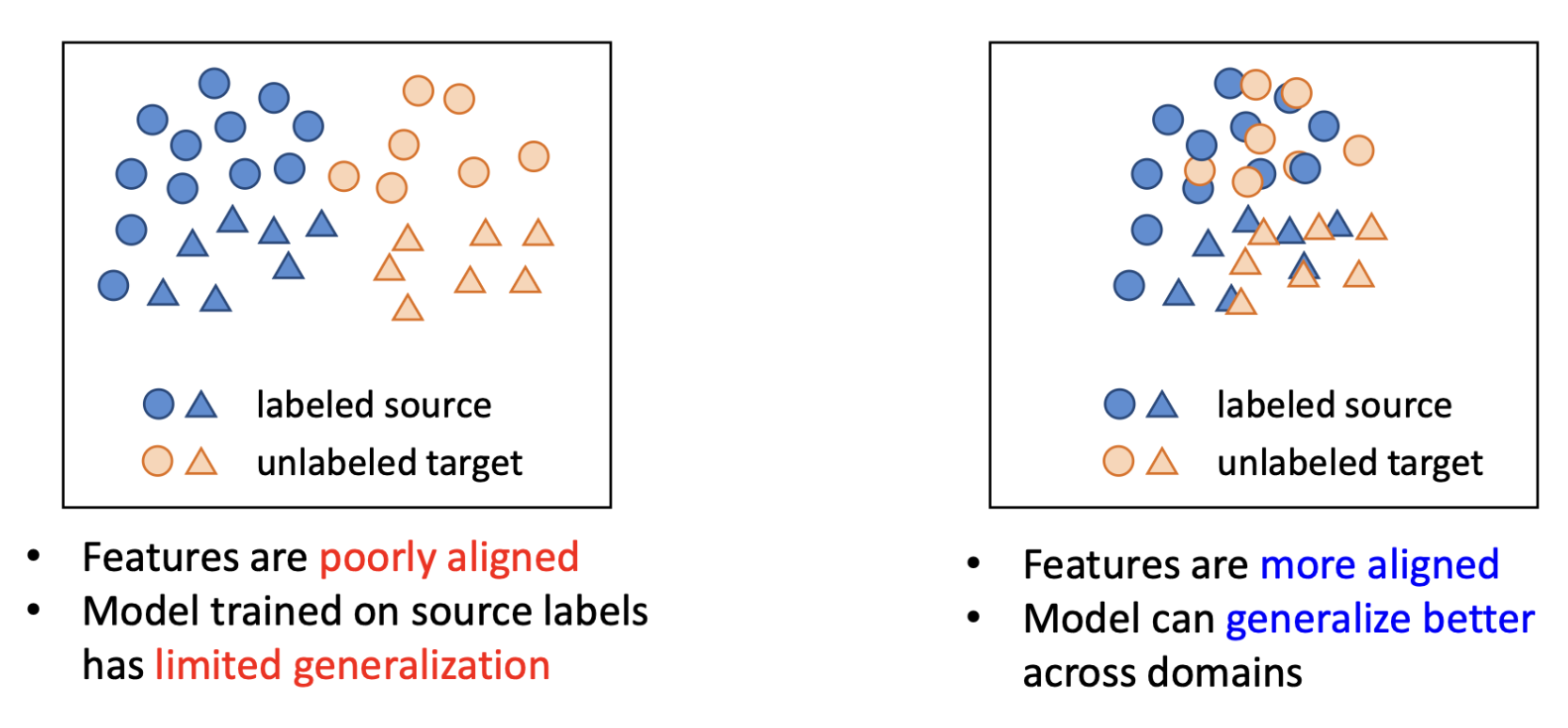
특징(feature)들이 더 잘 정렬되어 있을수록 도메인 간에서 더 나은 일반화가 가능함. 두 도메인 간의 특징 분포를 명시적으로 정렬하도록 모델 학습시키기 위한 방법이 없을까? --> 적대적 학습 (Adversarial learning 등장)
적대적 학습 (Adversarial learning)
중간층(intermediate layer)의 출력(output)에 인코딩 된 정보는
- 학습된 특징(learned features)으로 원시 입력 특징을 기반으로 구축됨
- 이들은 모델이 손실을 최소화 하도록 돕는 정보를 인코딩함
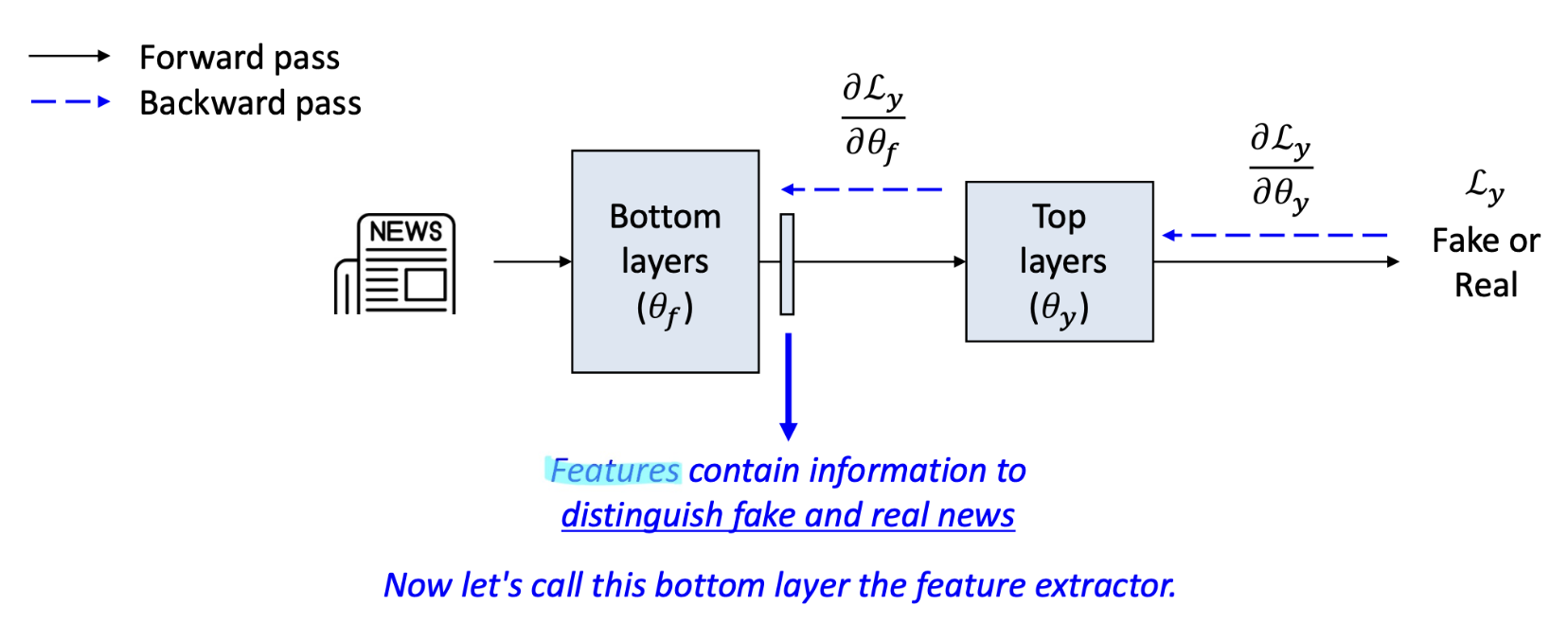
features 는 가짜 뉴스와 진짜 뉴스를 구별하는 정보를 포함함
여기서 이 하위계층(bottom layer) = 특징 추출기(feature extractor)
도메인 분류 과제(domain classification task)와 함께 다중 과제 학습(multi-task learning)을 적용한다면 어떨까? - 과제 1(Task 1) : 가짜 vs 진짜 분류(주요과제, main task)
- 과제 2(Task 2) : 소스 vs 타깃 분류(도메인과제, damain task)
특징(Features)은 가짜 뉴스와 진짜 뉴스를 구별할 뿐 아니라, 소스와 타깃 도메인도 구분할 수 있는 정보를 포함한다.
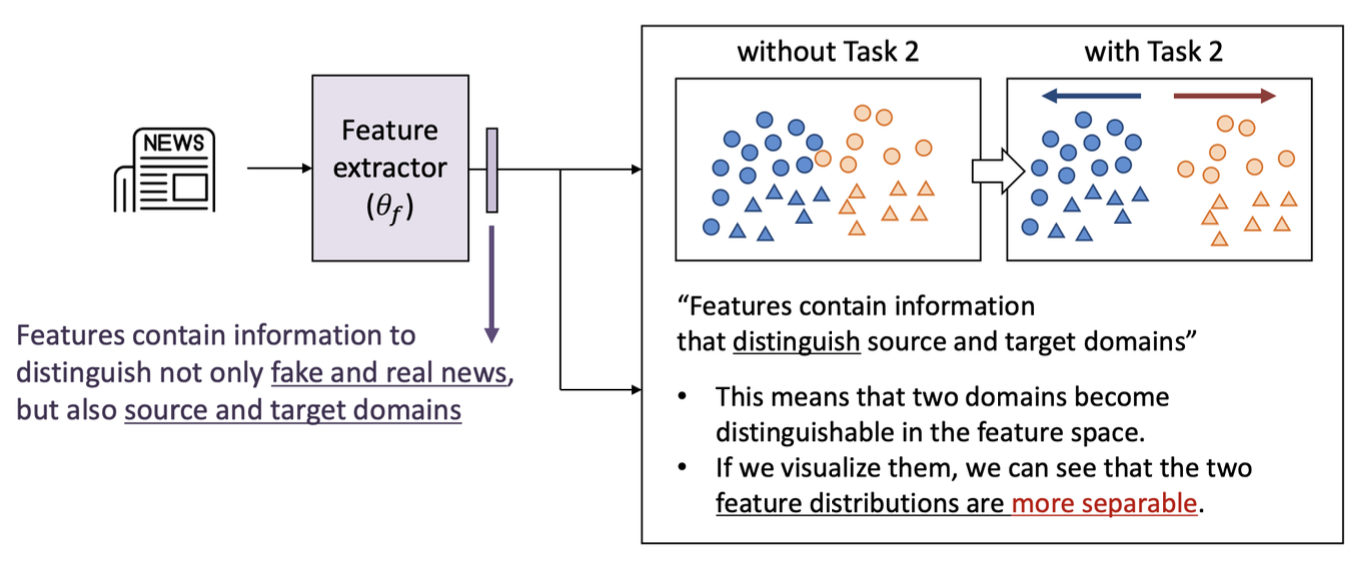
특징들은 소스와 타깃 도메인을 구분하는 정보를 포함하며, 이는 두 도메인이 특정공간(feature space)에서 구분이 가능해진다는 것을 의미한다. 시각화 했을때, Features를 포함한 정보가 두 도메인의 특징분포가 덜 분리되어 있음을 확인 할 수 있음
그래디언트 반전 (Adversarial learning : gradient reversal)
- 이 매커니즘은 그래디언트 반전 층(Gradient Reversal Layer, GRL)이라고 불린다.
- GRL은 도메인 분류기(domain classifier)로부터의 그래디언트를 반전시켜 하위계층이 도메인을 구별하지 못하는 특징 즉, 도메인 불변 특징을 생성하도록 강제한다.
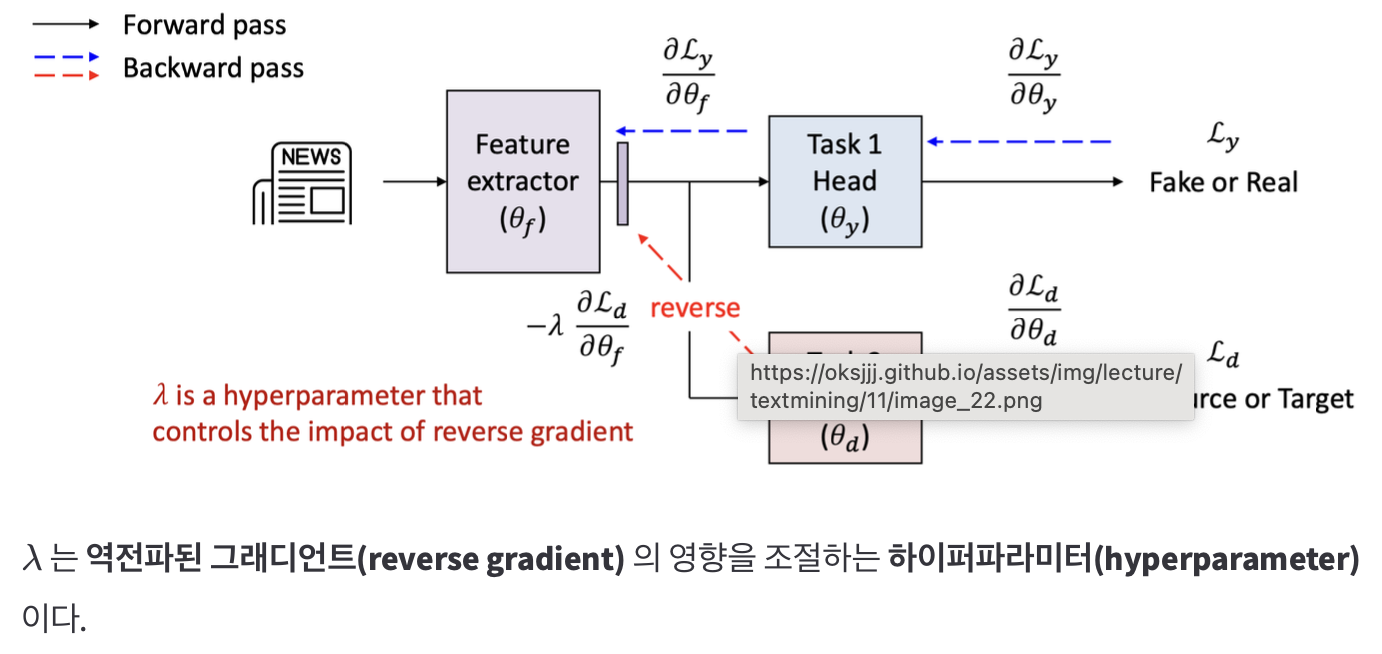
- Forward pass : 아무 일도 안함
- Backward pass : Domain classifier에서 오는 gradient의 부호를 반전
즉, Domain classifier는 여전히 Source vs Target을 구분하려고 학습
Feature extractor는 Domain classifier를 헷갈리게 만드는 방향으로 학습
-> 결과적으로 domain-invariant features 학습
Loss 함수
-
Label loss : Ly(f,g)
-
Domain loss : Ld(f,d)
전체 objective :
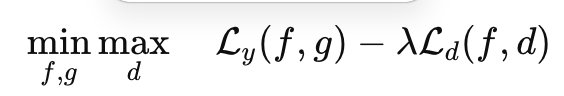
λ: domain confusion의 강도 조절 hyperparameter -
Feature extractor : domain loss 최대화
-
Domain classifier : domain loss 최소화
왜 그냥 domain loss 를 최대화 하면 안되는가?
- Domain classifier가 망가짐
- Feature extractor가 trivial solution으로 수렴
ex) 모든 feature가 0으로 출력 - -> label task까지 망가짐
결국 GRL은 Domain classifier는 정상학습, Feature extractor만 "속이도록" 업데이트
Adversarial Learning의 장단점
장점
- Feature space 자체를 align
- Source-Target overlap이 작아도 효과적
- 기존 모델에 GRL만 추가하면 적용 가능
단점
- Global alignment
* 클래스 구조 무시- 서로 다른 클래스가 섞일 위험
- 후속 연구에서는 class-aware alignment가 등장
