BERT : Bidirectional Encoder Representations from Transformers
Transformer encoder를 여러 층 쌓아 정교한 contextual embedding을 생성
BERT-base(12 layers, 110 million params) BERT-large(24 layers, 340 million params)
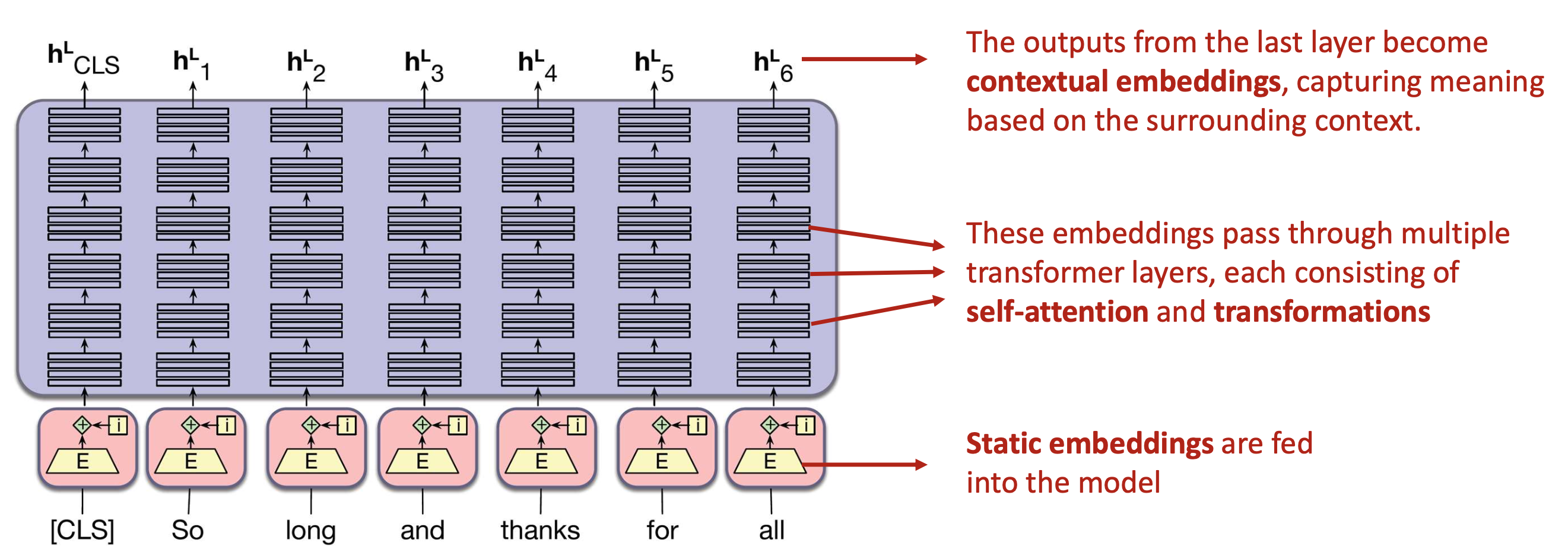
- 문장을 토크나이즈해 단어 ID로 변환
- ID를 embedding table에서 static embedding으로 변환
- Transformer layers를 통과하며 contextual embedding 생성 -> Self-attention과 transformations를 포함하는 transformer layers를 겹겹이 쌓아 통과시킨다.
Self-attention : 단어가 주변 단어들로부터 어떤 정보를 얼마나 가져올지 결정하는 메커니즘
Transformer Encoder : self-attention을 여러 층 쌓아 문맥 정보를 점진적으로 강화
BERT 의 학습 목표 (Pretraining Objectives)
1) MLM(Masked Language Modeling)
- 15% 토큰을 [MASK]로 가리고 원래 단어를 예측
- 모델은 양방향 문맥 전체를 활용해 단어 의미를 추론하게 됨
- 마지막 layer의 은닉벡터와 vocab embedding의 내적으로 확률계산(weight-tying)
2) NSP (Next Sentence Prediction)
- 문장 A 뒤에 문장 B가 실제 다음 문장인지 예측
- 문장 간 연결성(coherence) 학습
- [CLS] 토큰의 벡터를 sentence-level classification에 활용
BERT = MLM + NSP 로 사전학습한 강력한 contextual representation 모델 -> 텍스트 의미를 정밀하게 반영하는 dense contextual vector를 얻을 수 있음

2KT