이번 여름방학 동안 교내 분산컴퓨팅 및 운영체제 연구실에서 학부 연구생 인턴 활동했다. 거기에서 연구했던 것은 WiscKey 논문을 공부하고, Facebook의 RocksDB에 어떻게 이식을 할 수 있을지 연구하는 것이었다.
WiscKey는 USENIX Conference에서 발표된 논문으로 SSD에서 Key와 Value를 분리하는 LSM Tree를 기반으로 한 Key-Value Store의 개념을 설명한다.
LSM Tree
WiscKey에 대해 알아보기 앞서 LSM Tree는 무엇인지에 대해 알아야 한다.
LSM Tree의 구조
LSM Tree는 Log-Structured Merge Tree의 약자로, Bitcask, MongoDB, Bigtable, Cassandra, InfluxDB및 SQLite4와 같은 최신 관계형 및 비관계형 데이터베이스에서 사용하고 있는 인기있는 데이터 구조이다.

LSM Tree는 위의 그림과 같은 구조를 갖는다.
Component 중 C0은 im-memory의 자료구조로 update-in-place sorted tree로 이루어져있다. 그 외의 Component C1~Ck는 on-disk이며 append-only B-tree이다.
LSM Tree에서의 쿼리 연산 과정
1. Lookup (Search)
Component C0이 가장 최신의 데이터를 갖고 있고 그 다음에 C1, C2, ... 으로 이어진다. 따라서 어떤 데이터를 찾기 위해서는 다수의 Component를 탐색해야한다.
2. Insertion
한 쌍의 Key-Value를 삽입하는 것은 다음의 과정으로 이루어진다.
1. Key-Value 쌍을 disk에 있는 log file에 먼저 추가한다.
2. 그 쌍을 C0에 추가한 후 Key를 기준으로 정렬한다.
여기에서 C0이 가득차게 되면 어떻게 될까?
이 의문을 해결하기 위한 방법이 바로 Compaction이다.
Compaction 과정
1. Ci이 가득차게 되면 Ci+1와 merge를 한다. 이 과정에서 key를 기준으로 정렬한다. (Merge sort)
2. 이렇게 새로 쓰여진 Component가 이전의 Component를 replace한다.
- 이 과정은 인접한 Component 사이에서만 수행될 수 있고, 백그라운드에서 비동기적으로 수행된다.
Compaction의 알고리즘 상세는 뒤에서 다루도록 하겠다.
LevelDB
앞서 살펴본 LSM Tree를 기반으로 구현된 Key-Value Database의 대표적 예시는 구글이 공개한 LevelDB이다.

LevelDB의 구조는 위의 그림과 같다.
memory에는 2개의 sorted skiplist가 있고(memtable, immutable memtable), on-disk에는 log file와 7개의 level로 이루어진 SSTable(Sorted String Table)이 존재한다.
LevelDB에서의 쿼리 연산 과정
1. Lookup
데이터를 탐색하기 위해서 우선 memory에 있는 2개의 memtable을 먼저 살펴보고, 이후의 각 레벨의 파일들을 살펴본다.
L1~L6까지는 merge sort된 파일들이므로 중복되는 Key값이 없다는 것이 보장되지만,
L0에는 memory에서 그대로 내려온 memtable이어서 중복되는 key가 있을 수 있다. 따라서 L0에서는 여러 개의 파일을 탐색해야한다.
lookup에 소요되는 latency를 줄이기 위해서 foreground에서 진행되는 write(insertion)의 트래픽을 느리게 하는 방법을 사용한다.
2. Insertion
한 쌍의 Key-Value를 삽입하기 위해서 다음과 같은 과정을 거친다.
1. log file에 Key-Value 쌍을 추가한다.
2. memtable에 Key-Value 쌍을 추가한다.
여기에서 memtable이 가득차게 될 경우 기존의 memtable을 immutable memtable로 변경시키고, 기존의 immutable memtable을 SSTable로 만들어 disk의 L0에 flush한다
immutable memtable은 insert를 할 때 flush로 생기는 disk I/O나 compaction 등에 의해 연산이 blocked 되지 않게 하는 역할이 있다.
Compaction Algorithm
LevelDB에서 Compaction은 compaction을 담당하는 thread에 의해 백그라운드에서 수행된다.
- thread가 merge할 파일을 Li에서 하나 선택한다. 그리고 Li+1에서 범위가 겹치는 key가 존재하는 모든 파일을 선택한다. 예를 들어 L2에서 10~30의 key를 갖고 있는 파일을 선택한다. L3에서 10~30의 Key가 들어있는 모든 파일들을 선택한다.
- 선택한 파일들을 merge해서 새로운 Li+1를 구성한다.
- 이 과정을 모든 레벨이 size limits을 충족하도록 반복한다.
- 이 과정에서 merge를 통해 L0을 제외한 모든 파일이 고유한 key 범위를 갖도록 보장한다.
- L0은 immutable memtable으로부터 직접 flush된 파일이다.

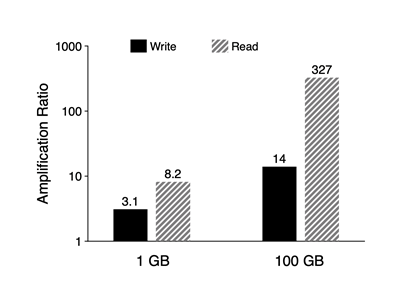
I/O Amplification
I/O amplification은 저장 장치로부터 읽은 또는 쓴 데이터의 양과 실제로 유저에게 요청받은 데이터의 양의 비율을 얘기한다.
예를 들어 4MB의 데이터를 요청 받았을 때, 실제로 읽은 데이터의 양이 16MB라면 Read Amplification은 4이다.
특히 LSM-tree를 기반으로 하는 Key-Value Store에서는 Lookup을 할 때 여러 Component와 여러 파일을 탐색해야하기 때문에 Read Amplification이 기본적으로 높다. 따라서 이를 줄이는 것이 중요한 문제 중 하나이다.
이제 본격적으로 WiscKey에 대해 다룰 텐데 글이 길어져 다음 포스트에서 다루도록 하겠다!
