저번 포스트까지 WiscKey의 기반이 되는 LSM-Tree와 LevelDB에 대해 알아봤다.
이번 포스트에서는 본격적으로 WiscKey가 무엇인지, 어떻게 동작하는지 알아보도록 하겠다.
WiscKey
WiscKey가 탄생한 배경은 LevelDB가 SSD보다 HDD에 더욱 특화되어 있어, SSD의 기기 대역폭을 충분히 활요하지 못하고 있었다는 점이다.
Critical Ideas
- Key를 Value로부터 분리해서 저장한다.
- 정렬되지 않은 Value를 위해 SSD의 병렬 Random Read를 적극 활용한다.
- 고유의 Crash-consistency와 GC 기술을 사용한다.
- LSM-tree의 로그를 제거해 최적화한다.
Design Goals
위의 아이디어를 통해 얻고자 하는 목표는 다음과 같다.
- Write Amplification을 낮게 한다.
- Read Amplification을 낮게 한다.
- I/O 패턴을 SSD의 특성에 맞춰 최적화한다.
- 현대적인 특징을 지원하는 API를 갖도록 한다.
- Key와 Value의 현실적인 크기에 맞춰 높은 성능을 낼 수 있도록 한다.
1번부터 살펴보면 SSD가 HDD에 비해 높은 대역폭을 갖고 있지만, 큰 WA(Write Amplification)은 대역폭을 낭비하고 SSD의 수명을 감축시킬 수 있다.
2번은 Read의 양이 필요보다 많아지면 그만큼 throughput이 감소하게 된다. 그만큼 caching되는 양이 많아지는 것이므로 cache의 효율성이 떨어진다.
3번은 SSD가 Sequential Read와 Parallel Random Read에 특화되어 있어 그 특성에 패턴을 맞추도록 한다.
4번은 Range Query나 Snapshot과 같은 현대적 특징을 지원하도록 해야한다.
5번은 보통 Key는 16바이트 정도로 작은 크기를 갖는 반면 Value는 상황에 따라 다양한 크기를 갖는다는 것이다.
Key와 Value의 분리
LSM-tree에서 가장 크게 비용이 소모되는 부분은, Compaction을 할 때 SSTable을 항상 정렬하는 것이다.
여기에서 Key와 Value를 모두 담고 있는 SSTable을 정렬하기보다, 작은 크기의 Key만을 정렬한다면 정렬하는 동안 읽어들이는 데이터의 양이 줄게 될 것이다.
따라서 LevelDB에 비해 작은 크기의 LSM-tree를 갖게 될 텐데, 가벼이 말한 이 내용은
- 큰 Value의 크기를 갖는 현대의 workload에 대해 WA도 줄어듦
- WA가 줄어 SSD의 수명이 늘어남
- RA가 줄어들어 Lookup 성능이 좋아짐
의 이점을 갖는다.
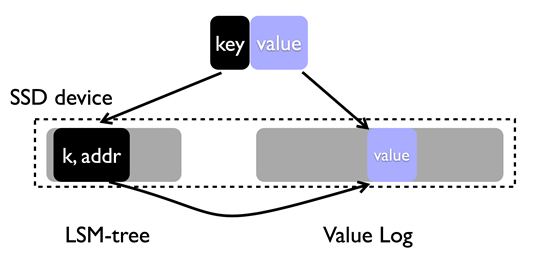
Key가 Value에서 분리된 WiscKey는 위와 같은 구조를 갖는다.
LSM-tree에는 Key와 Value를 가리키는 주소가 함께 저장된다.
Lookup
LSM-tree에서 Key와 Value를 찾고 찾았다면 그 주소로 찾아가 Value를 읽는다. 이 과정에서 Value를 얻기 위해 단 한번의 Random Read가 발생한다.
Insert
먼저 Value를 Value Log인 vLog에 추가한다. 그 추가한 vLog에서의 주소를 LSM-tree에 Key와 함께 삽입한다.
Delete
Delete를 할 때에는 vLog는 건들지 않고, LSM-tree에서 Key만을 제거한다.
LSM-tree에는 valid한 value를 담은 key만이 존재하게 된다. vLog에서 이 Key들에 해당하지 않는 invalid한 value는 이후에 다룰 GC에 의해 수거된다.
Challenges
Key와 Value를 분리하게 되면 몇가지 해결해야할 문제점이 생긴다.
- Range Query의 해결
- 새로운 GC 알고리즘과 crash consistency의 개선
- Lookup이 한 번의 Random Read를 발생시키지만 그것이 Range Query가 된다면 여러번의 Random Read가 발생할 것이다.
- Key만을 LSM-tree에 저장하기 때문에 Delete를 한 이후에 Value는 어떻게 따로 관리할지 결정해야 한다. crash에 대해서도 한 번에 Key와 Value를 저장하는 것이 아니므로 중간에 crash가 발생할 경우의 대처를 고민해야한다.
Range Query
LevelDB에서는 Range query를 요청받아도 Key와 Value를 sequential하게 읽어들일 수 있다.
반면 WiscKey에서는 Range query는 그에 상응하는 많은 Random Read가 발생하게 된다.
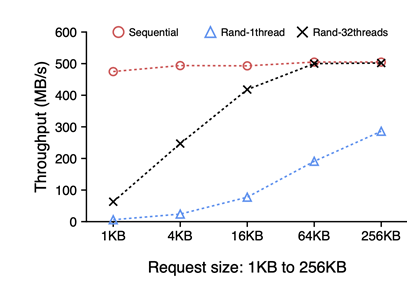
이를 위해 SSD의 Random Read를 활용한다. 위의 그래프를 보면 Random Read의 성능이 32개의 쓰레드를 사용해서 sequential read와 견줄 정도가 된다는 점을 알 수 있다.
이걸 어디에 활용하는가 하면 WiscKey는 Key는 매우 효율적으로 읽어올 수 있어서 Value를 읽어오는데에 이걸 활용한다. SSD의 Random Read 쓰레드는 백그라운드에서 동작해서 vLog로부터 Value를 미리 읽어온다.(prefetch)
그럼 어떻게 value를 "미리" 읽어올 수 있을까?
- WiscKey는 rnage query가 요청될 때 생성한 iterator에 Next() 또는 Prev() 함수를 통해 access pattern을 추적한다.
- 연속된 sequence가 요청되었다는 걸 확인하면, 좀 더 많은 key들을 sequential하게 읽어들이고 거기에 해당하는 value의 주소를 queue에 넣는다.
- 쓰레드들이 백그라운드에서 queue에 있는 주소로부터 value를 읽어들인다.
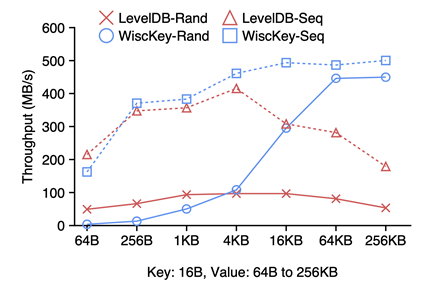
쓰레드를 통한 병렬 Read와 백그라운드에서 수행한다는 점은 많은 Random Read에도 성능 저하를 불러일으키지 않는데, 그 결과가 아래와 같다.
Garbage Collection
LSM-tree를 기반으로 한 Key-Value Store에서는 compaction 중에 사용되었던 공간이 다시 회수된다. WiscKey에서는 value를 compaction하지 않기 때문에 새로운 GC 알고리즘이 필요하다.
나이브하게 생각해보면,
- LSM-tree 전체를 스캔해서 valid한 value의 주소를 얻는다.
- invalid한 주소의 경우 회수한다.
라는 방법을 통해 GC를 수행할 수 있다. 하지만 LSM-tree 전체를 스캔하는 건 아무래도 비효율적이다.
이를 개선하기 위해 vLog에 key를 같이 저장하도록 바꾼다. 그러면 vLog의 저장되는 튜플은
(Ksize, Vsize, Key, Size) 와 같은 형태가 된다.
이렇게 바꾸더라도 결국 LSM-tree 대신에 vLog 전체를 스캔해야 되는 것으로 변경되었을 뿐, 비효율적인건 매한가지다.
포인터의 추가
vLog에서 valid한 값을 한 곳에 모아서 관리하기 위해 두개의 포인터를 추가한다.
head : 새로운 value가 추가되는 지점을 가리킨다.
tail : Garbage Collector의 시작점을 가리킨다.

여기에서 head ~ tail 구간에 있는 value들은 모두 valid하다. 포인터가 추가된 GC의 알고리즘은 다음과 같다.
- tail로부터 Key-Value 쌍들을 chunk 단위로 읽어들인다.
- valid한 value는 다시 head에 추가한다.
- 읽었던 Key-Value 쌍의 chunk의 공간을 free하고 tail을 업데이트한다.
이 과정을 반복하다보면 head에 다시 추가되지 못한 invalid한 value들은 자연스럽게 그 공간이 free될 것이다.
또 다음의 과정으로 GC 도중에 crash가 발생할 경우를 대비한다.
- value를 head에 추가하면, vLog에 대해 fsync()를 호출한다.
- fsync() : 지정된 파일과 관련된 모든 변경 자료(데이터 + 메타데이터)를 디스크와 동기화한다.
- 따라서 LSM-tree에 업데이트된 tail과 새로운 value의 주소가 저장된다.
Crash Consistency
기존 LSM-tree에서는 삽입된 Key-Value 쌍에 대한 원자성이 보장되었지만, WiscKey에서는 Key와 Value의 분리로 새로운 방법이 필요하다.
이를 위해 파일시스템에서 사용되는 방법을 차용한다.
아래의 그림을 보자.

b1~n의 데이터에 bn+1 ~ bn+m의 데이터를 저장하려고 한다. 이 떄 bn+x까지 저장을 하다가 crash가 발생한 경우 bn+1~bn+x만이 추가되어 저장될 것이다.
임의의 부분집합인 bn+10~bn+x만 저장된다거나 이런 일은 발생할 수 없다. 한 마디로 추가하려는 데이터의 prefix만이 저장된다는 것이다.
이를 WiscKey에 대입해 생각해보면 value X를 저장하던 도중 crash가 발생한다면, X 이후의 value들은 저장되면 안된다.
Optimization
WiscKey를 최적화하기 위한 몇 가지 방법들이 있다.
Value-Log Write Buffer
insert를 하기 위한 Put()이 호출될 때마다 WiscKey는 write() 시스템 콜을 통해 Key-Value를 저장할 것이다.
insert가 많은 workload에서는 그만큼 시스템 콜이 많이 호출될 것이고, 이는 곧 오버헤드가 된다.

위의 그래프는 write()의 단위 크기에 따른 소요 시간에 대한 그래프이다. 단위 크기가 작을 수록 시간이 더 많이 소요된다는 걸 알 수 있다. 하지만 어떤 크기의 value가 insert될지 알 수 없기 때문에 오버헤드를 줄이기 위해 Write Buffer를 사용한다.
이 Write Buffer의 크기가 가득 차면 write()을 통해 flush한다.
Lookup 연산에도 조금 변화가 생기는데, value가 flush되기 전에 탐색을 하려할 수 있으므로 buffer를 먼저 확인하고 vLog를 탐색한다.
LSM-tree log
WiscKey에서 LSM-tree는 Key와 value의 주소만을 저장하고 있다. 또 vLog는 GC를 위해 대응되는 key도 함께 저장하고 있다. 때문에 기존의 LSM-tree에서 사용되던 log 파일에 더이상 무언가를 쓸 필요가 없게 되었다.
crash는 vLog를 스캔해서 recover할 수 있다. 효율적인 스캔을 위해 head 또한 LSM-tree에 저장한다. head ~ tail 구간을 스캔할 텐데 삽입된 순서대로 저장되므로 이 순서대로 recover될 것도 보장된다.
Trade-Off
이제 Sequential Write 뿐만 아니라 SSD의 32개의 쓰레드가 저장된 쓰레드풀을 사용해 Random Write의 성능도 LevelDB보다 앞선다. 또 LSM-tree의 크기가 LevelDB에 비해 현저히 작으므로 I/O amplification 또한 훨씬 낮다.
하지만 LevelDB에서는 Compaction을 통한 정렬과 GC가 동시에 일어나는 반면 WiscKey에서는 GC가 나중에 일어난다. 따라서 invalid한 value더라도 한 동안은 저장되어 있게 된다. 그러면 저장하려는 데이터의 양보다 저장되어 있는 데이터의 양이 더 많게 된다.
즉, Space amplification이 1보다 크게 된다.

모든 면에서 완벽한 Store를 설계할 순 없기에 성능에 직결된 I/O amplification 대신 Space amplification을 희생한 것이다.
마무리
길었던 WiscKey 논문 리뷰가 끝났다. 다음 포스트부터는 RocksDB에서 Put, 즉 Write의 과정이 어떻게 되는지 살펴보고 어떻게 WiscKey를 적용할 수 있을지에 대해 얘기해보겠다.
