이전에는 픽셀의 평균값을 구해서 구별했다.
하지만 이것은 우리가 과일의 종류를 이미 알고 있는 상태이기 때문에 가능했다.
만약 사진이 있는데 어떤 사진인지 모르는 상태에서 구별하려고 한다면 어떻게 해야 할까
이럴때 k-평균 군집 알고리즘을 사용한다.
이 평균값이 클러스터의 중심에 있기 때문에 클러스터 중심, 센트로이드라고도 한다.
K-평균 알고리즘
- 무작위로 k개의 클러스터 중심을 정한다.
- 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
- 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
- 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복한다.
import numpy as np
from sklearn.cluster import KMeans
fruits = np.load('datas/fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_2d)
print(np.unique(km.labels_, return_counts=True))
# (array([0, 1, 2], dtype=int32), array([112, 98, 90]))각각의 레이블에 112개, 98개, 90개가 들어있다.
클러스터 중심
K-Means로 나온 클러스트 중심은 cluster_centers_ 속성에 저장되어있다.
draw_fruits(km.cluster_centers_.reshape(-1, 100, 100), ratio=3)최적의 K 찾기
k값을 변경하면서 최적의 k를 찾아보자
inertia= []
for k in range(2, 7):
km = KMeans(n_clusters=k, n_init='auto', random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_)
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()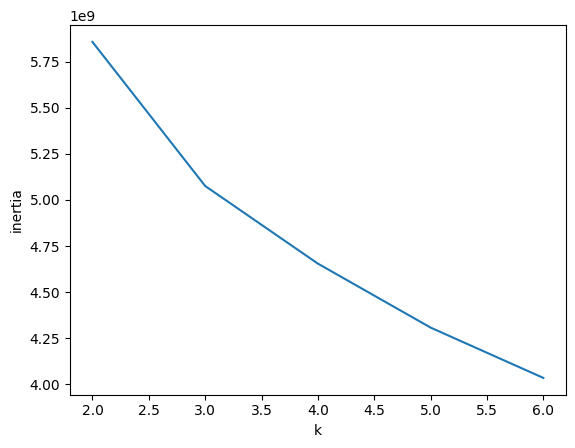
점점 내려가기는 하지만 제일 급격하게 꺽이는 부분이 3인 것을 알 수 있다.

코딩 공부하는 사람