비지도 학습
지도 학습과 비지도 학습의 차이는 타깃값이 있는지 없는지다.
있으면 지도 학습, 없으면 비지도 학습이다.
과일 이미지
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
fruits = np.load('datas/fruits_300.npy')
print(fruits.shape)
# (300, 100, 100)
# 첫 번째 행에 있는 픽셀 100개
# 100x100 사진이 300개 있음
print(fruits[0, 0, :])
"""
[ 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1
2 2 2 2 2 2 1 1 1 1 1 1 1 1 2 3 2 1
2 1 1 1 1 2 1 3 2 1 3 1 4 1 2 5 5 5
19 148 192 117 28 1 1 2 1 4 1 1 3 1 1 1 1 1
2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1]
"""
# 첫 번째 사진, 흑백 출력
plt.imshow(fruits[0], cmap='gray')
plt.show()0일수록 검은색에 가깝다.
cmap='gray'값을 cmap='gray_r'로 변경하면 색이 반전된다.
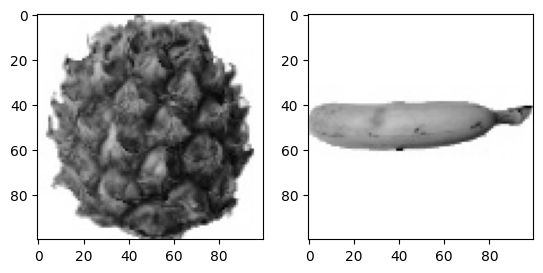
이대로 포도화 바나나도 출력한다.
그리고 2차원 배열로 되어있는 데이터를 1차원으로 변경한다.
apple = fruits[:100].reshape(-1, 100*100)
pineapple = fruits[100:200].reshape(-1, 100*100)
banana = fruits[200:300].reshape(-1, 100*100)
print(apple.shape)
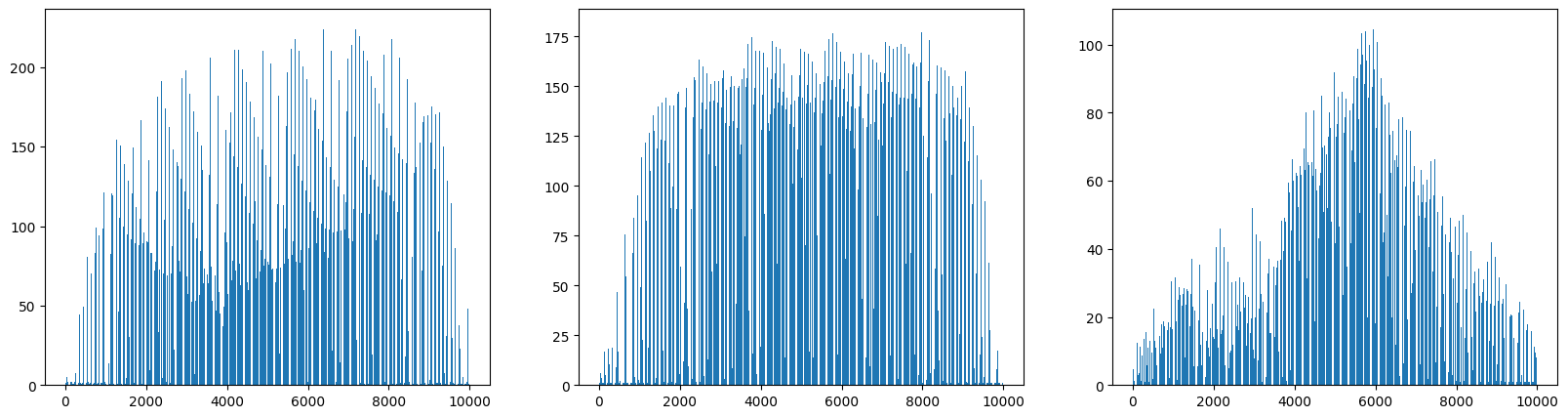
# (100, 10000)그리고 열을 따라서 평균값을 내어 그래프로 그리면 아래와 같이 나온다.
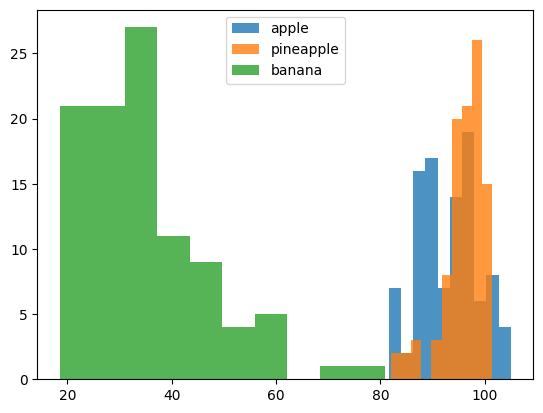
바나나는 40을 기준으로 분포되어있고 사과와 파인애플은 90~100 사이에 집중되어있다.
바나나는 확실히 구별되는 모습이다.
그리고 이번에는 전체 샘플에 대해서 필셀의 평균값을 계산했다.
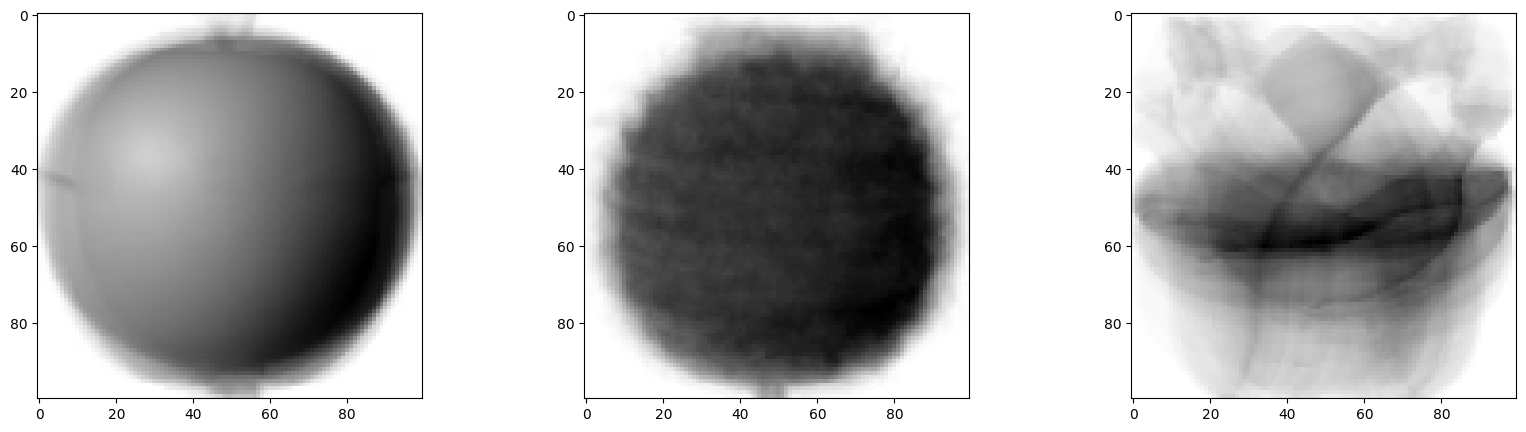
왼쪽부터 사과, 파인애플, 바나나다.
바나나는 확실히 중앙의 픽셀값이 높고, 파인애플은 사과에 비해 비교적 높은 것을 알 수 있다.
이번에는 과일별 이미지를 겹쳐보았다.
사과 사진 평균값과 가장 가까운 사진을 골랐다.
abs() 함수를 통해 절대값을 계산하고 평균을 구한다.
그리고 그 값을 기준으로 정렬해서 100개를 출력했다.

전부 사과만 골랐다.

코딩 공부하는 사람