Clustering 관련 공부를 했다.
이와 관련한 다양한 용어들을 익히고, 직접 실습을 해보았다. 그 내용을 정리하고자 포스팅한다.
- Definition and Purpose of Clustering
- Implement of K-means Clustering
-정규화(Normalization/Standardization)
-PCA(Principal Component Analysis)
-K-means Clustering
-Visualization
-Practice to figure out some meaning from the output
Clustering이란?
머신러닝 비지도학습(Unsupervised Learning)에 속하며, 비슷한 데이터끼리 '군집'을 만든다. 대표적으로 K-means와 Hierarchical clustering이 있다.
Train data에 대한 특정 label이 없고, 결과 값이 PCA처럼 dataset에서 어떤 축을 의미하는지 알 수 없다. 그래서 정확도가 떨어지기에 대부분 EDA에서 많이 사용한다. linkkage(simple, average, complete 등)나 Distance Matrix 등 Clustering을 깊게 파고들면 끝도없기 때문에 deep한 부분은 생략하고, 실습에 focus를 맞추도록 한다.
K-means Clustering
K-means clustering이란 현재 가장 대중적으로 사용되는 clustering 방법 중 하나로, 특정한 centroid 개수를 설정하면 해당 수로 군집을 만들어준다. 여기서 K는 각 군집의 중심(centroid)의 개수를 나타내며, means는 말 그대로 평균을 얘기해서 '평균 군집화'라고 한다. python에서는 sklearn package로 단번에 사용이 가능하다.
Seaborn에서 제공한 'Penguin' dataset을 이용해 군집을 실행 해보겠다.
import pandas as pd
import numpy as np
import seaborn as sns
df = sns.load_dataset('penguins') # 펭귄 dataset load
df
df.dropna(inplace=True) #df의 결측치들은 행째로 제거 (inplace=True를 통해 즉시 데이터에 적용)
df_num = df[['bill_length_mm','bill_depth_mm','flipper_length_mm','body_mass_g']] # df_num 변수에 numerical column만 저장
dataset 불러오기 + clustering을 위한 조정
불러온 뒤, dataset 내의 numerical한 data들에 대해서만 진행할 것이므로 나머지는 따로 분류 해준다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() # 표준화를 하기 위한 StandardScaler를 scaler변수에 넣는다
scaler.fit(df_num) # numerical data만 뽑았던 df_num dataset에 해당 scaler를 적용시킨다.
df_s = scaler.transform(df_num) # StandardScaler가 적용된 df_num을 해당 scalar대로 변환한다.
df_s = pd.DataFrame(df_s, index = df_num.index, columns=df_num.columns) # 변환된 데이터셋은 수치화 되어있으므로 데이터프레임화 시켜준다.
df_s

데이터의 표준화(Standardize) 진행
Dataset의 모든 data들이 우리가 모델에 맞춰 진행하도록 예쁘게 갖춰져 있지는 않다. 큰 차이가 없는 경우를 제외하고는 StandardScalar를 사용하여 Data를 비교하기 좋게 정리를 해준다.
이전 결과와 다르게 모든 Feature들이 단위와 관계없이 비교 가능한 정도의 크기로 변경 되었다.

from sklearn.decomposition import PCA # sklearn 라이브러리의 PCA를 import한다
pca = PCA(n_components = 2) # 2차원으로 시각화를 진행할 것이므로 2개로 설정한다.
pca.fit(df_s)
df_p = pca.transform(df_s)
df_p = pd.DataFrame(df_p, columns = ['PC1','PC2']) #PCA진행 한 두 개의 값을 column으로 데이터프레임화 시킨다.
df_p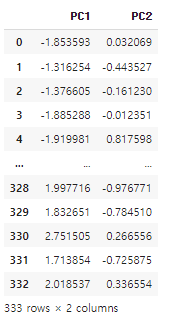
주성분 분석(PCA)으로 차원축소 진행.
Feature개수를 차원으로 본다면, dataset은 4차원이므로 clustering 시각화가 불가능하다. 이럴 때 다양한 방법으로 차원을 축소하여 볼 수 있는데, 이번에는 PCA를 이용해 2차원 평면으로 진행해볼 것이다.
선택한 data들의 분산치가 가장 큰 두 개의 축을 찾아 좀 더 유의미한 분석을 할 수 있기 때문에 pca로 진행한다.
from sklearn.cluster import KMeans # KMeans 라이브러리를 불러온다.
sum_of_squared_distance = [] # k의 개수를 구하기 위한 엘보우 메소드의 요소를 넣을 list 변수 생성
K = range(1,10) # 9개만 구해본다.
for k in K: # 1부터 9까지의 for문 반복을 통해 각 Kmeans의 군집을 몇개까지 하면 될지 측정한다.
km = KMeans(n_clusters = k) # KMeans 함수의 설정 - n_clusters = 군집의 개수(정확히는 군집의 centroid 개수이다)
km = km.fit(df_p) # 해당 군집중앙의 개수를 정규화(표준화) 해놓은 df_p data에 적용
sum_of_squared_distance.append(km.inertia_) # inertia_함수를 이용해 군집간 거리가 최소가 되는 k를 누적하여 파악한다.군집의 개수(정확히는 군집의 중심이 될 점 centroid의 개수)를 정한다.
K-Means를 사용하기 위해선 centroid의 개수 k를 먼저 찾아야 한다. 어떤 산업군에서든지 도메인 지식이 뛰어나다면 해당 지식을 바탕으로 개수를 정하는것이 훨씬 더 바람직하지만, 그렇지 않은 경우데는 적당한 k값을 찾는 것이 중요하다.
import matplotlib.pyplot as plt # 그래프를 그리기 matplotlib 라이브러리를 사용한다.
plt.plot(sum_of_squared_distance, '-bx') # (default = line) plot을 그리고, 컬러를 blue, 포인터를 x로 놓는다.
plt.xlabel('k') # x축은 k로 지정
plt.ylabel('sum of squared distance') # y축엔 거리제곱합의 이름
plt.title('Elbow Method for getting k value') # 제목도 변경한다.
plt.show() # 플롯을 그려본다
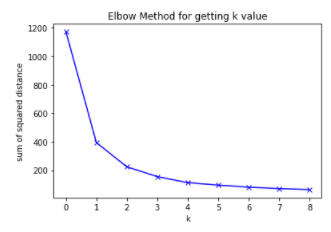
시각화를 통한 k 값 결정 - Elbow Method
그대로 수치상으로 봐도 진행 가능하지만, 좀 더 편하게 확인하기 위해 Elbow Method를 사용한다. 이름 그대로 팔꿈치처럼 생겼으며, 완만해지기 전까지가 유의미한 데이터들이라 판단하여 해당 수 만큼 k를 둔다. 위 그래프를 보아 3개까지는 만들어도 괜찮을 것으로 보이므로 k =3을 넣어보도록 한다.
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(df_p)
label = kmeans.labels_
label = pd.Series(label)
df_p['label'] = label.values
df_p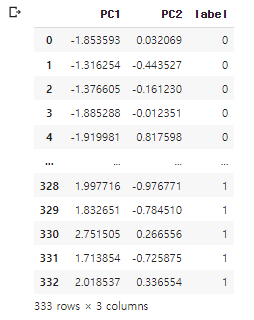
구한 k값을 바탕으로 K-Means 진행하기
PCA로 구한 PC1과 PC2 값이 들어있는 dataframe df_p에 k-means의 value를 label 열로 만들어 붙여 넣었다. 그럼이제 준비 완료되었으니 scatter plot으로 한번 보도록 한다.
import seaborn as sns # 시각화에 발달된 seaborn 라이브러리를 import한다.
sns.scatterplot(data = df_p, x = 'PC1',y = 'PC2', hue = 'label'); 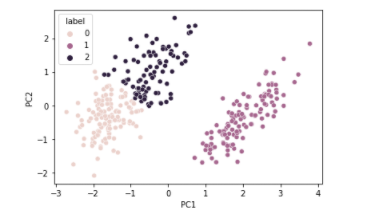
SCATTER PLOT으로 군집형성 시각화하여 확인하기
군집(n_clusters = 3)으로 진행하여 시각화한 scatter plot이다. 그래프를 보면 1번 군집이 완전히 차이가 있고, 0번,2번 군집은 나뉘어져있지만 1번에 비해 가깝게 모여있는 것으로 보인다. 정확히 어떤 feature 또는 data가 군집한지 알수 없지만, data들의 군집에 저러한 규칙성과 연관성이 있음을 파악한다.
'species'라는 Feature가 유사할 것 같으므로 한번 검토(?)차원에서 대입해보도록 한다.
df_p['species'] = df['species'].values # 기존 df의 species feature를 df_p에 추가한다.
sns.scatterplot(data = df_p, x = 'PC1',y = 'PC2', hue = 'species'); # scatter plot을 띄운다.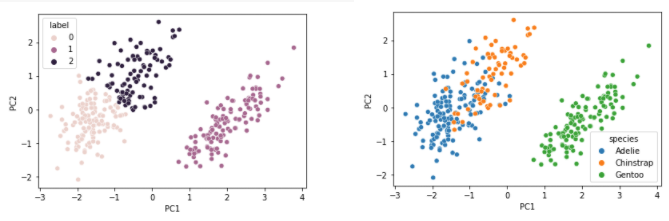
Species로 label을 작성했을때 위에서 k-means로 진행한 label의 군집과 매우 흡사한 것을 볼 수 있다. 당연하겠지만, 이는 여러 데이터들의 군집이 나름대로 종 별로 나눠져 있음을 볼 수 있는 실습이였다.
K-means Clustering을 통해 군집을 만들고 이를 분석해봤는데, 사실상 Penguin data는 굉장히 처리가 잘~ 되어있는 dataset이기 때문에 앞으로 주변의 다양한 data를 접목해서 분석해 업로드 해보도록 하겠다.
용어정리
지도학습(Supervised Learning)
지도학습이란 주어진 data에 정확한 label이 존재하고, 이에 맞춰 데이터들을 분류, 회귀등의 방법으로 예측모델을 설계 할 수 있도록 한다.
ex) (분류)Data set에서 매출액이 일정 수준 이상인 고객은 'VIP'로 분류한다.
비지도학습(Unsupervised Learning)
비지도학습이란 data에 대한 정확한 label이 존재하지 않은 상태로 데이터셋의 Feature 별 연관성이나 유사성을 파악하고, 단순화 또는 요약에 효율적인 자율학습 형태로 볼 수 있다. Clustering을 위한 내용이지만 추후 비지도학습에 대해 더 연구해서 업데이트 할 것이다. Clustering, Dimensionality Reduction, Assosiation Rule Learning 등이 있다.
ex) (클러스터링) Data set의 다양한 Feature들이 Feature간에 어떠한 규칙성, 특성을 갖고 있는지 파악한다. - 딱히 좋은 예가 떠오르진 않는다..
hard & soft clustering
Clustering에는 다른 관점에서 볼 때도 크게 두 가지로 나눌 수 있다. Hard clustering은 일반적으로 사용하는것으로 한 군집의 데이터는 해당 군집에만 포함되어있는 반면, Soft clustering은 여러 cluster에 속할 수 있다.
ex) 바이오 산업에서 유전자의 경우 다양한 군집에 속할 수 있다.
