데이터셋에 많은 데이터가 있을 경우, 혹은 어떠한 계산을 필요로 할 경우 특정 데이터만 골라 봐야하는 경우가 있다. 원하는 열의 원하는 행만 보고 싶은 경우가 있는데, 이럴 때 유용하게 사용했던 방법들을 기재해보겠다.
import seaborn as sns
df = sns.load_dataset('exercise') # seaborn 제공 오픈 데이터 이용
df # 데이터 프레임 불러오기
우선 이번엔 좀 더 실제 데이터로 사용하는느낌으로 알아보기 위해 seaborn 제공 데이터를 사용한다.
column 선택하기
1. column name으로 선택하기
df['diet'].head() #diet 행만 보고싶은경우 Series 형태로 출력
df[['diet']].head() #diet column만 보고싶은경우 Series > DataFrame로 변경출력
df[['diet','pulse']].head() #diet, pulse column을 선택하기
대괄호를 한번 더 씌워줌으로써 Series로 추출되는 것을 Series의 모음 DataFrame으로 추출되게 할 수 있다.
2. df.columns를 이용해 column 선택하기
df[df.columns[df.columns.isin(['diet','pulse'])]].head()
df[df.columns.difference(['diet','pulse'])].head() # diet와 pulse가 아닌 열만 추출
df[df.columns[~df.columns.isin(['diet','pulse'])]].head() # diet와 pulse가 아닌 열만 추출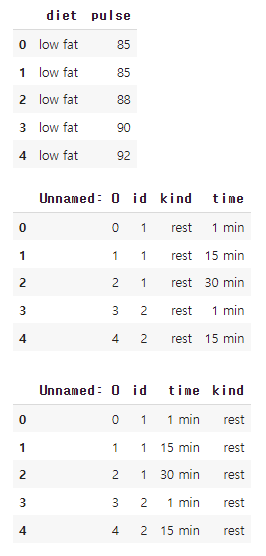
~를 이용한 것은 isin이 '아닌' 열들만 추출하는 방법이다.
3. iloc, loc 이용해 column 선택하기
# iloc을 이용한 column 추출
df.iloc[:,2].head() # 세 번째 column 선택조회
df.iloc[:,2:4].head() # 슬라이싱을 통한 세 번째 ~ 네 번째 column 선택조회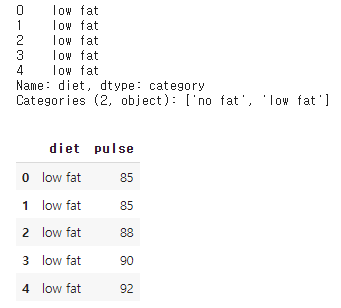
# loc을 이용한 column 추출
df.loc[:,'diet'].head() #diet column 선택 조회
df.loc[:,'diet':].head() #diet column부터 전체 column 조회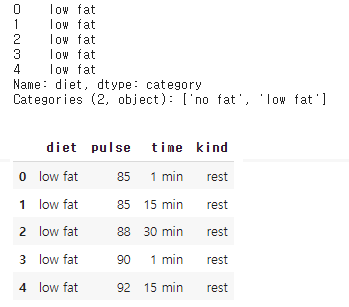
row 선택하기
1. iloc, loc 이용해 row 추출하기
df.iloc[4] # index 상 5번째 행을 추출
df.iloc[4:10] # index 상 5~10번째 행을 추출
2. 특정 열의 조건에 맞는 row만 추출하기
DataFrame column 내 조건부 조회
df[df['diet'] == 'low fat'].head() # diet 열이 'low fat'인 행들만 추출
df[df['pulse'] > 100].head() #pulse 열이 100보다 큰 행들만 추출
df[(df['diet']=='low fat') & (df['pulse'] >100)] # diet 열이 low fat인 행 중에 pulse열이 100 이상인 열만 추출
조건부로 조회를 하고싶을 때에 주로 사용하는 방법이다. 두 가지 조건을 () & () 등으로 묶어서 조회 할 수도 있다.
str.contains를 이용한 포함단어 조회
df[df['diet'].str.contains('low')].head() # diet 열 안에 'low'라는 글자를 포함한 행 추출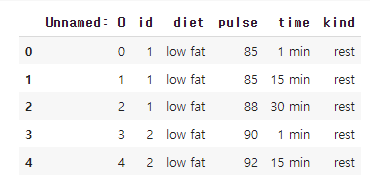
원하는 위치에 어떤 data가 있는지는 정확히 모르지만, 포함된 것을 찾고싶을때 유용하다.
startswith, endswith를 이용한 조회
df[df['diet'].str.startswith('lo')].head() # diet 열 안에 'lo'로 시작하는 행 추출
df[df['diet'].str.endswith('fat')].head() # diet 열 안에 'fat'으로 끝나는 행 추출
3. 특정 열의 특정 행을 다른 값으로 바꾸기

기본 데이터셋 df의 4번행(index상 3으로 기재된 행)의 특정 열에서의 값을 변경한다.
# 두 가지 모두 같은 결과를 나타낸다.
df.at[3, 'pulse'] = 55 # 3번 행의 pulse 열의 값을 55로 바꾼다.
df.loc[3, 'pulse'] = 55 # 3번 행의 pulse 열의 값을 55로 바꾼다.
결과창의 3번 행의 pulse 열을 보면 숫자가 90에서 55로 변경된 것을 볼 수 있다.
단, 주의할 점은 이렇게 변경하는 것은 df dataframe 내 값이 바로 수정적용되는 것을 참고해야한다.
import pandas as pd
df1 = pd.DataFrame({'abc':[1,5,2,6,23,4,76,14],
'def':[91,239,34,1,453,23,1,2],
'ghi':[10,93,2,6,43,7,54,123],
'jkl':[1,2,3,4,5,6,7,8]})
df1 # 데이터프레임 새로 생성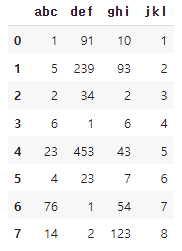
위 데이터셋은 categorical이므로 예시를 들기 번거로워 새로운 간단한 데이터프레임을 하나 새로 생성했다. 그리고 이 중에서 몇 가지 조건에 대한 다른 열의 값을 변경해보겠다.
df1.loc[df1['def'] == 1,'ghi'] = 100 # def 열에서 값이 1인 행의 location 중 ghi 열의 값을 100으로 할당한다.
df1
def열의 1값을 갖고 있는 3번, 6번행의 ghi 열에 있던 값이 각각 6,54에서 100으로 변경된 것을 볼 수 있다. 그렇다면 따로 다른 값을 할당할 순 없을까?
df1.loc[df1['def'] == 1,'ghi'] = 100,50 # def 열에서 값이 1인 행의 location 중 ghi 열의 값을 각각 100과 50으로 할당한다..
df1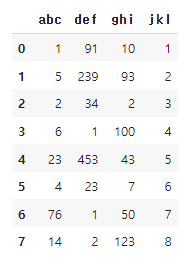
이미지와 같이 가능한 것을 알 수 있다. 단, 수정하고자 하는 데이터의 수를 알 때, 그 모든 값을 할당해줘야 한다.
이렇게 다양한 조건을 두고 조회하는 방법을 이용해서 데이터셋 내 필요한 데이터만 빠르게 조회하고 변경해서 분석을 진행 할 수 있다.
