Linear Regression에 대해 배운 내용을 정리한다.
선형회귀 - Linear Regression
위키백과에서 종속변수 y에 대해 독립변수 X와의 선형 상관 관계를 모델링하는 회귀분석 기법이라고 기재되어있다. 이 때, 독립변수 X는 설명변수라고도 불리우고 다양한 곳에서 설명변수 X의 변화에 따라 달라지는 타겟 즉, 반응변수 y의 변화를 예측하는 기법으로 볼 수 있다.
변수의 표현
선형회귀에서 변수를 다르게 표현하는 경우가 있다.
독립변수 X:
예측변수(predict)
설명변수(Explanatory)
특성(Feature)
종속변수 y:
반응변수(Response)
레이블(Label) - in korean 라벨!
타겟(Target)
이는 이를 표현하는 학문(?)에 따라 다른것 같으나, data science에서 주로 Feature(독립변수)와 Target(종속변수)로 표현한다.
회귀(Regression)와 분류(Classification)
회귀(Regression)는 우선 분류(Classification)와 비교가 되는데, 데이터의 타입이 numerical(연속형)이냐, categorical(범주형)이냐에 따라 달라진다.
대개 범주형(categorical data) 데이터로는 회귀분석이 안되어 분류(classification)를 진행하는데, 이는 아예 불가능한 것은 아니고 one-hot encoding을 통한 변환을 진행하면 가능하다. 하지만 이것은 추후에 다뤄보도록 하고 오늘 포스팅은 회귀에 포커스를 두겠다.
선형회귀의 예시
회귀의 예시로는 아래와 같이 들 수 있다.
- 공부시간(독립변수)에 따른 시험점수(종속변수)
- 기온과 요일(독립변수)에 따른 해수욕장 인원(종속변수)
- 역에서의 거리, 조망(독립변수)에 따른 부동산시세(종속변수)
여기서 포인트는 '독립변수는 여러개가 될 수 있고 종속변수는 하나만 올 수 있다'는 점이다. 다양한 독립변수의 변화에 의한 종속변수의 변화를 설명하는 모델을 설계해 변화를 예측하는 것이 그 궁극적 목적이라고 할 수 있겠다.
단순선형회귀
단순선형회귀와 다중선형회귀로 분류할때, 그 차이는 독립변수 X의 개수이다. 단순선형회귀는 이름 그대로 독립변수 X가 하나뿐인 단순한 선형회귀를 말한다.
단순선형회귀에서의 회귀선에 대한 회귀식의 일반적인 공식은 아래와 같다.
= +
: 예측된 회귀선
: 절편(y intercept라고도 한다.)
: 회귀 계수(slope, 기울기로 볼 수 있다.) - 설명변수 X의 변화에 따라 반응변수 y가 반응하는 정도
회귀 계수가 양수일때, X값이 커지면 y값도 증가하는 선이 생긴다.
반대로 계수 음수일때, X값이 커지면 y값은 감소하는 선이 생긴다.
예측된 회귀선의 의미는 무엇일까?
회귀선은 예측선이라고 얘기할 수 있다. 주어진 변수들의 데이터에 대한 관계분석을 통해 예측값과 관측값의 잔차(Residual)를 최소화해서 최종적으로 가장 잘 맞는 예측을 하도록 하는 선을 의미한다.
대개 기준 모델을 만들고 가중치 학습을 통해 fit하게 만들어가는 과정을 거치게 된다.
이 잔차들의 제곱의 합(RSS - Residual Sum of Squares)을 최소화 하는 선의 의 값을 찾는 것이다.
회귀계수 는 어떻게 구할까?
=
회귀 계수를 구하는 공식은 위와 같다. 값을 평균으로 뺀것과 값을 평균으로 뺀 값을 순차적으로 모두 더한값에서 값에서 의 평균을 뺀 값의 제곱을 모두 더한 값을 나눠준다.
글로쓰니 무슨 말인지를 모르겠으니... 직접 python으로 간단한 데이터를 만들고 시각화를 해본다.
import pandas as pd
import matplotlib.pyplot as plt
X = pd.DataFrame({'x':[1,2,3,4,5], # x 축 데이터
'y':[2,4,5,4,5]}) # y 축 데이터
plt.scatter(X['x'],X['y']) # 그래프를 그린다
plt.grid(None) # 사각 모눈을 그린다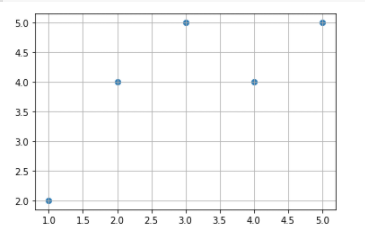
| 1 | 2 |
| 2 | 4 |
| 3 | 5 |
| 4 | 4 |
| 5 | 5 |
위와 같이 x, y에 대한 data가 존재하고, 산점도를 그렸을때, 그 데이터를 바탕으로 잔차제곱합(Residual sum of squares - RSS)이 가장 낮은 선을 긋는 것이 회귀선(Regression line)이 된다.
plt.axhline(y=np.mean(X['y']), color = 'r') # y축의 평균선에 붉은선을 긋는다. y 평균: 4
plt.axvline(x=np.mean(X['x']), color = 'b') # x축의 편균선에 붉은선을 긋는다. x 평균: 3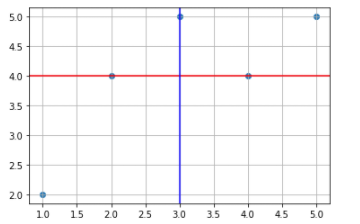
= 값 - 값 평균(3) = - 3
= 값 - 값 평균(4) = - 4
| 1 | 2 | -2 | -2 |
| 2 | 4 | -1 | 0 |
| 3 | 5 | 0 | 1 |
| 4 | 4 | 1 | 0 |
| 5 | 5 | 2 | 1 |
| 평균=3 | 평균=4 |
이렇게 나온 를 제곱하고 모두 합한 뒤, 를 합한 값에서 나눠준다.
| 1 | 2 | -2 | -2 | 4 | 4 |
| 2 | 4 | -1 | 0 | 1 | 0 |
| 3 | 5 | 0 | 1 | 0 | 0 |
| 4 | 4 | 1 | 0 | 1 | 0 |
| 5 | 5 | 2 | 1 | 4 | 2 |
| 평균=3 | 평균=4 | 합=10 | 합=6 |
= 10
= 6
= =
x = X['x'] # x변수에 모집단 X의 x특성을 할당한다.
y = X['y'] # y변수에 모집단 X의 y특성(종속변수)를 할당한다.
m_x = np.mean(X['x']) # m_x 변수에 x의 평균
m_y = np.mean(X['y']) # m_y 변수에 y의 평균
numerator = ((x-m_x)*(y-m_y)).sum() #분자식을 정의하고
denominator = sum(np.square(x-m_x)) #분모도 정의해서
beta1 = numerator / denominator #분자에서 분모를 나눠주면
print('회귀계수 beta1 값은 {0}'.format(beta1)) #베타1 회귀계수 값 0.6 확인위와같이 파이썬 numpy로 회귀계수를 구해보았다.
이렇게 회귀계수 의 값을 0.6으로 찾았으므로, 이에 대한 절편 의 값도 찾아낼 수 있다.
이라는 식에서 에 y의 평균값 4를, 에 의 평균값 3을 대입해서 구할 수 있다. 이를 식으로 표현하면,
4 = + 0.6 * 3
4 - 1.8 =
= 2.2
이므로 절편(y intercept)은 2.2라는 사실을 알 수 있다.
간단한 선형회귀모델을 만들어서 확인해보기
model = LinearRegression() # scikit-learn 라이브러리를 사용한다
model.fit(X[['x']], X[['y']]) # model에 x, y데이터를 학습시킨다.
y_pred = model.predict(X[['x']]) # 학습된 모델에 X데이터를 적용시킨다.
plt.plot(X['x'], y_pred, color = 'c') # X데이터에 대한 예측회귀선을 긋는다.
y_intercept = model.predict([[0]]) # x데이터에 0이 없으므로 0값을 넣어 절편값을 확인한다.
y_intercept[0][0]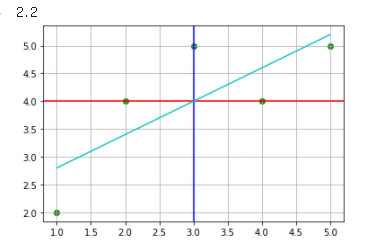
그림과 같이 하늘색 선으로 회귀모델을 그린것을 볼 수 있다. 회귀모델 작성에 대해선 다시 포스팅하도록 하겠다.
위 그림에선 잘 표현이 되지 않긴 했지만, 절편이 2.2로 나온것에 문제가 없음을 알 수 있다.
sklearn 라이브러리를 이용해 회귀계수, 절편 구하기.
사실 scikit-learn 라이브러리가 굉장히 잘 되어있어서 위와같이 여러 번의 작업을 거치지 않고 할 수 있다. 아래와 같이 한번에 구할 수 있다. sklearn 최고!
model.coef_ # 회귀계수 구하기
model.intercept_ # 회귀계수 구하기
model.coef_[0][0], model.intercept_[0] (0.6, 2.2)
선형회귀에서 중요한 용어들
-
예측값(predict): 만들어진 선형회귀모델이 추정하는 값, 회귀선상의 독립변수에 대한 종속변수를 뜻한다.
-
잔차(residual): 예측값과 관측값의 차이
-
오차(error): 모집단에서의 예측값과 관측값의 차이
-
잔차제곱합(RSS): 회귀모델의 비용함수. 회귀모델의 잔차들의 제곱을 모두 합한 것으로 작을 수록 예측이 잘 되었다고 볼 수 있다. 그만큼 예측한 값들이 관측값들에서 멀리 떨어지지 않았다는 것을 의미한다.
-
학습: 이러한 잔차제곱합 등의 비용함수를 최소화하는 모델을 찾는 과정
-
외삽(extrapolate): 기존에 학습된 데이터의 범위를 넘어서는 값을 예측한다.
-
기준모델: 가장 간단하고 직관적이며, 최소한의 성능을 가지고 있어 첫 학습모델에 대한 성능 비교를 할때 사용한다.
- 분류문제 기준모델: 타겟(y)의 최빈 클래스
- 회귀문제 기준모델: 타겟(y)의 평균 값
- 시계열 회귀문제 기준모델: 이전 타임스탬프 값

좋아용