Linear Regression - 다중선형회귀 정리, 기준모델, 다중모델 작성 및 시각화해보기
다중선형회귀란?
단순선형회귀와 같이 독립변수 X의 변화에 따른 종속변수 y의 변화를 선으로서 예측하는 기법인데, 독립변수 X가 여러개인 분석기법이다.
독립변수 X가 여러개 = 특성(feature)이 여러개라는 뜻이다.
하여 독립변수 2개를 이용해 선형회귀 모델을 만들면서 그 과정을 정리해보고, 중요한 용어나 내용들을 함께 정리해보겠다.
기준모델 작성
머신러닝 모델을 작성하기 전에 갖고있는 데이터로 작성되는 최소성능의 모델로, 기준모델의 오차를 파악함으로써 앞으로 만들 모델의 성능평가를 비교하기 위해 사용이 된다.
다룰 문제에 따라 다른데, 아래와 같이 분류할 수 있다.
- 회귀문제(Regression): 타겟의 평균값 (데이터와 상황에 따라 중앙값, 또는 다른 값을 사용할 수도 있다.)
- 분류문제(Classification): 타겟의 최빈값
- 시계열데이터(TimeStamp): 이전 타임스탬프 값 -> 1초전의 느낌. 다루기 어려운 데이터이긴 하지만, GPS의 경우 시간에 다라 위치정보가 다르고, 주식의 경우도 시간의 흐름에 따라 정보가 달라지기에 '과거의 정보로 학습해서 미래를 예측'해야하는 경우가 많다.
이 포스팅에선 numerical target을 다루는 문제를 해결하기 위해 회귀문제를 풀어보도록 할 것이다.
data set은 seaborn에서 제공하는 diamond data set을 이용한다.
price를 target으로 회귀문제로 간주하여 기준모델을 평균값으로 하여 진행해보겠다.
import seaborn as sns
import numpy as np
# seaborn의 diamond 데이터 불러오기
df = sns.load_dataset('diamonds')
# target = price / feature = carat 그래프로 산점도 나타내기
sns.scatterplot(df['carat'], df['price']);
# 기준선 예측값 구하기(price column의 평균값)
predicted = df['price'].mean()
#기준선 긋기( price column의 평균값)
sns.lineplot(x=df['carat'], y= predicted, color = 'red');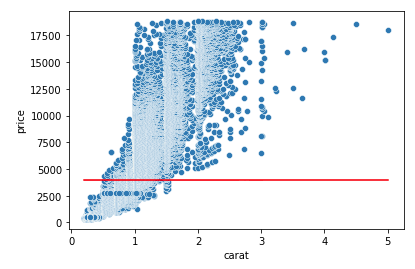
시각화를 위해 '단순선형회귀'로 표현해봤다. 빨간색 선이 처음 예측했던 기준모델이자 예측선이다.
price data들의 평균으로 이루어져 있고, 한 눈에 봐도 데이터의 분포와 거리가 있어 보인다. MAE(절대평균오차)를 통해 정확도를 체크해볼 수 있다. sklearn 라이브러리를 이용해 구해보겠다.
from sklearn.metrics import mean_absolute_error
# 절대평균오차 구하기
mae = mean_absolute_error(predicted, df['price'])3031.6032208510013031 오차는 우리가 예측한 붉은 선 과 데이터사이의 거리의 절대값의 평균이다. 최고치가 17500인 데이터에서 오차가 3000대라는건 굉장히 큰 오차로 보여질 수 있다. 이를 줄이는 과정이 모델링을 하는것이다.
다중선형회귀모델 작성
다중선형모델은 특성이 2개인것까진 3차원 plot으로 생성이 가능하지만, 3개 이상의 특성들로는 plotting 하지 못하므로 2개의 특성으로 모델링 한다.
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 2개 feature(특성)을 이용한 다중 선형회귀모델 작성
# target 설정 = price
target = ['price']
# feature 설정 = carat, depth 두가지 특성
feature = ['carat', 'depth']
# 다중선형회귀 모델작성하기
# model 변수에 선형회귀 모델을 집어넣는다.
model = LinearRegression()
# 선형회귀 모델을 X_train(두개의 특성), y_train(price라는 타겟)에 적용(fit)한다.
model.fit(df[feature], df[target])
# 만들어진 모델을 원래학습시켰던 데이터에 적용해본다.
y_pred = model.predict(df[feature]) 빈 LinearRegression model에 feature와 target data를 넣고 fit 한다. model.fit(X, y) 까지 진행하면 모델이 만들어졌다고 보면 된다. 이후 predict를 통해 다른 data set의 X(feature)를 학습해 그에 맞는 y를 예측한다.
# 우리가 만든 모델의 에러를 점검해본다.
mae_pred = mean_absolute_error(y_pred, df['price'])
print('기준모델의 오차: {0} \n다중회귀모델의 오차: {1}'.format(mae, mae_pred))
# 오차가 확 줄어든 것을 볼 수 있다. 기준모델의 오차: 3031.603220851001
다중회귀모델의 오차: 1005.1337893657361작성한 model을 기준모델과 비교해본다. 평균으로 만든 기준모델에 대한 실제 타겟 데이터들의 오차보다 X_train데이터들로 회귀선을 fit한 모델의 오차가 훨씬 줄어든 것을 볼 수 있다. 평균선에 비해 특성과 타겟 간 오차 제곱합이 가장 적은 선을 그려낸 것을 알 수 있다.
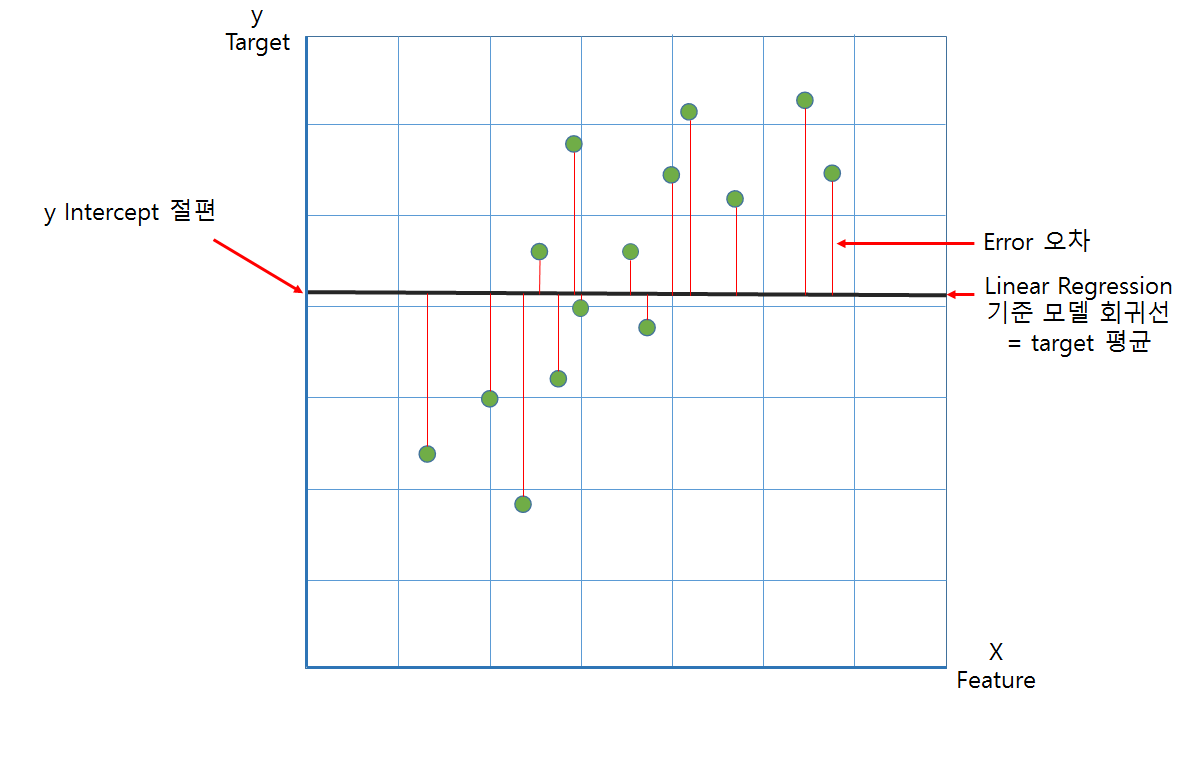
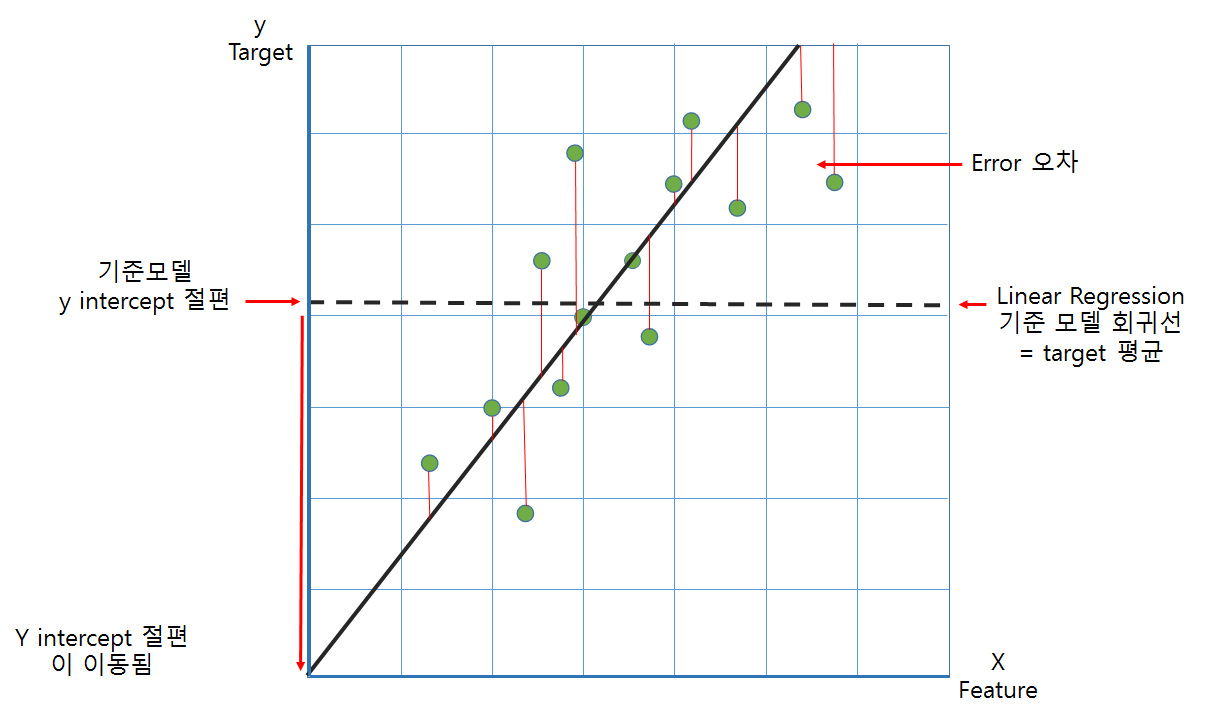
그림은 단순선형회귀모델에 대한 기준모델과의 비교이지만, 그림과같이 오차가 확 줄어들게하는 선을 그려냈다고 생각하면 된다.
진행해본 데이터는 특성이 2개이므로 데이터의 분포 및 상관관계와 우리가 예측한 모델의 예측 선(면)을 볼 수 있다. 종속변수와 독립변수가 TTL 3개이기 때문에 이들이 면을 이루게 된다.
import matplotlib.pyplot as plt
from matplotlib import style
import plotly.express as px
import plotly.graph_objs as go
import itertools
def surface_3d(df, f1, f2, target, length=20, **kwargs):
# scatter plot(https://plotly.com/python-api-reference/generated/plotly.express.scatter_3d)
plot = px.scatter_3d(df, x=f1, y=f2, z=target, opacity=0.5, **kwargs)
# 다중선형회귀방정식 학습
model = LinearRegression()
model.fit(df[[f1, f2]], df[target])
# 좌표축 설정
x_axis = np.linspace(df[f1].min(), df[f1].max(), length)
y_axis = np.linspace(df[f2].min(), df[f2].max(), length)
coords = list(itertools.product(x_axis, y_axis))
# 예측
pred = model.predict(coords)
z_axis = pred.reshape(length, length).T
# plot 예측평면
plot.add_trace(go.Surface(x=x_axis, y=y_axis, z=z_axis, colorscale='Viridis'))
return plot
surface_3d(
df,
f1='carat',
f2='depth',
target='price',
title='diamond price'
)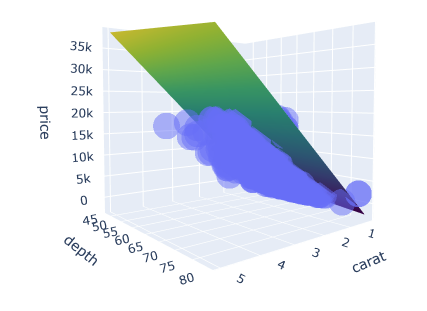
시각적으로 3d scatter를 사용헤봤다. 수 많은 데이터들의 산점도들과 예측 면 3차원으로 구성된 것을 볼 수 있다.
모델의 평가
Train set / Validation set / Test set 이해하기
작성한 모델이 쓸모가 있는지는 어떻게 알 수 있을까?
검증 데이터(validation set)와 테스트 데이터(Test set)으로 할 수 있다.
훈련용 데이터(Train set)에 익숙하게 학습을 하고, 새로운 데이터에 대한 성능평가를 위해 검증 데이터를 사용한다.
성능을 개선해야 한다면, 다시 훈련용 데이터를 이용해 튜닝을 하고, 검증 데이터로 확인을 해본다.
검증 데이터에 대해서도 성능 평가가 적합하다고 생각되면, 마지막 점검을 위해 테스트 데이터를 사용한다.
- 훈련 데이터 (Train data): 모델을 학습시키기 위한 기본 데이터 자원
- 검증 데이터 (Validation data): 훈련 데이터에만 성능이 좋지 않도록 확인하고, 모델을 발전(튜닝)시키도록 확인하기 위한 데이터 자원 (ex: 모의고사)
- 테스트 데이터 (Test data): 최종적으로 학습을 마무리하고 성능을 평가하기 위해 1번만 사용해야하는 데이터, 테스트데이터로 학습할 경우 유출문제가 발생할 수 있다.
# test set, train set으로 나누기
X_train = df[feature]
y_train = df[target]
X_test = df[feature]
Y_train = df[target]
# 각각 training set 80% test set 20%로 나눠서 뽑는다
X_train, X_test, y_train, y_test = train_test_split(df[feature],df[target], test_size = 0.2, random_state = 2)
# 다중선형회귀 모델작성하기
model = LinearRegression() # model 변수에 선형회귀 모델을 집어넣는다.
model.fit(X_train, y_train) # 선형회귀 모델을 X_train(두개의 특성), y_train(price라는 타겟)에 적용(fit)한다.
y_pred = model.predict(X_train) # 만들어진 모델을 학습 데이터에 적용해본다.
y_pred1 = model.predict(X_test) # 완성된 모델을 테스트용 데이터에 적용해본다.편의상 validation set은 나누지 않았다. 보통의 경우, train과 test를 나눈 뒤 그 train set에서 한번 더 train과 val set 나눈다.
이를 hold-out 방식이라고 한다.
from sklearn.metrics import r2_score
# MAE 비교해보기
mae_train = mean_absolute_error(y_train, y_pred)
mae_test = mean_absolute_error(y_test, y_pred1)
mae_train, mae_test
#R2 square 비교해보기
r2_train = r2_score(y_train, y_pred)
r2_test = r2_score(y_test, y_pred1)
r2_train, r2_test
print(f'Train set MAE: {mae_train:,.0f}')
print(f'Train set R2: {r2_train:,.3f}')
print(f'Test set MAE: {mae_test:,.0f}')
print(f'Test set R2: {r2_test:,.3f}')Train set MAE: 1,004
Train set R2: 0.851
Test set MAE: 1,009
Test set R2: 0.850train set과 test set의 모델의 예측에 대한 오차를 MAE, 결정계수 R2를 표시해보았다. Train set과 Test set의 오차가 크지 않고, 결정계수가 높아 '분산이 적은' 모델을 잘 만들었다고 볼 수 있다.
# 회귀계수 확인하기
a = model.coef_
b = model.intercept_
print('carat 특성 회귀계수:',a[0][0])
print('depth 특성 회귀계수:',a[0][1])
print('y 절편 값:',b[0])carat 특성 회귀계수: 7765.140663767152
depth 특성 회귀계수: -102.1653221580108
y 절편 값: 4045.3331826016815coef와 intercept를 통해 모델 특성의 회귀계수와 y절편 값을 확인해봤다.
carat 특성은 1단위당 price가 7765씩 오른다는 것을 알 수 있다.
반면, depth 특성은 1높아질때마다 price가 102씩 줄어드는 반비례 관계임을 회귀계수를 통해 알 수 있다.
y 절편의 경우는 최적의 기울기를 맞추는 과정에서 특성 X값이 0일 때 4045의 위치에 있다는 사실을 알 수 있다.
다중선형회귀모델을 직접 작성해보고, 평가하고, 이 모델에 대한 확인을 해보았다.
과적합/과소적합 정의
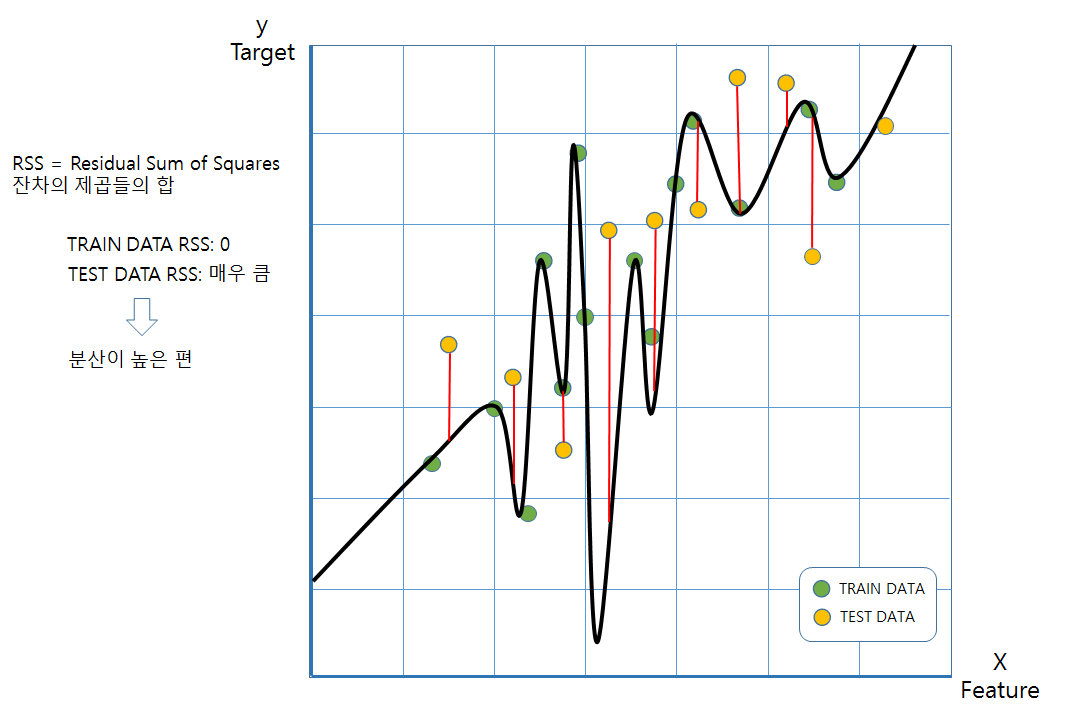
-과적합(overfitting): 모델이 훈련용 데이터에 너무 과하게 학습이 되어 검증데이터 또는 테스트데이터에 적용시 오차가 크게 나는 경우 과적합이 되었다고 하고, 분산이 높다라고 표현한다.
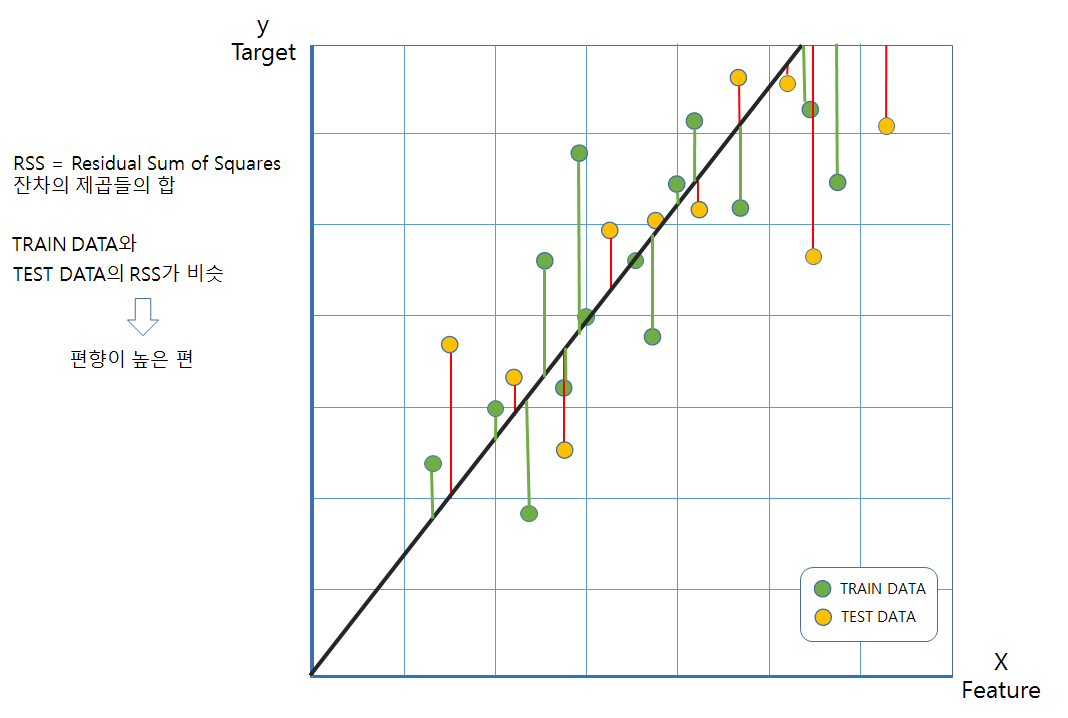
-과소적합(underfitting): 모델이 훈련 데이터에 학습이 너무 덜 되어있어 오차가 높은 경우이다. 이 경우는 편향이 높다라고 표현한다.
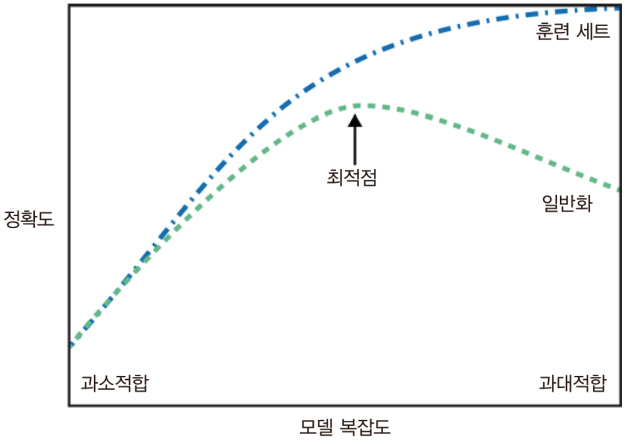 (이미지 출처: https://tensorflow.blog)
(이미지 출처: https://tensorflow.blog)
-일반화(Generalizaion): 규제라고도 표현하는 이 일반화는 훈련 데이터와 테스트 데이터에 대한 오차가 비슷하면서 어떤 새로운 feature 데이터가 input되어도 훈련 데이터와 비슷한 오차로 target 값을 예측하는 모델을 일반화가 되었다고 표현한다.
일반적으로 다중선형회귀를 이용하면 특성이 많아지면서 과적합이 될 가능성이 높아 이를 잘 조절해서 일반화 해야한다.
