Machine Learning - Decision tree 결정 트리 정리, 모델 작성, 지니 불순도와 엔트로피 이론
선형 회귀가 아닌 트리 구조의 모델에 대한 정리를 하고, 모델이 작동되는 원리를 살펴본다.
Decision Tree - 결정 트리란?
기존에 공부했던 선형회귀와는 다르게 결정 트리는 말 그대로 의사결정 나무를 만드는 것이다. 각 특성들이 노드가 되고, 중요한것을 상위에서 시작해 분기해 나가면서 그에 맞는 예측을 하는 모델이다. 가지가 뻗어나가는 트리 모양이어서 이름이 붙여졌다.
이미지 출처: https://www.youtube.com/watch?v=_L39rN6gz7Y
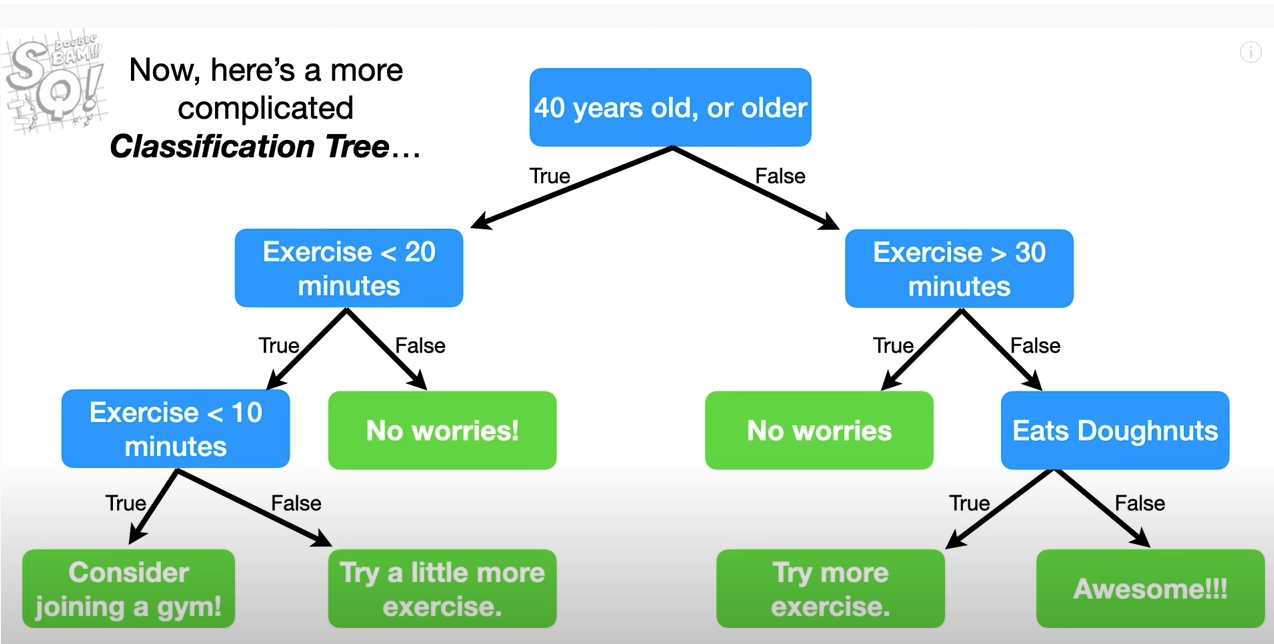
스탯 퀘스트의 이미지를 이용해서 설명하자면, 맨 위 루트노드부터 정해진 질문에 대한 True or False 답을 내리고, 그 이후에도 추가적인 질문에 대한 답을 내려 최종적으로 의사 결정을 하도록 하여 예측하는 모델이다.
위의 예시로 보아 만약 41세에 운동을 하루에 5분정도 하는 사람을 한 샘플(row)이라고 가정하여 위 모델을 적용하면,
40세 이상이냐는 질문에서 True >
운동을 하루에 20분 미만으로 하냐는 질문에 True >
운동을 하루에 10분 미만으로 하냐는 질문에 True >
최종적으로 선택도니 것은 Consider joining a gym!
이라는 결과를 얻을 수 있다. 이처럼 스무고개 하듯 계속해서 질문(feature)에 대한 답을 통해 최종 결과를 예측하는 것이 결정 트리 이다.
Decision Tree 모델의 용어
노드(Node): 각 특성(feature들 의미)
엣지)Edge_: 분기할 때의 선을 의미
지니 불순도(Gini Impurity): 해당 feature에 대한 data를 통해 target을 예측할 때, 얼마나 target과 관련없는 답이 섞여있는지를 파악하는 척도
엔트로피(Entropy): 열역학의 용어인데, 말하자면 무질서의 정도이다. 보통은 지니 불순도를 더 활용하는 것으로 보인다.
Decision Tree의 작동 원리, 장단점(특성 상호작용)
특성들 간의 중요도를 파악해 해당 특성을 Root Node(최상위 노드)로 선정하고, 이후 그에 맞는
Decision Tree 모델 작성
import seaborn as sns
#Decision Tree dataset 불러오기
df = sns.load_dataset('iris')
df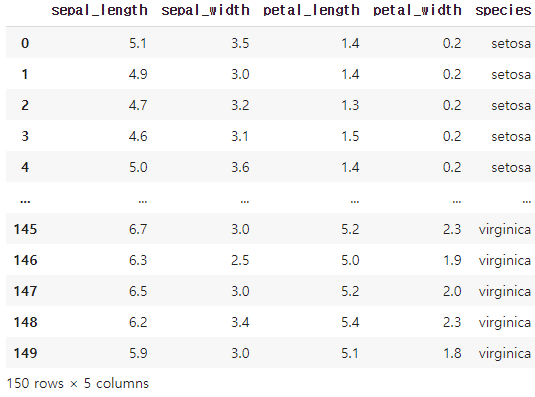
df['species'].value_counts()[output]
virginica 50
versicolor 50
setosa 50
Name: species, dtype: int64seaborn의 dataset을 불러왔다. 이 중 범주형 column인 species의 분포를 확인했을때 세 가지 범주가 각 50개씩의 샘플로 이뤄져있음을 확인했고, 이 중 'versicolor'를 찾아내는 이진분류로 맞춰보는 모델을 작성하겠다.
Target: species
versicolor: 1
setosa, virginica : 0
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import f1_score, roc_auc_score, confusion_matrix
# target 선정
target = 'species'
df['species']= [1 if i == 'versicolor' else 0 for i in df['species']]
train, test = train_test_split(df, test_size = 0.2, random_state = 2)
feature = df.drop(columns = target).columns
X_train = train[feature]
y_train = train[target]
X_test = test[feature]
y_test = test[target]
# 결정트리 모델 작성
decit = DecisionTreeClassifier()
decit.fit(X_train, y_train)
# train 셋에 먼저 적용
y_pred_train = decit.predict(X_train)
y_pred_proba_train = decit.predict_proba(X_train)[:,1]
# test 셋에 모델 적용
y_pred = decit.predict(X_test)
y_pred_proba = decit.predict_proba(X_test)[:,1]
# train 셋 적용 결과
print('[train] accuracy:',decit.score(X_train, y_train))
print('[train] f1:', f1_score(y_train, y_pred_train))
print('[train] auc:', roc_auc_score(y_train, y_pred_proba_train))
# test 셋 적용 결과
print('\n[test] accuracy:',decit.score(X_test, y_test))
print('[test] f1:', f1_score(y_test, y_pred))
print('[test] auc:', roc_auc_score(y_test, y_pred_proba))[output]
[train] accuracy: 1.0
[train] f1: 1.0
[train] auc: 1.0
[test] accuracy: 0.9333333333333333
[test] f1: 0.875
[test] auc: 0.9147727272727273모델을 X_train set으로 학습한 뒤, 각각 train set과 test set에 predict 적용했을 때 결과를 비교해본다.
세 가지 평가지표로 확인을 했을 때, 당연한 결과지만 train set은 과적합되어 모든 지표가 1로 나왔다.
test 셋도 사실 성능이 굉장히 좋게 나왔는데, 이것은 해당 데이터의 target 예측 문제가 비교적 쉬운편이라고 볼 수 있다.
Feature importance - 특성 중요도 확인해보기
import pandas as pd
import matplotlib.pyplot as plt
# 특성 중요도 파악
# 특성 중요도 계산 후 X_test column으로 넣는다.
importance = pd.Series(decit.feature_importances_, X_test.columns)
importance.sort_values().plot.barh();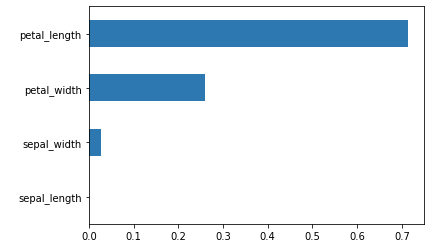
예측모델을 만든 뒤, 데이터셋에 대한 인사이트를 얻기 위해 예측에 중요한 역할을 한 feature을 찾는 방법이다. 위 모델에서 target을 예측하는데엔 petal_length가 가장 중요한 특성으로 보인다.
중요 특성을 파악해 insight 확보하기
# 상관계수분석
df_c = df.corr()
sns.heatmap(df_c, cmap = "YlGn");
plt.show();
# 타겟(species에 대한 상관계수 확인)
print(df.corr()[target].sort_values(ascending = False))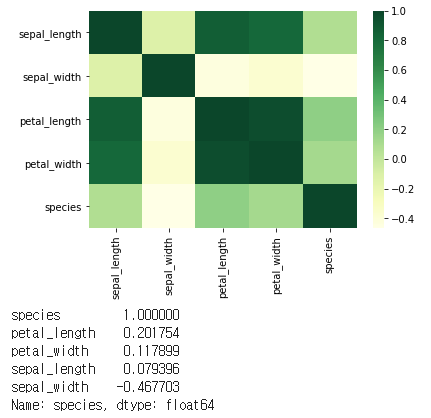
상관관계를 파악해서 시각화 및 수치화 했을 때, 타겟인 species에 대해 'petal length'가 0.2로 가장 높은 상관계수를 띄고, 'sepal_width'가 -0.46으로 가장 낮은 음의 상관계수를 띄는 것을 알 수 있다. 결론적으로 데이터 셋 상에서 'sepal width'가 낮고, 'petal_length'가 높을 수록, 1로 설정해놓은 우리의 target(versicolor: 1)에 가깝게 예측을 한다는 것을 알 수 있다.
지니 불순도
지니 불순도(gini impurity)는 한 feature 내에 있는 요소의 target값의 분산이 얼마나 퍼져있는가를 확인하는 것으로 불순도가 낮을 수록 더 중요한 feature라고 할 수 있다.
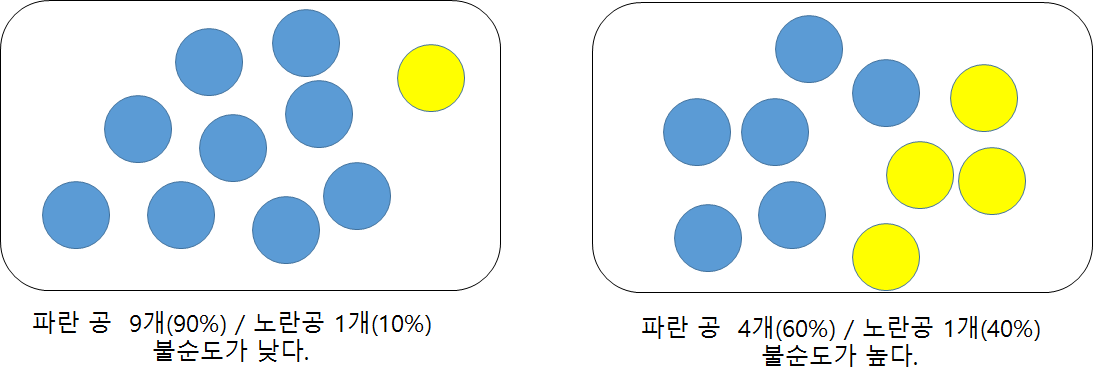
위와같은 그림으로 보면 왼쪽의 경우가 타겟을 예측하기에 좀 더 중요한 특성으로 여겨질 수 있다.
그렇다면 이번엔 예제를 통해 지니 불순도를 구해보도록 한다.
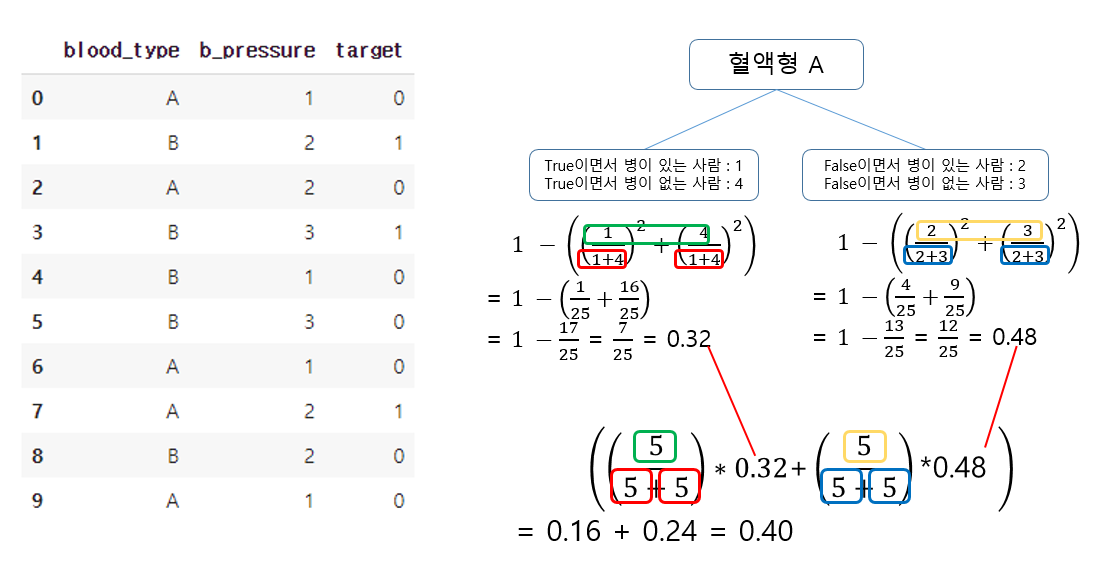
위와 같은 data set에서 blood type이 A와 B 두개라고 가정했을 때, 병(target)이 있으면 1, 없으면 0이라고 하자. 혈액형은 A또는 B이고, 혈액형은 A냐 라는 질문에 True or False로 나타내본다.
위 이미지의 식과 같이 진행을 하면 지니 불순도를 구할 수 있는데, 포인트는 True의 불순도 False의 불순도를 구해 최종적으로 이를 가중치로써 곱한 값을 1에서 빼준다는 것이다.
이 내용을 기재한 이유는, 지니 불순도에 대한 이해도 중요하지만, 특성의 범주가 많으면 많을 수록 이 불순도가 낮아져 상대적으로 중요한 특성처럼 여겨질 수 있기에 주의해야 하기 때문이다.
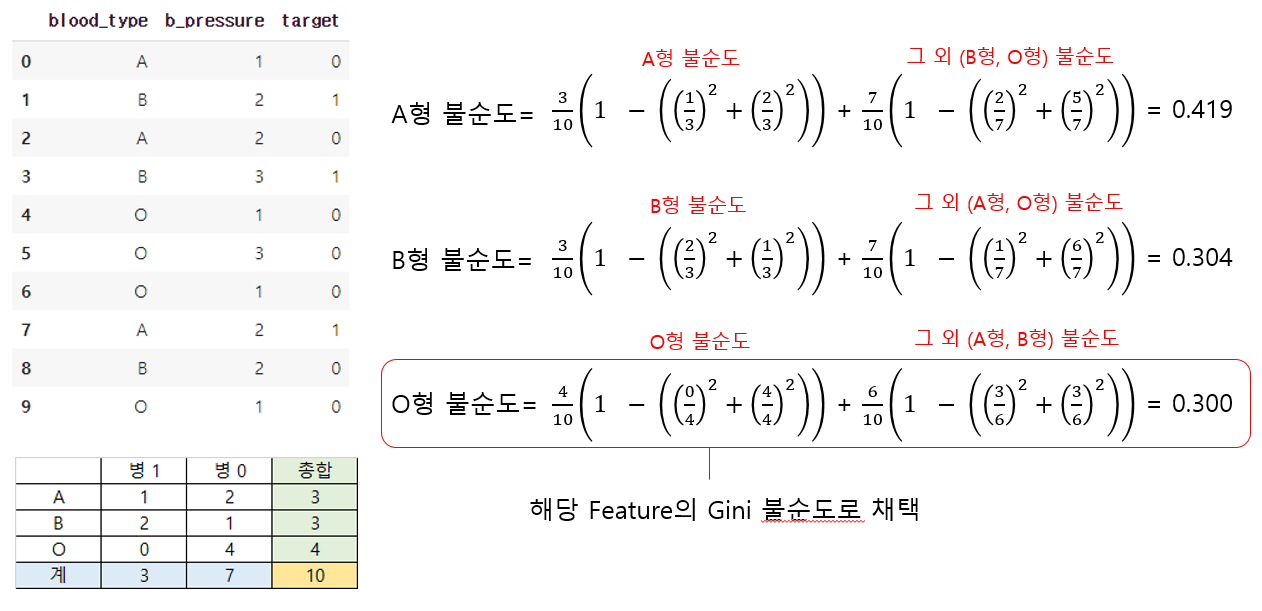
그렇다면 O형을 추가해 세개의 범주가 된다면 불순도가 줄어드는지 확인해보자.
지니 불순도를 결정하는 알고리즘은 Binary로 분할을 진행하기 때문에 A형과 그 외/ B형과 그 외/ O형과 그 외와 같이 각 요소별로 불순도를 측정한다. 그리고 그 요소들 중 가장 불순도가 작은 것으로 해당 feature의 불순도로 채택을 하게 된다. 이러한 이유로 범주가 굉장히 많은 High Cardinality Feature의 경우엔 중요치 않은 특성임에도 중요한 특성처럼 Root Node를 차지할 수 있으니 주의해야 한다.
