Machine Learning - Random Forest 정리, 구성원리 파악 및 모델 작성
Random Forest란?
Decision Tree(의사결정나무)의 Forest(숲)이다.
Random으로 feature를 선정해 Node로 지정하고, 분기할 때마다 Decision Tree와 같은 방식으로 지니 불순도를 파악하여 분기해 나가는 Weaker learner를 여러개 만들어 비교하고, 그 안에서 최적의 예측을 하는 모델이다.
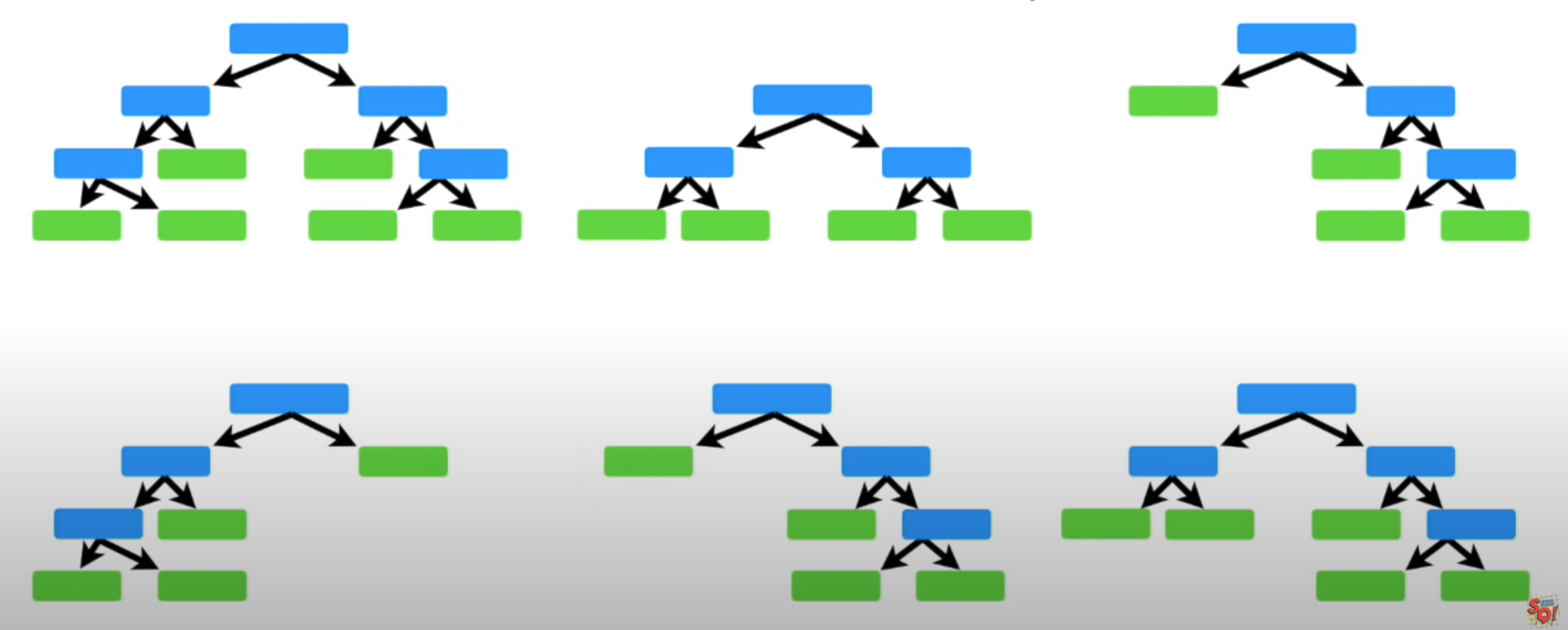
이미지 출처: https://www.youtube.com/watch?v=J4Wdy0Wc_xQ
Random Forest 구성원리
1. 부트스트랩 샘플링(Bootstrap):
RandomForest(숲)을 만들기 위한 각각의 Weaker learner를 만들기 위해 사용하는 샘플링 방법으로 임의로 Feature를 뽑고, 그 Feature 안에서도 임의로 Sample을 복원추출(중복이 가능하도록)하여 뽑는 방법이다.
데이터 셋에 n개의 sample이 있다면, 기존 데이터셋과 같이 n개의 sample을 복원추출하여 New Bootstrap data set을 만들고, 이를 수차례 반복하는 샘플링 방법이다.
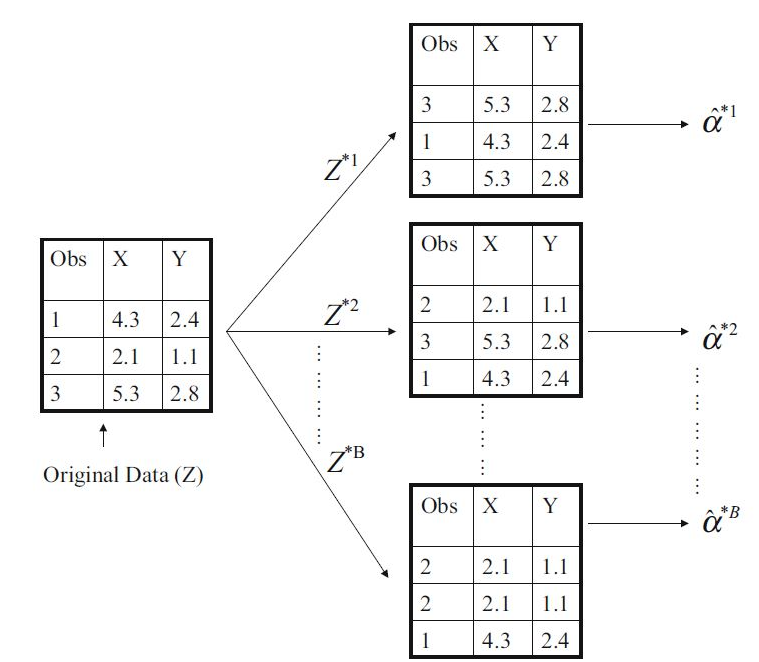
이미지 출처: https://blog.kakaocdn.net/dn/WnWjt/btqMvfwFqg1/8AwRUJYDc6nJHws5RqJsg1/img.jpg
{kind=link}
2. 분기(edge, branching)와 임의의 특성 선택(Randomized feature selecting):
RandomForest의 또다른 특징은 분기 시 다음 특성을 고를 때에도 Random한 방식을 취한다는 점이다.
다른 말로 Bagging이라고 하는 이 특징은 Bootstrap sampling을 한 Data set에서 Feature를 임의로 선정해 여러 Tree 분류기를 만드는 만드는 것으로 Ensemble 기법, 병렬구조라고 이야기 할 수 있다. Decision Tree의 큰 단점중 하나인 과적합을 예방해주는 강점으로도 볼 수 있다.
3. OOB 검증(Out of Bag data validation):
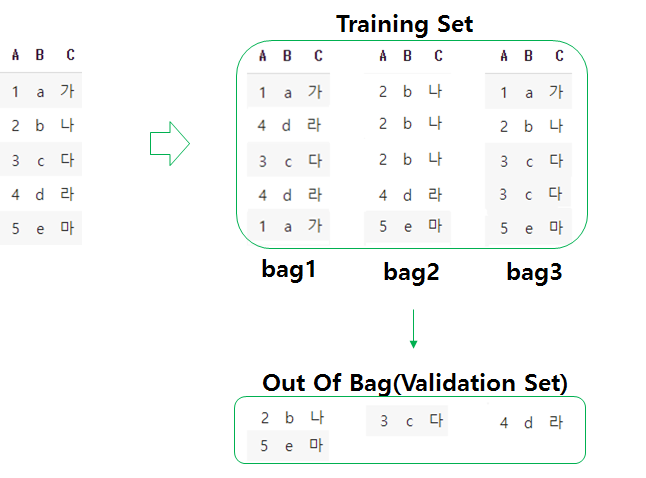
Bootstrap은 하나의 Dataset 내에서 여러개의 New Dataset을 복원추출함으로써 그 자체적인 검증도 어느정도 진행을 한다. Original Dataset과 같이 n개의 샘플만큼 복원추출을 하게되면 뽑히지 않는 샘플도 생기기 마련이다. 이렇게 뽑히지 않는 샘플을 OOB(Out of Bag Data)라고 하는데, 이들을 검증셋(Validation set)으로 두어 자체적인 검증을 진행을 한다.
python에서의 OOB 스코어를 확인하는 예시는 아래 모델 작성에서 함께 보도록 한다.
Random Forest 모델 작성
import pandas as pd
# iris dataset 불러오기
df = sns.load_dataset('iris')
df
지난번 Tree모델로 작성했던 Decision Tree의 성능과 비교해 볼 수 있도록 똑같이 'iris' Dataset을 불러와 진행해본다.
# target 선정
target = 'species'
df['species']= [1 if i == 'versicolor' else 0 for i in df['species']]
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size = 0.2, random_state = 2)
feature = df.drop(columns = target).columns
X_train = train[feature]
y_train = train[target]
X_test = test[feature]
y_test = test[target]
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, roc_auc_score, confusion_matrix
# RandomForest 앙상블 모델 작성
rf = RandomForestClassifier( oob_score= True)
rf.fit(X_train, y_train)
# test 셋에 모델 적용
y_pred = rf.predict(X_test)
y_pred_proba = rf.predict_proba(X_test)[:,1]
# test 셋 적용 결과
print('\n[test] accuracy:',rf.score(X_test, y_test))
print('[test] f1:', f1_score(y_test, y_pred))
print('[test] auc:', roc_auc_score(y_test, y_pred_proba))
print('\n oob_score:',rf.oob_score_)[output]
[test] accuracy: 0.9666666666666667
[test] f1: 0.9333333333333333
[test] auc: 0.9460227272727273
oob_score: 0.9416666666666667 
Decision Tree 모델 작성할 때와 모델만 빼고 완전히 동일하게 작성했을 때의 결과이다. 모든 똑같은 조건에서 모델링을 했음에도 Decision Tree보다 성능이 좋은 것을 볼 수 있다.
Random Forest의 파라미터에서 oobscore = True로 설정하게 되면, 추후 .oob_score를 통해 자체 검증 결과를 확인할 수 있다.
