
들어가기 앞서
해당 포스팅은,
https://www.youtube.com/watch?v=vQFGBZemJLQ&list=PLo0ta52hn1uHQ5iQ3hAeRoMUeLJFIeRew&index=8
를 시청하고 작성된 포스팅임을 밝힙니다! :)
MySQL 아키텍처
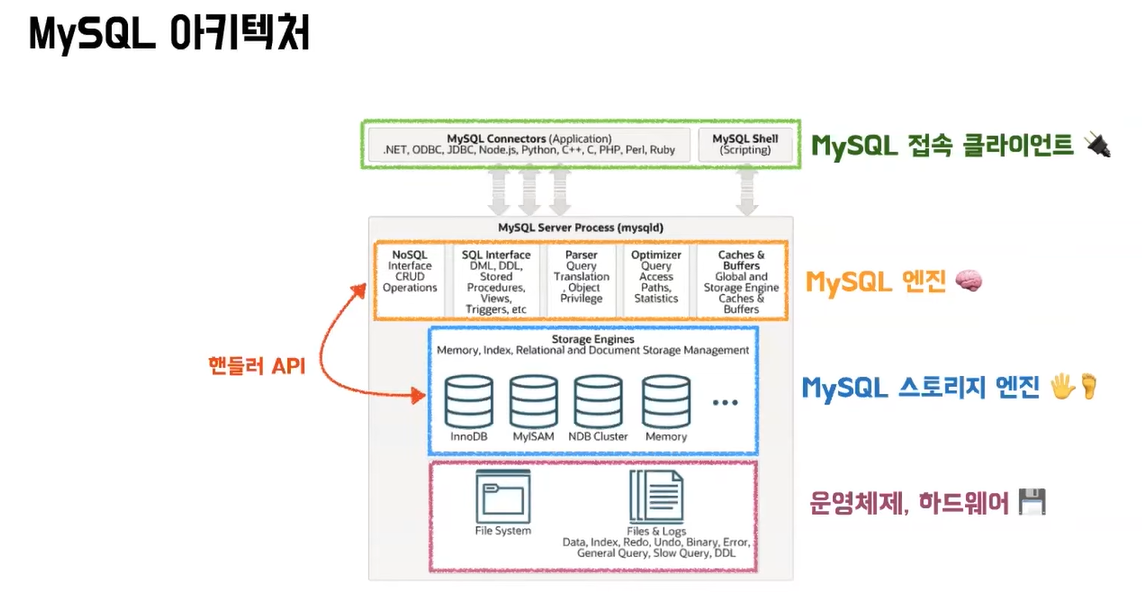
MySQL 아키텍처는 위의 사진과 같다.
MySQL은 아래의 요소들로 이루어져 있다.
-
우리가 작성하는 소스코드와 DB를 연결해주는 MySQL 접속 클라이언트
- 자바 진영에서는, JDBC API를 예시로 들 수 있다. -
MySQL의 두뇌와 같은 역할을 하는 MySQL 엔진
- 우리가 날리는 쿼리문을 트리 형태로 바꿔주는 파서
- 해당 트리형태의 쿼리문으로 실행 계획을 만드는 옵티마이저
-
데이터를 실제로 저장하거나 읽어오는 MySQL 스토리지 엔진
- 옵티마이저가 작성한 계획에 따라 MySQL엔진이 스토리지 엔진을 호출해서 사용함.
-
실제 데이터들을 사용하고 저장되는 운영체제와 하드웨어
쿼리 실행 과정
- 쿼리 캐시

쿼리문이 MySQL로 날아가면, 가장 먼저 쿼리캐시를 만나게 된다.
쿼리 캐시에는 이전의 SQL문에 대한 결과가 저장되어 있다.
우리가 아는 캐시메모리의 사용처럼,
쿼리 캐시는 데이터베이스나 애플리케이션에서 반복적으로 실행되는 쿼리에 대한 성능을 향상시키는데 도움을 준다.
하지만 새로운 SQL문이 날아가면 캐싱된 데이터를 삭제해야 하므로,
캐시 처리 쓰레드에 락이 걸리는 이슈가 생겨
성능이 저하되는 문제가 있어 MySQL 8.0부터는 완전히 제거되었다.
- 쿼리 파서
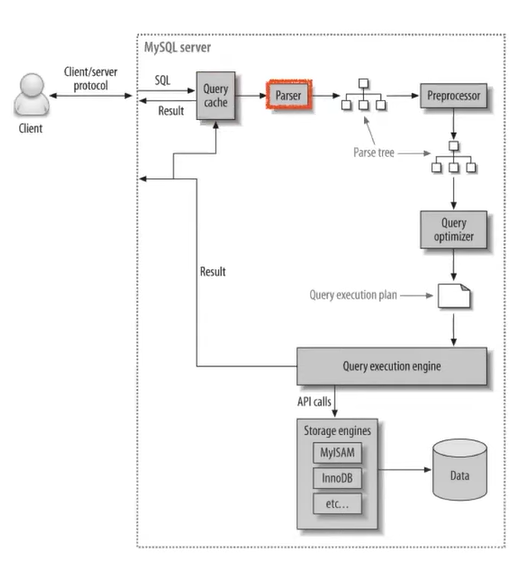
SQL문을 쪼개서 트리로 만들고, 오류를 체크한다.
해당 예시는 아래와 같다.

3. 전처리기
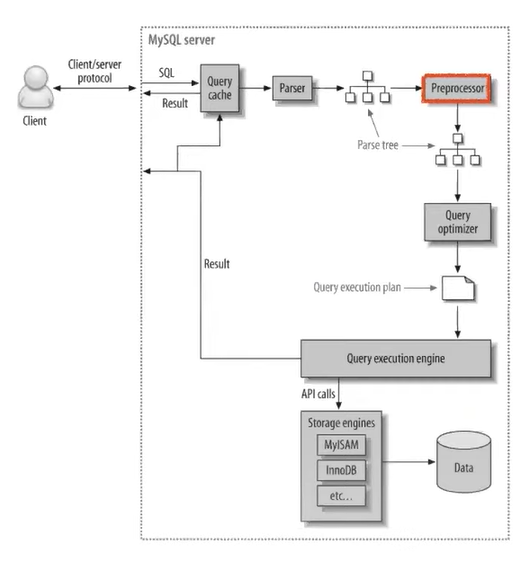
2번의 쿼리 파서가 쪼개놓은 트리를 기반으로 SQL문이 유효한지를 검사한다.
(주어진 컬럼명, 테이블명, 접근 권한 등이 유효한지)
4. 옵티마이저
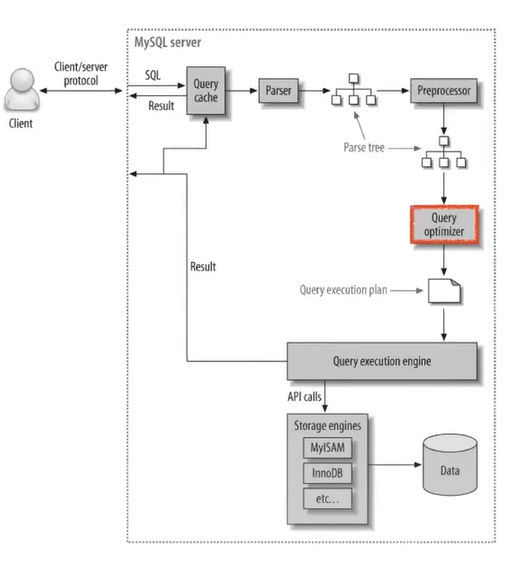
3번까지의 과정을 통해 받아온 SQL문을 최적화하여 실행한다.
최적화에는 두가지 방법이 있다.
- 규칙 기반 최적화
- 옵티마이저의 내장된 우선순위에 따라 최적화한다.
- 비용 기반 최적화
- 작업 비용(메모리, CPU..)과 테이블의 통계 정보를 활용하여 최적화한다.
- 쿼리 실행 엔진
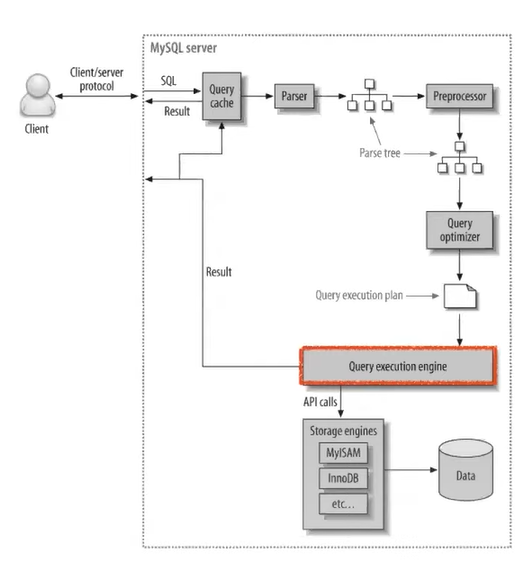
4번에서 옵티마이저가 실행계획을 수립하면, 해당 계획대로
쿼리 실행 엔진이 스토리지 엔진을 호출하여 쿼리를 수행한다.
이제 쿼리 수행을 위해 스토리지 엔진이 작동할 차례이다.
스토리지 엔진은, 데이터를 저장하고, 읽고, 쓰는 과정이 엔진에 따라 각각 다른 방식으로 작동된다.
MySQL은 대표적으로 InnoDB, MyISAM의 스토리지 엔진을 사용한다.
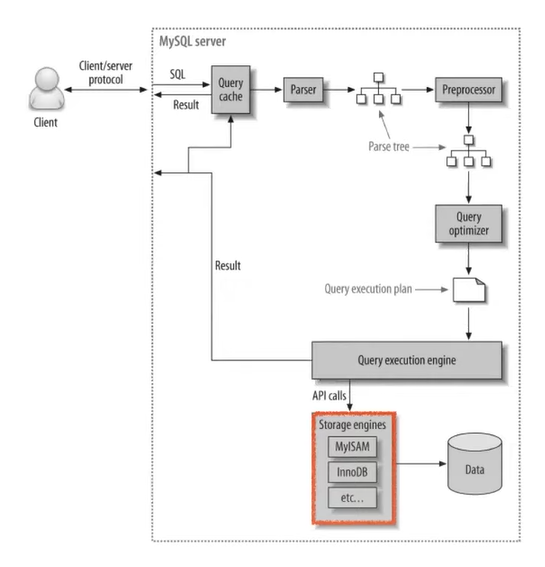
InnoDB 스토리지 엔진 특징
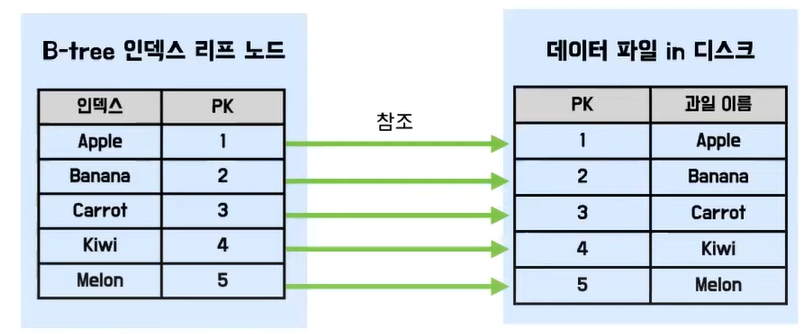
- PK순서대로 행을 정렬(클러스터링)하여 디스크에 저장한다.
- PK를 통해 데이터에 접근
- PK에 대한 인덱스를 자동 생성해주기도 함
- 그(클러스터링)에 따라 검색속도 빠르지만 읽기,쓰기 속도 저하됨
- 일반적 웹서비스는 검색이 읽기, 쓰기보다 많기 때문에 클러스터링은 합리적임
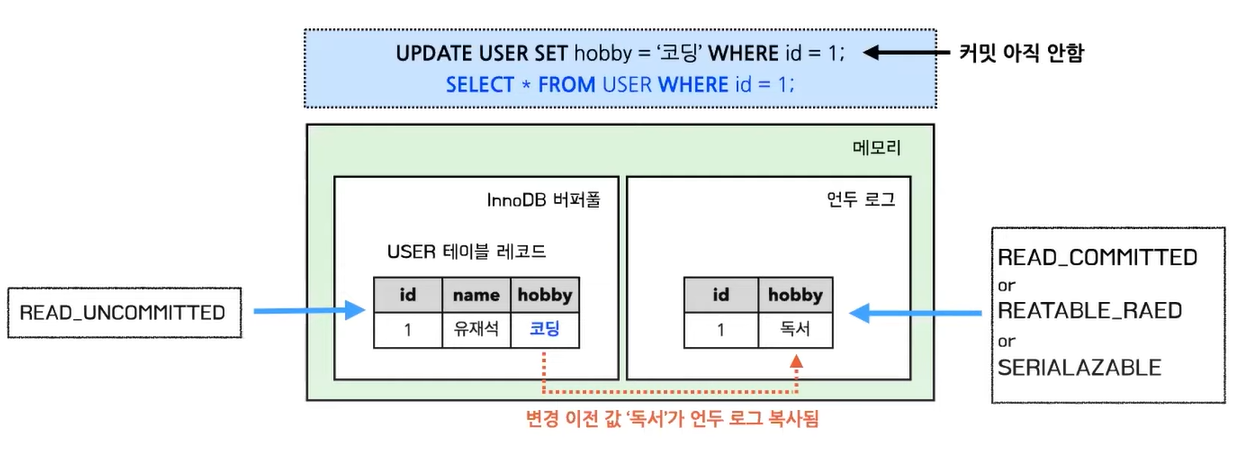
설명 : InnoDB 버퍼풀은 사진 가장 위의 UPDATE문이 적용되기 이전의 데이터 자체를 캐시로 저장하고, 언두 로그는 UPDATE문이 적용된 후를 로그로 기록한다.
쉽게 말해, 변경 전 데이터와 변경 후 데이터.
- 트랜잭션에 따라 조회되는 데이터가 달라진다. (MVCC특징)
-READ_COMMITED, READ_UNCOMMITED라는 트랜잭션 격리 수준에 따라 조회되는 데이터가 변경전, 변경 후로 다르다.

- 변경전, 변경후 데이터를 로그로 기록해놓는다.
- 언두 로그는 트랜잭션을 보장할 수 있도록(오류나면 롤백가능) 변경 이전 데이터를 기록해놓는다.
- 리두 로그는 영속성을 보장할 수 있도록(도중에 종료되더라도 반영가능) 변경 이후 데이터를 기록해놓는다.
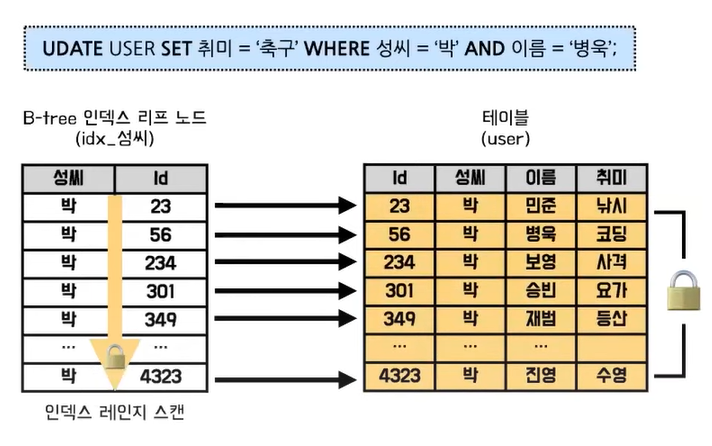
- 레코드 단위로 잠글 수 있다. (레코드 단위로 잠그게 된다면, 여러 레코드에 병렬적으로 접근 가능하여 동시 처리 성능이 좋다.)
- 사실 레코드 단위로 잠그는 것이 아니라, 사진과 같이index단위로 잠그는것 (위에서의 예시는 성씨를 index로 잡아 박씨 레코드들이 잠겼다.)
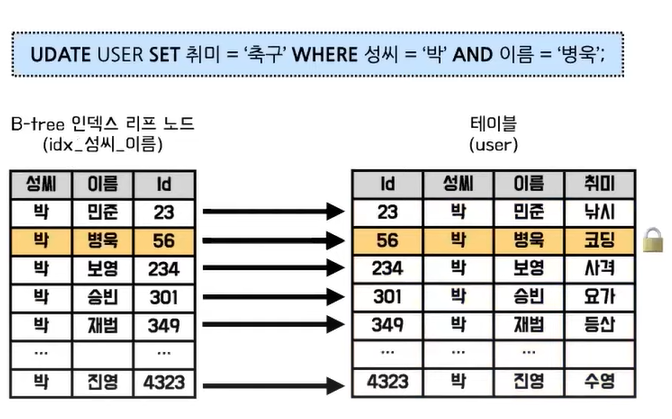
- 복합 인덱스를 사용하여 레코드를 잠근다면, 아래와 같이 특정 레코드도 잠글 수 있다. (index 는 성씨, 이름 복합 index)
위에서 설명한 버퍼 풀이 InnoDB의 특징중 하나이다.
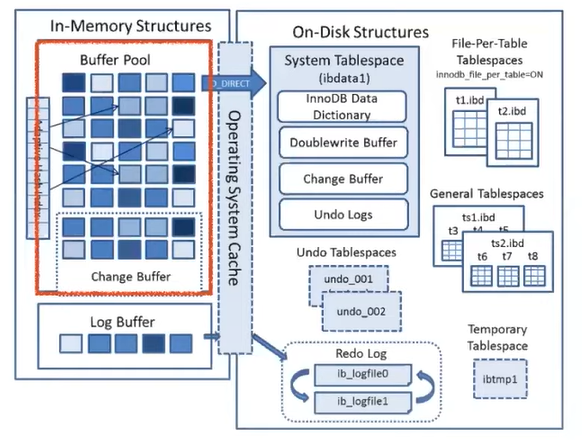
- SQL결과를 데이터 자체로 캐싱메모리로 페이지 단위로 캐싱하고,
해당 페이지들을 더티 페이지라고 부르고,
페이지들을 한꺼번에 모아 처리한다.
MyISAM 스토리지 엔진 특징
팁 : 마이아이삼이라고 읽는다 ㅎㅎ..
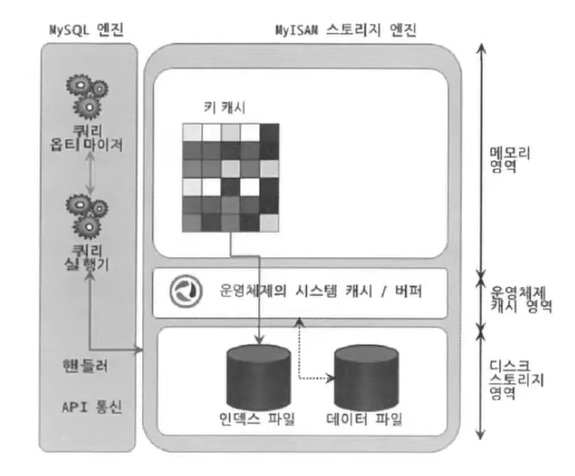
지금은 MySQL 8.0부터는 InnoDB 스토리지 엔진을 사용한다.
그래서 현재 사용중인 InnoDB 스토리지 엔진과 비교하여 간단하게 설명하겠다.
- 정렬(클러스터링), 트랜잭션, 외래키를 지원하지 않는다(PK는 제공한다!).
사진출처 : https://www.youtube.com/watch?v=vQFGBZemJLQ&list=PLo0ta52hn1uHQ5iQ3hAeRoMUeLJFIeRew&index=8

복잡하지만 흥미롭네요 마이아이삼이라고 읽는 건 또 처음 알았네요