
들어가기 앞서
이 포스팅은,
https://www.youtube.com/playlist?list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN
의 영상들을 시청하고 작성되었습니다! :)
프로세스를 쉽게 정의하면,
우리가 아는 프로그램을 실행시켜, 해당 프로그램이 메모리에 적재되어
자원을 할당받을 수 있는 상태다.
라고 할 수 있다.
그러면, 프로세스는 메모리에 적재되어있다.
라는 의미가 된다.
그러면 어떻게 적재되어있을까?
에 관한 이야기를 하려고 한다.
- 프로세스를 한꺼번에 메모리에 적재시킨다.
연속 할당
- 프로세스를 여러개로 쪼개어 메모리에 적재시킨다.
불연속 할당
연속 할당
프로세스가 하나의 연속된 메모리 공간에 할당되는 방식이다.
이 방식에는 두가지 종류가 있다.
- 고정 분할 방식
- 가변 분할 방식
고정 분할 방식
메모리 공간을 고정된 크기로 분할한다.
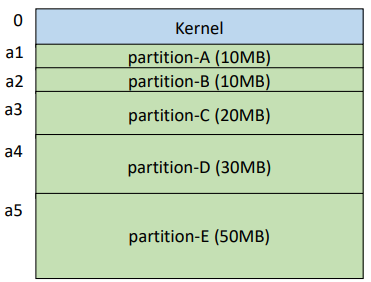
위 사진과 같이, 메모리 공간에서 각각의 파티션 들은
10, 10, 20, 30, 50 크기로 분할되어있다.
이제 프로세스가 들어오면, 해당 파티션에 통째로 할당시켜주면 된다.
여기서, 15MB 크기의 프로세스 P1이 C 파티션에 할당되었다고 가정하자.
그렇게 된다면 C 파티션에는 5MB의 공간이 남고,
이렇게 파티션 크기가 프로세스 크기보다 클때,
내부 단편화가 발생한다. (메모리 낭비)
또한, 55MB 크기의 프로세스 P2를 메모리에 적재해야한다고 가정하자.
그렇게 된다면 어떤 파티션에도 적재할 수 없게 된다.
이렇게 프로세스 크기가 남은 메모리 크기보다 클때,
외부 단편화가 발생한다. (메모리 낭비)
즉,
고정 분할 방식은 고정된 크기로 메모리를 미리 분할하므로,
메모리 관리가 간편해서 오버헤드가 낮다. (메모리를 나누는데 자원 소모가 적다는 이야기)
하지만, 내부 외부 단편화로 인해 자원이 낭비될 수 있다.
동적 분할 방식
위의 고정 분할 방식에서, 메모리의 크기를 동적으로 분할하는 방식이다.
아래의 순서로 예시를 들겠다.
- 초기 상태 (메모리 공간 120MB)

- 프로세스 A (20MB) 적재

- 프로세스 B (10MB) 적재
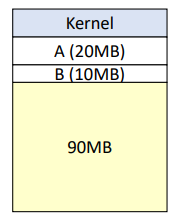
여기서 짚고 넘어가야 할 부분이, 가변 분할 방식이기에
고정 분할 방식과는 달리 파티션이 존재하지 않고,
A가 적재된 바로 다음 공간부터 연속 할당이 된다.
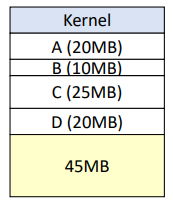
4. 프로세스 C (15MB) 적재

- 프로세스 D (20MB) 적재
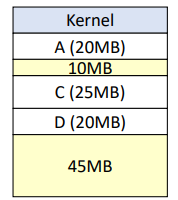
- 프로세스 B 종료 후 주기억장치에 반납
- 프로세스 E (15MB) 적재
- 프로세스 D 종료 후 주기억장치에 반납

- 이 상황에서, 5MB 크기의 새로운 프로세스 F가 들어온다고 하자.
그러면 어떤 공간에 배치해야 할까?
여기서 필요한 내용이,
배치 전략이다.
배치전략은 네가지 종류가 있다.
- 최초 적합 : 들어갈 수 있는 공간 중 첫번째 공간 선택
(오버헤드 낮지만, 공간 활용률이 떨어짐) - 최적 적합 : 프로세스가 들어갈 수 있는 공간 중 가장 작은 공간 선택
(전부 탐색하므로 오버헤드 높음) - 최악 적합 : 프로세스가 들어갈 수 있는 공간 중 가장 큰 공간 선택
(전부 탐색하므로 오버헤드 높음) - 순차 최초 적합 : 최초 적합 + 탐색 위치 기억
(메모리 사용 영역 균등화, 오버헤드 낮음)
또한, 가변 분할 방식에는
공간 통합과.
메모리 압축 방식이 있다.
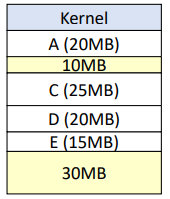
공간 통합은, 아래의 사진과 같이 인접한 빈 영역을 하나의 파티션으로 통합한다.
(20MB 파티션 + 10MB 파티션 -> 30MB 파티션)
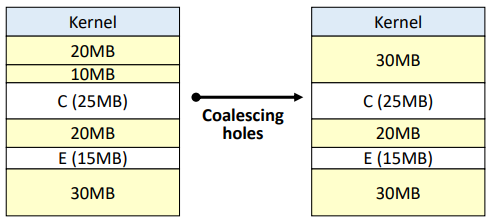
메모리 압축 방식은, 모든 빈 공간을 하나로 통합한다.
큰 프로세스가 할당되어 적재 공간 확보가 필요할때 수행한다.
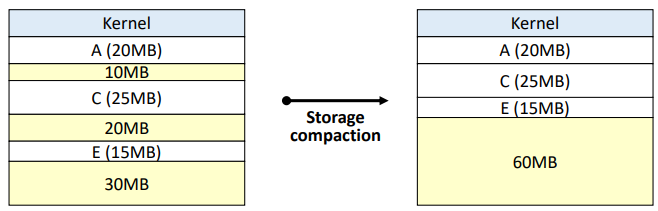
하지만, 사진에서 볼 수 있듯 모든 공간을 압축하므로,
진행중인 프로세스의 주소를 전부 바꿔주어야 한다. (주소 바인딩 작업)
(사진에선 A, B, E를 이동.)
그러므로 많은 시스템 자원을 소비하고, 높은 오버헤드가 발생한다.
불연속 할당
연속 할당은 프로세스가 통째로 메모리에 적재된다고 생각하면,
불연속 할당은 통쨰로가 아니라 연속적이지 않게 적재된다고 생각하면 쉽다.
하지만, 불연속인채로 적재되는것이지, 무조건 불연속인채로 전체 프로세스가 적재되진 않는다.
프로그램, 프로세스를 여러개의 블록으로 분할한다.
실행시, 필요한 블록들만 메모리에 적재한다.
그럼 의문이 생길 수 있다.
- 블록들로 찢어져있으면, 블록들을 어떻게 찾아가나요?
- 그리고, 필요한 블록들만 적재한다면, 필요없는 블록들은 메모리에서 필요하지 않겠네요?
1번, 블록들로 찢어져있으면, 블록들을 어떻게 찾아가나요?
에 대한 대답은 다음과 같다.
블록들을 찾아가기 위해, 가상 주소를 사용한다.
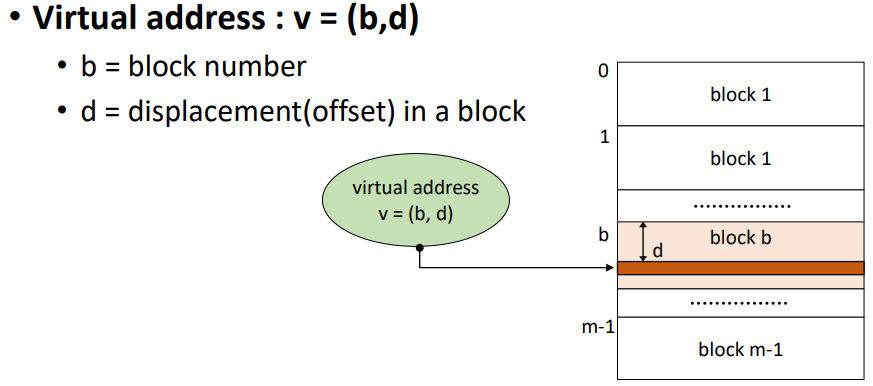
가상 주소가 존재한다.
해당 주소의 (b, d)의 b에서 몇번 블록인지 확인하고,
d에서 해당 블록에서의 상대 위치를 확인한다.
그렇다면, 프로세스의 블록들에 대한 정보들을 적어놓아야 한다.
해당 정보들을 적어놓고 메모리에 적재해서 사용한다.
그게 바로 BMT (Block Map Table) 이다.
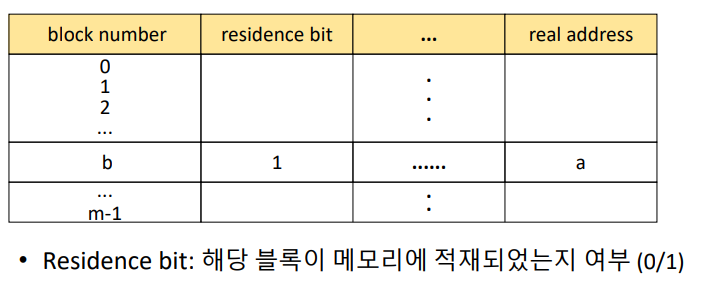
자세한 매핑 은 다음과 같다.
- 프로세스의 BMT에 접근
- 현재 여러개로 찢긴 블록중에, 해당 블록이 메모리에 있어서 즉시 사용가능한지 체크 (위 사진의 resident bit)
- 없다면 컨텍스트 스위칭이 일어나며 해당 블록을 적재하고,
있다면 실제 주소를 위에서 말한 방법으로 계산
(b, d) b에서 블록찾고, d에서 상대위치 찾기 - 해당 방식으로 메모리에 접근
2번, 그리고, 필요한 블록들만 적재한다면, 필요없는 블록들은 메모리에서 필요하지 않겠네요?
에 대한 대답은 다음과 같다.
맞다. 위의 resident bit를 생각해보자.
왜 메모리에 적재되어있는지 여부를 체크할까?
그야 수많은 블록으로 프로세스는 찢어져있고,
수많은 블록중 일부만 메모리에 적재해서 효율적으로 사용하기 위함이다.
이 방식이, 가상 메모리 방식이다.
가상 메모리 방식에는
페이징, 세그먼트 시스템이 있고,
페이지를 어떻게 효율적으로 사용할지에 대해서도 수많은 알고리즘과 기법들이 존재한다.
요약
프로세스가 메모리에 적재되는 방식은 두가지.
연속할당
불연속할당
연속 할당엔 파티션 크기를 고정하거나 고정하지 않는
고정분할, 가변분할 방식이 있다.
하지만, 연속 할당은 어쨌든 프로세스 전체를 메모리에 적재시켜야 하므로,
작업량이 많아지거나 거대한 프로세스는 사용하지 못하게 된다.
그래서
요즘의 OS는 대부분
프로세스를 여러개의 블럭으로 나누는 불연속 할당을 사용한다.
해당 불연속 할당 방식은 알아야 할 내용이 많다.
다음 포스팅에서 다룰 생각이다.
OS를 왜 배워야할지에 대해 생각이 많이 든다.
막연하게 CS공부를 통해 취직하기 위해서일수도 있지만,
이러한 CS공부가 전공자와 비전공자의 차이를 내도록 만드는 큰 요소라고 생각한다.
OS가 메모리를 관리하는 방식을 생각해보면,
내가 코드를 어떻게 작성해야 효율적일지가 조금씩은 알 수 있게 되는 느낌이다.
코딩테스트를 볼 때,
권장 사양에서 mac OS는 램 4GB,
window는 램 8GB를 권장한다는 글을 본적이 있다.
그러면 맥북의 램과 윈도우노트북의 램은 다른 램일까?
아니다.
이렇게, 같은 가용 자원으로도 앞서 말한
OS의 관리 방식을 찾아 들어가면 최적화, 자원효율 등에 대한 많은 생각을 할 수 있게 해준다.
재밌는것 같다.

학부생인데 깔끔하게 정리 잘해주셔서 잘 공부하고 갑니다