
이 글은
https://www.youtube.com/watch?v=J-VP0WFEQsY
를 보고 작성되었습니다! :)
비록 어느 한 서비스인 11번가 서비스를 제공하기 위해
MSA 방식으로의 개발을 설명하고 있지만,
해당 내용을 집중해서 시청한 후엔
MSA에 대한 전반적인 이해를 할 수 있을거라고 생각합니다!
11번가 Spring Cloud 기반 MSA로의 전환 - 지난 1년간의 이야기
들어가기 앞서
11번가는 지마켓, 옥션 등 인터넷 상거래 업체의 후발주자였다.
빠른 시일 내에 개발을 해야 했고, 그러한 이유로 코드 작성이 굉장히 집약적이었다고 한다.
그 이후 8년이 흘렀고,
좋은 의도로 시작된 집약적인 코드는 공통 모듈이 수없이 많아져
200만줄의 코드가 되었다.

그로인해 나쁜 코드가 나쁜 시스템을 만들었다.
빌드하고 배포라도 할 시엔 백명 가량의 개발자들이 대기해야 했고,
코드 한줄의 변경마저도 다른 수십만줄의 코드때문에 힘들었다.
즉, 나쁜 시스템이 나쁜 개발문화를 만들었다.
큰 고민은 다음과 같다
- 잘 사용하지 않는 코드를 식별하기
- 대규모 시스템의 코드를 수정하는것은 어려운 일
- 새로운 아키텍처 방식을 경험해보지 못한것
그렇게 MSA 도입이 시작되었다.
MSA 전략
어떤 전략을 사용했냐면, 점진적인 변화를 꾀했다.

그게 바로 위의 vine(덩굴) 전략이었다.
사진의 가운데 줄기가 기존의 모노리식 아키텍처 코드이고,
덩굴이 마이크로 서비스이다.
덩굴이 자라는 방식으로 줄기를 감싸며 성장하고,
언젠가는 가운데 줄기(모노리식 코드)를 없에더래도
덩굴(MSA 코드)들은 모양(서비스 제공)을 유지할 수 있다.
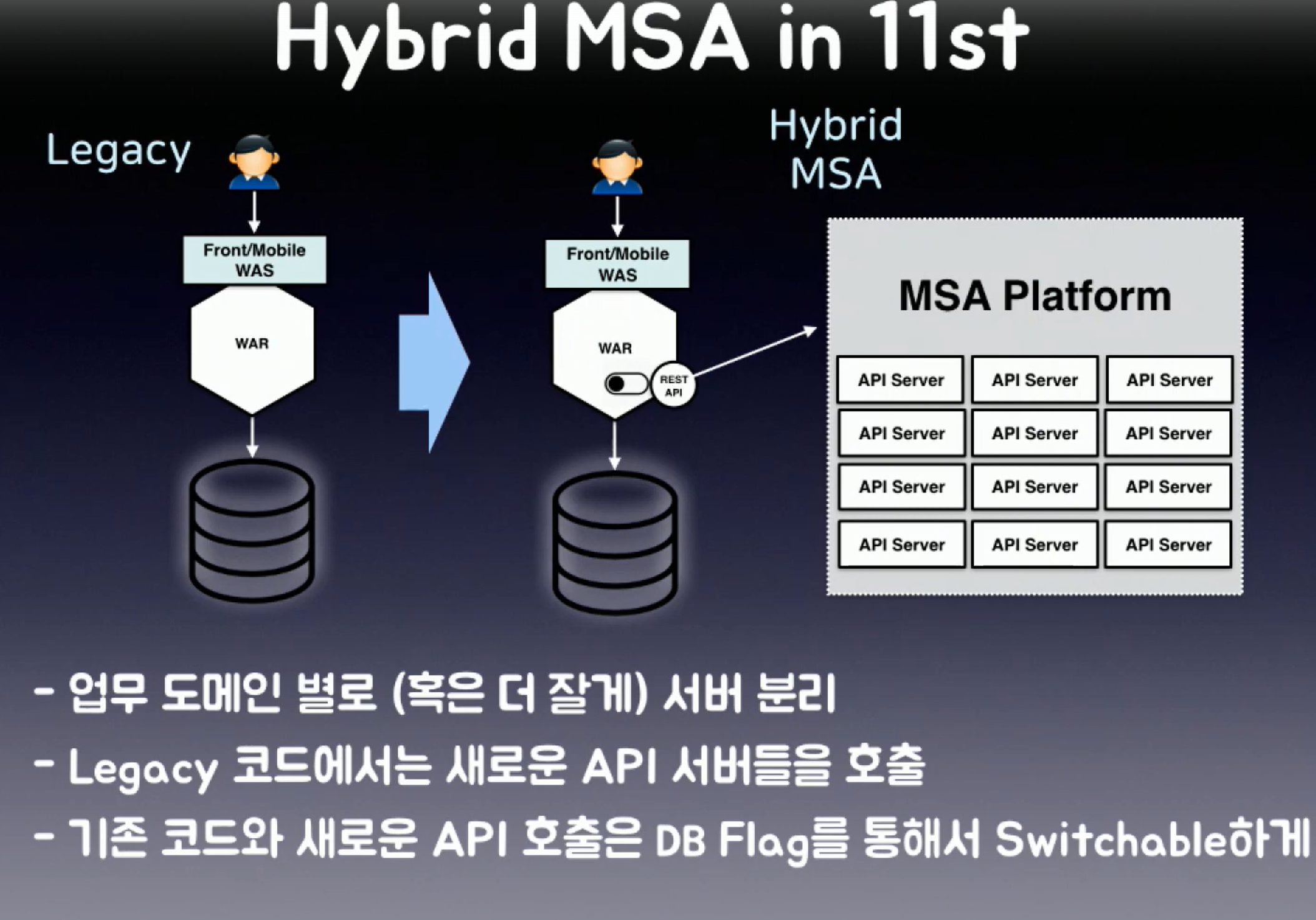
위의 사진에 대한 설명은 다음과 같다.
기존의 11번가는 로그인부터 결제까지,
즉 처음부터 끝까지 하나의 코드로 작동이 되었다.
로그인, 물건 검색, 결제 와 같은 기존의 API들을
하나씩 REST API로 분리하여
새롭게 작성한 코드를 호출하는 식(MSA)으로 진행했다.
이런식으로 진행되면, MSA로의 변경으로 인한 장애가 발생하더래도 기존의 코드(모노리식)로 회귀할 수 있어 점차 MSA 방식으로 변환할 수 있었다.
MSA 플랫폼 선정

MSA로의 전환으로는 많이들 사용하는
NETFLIX OSS와 Spring Cloud를 사용했다.
NETFLIX OSS 라이브러리 간략한 설명
Hystrix : 계단식 오류를 방지하기 위한 Circuit breaker 패턴을 W구현한 라이브러리.
(계단식 오류란? 여러 개의 오류가 연쇄적으로 발생)
Eureka : MSA 서비스들의 목록들을 자동으로 관리.
(로그인 서버, 상품 주문 서버 이러한 서비스들의 목록 관리)
(음.. 컨트롤러 자체에서 API를 호출할 수도 있다. 허나 그렇게 되면 마이크로서비스간 강한 결합이 발생하고, 강한 결합은 SW 변화에 취약하다.
그래서 Eureka와 같은 툴을 이용하는게 더 이상적이기 때문에 그렇게 한다. )
Ribbon : 클라이언트 사이드 로드 밸런서. (Client Side Load Balancer)
Zuul : zuul은 Netflix OSS에서 제공하는 api gateway의 구현체 + 인증, 보안, 로깅 등의 공통 기능을 처리하는 역할.
(API Gateway는 통합적으로 엔드포인트와 REST API를 관리)
(OSI 7 계층중 Application Layer에서 동작)
클라이언트에게 요청이 들어오면, Eureka를 통해 다른 서비스의 위치를 찾고 Zuul을 통해 알맞은 API를 실행하여 다른 서비스로 라우팅하며, 해당 과정에서 Ribbon이 서버의 부하를 체크하여 로드 밸런서 역할을 한다.
이 과정에서 하나의 오류로 인해 계단식 오류가 생기게 되면, Hystrix 라이브러리를 통해 장애 복구가 될때까지 장애 서비스를 피함으로 시스템의 안정성을 보장한다.
(보통 @LoadBalanced 기능을 이용하여 유레카와 리본을 동시에 사용.)
지금은 무슨말인지 이해가 가지 않을 수 있다.
하지만 최종 정리에서 한번 더 설명하므로, 그렇구나 하고 글을 읽는다면
달콤한 결과(?) 를 얻을 수 있다.
넷플릭스 OSS + Spring Cloud 자세한 설명 https://bravenamme.github.io/2020/07/21/msa-netflix/
읽으시면 글 이해가 훨씬 쉬우실겁니다! :)
넷플릭스 OSS 코드
https://github.com/Netflix
이 다음에는,
어떻게 해당 라이브러리와 프레임워크를 사용했는지를 알려주셨다
해당 플랫폼의 Tool들
Hystrix
역할은 다음과 같다.
단위 시간과 단위 실행 횟수에 따른 에러 통계를 계산하여
에러 통계가 설정해둔 퍼센테이지를 넘기면
해당 로직을 실행하지 않는 서킷 브레이커를 작동한다.
Fallback은 해당 로직 대신 다른 로직을 실행한다는 의미
Timeout은 정해진 시간동안 매서드가 완료되지 않았을때


예외의 상황
Hystrix를 잘못사용시에 에러와 좋지 못한 코드까지 숨겨질수 있다 .
(코드가 맨 처음부터 에러가 있다면, 내가 원하는 로직이 실행되지 않고 해당 로직을 피하고 설정해둔 다른 로직을 실행하는 fallback이 실행되어
원래 실행하려는 로직 자체가 실행되지 않으므로, 다른 로직만이 수행된다. 만약 다른 로직이 기존의 로직보다 간단하고 빠르다면, 원하는대로 작동되지 않아도 결과는 좋을 수 있다)
그래서 처음엔 비정상적으로 서버 속도가 빠르게 측정되기도 하셨다고 한다.
해당 예외상황을 해결하기 위해,
다른 로직를 실행하게 하도록 만드는 Hystrix의 통계에 집계되지 않도록 하는
HystrixBadRequestException을 사용했다고 한다.

그리고
hystrix의 기능중 하나인 timeout에 대해서는,
(일정시간동안 처리되지 못하면 멈춰야함)
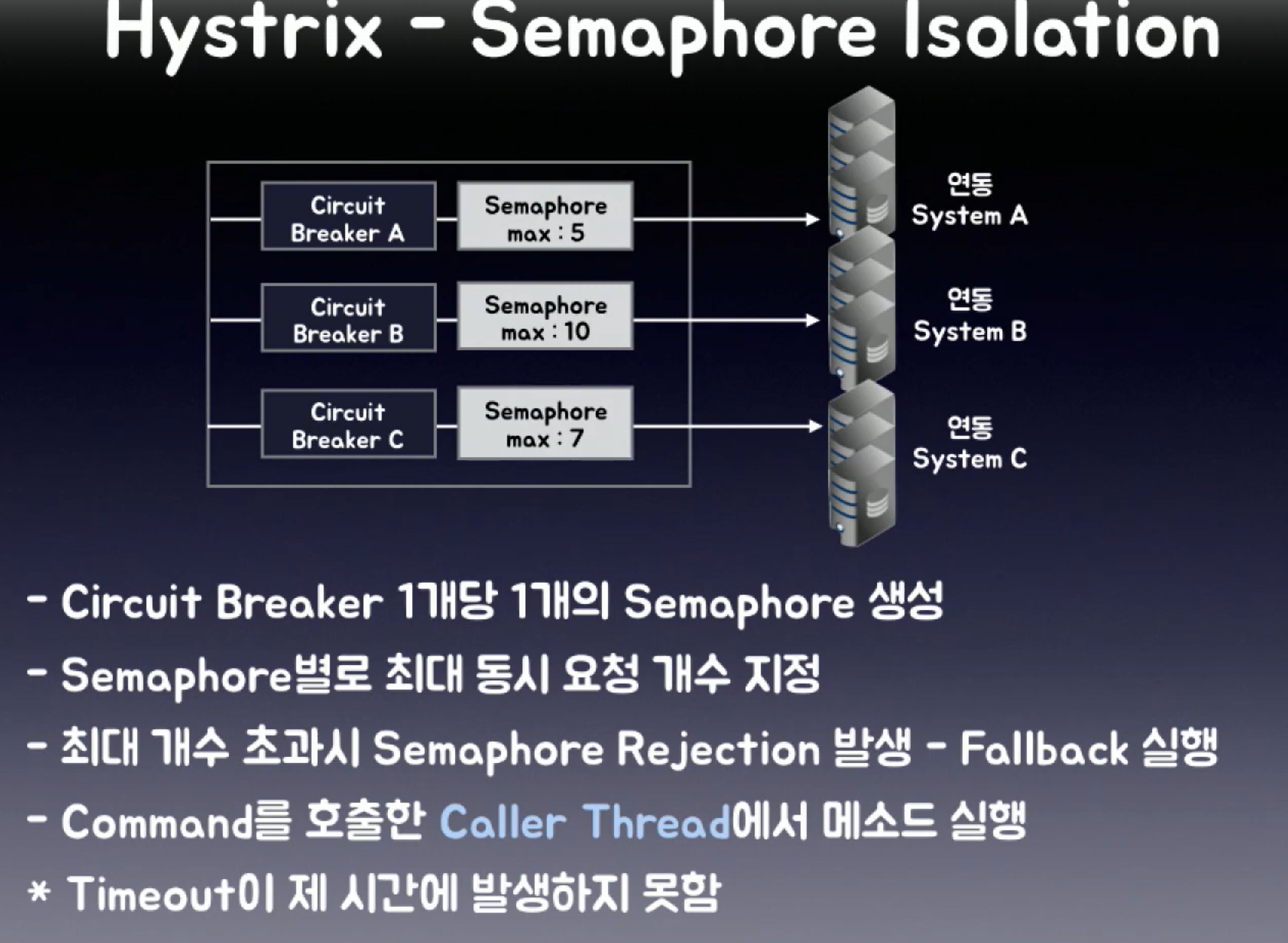
Semaphore isolation(세마포 아이솔레이션)을 사용하면
공유 리소스를 사용하므로 쓰레드를 강제로 종료시킬 수 없어 Timeout을 발생시킬 수 없었다.

그래서 각 스레드가 독립적으로 자신만의 복사본 리소스를 사용하는 방식인
Thread Isolation(쓰레드 아이솔레이션) 방법을 통해 Timeout을 실현할 수 있었다.
(스레드 간의 상호작용 없이 독립적으로 실행되기 때문에 스레드 중단을 통한 Timeout 가능)
Ribbon
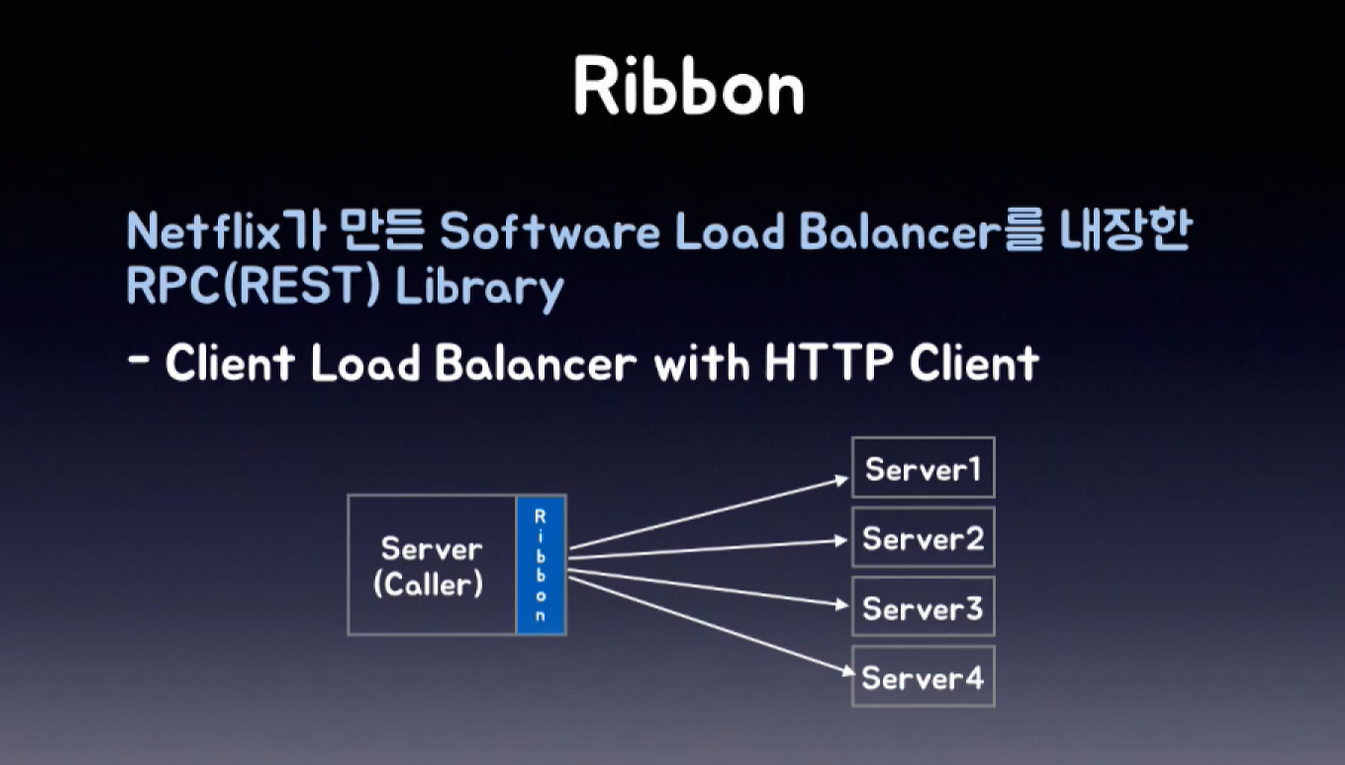
클라이언트 개념은 상대적이다.
API를 요청하는쪽이 클라이언트가 된다.
마이크로서비스 각각에 요청을 보내는 서버가 클라이언트가 되는것이다.
그래서 각각의 서버에 요청을 보내는 Ribbon은 클라이언트 로드밸런서이다.

이러한 다양한 매서드를 통해
기존의 로드 밸런서보다 더 자세한 로드밸런싱 기능을 수행할 수 있다
Eureka

좀 많이 간단하게 말해서, 전화번호부라고 생각하면 쉽다.
(application.yml 파일에 유레카 서버의 주소를 설정하여 등록)
(엔드포인트 B를 호출하는 API A가 있다고 하고,
B-1, B-2, B-3은 각각의 엔드포인트 B 담당의 API라고 하면,
B-1, B-2, B-3에 유레카를 통해 A를 등록)
전화번호부에 전화를 걸지 말지는,
해당 번호에 전화 거는 사람의 수를 봐서
Ribbon이 정해준다고 생각하면 된다.
유레카는 스프링 클라우드 어플리케이션의 라이프사이클과 맞물려 돌아간다.
예를 들어,
스프링 클라우드 어플리케이션이 죽으면 유레카의 해당 서버 목록이 삭제되고
서버가 시작되면 자동으로 자신의 상태를 등록한다. 해당 설명이 아래의 사진이다.

이렇게 리본과 유레카의 조합을 사용하면, 복잡한 과정을 거치는것 없이
스프링 어플리케이션을 하나만 더 띄우는 것으로 MSA에 참여할 수 있다.
Zuul
일반 API gateway보다 Zuul을 사용함의 이점이 있다
위의 리본과 유레카를 사용하며 연결됨으로서
(같은 넷플릭스 OSS이므로 RibbonRoutingFilter를 이용해 연결 가능)
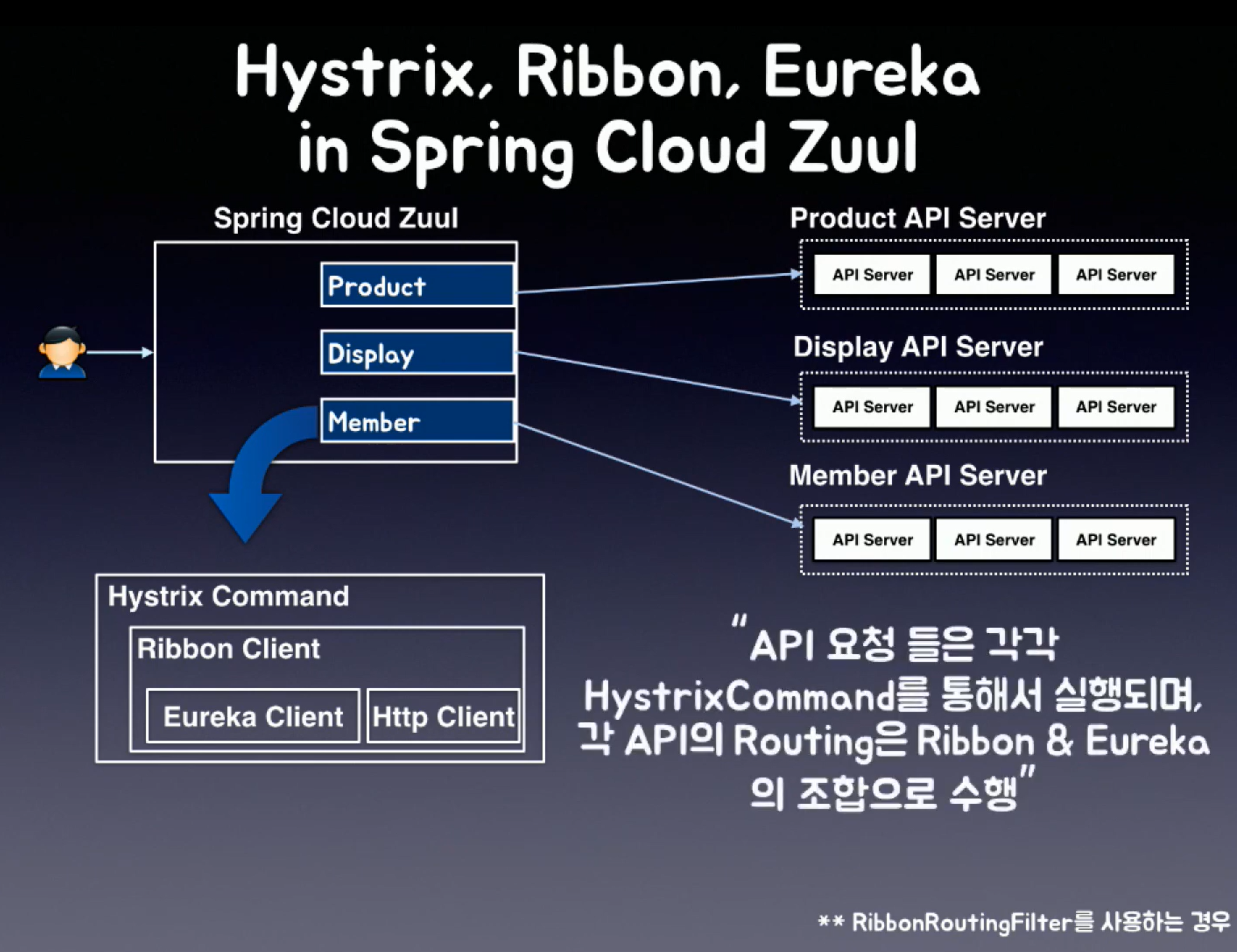
게이트웨이의 역할인 엔드포인트를 지정에 있어,
해당 엔드포인트는 zuul과 연결된 Eureka가 가지고 있어
쉽게 사용할 수 있다는 이점이 있고,
API gateway도 연결된 Hystrix에 의해 관리가 되며 서버가 죽지 않을 최후의 보루가 생긴다. (유레카의 서킷브레이커)
(API gateway가 죽으면 어마어마하게 큰 궁전의 대문이 닫힌다고 생각하면 된다. 궁전 내부의 다른 문들이 아무리 잘 정비되어있어도, 대문이 닫혀있으므로 사용할 수 없게 된다.)
여기까지 넷플릭스OSS 스프링 클라우드의 라이브러리들을 사용하며 해주신 설명이다.
이후엔 또 다른 고민이 생겼다.
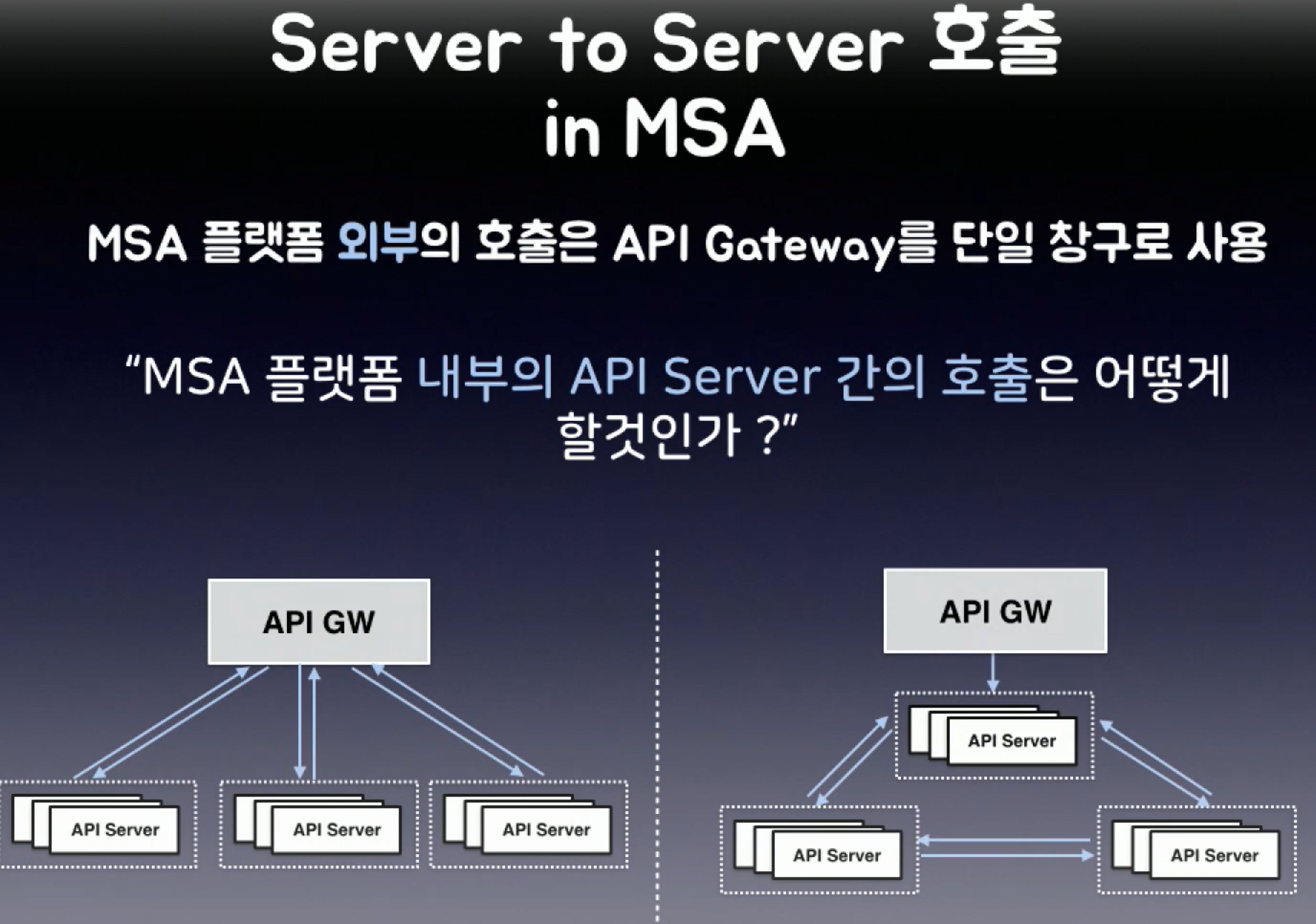
-
API gateway만 서버를 호출하는 중추 역할을 시킬것인지 (왼쪽)
-
혹은 서버가 서로서로 어느정도 서로를 호출할것인지 (오른쪽)
1번은 모든 API를 게이트웨이가 관리하므로,
서버가 허용하지 않은 API를 제어할 수 있고,
상황을 통제할 수 있다.
하지만 gateway가 죽으면 모든 서버가 무용지물이 되고
게이트웨이에 대한 부하가 엄청나다.
따라서
2번 방법을 적용했다.
API 서버도 서로간에 호출을 할 수 있도록 코드를 작성한것이다.
음.. 그러면 API서버가 서로 다른 서버의 위치를 어떻게 아나요?
라는 질문에는,
유레카를 통해 해결하셨다고 한다.
장애 유형별 동작 예
이제 계속해서 영상을 보며 이해가 가니까,
더 재밌게 시청할 수 있었다.
하나의 API서버, 즉 마이크로서비스중 하나가 장애가 생기면 어떻게 될까?

Hystrix가 장애를 감지하고 서킷브레이커를 수행하므로
히스트릭스에서 무슨 작업을 할까?
라고 생각한 당신! 나와 비슷하다.
하지만, 아니다.
-
유레카는 스프링 어플리케이션과 생명 주기를 같이한다고 했다. 즉, API서버가 죽으면, 해당 API 서버도 자동으로 유레카의 목록에서 자동으로 지워진다.
-
유레카뿐만 아니라, 리본 자체에서도 IOException 예외가 생길때,
즉 호출을 했는데 호출을 받지 않는 입출력 에러가 나오면, 다른 인스턴스(다른 API 서버)로 Retry한다. -
Hystrix가 작동하지 않는 이유는, 예를 들어 내가 Hystrix의 서킷 브레이커 호출 통계를 50퍼센트로 설정했다고 하자. 위의 사진을 보면, 세대 중 한대. 즉 33퍼센트의 통계가 잡히며 작동하지 않는다.
이렇게 유레카와 리본 선에서 해당 장애는 해결이 된다.
Hystrix는 시간초과, 통계 이상의 에러인 Timeout과 Fallback 문제를 해결해 준다.
다음은 다른 장애상황 예시이다.
API 서버 자체가 아닌 API 서버 안의 여러 API중 단 하나의 API에 문제가 있는 경우를 생각하자.

이런 경우가 Hystrix가 작동한다.
문제있는 해당 API로 인해 시간이 느려지거나, 통계 이상이 생겨
Hystrix의 Timeout과 Fallback이 작동하기 때문이다.
종합
이렇게 11번가의 Spring Cloud 기반의 MSA서버는 완성되었다.
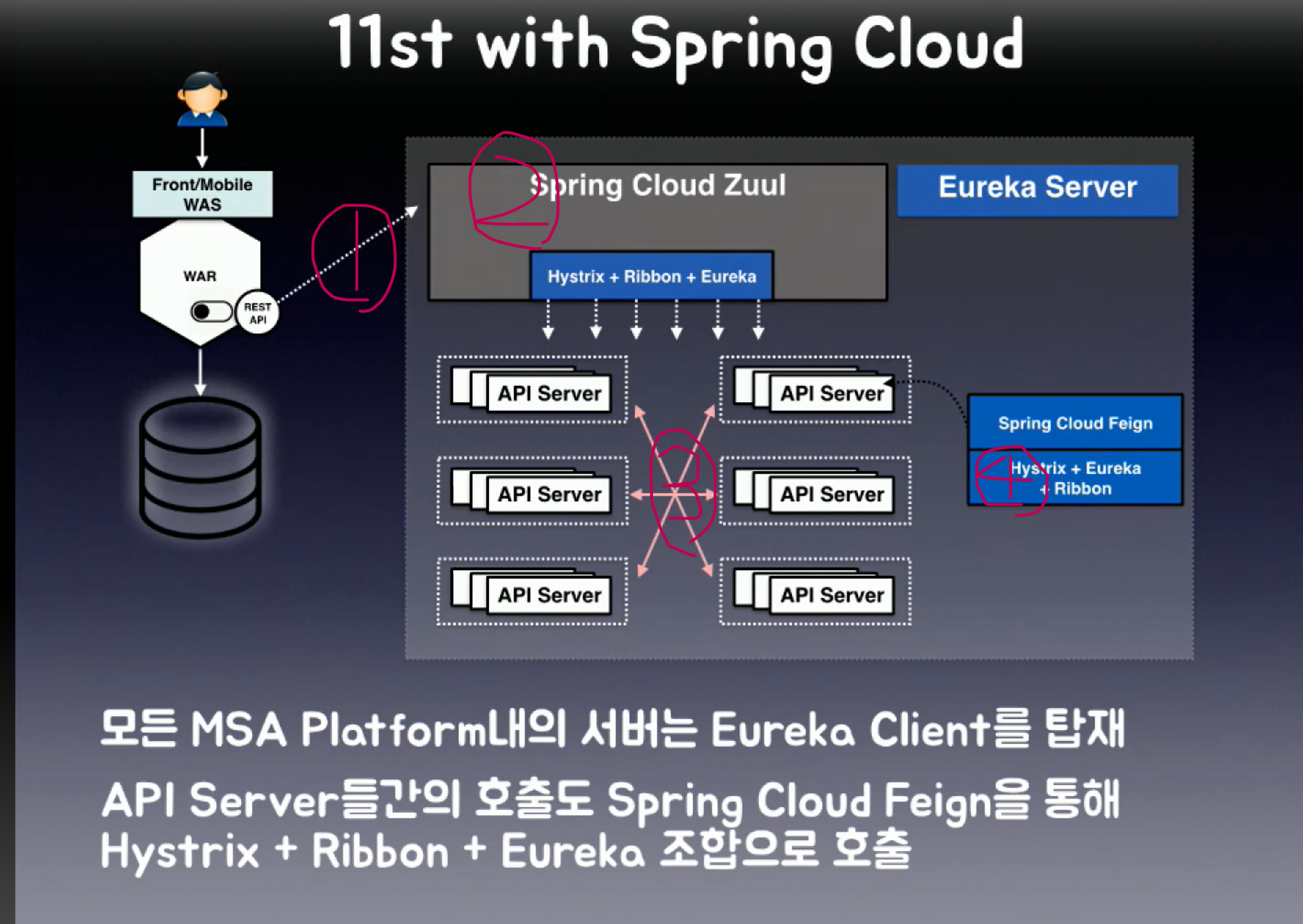
-
클라이언트에게 요청이 들어오면
-
API게이트웨이인 Zuul이 어디로 가라고 명령을 내리고,
해당 명령을 내리는 과정에서
명령을 수행하는곳이 어디인지 찾아야 하는 Eureka,
명령을 수행하는곳이 지금 요청을 받을 수 있는 상황인지를 보는 로드밸런서 Ribbon,
그 명령이 또다른 오류를 낳지 않고 제대로 수행되는지 보는 Hystrix가 사용된다. -
해당 API가 하나의 마이크로 서버에 도착하고, 또다른 서버를 부를 수도 있다.
-
그렇게 또다른 서버를 찾는 과정에서 또한 유레카와 리본이 사용된다
마치며
음... 뭔가 유익한 영상을 본다는 생각으로
한시간정도의 영상을 보려고 했다.
하지만 유익하긴 했지만 많은 양의 공부를 했다...
덕분에 Spring Cloud, NETFLIX OSS 기반의 MSA 코드가 작동되는 환경을 어느정도는 이해를 한 것 같다.
물론 모르는 내용이 있으면 또다시 구글링을 하고
ChatGPT에게 질문을 해가며 봤기 때문에,
실제로 영상을 보고 이해하는데는
훨씬 더 긴 시간이 든 것 같다.
뭐 다른 분야도 마찬가지이겠지만,
이 분야는 정말 알면 알수록 초라해지는 기분이다.
단순히 CRUD구현하고 어? 와따시.. 어쩌면... 천재개발자..? 라는 헛된 생각이 와장창 무너지는게 느껴진다.
하지만, 세상에는 기술들이 빠른 속도로 나오고 있기에,
이렇게 알아가는게 좋기도 하고, 모르는 내용을 찾아가며 듣다보니
도중에는 이해가 쏙쏙 되어가며 MSA 방식에 대해 어느정도 이해한 것 같아 즐거웠다.

헉 그래서 200만줄의 코드를 직접 읽으셨다는 건가요?! 대단해요!!