Retriever
- Retriever는 비정형 쿼리가 주어지면 문서를 반환하는 인터페이스이다. 벡터 저장소보다 더 일반적이다. Retriever는 문서를 저장할 필요 없이 단지 반환만 할 수 있다.
pip install chromadb tiktoken transformers sentence_transformers openai langchain pypdf
import os
import openai
import tiktoken
os.environ["OPENAI_API_KEY"] = 'API_KEY'
tokenizer = tiktoken.get_encoding("cl100k_base")
# 토크나이저 기반으로 토큰 개수를 새줌
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/Users/kimjehyeon/study/강의대화1.pdf")
pages = loader.load_and_split()
# chunking
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50, length_function=tiktoken_len)
texts = text_splitter.split_documents(pages)
# text embedding
# embedding model
from langchain.embeddings import HuggingFaceEmbeddings
model_name ="jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# texts들에 대해 hf 임베딩 모델로 임베딩 하는 과정 -> 이를 docsearch에 저장
docsearch = Chroma.from_documents(texts, hf)
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
openai = ChatOpenAI(model_name="gpt-3.5-turbo",
streaming=True, callbacks=[StreamingStdOutCallbackHandler()],
temperature = 0)
qa = RetrievalQA.from_chain_type(llm = openai,
chain_type= "stuff",
retriever = docsearch.as_retriever(
search_type="mmr",
search_kwargs={'k':3, 'fetch_k': 10}),
return_source_documents=True)
query="1대1 대화하는 법에 대해 설명해줘"
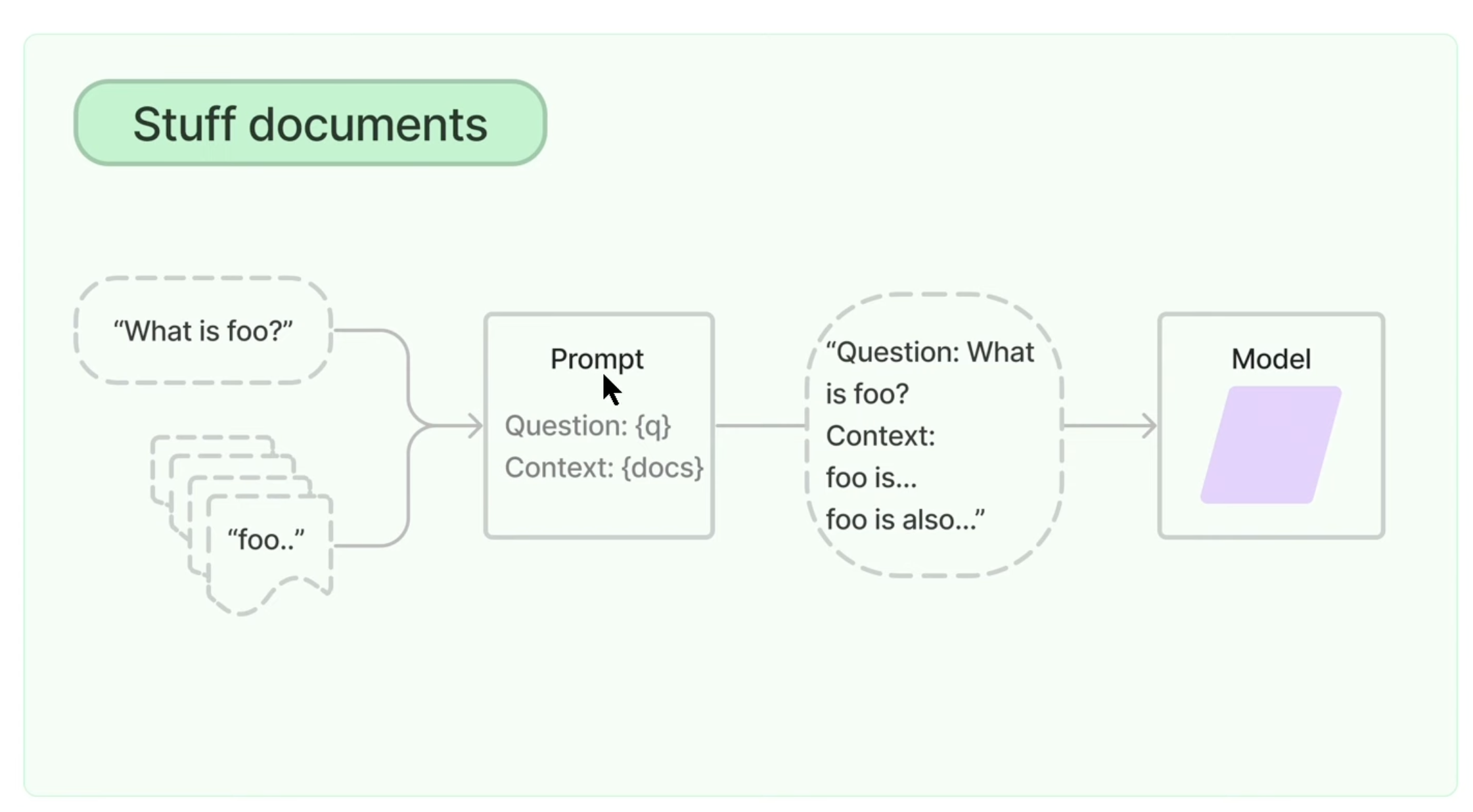
result = qa(query)Stuff documents chain
- 사용자가 질문을 하면 이 질문과 가장 유사한 청크들이 출력이 되면 LLM에게 질문과 유사한 청크들을 그대로 넘겨주는 것이다. 이렇게 될 경우 LLM이 받을 수 있는 토큰제한이 있기 때문에 토큰 이슈가 발생할 수 있다.
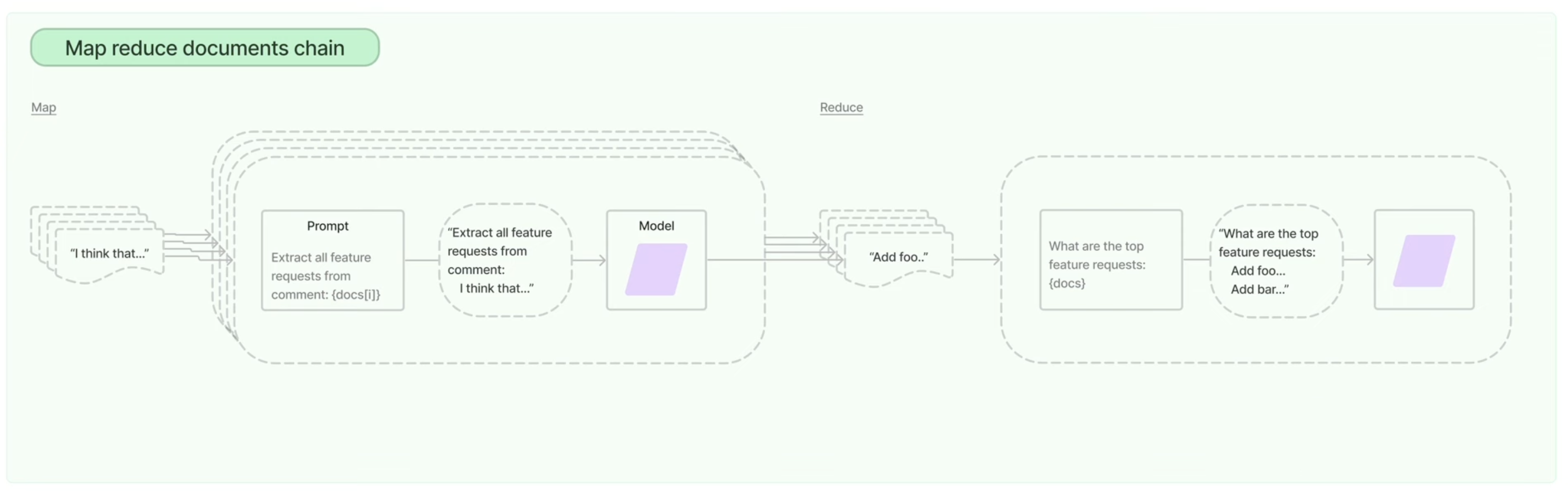
Map reduce documents chain
- 첫 과정은 위와 유사하다 질문을 하고 유사한 청크들이 나오면 이러한 텍스트 청크들에 대해 각각 요약을 수행한다. 연관문서가 4개라고 하면 4개의 요약이 생기는 데 이걸 map이라고 한다. reduce에서는 최종 요약을 만드는 과정인데 이러한 과정을 통해 토큰 이슈를 해결할 수 있다. 하지만 요약으로 인해 실행시간이 오래걸린다는 점과 LLM을 반복적으로 호출해야해서 비용적인 문제가 있다.
Refine documents chain
- 좋은 품질의 답변을 얻기 위해 사용하는 chain 타입이다. refine은 누적을 한다고 생각하면 된다.
Map re-rank documents chain
- 사용자의 질문과 텍스트 청크를 프롬포트에 넣고 llm에게 답변을 받으면 원래는 answer하나만 받았는데 score까지 받는 것이다.
- 시간이 오래걸리고 llm을 많이 호출해야해서 비용적인 문제가 있지만 텍스트 청크 각각이 구분된 답변을 하고 질문을 하는 것에 있어 높은 유사성을 요구하는 경우에는 map-re-rank를 사용하면 높은 품질의 답변을 얻을 수 있다.
