
오늘은 데이터분석 competition사이트로 유명한 kaggle에서 가장 대표분석 주제인 titanic 데이터를 분석보았다. 목적은 생존자(survived)변수와 그 외 나머지 feature들의 관계를 파악해 생존자를 예측하는 것이다.
1. 데이터 및 변수 확인
- 데이터 불러오기

2. 데이터 전체적으로 살펴보기
- .dscribe() : 수치형 데이터에대해 평균, 표준편차, max값, min값 등 특성을 보여준다.
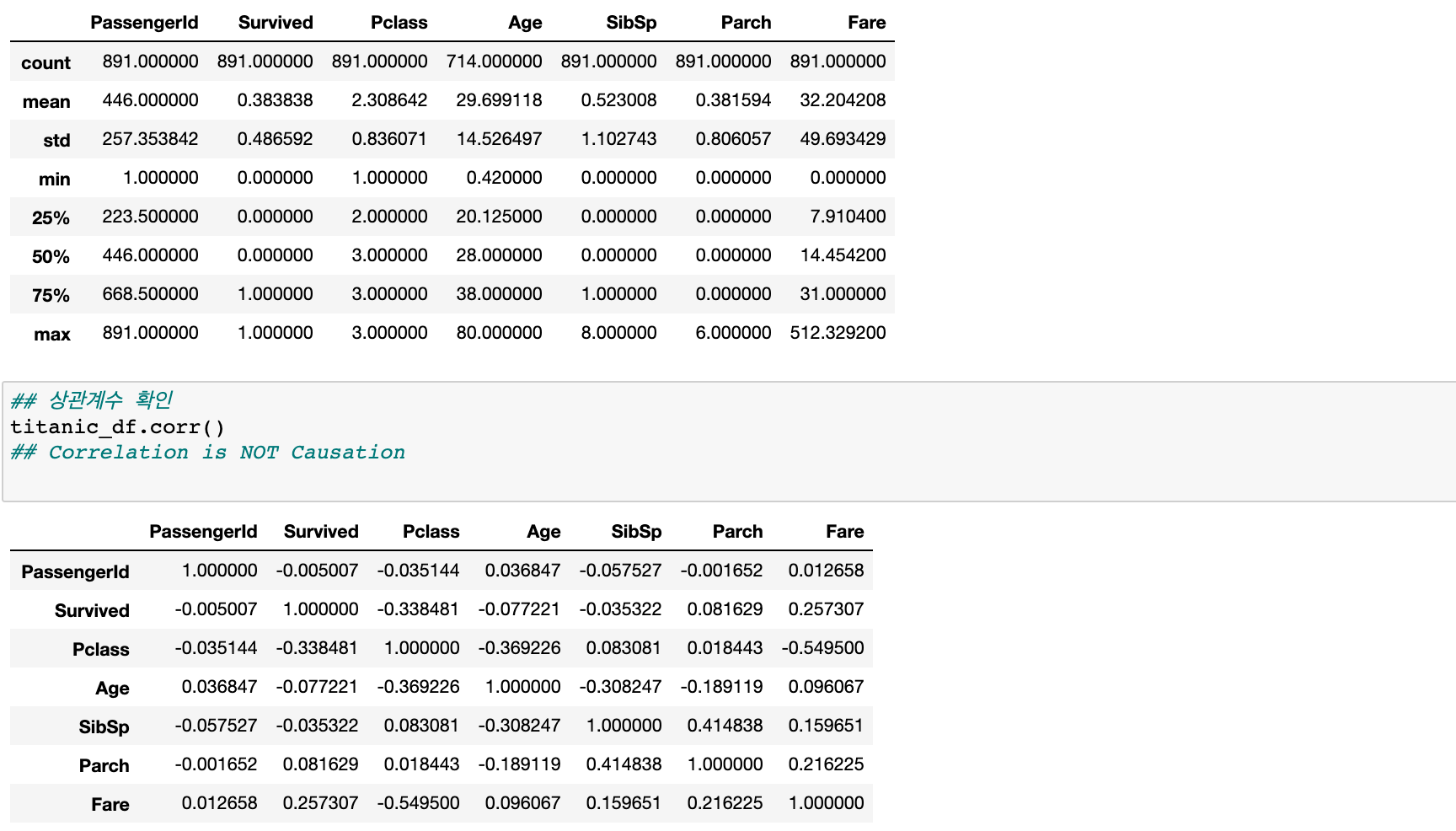
- .corr() : 변수들간의 상관관계를 보여준다.
위 두 함수와 .dtypes(데이터 타입확인) 그리고 결측값을 확인하는 .isnull().sum() 함수는 데이터를 불러오면 습관적로 우선 확인하는게 좋을 것 같다.
타이타닉 데이터에서는 특히 correlation을 통해 Pclass(아마 티켓의 등급인듯)가 생존결과에 큰 영향을 준다고 예측할 수 있다.
3. 데이터 개별 속성 파악하기
1) 생존자 변수 : 안타깝게도 생존하지 못한사람(0)이 생존자(1) 보다 많다.

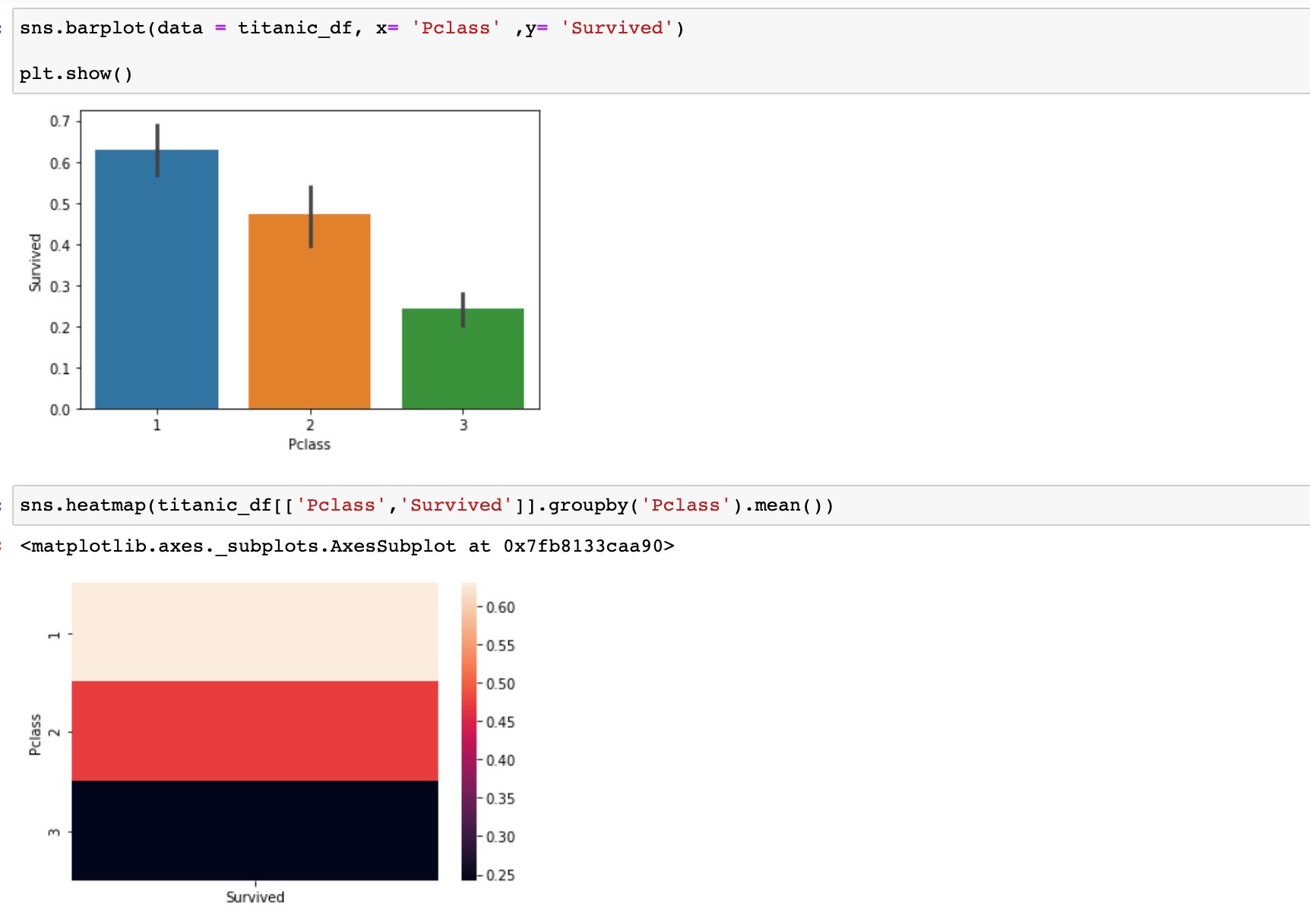
2) Pclass : 등급이 내려갈수록(1 -> 3등급) 생존자가 적다. 히트맵을 통해 비율도 볼 수 있다.
- 여기서 내가 오해한점은 barplot을 아래와 같이 그리면 Pclass에 따른 생존자의 수가 나오는 것이아니라 각 Pclass별 인원 중 생존자 얼마나 되는지 비율이 나온다는 것이다.
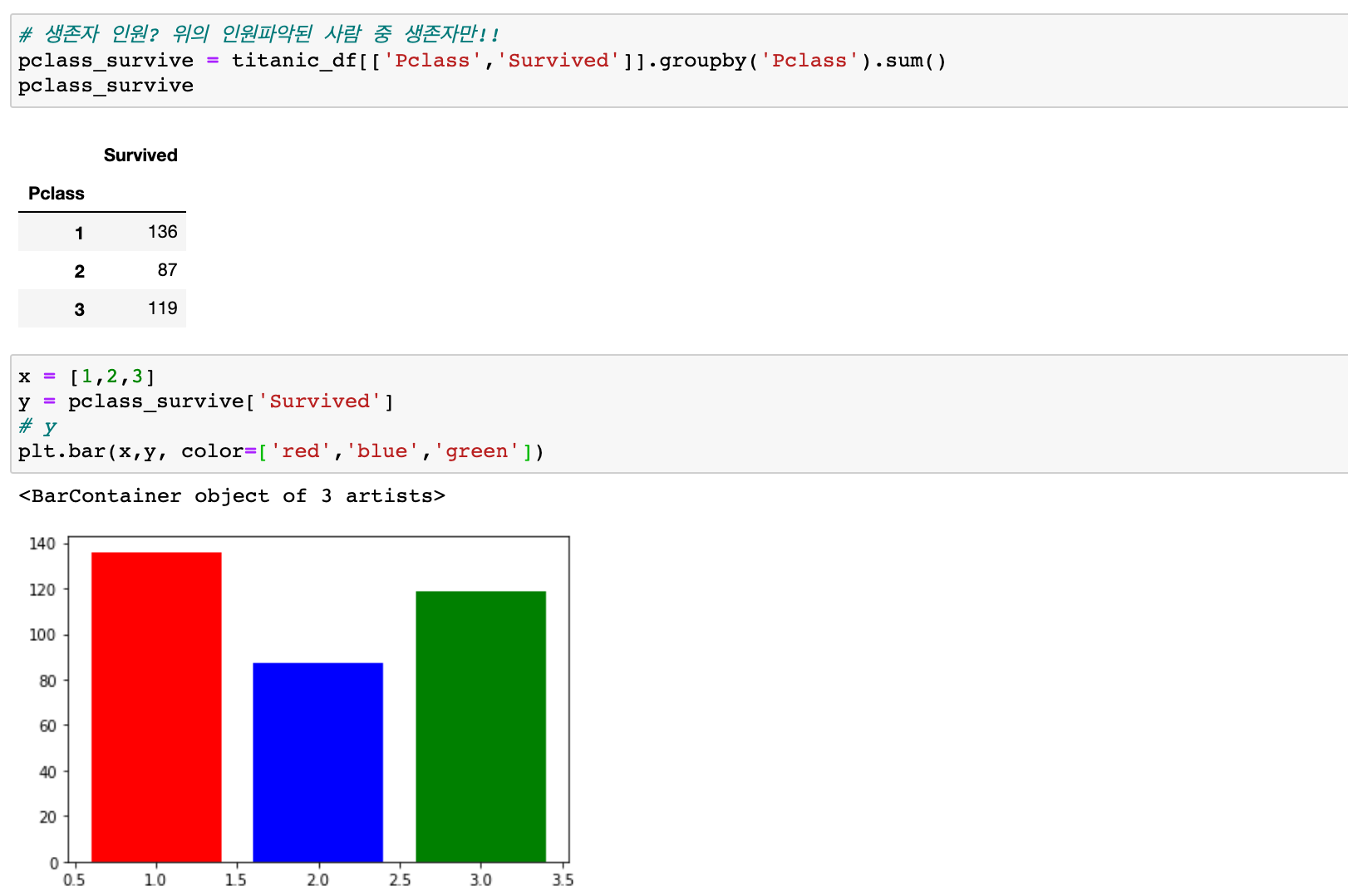
만약 Pclass별 생존자 수를 알고싶다면 아래와 같이 작성해주면 된다.
3) 성별 - 여성이 남성보다 생존률이 매우 높다.

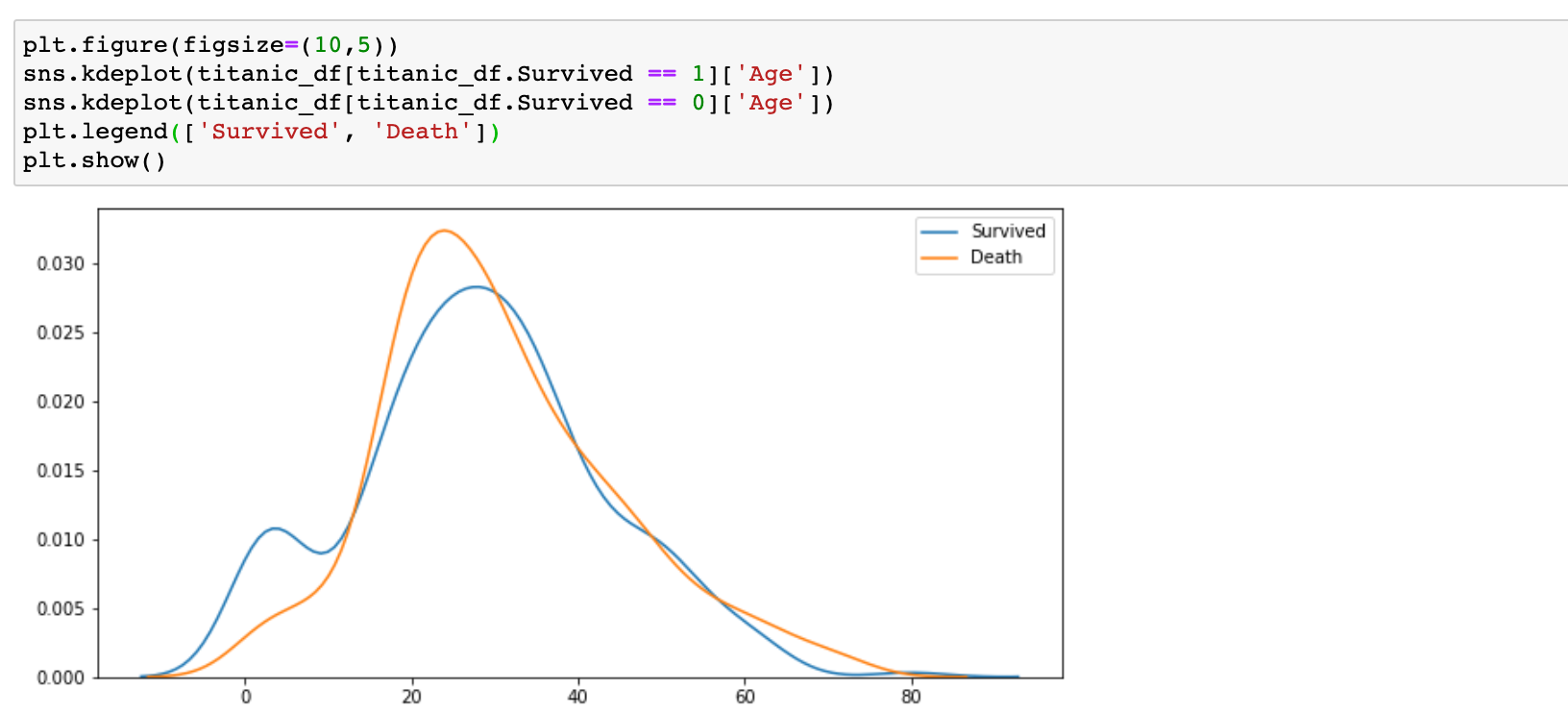
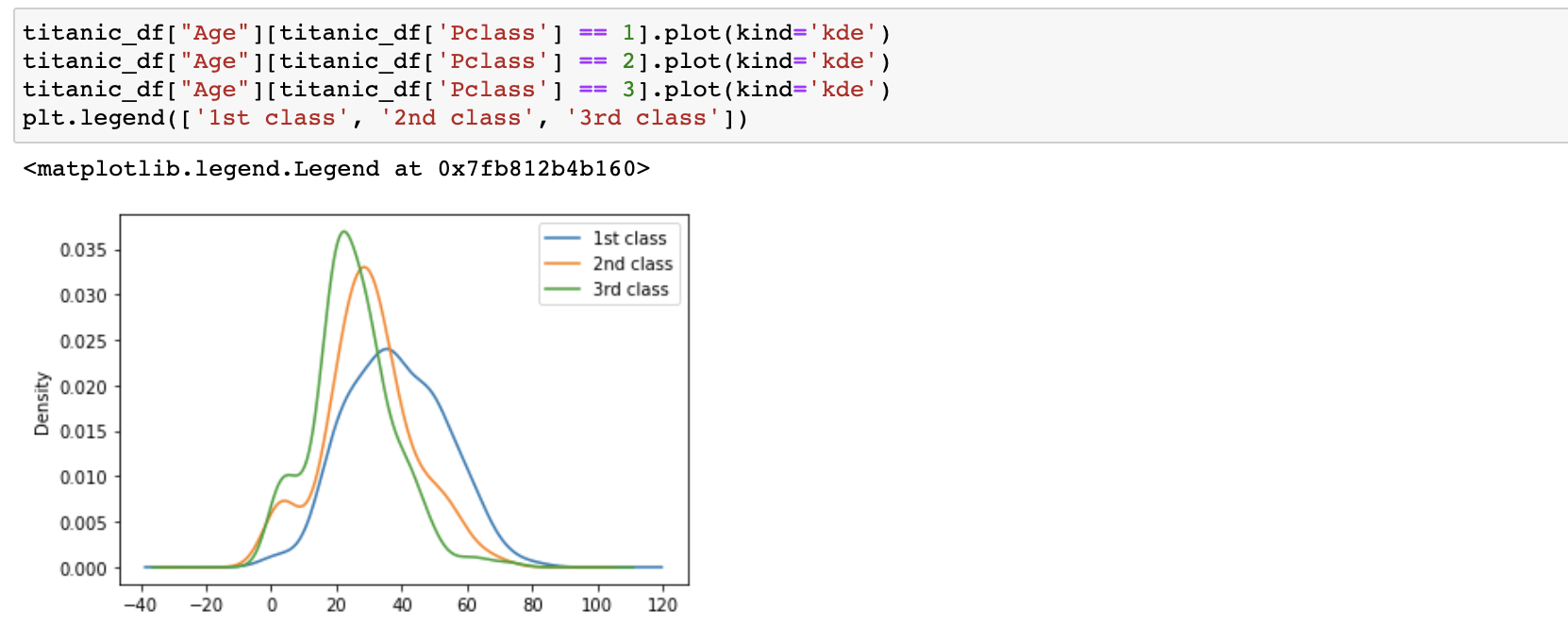
4) 나이(Age) - 커널 밀도그래프(kernel density plot)을 이용해 나이분포에따른 생존자 비율을 확인했다.
- 나이가 매우어린경우 생존률이 높았고 20대, 70대 부분에서는 생존율이 많이 떨어졌다.
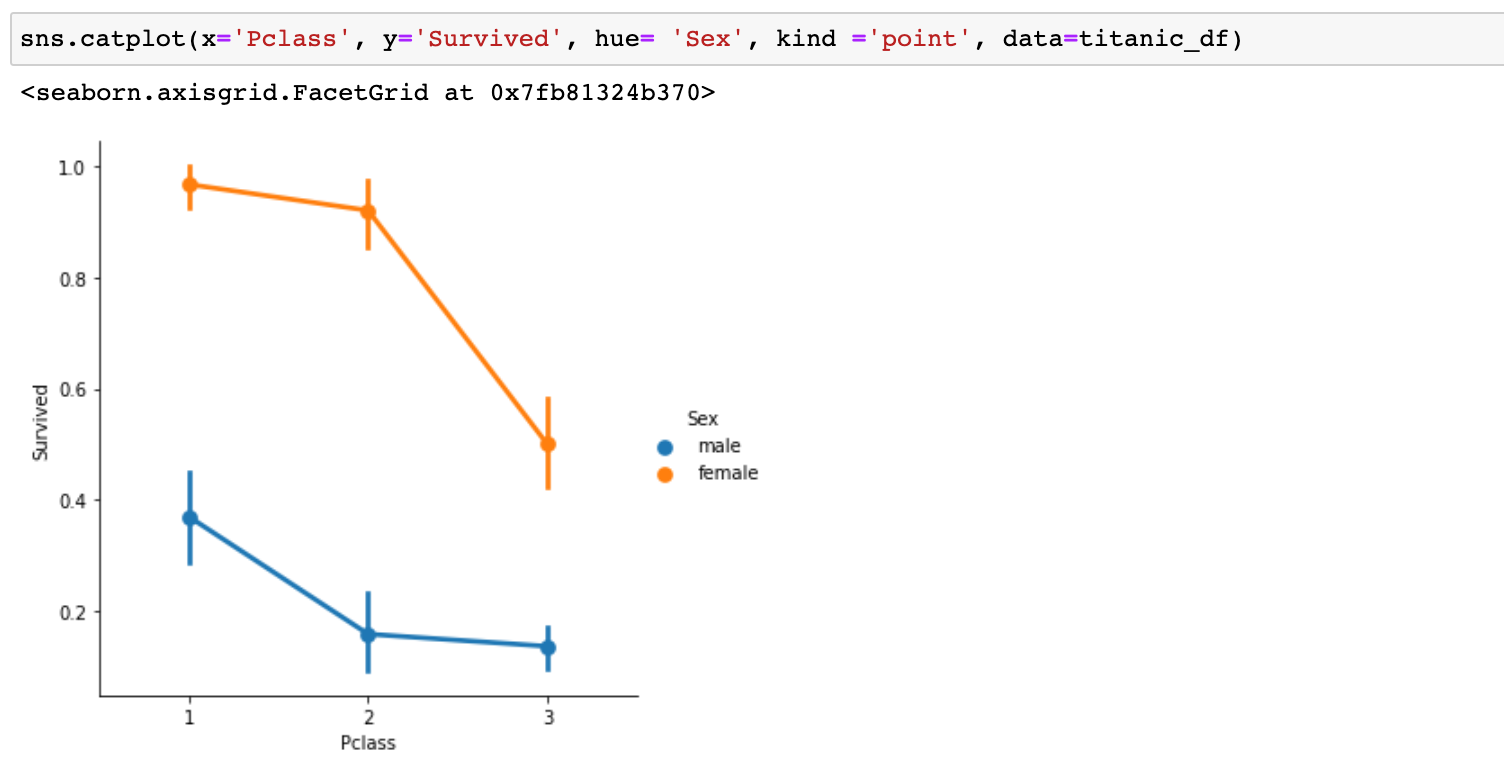
5) 성별 + Pclass vs Survived - hue는 정확한 용어가 맞는지 모르겠는데 구분자? 역할을 한다. 아래 그래프는 Pclass에따른 생존자비율을 성별로 구분하여 시각한 것이다.
6) Age + Pclass - plot 명령을 여러번하여 하나의 그래프에 시각화 가능하다. 이때는 알기 쉽게 legend 함수를 이용해 범례을 리스트 원소와 그래프의 순서에 맞게 지정해준다.

원하는 대로 살자