
Python에서 dataframe 시각화를 위해 보통 matplotlib과 seaborn 패키지를 사용한다.
간단히 설명하면 matplotlib은 그래프를 그리기 위함이고 seaborn은 그래프를 조금 더 다양한 형태로 이쁘게 표현하기 위한 목적으로 쓰인다.
1. matplotlib
- 모듈 또는 패키지 import
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd- plot 하기
## 아래 리스트는 y값, x값은 인덱스
plt.plot([1,2,3,4])
plt.show()
## plot 사이즈 지정
plt.figure(figsize=(9,6))
x = np.arange(-10,10,0.01) ## -10부터 10까지 0.01간격으로 랜덤수 발생
plt.plot(x, x**2)
x = np.arange(-10,10,0.1)
## 맥에서 그래프에 한글 제목이나 label명 지정시 깨져나와서 폰트를 변경해줌
plt.rc('font', family='AppleGothic')
sns.set(font='AppleGothic',
rc={"axes.unicode_minus":False},
style='darkgrid')
plt.title('f(x) = x^3 그래프')
plt.axis([0,10,0,1000]) ## [x축 시작좌표, x축 끝좌표, y축 시작좌표, y축 끝좌표] 만 보여줌
plt.xticks([1,2,3,4,5,6,7,8,9]) ## 그래프의 x축 눈금
plt.yticks([i for i in range(0,1000, 100)]) ## y축 눈금
plt.xlabel('xx') ## x축 레이블
plt.ylabel('yy') ## y축 레이블
plt.show()
x = np.arange(-10,10,0.01)
plt.axis([0,10,0,100])
plt.title('그래프')
plt.plot(x, x**2, label='trend' ) ## 범례명 trend 지정, 아래 legend() 같이 설정!
plt.legend()
plt.show(){kind=link}
- 꺽은선 그래프
x = np.arange(20) ## 0~19 까지
y = np.random.randint(0,20,20) ## 0이상 20미만 사이 중 하나의 값 랜덤하게 20번 발생
plt.yticks([0,5,10,15,20])
plt.xticks([0,5,10,15,20])
plt.axis([0,20,0,20])
plt.plot(x,y)
plt.show()- 산점도 그래프
plt.scatter(x,y)
plt.show()
- Bar 그래프
plt.bar(x,y)
plt.xticks([i for i in rang(0,20,1)])
plt.show()
- Box 그래프
- min, Q1, Q2(중간값), Q3, max을 알 수 있다.
plt.box((x,y))
plt.title('box plot x y')
plt.show()
- pie 그래프
z= [1,2,3,4]
plt.pie(z, labels =['one','two','three','four','five'])
- 히스토그램
- 도수분포표를 직사각형의 막대 형태로 나타낸다.
- "계급"으로 나타낸 것이 특징 : 0,1,2가 아니라 0~2까지의 "범주형" 데이터로 구성 후 그림을 그림
plt.xticks([i for i in range(0,20,2)])
plt.hist(y, bins = np.arrange(0,20,2))
plt.show()
2. seaborn
- 커널밀도 그림(kernel density plot)
- 히스토그램과 같은 연속적인 분포를 곡선화해서 그린 그림
- sns.kdeplot()
sns.kdeplot(y, shade=Ture)
plt.show()
- 카운트 그림(count plot)
- 범주형 column의 빈도수를 시각화 -> groupby 후의 도수를 하는 것과 동일한 효과
- sns.countplot()
vote_df = pd.DataFrame({'name' : ['Andy','Bob', 'Cat'], 'vote':[True,True,False]})
sns.countplot(x=vote_df['vote'])
plt.show()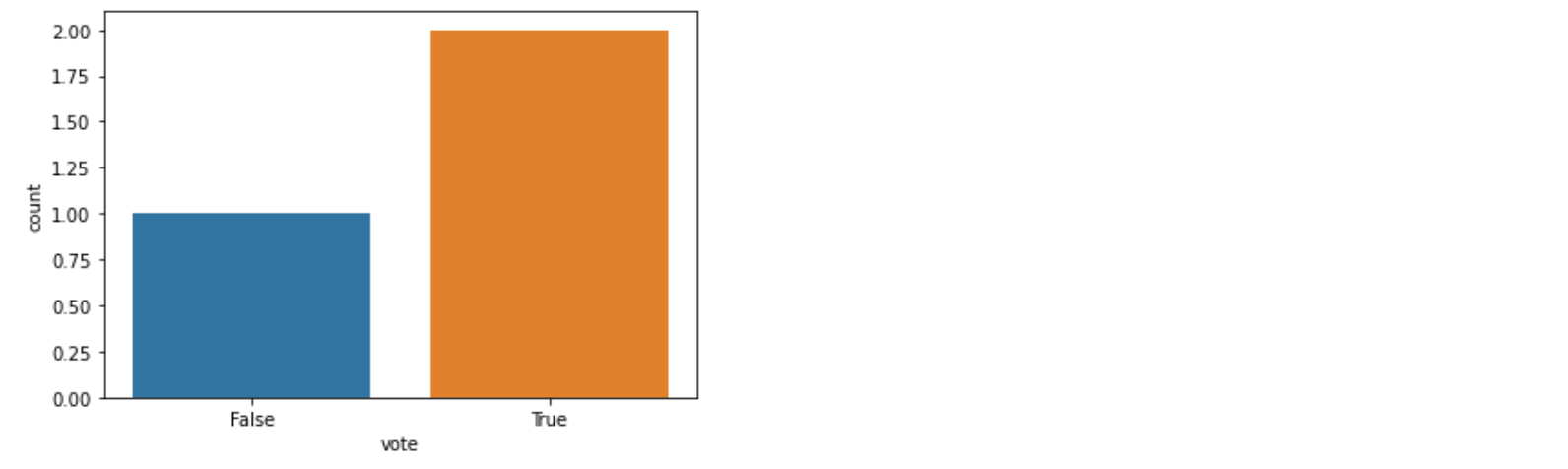
- 캣 그림(cat plot)
- 숫자형 변수와 하나 이상의 범주형 변수의 관계를 보여주는 함수
- sns.catplot()
s=sns.catplot(x ='WHO Region', y='Confirmed', data=covid) #kind='violin')
s.fig.set_size_inches(8,5)
plt.xticks(rotation=90) ## x label 90도 회전
plt.show()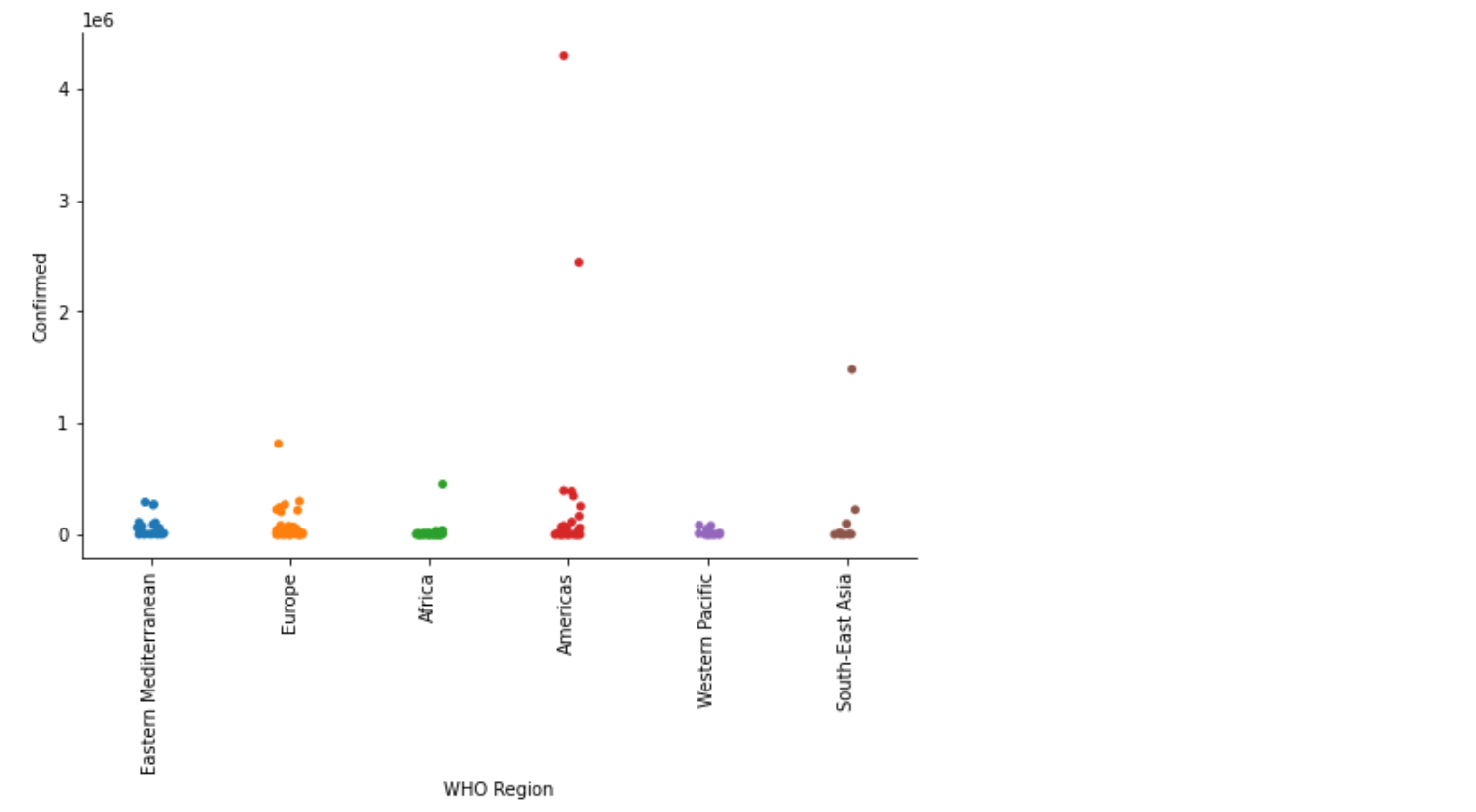
- 스트립그림(strip plot)
- scatter plot과 유사하게 데이터의 수치를 표현하는 그래프
- sns.stripplot()
plt.figure(figsize =(10,7))
sns.stripplot(x='WHO Region, y='Recovered', data=covid)
plt.show()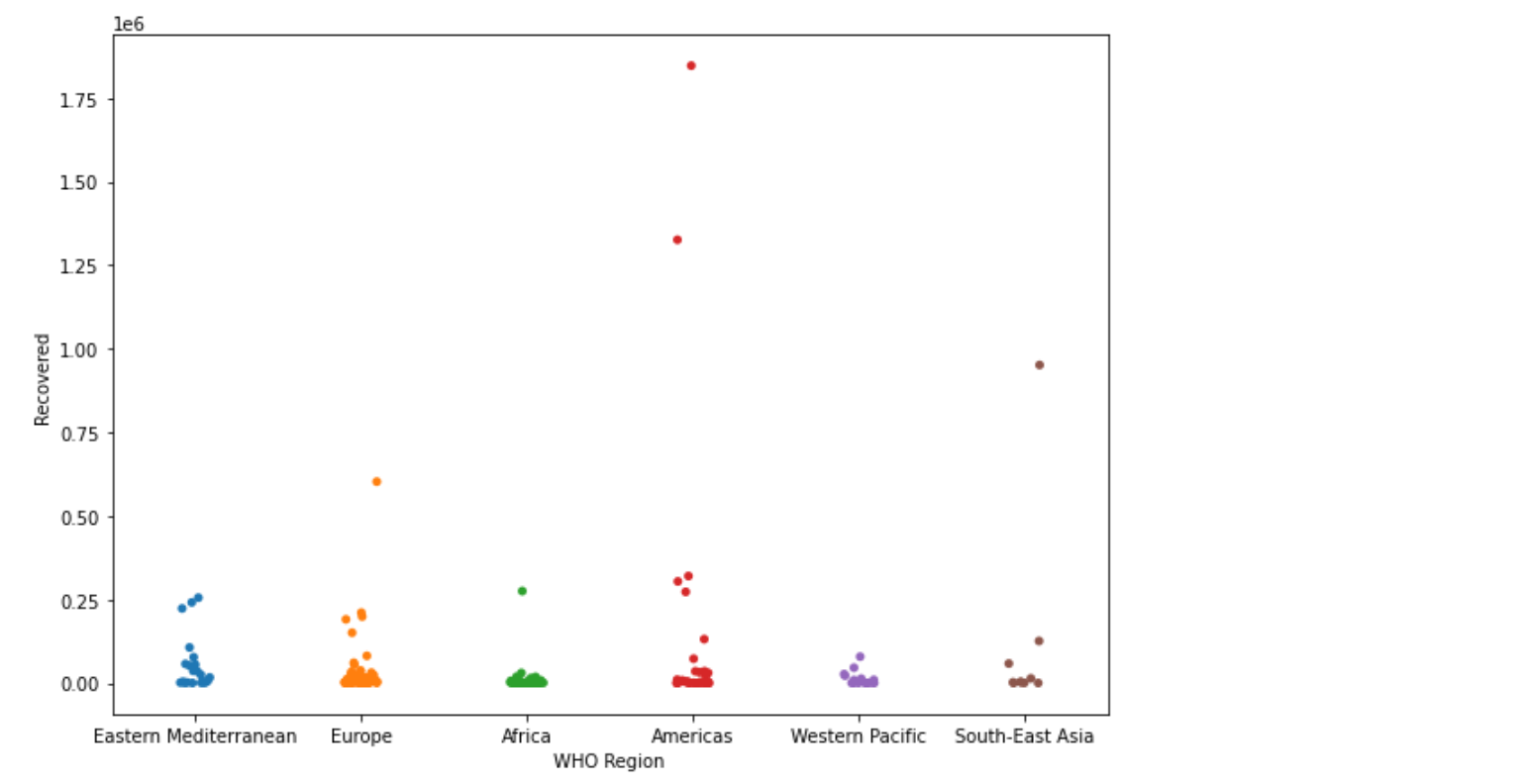
- 히트맵(heatmap)
- 데이터의 행렬을 색상으로 표현해주는 그래프
- sns.heatmap()
- 상관계수행렬에서 가장 많이 쓰임
heat = covid.corr() ## 상관계수로 나태내는 함수
sns.heatmap(heat)
plt.show()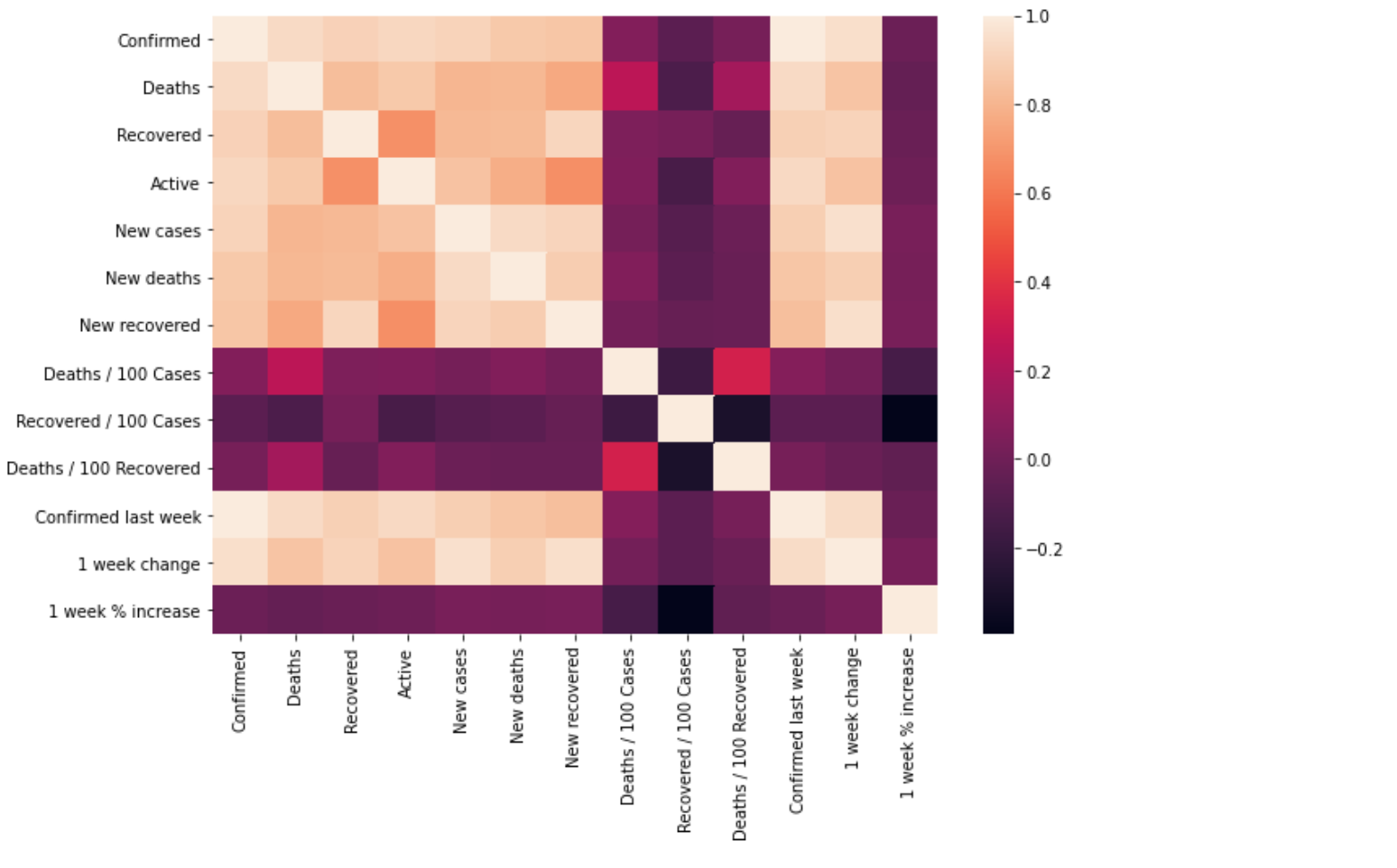

원하는 대로 살자