[배운점]
유사도
벡터의 유사도를 구하는데 대표적으로 Pearson Correlation 와 cosine 유사도가 사용된다. 여기서 벡터라함은 보통 유사도를 구하기위해 임베딩된 데이터가 될 수 있다.
두 유사도 측정 방법의 차이점에 대해서 지난 TIL에 다룬적이있다. 아래 링크 참고.
TIL-202103202
Skip-gram vs CBOW(continous bag of word)
- skip-gram 과 CBOW 모두 Word2Vec의 학습하기위한 알고리즘이다. skip-gram의 경우 중심단어(target word)로부터 주변의 단어(context words)를 예측하는 것이고 반대로 CBOW는 주변의 단어로부터 중심단어를 예측한다. 일반적으로 skip-gram이 보다 성능이 우수한 경향을 보인다.
참고로 단어를 벡터로 변환하는 것을 임베딩이라고하는데 이러한 과정이 필요한 이유는 벡터는 크기뿐만 아니라 방향이 존재하기 때문에 그 방향을 통해서 단어의 유사도를 알 수있다.
python extend 메소드
extend(iterable) 메소드는 입력으로 iterable 자료형을 받아 요소를 각각 추가해준다. iterable 자료형은 한번에 하나씩 요소를 반환하는 자료형이며 대표적으로 list, tuple, dictionary가있다.
a = [3,4]
b = [1,2]
b.extend(a)
print(b)
>>> [1,2,3,4]ROC(receiver opreating characteristic) 커브
ROC 커브는 threshold 따라 이진분류기의 성능을 표시한 것이다. 아래 예시를 보자
일반적으로 아래 그래프를 암환자에 대한 의사의 판단으로 설명을 많이하는데 오른쪽의 빨간색의 TPR(true positive rate)를 암에 걸렸을 때 암으로 진단한 경우, 왼쪽의 파란색을 FPR(false positive rate) 암에 걸렸을 때 암이 아닌 것으로 진단한 경우를 나타낸다.
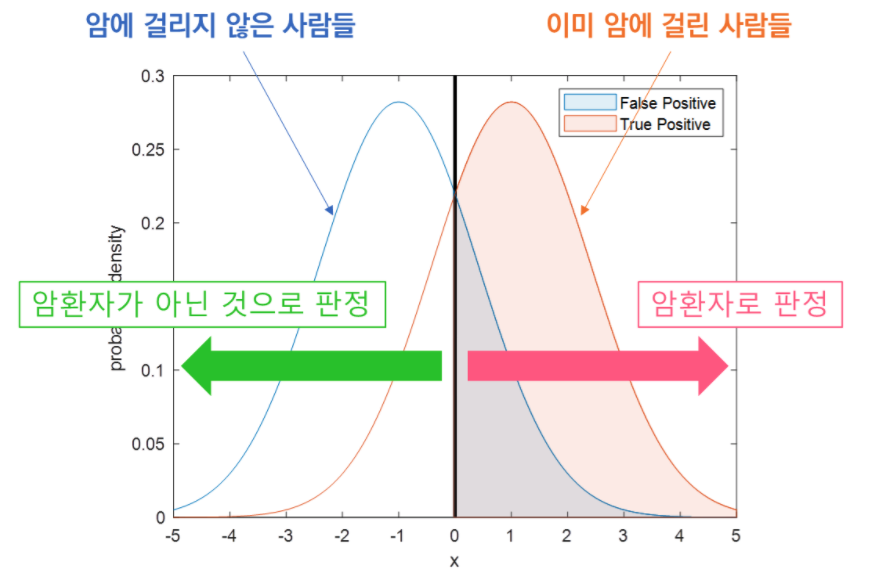
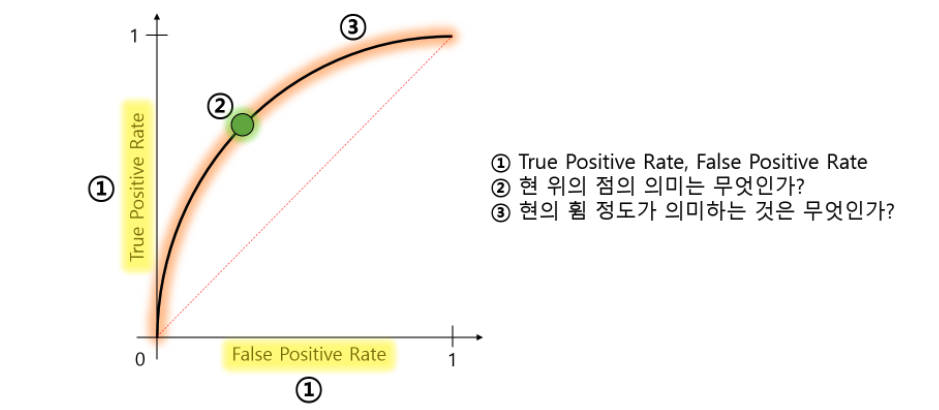
위 그래프에서 굵은 선(threshold)이 아래 ROC 커브의 현 위의 점을 나타내며 x축이 FPR이므로 위 그래프의 굵은 선이 왼쪽으로 갈수록 아래 그래프에서 현 위의 점은 1에 가까워진다.
또한 TPR, FPR 그래프의 겹치는 정도가 현의 휨 정도를 나타내는데 두 그래프가 완전히 분리 될 수록 굵은 선으로 명확히 TPR인지 FPR인지 구분 가능하다. 따라서 현이 좌측 상단에 많이 붙을 수록 완전히 구분하능한 좋은 분류기라고 볼 수 있으며 직선에 가까울 수록 분류가 어려운 그래프가 많이 겹치는 경우라고 볼 수 있다.
PyPI, Py4J
- PyPI(python package index) : 파이썬을위한 다양한 패키지, sw가 저장된 저장소이다.
- Py4J : 파이썬 프로그램과 자바객체의 연결을 가능케하는 라이브러리이다.
[느낀점]
TIL은 간만에 적는 것 같은데 오늘 조금 느낀점이 있어서 적게되었다.
그 동안 단시간에 많은 것들을 얻어내는데 초점을 맞추다보니 복습에 소홀히하고 학습에 빈틈이 많았던 것 같다. 내가 여기에 기록한 것들을 실무에 반복적으로 적용할 기회가 없다보니 당시에는 완벽하게 이해했더라도 얼마 안되어 기억이 흐릿해졌다. 또한 지난 기록들에 보완이 필요하거나 심지어 틀린 내용이 있을수도 있다고 생각하는데 주기적으로 확인하고 수정하는 작업이 필요하다는 생각이든다.
