지난 강의는 image classification과 linear classification에 대해 이야기했다.
Lecture3은 가중지 행렬 W를 어떻게 구해야하며 최적의 모델을 어떻게 구해야하는지, 즉 Loss function과 Optimization에 대한 이야기이다.
가중치 Matrix W
이미지 픽셀벡터 x에 가중치 matrix W를 내적한 결과인 스코어를 통해 분류기 또는 모델이 이미지를 정확히 예측했는지 알 수 있었다.
아래 그림 좌측이 스코어 결과인데 선형분류기(Linear Calssification)가 자동차를 제외한 나머지 클래스에서는 제대로 예측하지 못했으며 특히 개구리의 경우는 그 정도가 심하게 벗어났음을 알 수 있다.
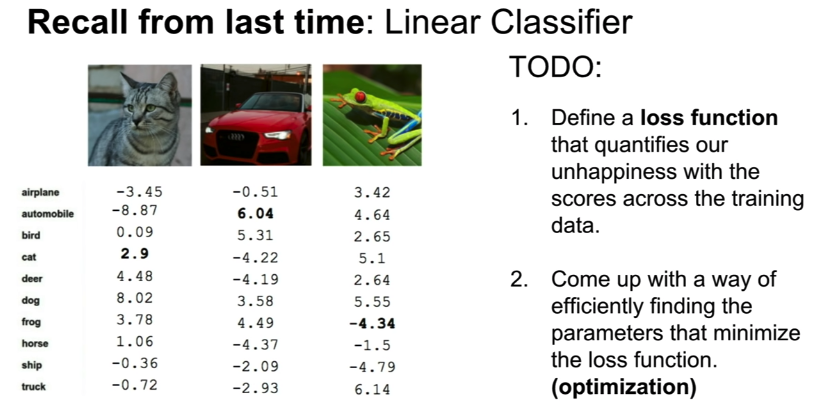
이러한 W는 특별한 과정에의해 정해지며 잘(예측을 잘 하도록) 설정되었는지 판단하기 위한 도구로 손실함수(loss fucntioin)라는 함수가 사용된다. 때로는 비용함수(cost function), 목적함수(objective function)이라는 용어로도 쓰이지만 의미적으로는 큰 차이가 없다.
Loss Funtion
스코어를 결정하는 Matrix W를 정량적으로 판단하는 함수를 손실함수라고 하며 그러한 손실함수의 최적해(손실이 가장 적은)를 찾는 과정을 Optimization이라고 한다.
손실함수에는 여러가지가 있으며 주로 이미지 분류에서 사용되는 대표적인 함수인 Multiclass SVM loss를 알아보겠다.
Multiclass SVM loss
Multiclass SVM loss는 평가하고자하는 클래스의 스코어(Syi)와 나머지 클래스의 스코어(Si)들의 차이를 비교한다. 잘 예측한 경우는 0을 아닌 경우는 양수값을 산출해 최종 sum했을 때 예측이 정확히 이루어질 수록 0에 가까운 값을 산출하도록 하는 방법이다. 참고로 수식에서 +1은 margin을 주기위해 설정된 값이다.
아래 고양이, 자동차, 개구리 총 3개의 이미지에대한 Multiclass SVM Loss값 구한 과정을 참고하면 이해가 쉬울 것이다.

Loss(고양이) : max(0, 5.1 - 3.2 + 1) + max(0, -1.7 - 3.2 + 1) = 2.9 + 0 = 2.9
Loss(자동차) : max(0, 1.3 - 4.9 + 1) + max(0, 2.0 - 4.9 + 1) = 0 + 0 = 0
Loss(개구리) : max(0, 2.2 - (-3.1) + 1) + max(0, 2.5 - (-3.1) + 1) = 6.3 + 6.6 = 12.9Loss(full dataset) : (2.9 + 0 + 12.9) / 3 = 5.27
Q. What happen to loss if car scores change a bit?
A. 자동차는 올바로 예측한 결과로 살짝 스코어를 변경해도 여전히 손실은 0일 것이다. 위의 결과 기준으로는 2.3정도까지는 스코어를 낮추어도 결과에는 변화가 없다.
Q. What's the min and max possible loss?
A. 0 ~ ∞이다. 힌지 그래프를 참고하면 알 수 있다.
Q. If all of Ss, if all of the scores are approximately zero or equal then what kind of loss expect?
A. 평가하고자하는 클래스와 나머지 클래스를 비교하는 것이므로 스코어가 모두 0 또는 같다면 margin값인 1만 남게된다. 따라서 나머지 클래스의 개수인 n-1이(총 n개의 클래스일 때) 된다.
Q. What if we used mean instead of sum?
A. loss값은 rescaling 될 것이지만 분류 결과는 동일할 것이다. 즉, 문제되지 않는다.
Q. What if we added a square term on top of the max?
A. max term이 제곱항이 된다면 잘못 예측할 수록 loss은 이전보다 더 커지는 효과가 생긴다.
## Multiclass SVM Loss
def L_i_vectorized(x, y, W):
scores = W.dot(x)
margins = np.maximum(0, scores - scores[y] + 1)
margins[y] = 0
loss_i = np.sum(margins)
return loss_i과적합(Overfitting), 규제화(Regularization)
중요한 것은 다른 모든 종류의 손실함수도 마찬가지이지만 손실이 0에 가까울 수록 예측을 정확히한다는 것을 의미한다.
그렇다면 손실함수를 0으로 만드는 W값은 하나만 존재할까? 물론 아니다.
이런경우를 생각해볼 수 있다.
아래 그림과 같이 파란색 점들이 train 데이터셋이라면 파란 곡선의 그래프는 데이터를 완벽하게 설명한다고 볼 수있이다.그리고 이 그래프는 어떤(아마도 4차)함수로 표현될 것인고 그 함수의 계수들은 W의 원소들이다.
과연 이 모델을 좋은 모델일까?
train 데이터셋이아닌 새로운 데이터인 녹색 점들이 추가되었다고 하자. 이 모델은 새로운 데이터에 대해서는 예측이 뛰어나다고 할 수 없을 것이다.
이렇게 train 데이터에 대해서는 정확한 예측을하지만 새로운 데이터에대해서는 예측이 떨어지는 경우 학습데이터에 overfitting되었다고 이야기한다.
이런경우에는 아래의 녹색 그래프가 오히여 모든(파란+녹색) 데이터에대해 잘 예측하고있다고 할 수 있다.
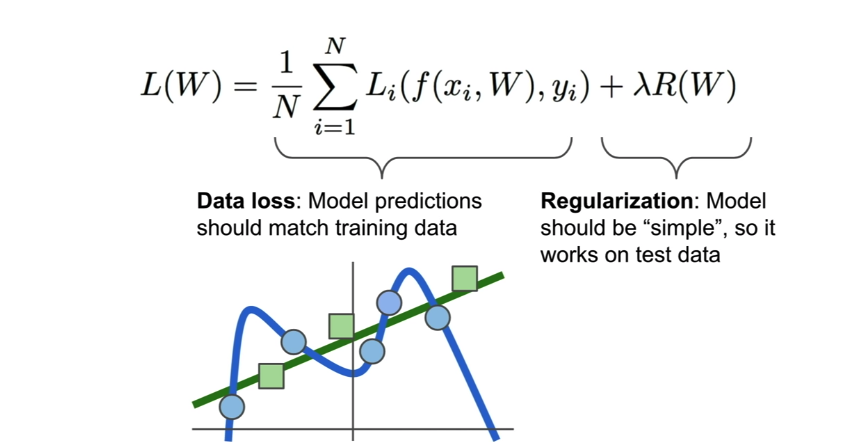
따라서 손실함수에 별도의 항을 추가해 예측모델을 보다 일반화(generalization)하고 보편적인 형태로 만들어주는 기법을 규제화(regularization)이라고 한다.
직관적으로 생각했을 때 고차함수의 계수인 행렬 W의 계수들을 작게 만들어준다면 그 고차항들의 영향이 작아지게되며 계수가 극단적으로 0이 된다면 고차항은 결국 사라지게 되어 위의 그림처럼 파란색 곡선이 직선처럼 변경 될 수 있다. 이러한 컨셉으로 하이퍼파라미터인 람다를 규제항에 포함시켜 예측함수를 보다 일반화해 새로운 데이터에대해서도 잘 설명할 수 있게해주는 방법이 규제화의 핵심이다.
Softmax classifier(Multinomial Logistic Regression)
- deep learning에서 더 많이 사용하는 분류기로 Softmax classifier(Multinomial Loistic Regression)이 있다. SVM loss에서는 스코어에 특별한 의미를 부여하지 않은 것과 달리 Multinomal Logistic Regression에서는 스코어에 확률적 의미를 부여한다. 그리고 스코어를 확퓰 분포로 변환하기위한 함수를 Softmax 함수라고한다.


스코어를 확률로 변환하는 softmax 함수는 위의 log안에 포함된 함수이고 Li는 손실함수를 의미한다. 따라서 확률이 1에 가까울수록 즉, 예측이 정확할 때 Li값은 0이된다.
Softmax VS SVM
위에서 확인한 두 손실함수의 차이는 무엇일까?
SVM loss의 경우 정답 스코어와 오답 스코어의 차이가 마진을 넘기는 것에만 만족을 했다.
반면 Softmax loss에서는 정답 스코어에 대해서 확률을 1로 최대한 가깝게 되도록 계속해서 개선할 여지가 있다는 점이 두 함수의 가장 큰 차이이다.

Optimization
우리는 손실함수의 결과값인 손실이 0에 가까울 수록 예측이 정확하다는 것을 의미하며 결국 최소의 손실을 만족하는 W를 찾는 것이 목적임을 알 수 있다. (스코어가 결국에는 W와 x의 내적이므로)
그리고 손실을 최소로하는 W를 찾는 과정을 최적화(Optimization)이라고한다.
경사하강법(Gradient Descent)
최적화의 기본 컨셉은 손실함수를 골짜기라고 했을 때 사람이 점진적으로 그 골짜기를 내려가면서 최저점인 즉, 손실이 0에 가장 가까운 지점을 찾는 것이다.
첫째로 무작위로 W를 선택하는 방법을 생각해볼 수있다. 하지만 이 알고리즘은 굉장히 stupid한 방법이며 때문에 거의 쓰이지않는다.
만약 골짜기의 경사를 확인하여 이 경사가 감소하는 방향으로 점진적으로 내려가는 방법은 어떨까? 이 알고리즘 역시 간단하지만 위 방법과 달리 실제로 일반적으로 사용되는 방법이며 강력하고 정확하다.

이와 같이 경사(gradient)를 작아지게 만드는 쪽으로 W를 h 만큼 계속해서 조정해 최종적으로 최저점인 손실이 가장 작은 지점을 찾아가는 방법을 경사 하강법(gradient descent)이라고한다.
하지만 실제로는 이 반복적인 과정이 너무 느리기 때문에 우리가 이미 알고있는 미분을 이용해 최저점을 쉽게 구할 수 있다. 이때 미분해야할 대상 함수는 우리가 위에서 배운 손실함수 f이다. 
## Vanilla Gradient Descent
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += -step_size * weights_gradStochastic Gradient Descent(SGD)
전체 train 데이터셋으로부터 손실을 계산하는 것이아니라 미니배치(minibatch)라는 작은 단위(보통 32/64/128)의 샘플 데이터를 추출해 손실을 반복적으로 구해 개선하는 방법을 확률적 경사하강법(stocahstic gradient descent)라고한다.
기존의 gradient descent의 경우는 실제 대규모 작업에서는 데이터셋이 굉장히 많기 때문에 손실을 구해 W을 업데이트하는 과정에 많은 시간이 소요된다. 따라서 이러한 SGD를 사용하면 보다 적은 샘플 데이터로도 충분히 효과적으로 W값을 개선할 수 있다는 장점이있다.
## Vanilla Minibatch Gradient Descent
While True:
data_batch = sample_training_data(data, 256)
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weight += - step_size * weights_gradAside : image Features
그 밖의 이미지 분류 방법으로는 이미지에서 각각의 특징들, 예를들면 개구리의 다리, 손, 얼굴 등을 벡터로 만든 후 이러한 feature 벡터를 모두 합쳐 이미지가 개구리인지 판단하는 방법이있다.
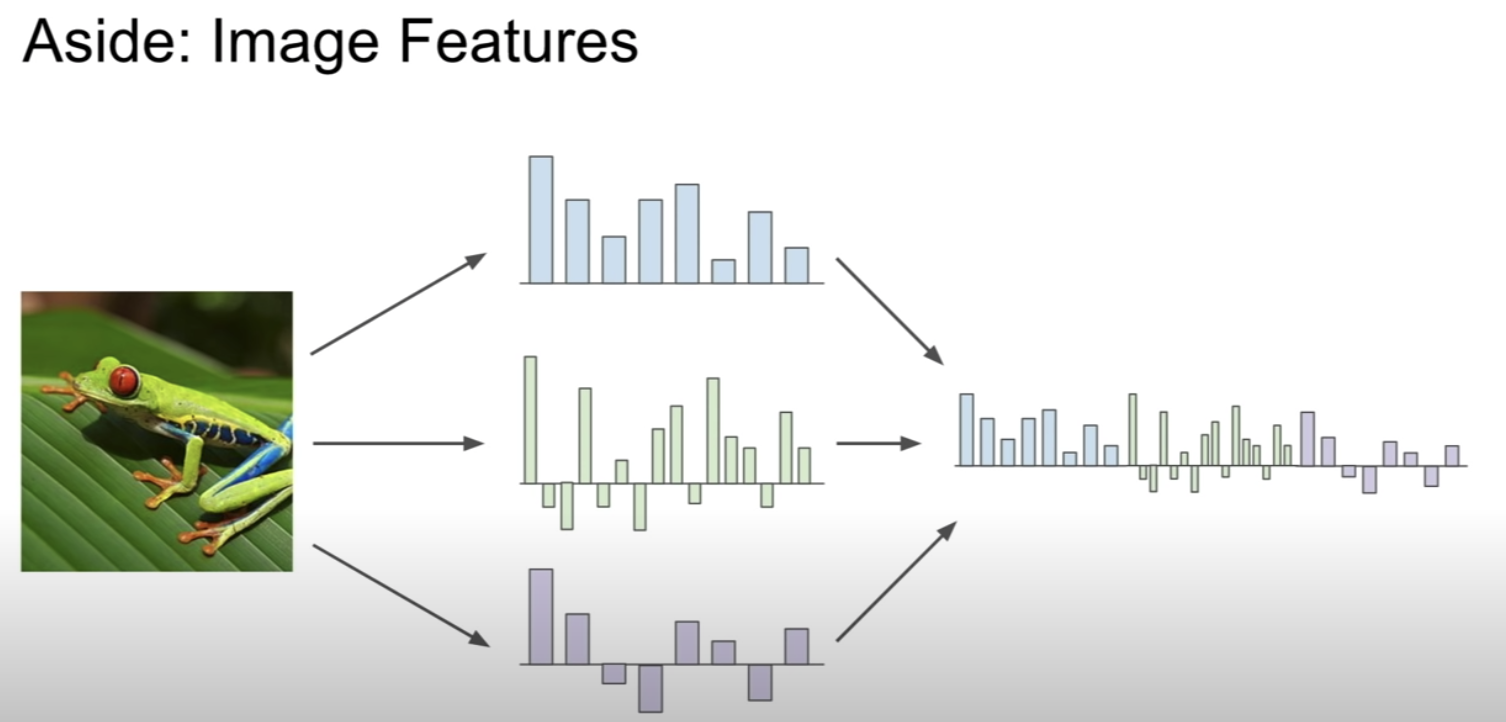
Image Features : Motivation
아래 왼쪽 그림과 같이 선형 분류기로 빨간색과 파란색의 점을 분류하기 힘든 경우, feature transform을 이용해 좌표계를 변경해 분류가 가능하도록 하는 방법이 있다.

