Intro
CS231n는 2017년 스탠포드 대학에서 공개한 visual recognition 관련 강의이다.
총 16개의 Lecture로 이루어졌는데 강의소개인 Lecture1을 제외한 15개의 Lecture를 앞으로 부지런히 학습하고 정리할 계획이다.
강의 중 내가 몰랐던 내용이나 핵심이라고 여겨지는 부분만 간단하게 기록해 나만을 위한 강의노트를 만들어보겠다.
Image Classification
우리 인간과 다르게 컴퓨터는 이미지를 인식할 때 아래와 같이 픽셀값인 숫자로 인식을한다.
이에 따른 문제점으로는 고양이 이미지를 인식한다고 가정했을 때 사진을 찍는 카메라의 앵글과 조명의 변화 그리고 고양이의 종이나 크기가 달라진다면 픽셀값도 변하기 때문에 컴퓨터에게는 같은 고양이로 인식한다는 것이 쉽지가 않다.
 반면에 우리 인간은 위의 변화에도 같은 고양이임을 쉽게 인지할 수 있다. 이러한 인식률의 차이는 컴퓨터와 인간이 물체를 인식하는 방법의 차이에서 기인하는 것일 것이다.(예를들면 인간은 고양이의 꼬리나 얼굴 등 부분적 특징만으로 고양이인 것을 유추하는 것이 가능하지만 컴퓨터는 픽셀 전체를 보고 고양이로 판단한다) 따라서 인간이 물체를 인지하는 방법과 유사한 방법으로 인지하게끔 만들어 준다면 컴퓨터 역시 인간 수준에 가까운 능력을 보일 것이며 visual recognition의 목표 역시 결국에는 인간의 인지능력을 최대한 가깝게 모방하는 알고리즘을 찾는데 있을 것이다.
반면에 우리 인간은 위의 변화에도 같은 고양이임을 쉽게 인지할 수 있다. 이러한 인식률의 차이는 컴퓨터와 인간이 물체를 인식하는 방법의 차이에서 기인하는 것일 것이다.(예를들면 인간은 고양이의 꼬리나 얼굴 등 부분적 특징만으로 고양이인 것을 유추하는 것이 가능하지만 컴퓨터는 픽셀 전체를 보고 고양이로 판단한다) 따라서 인간이 물체를 인지하는 방법과 유사한 방법으로 인지하게끔 만들어 준다면 컴퓨터 역시 인간 수준에 가까운 능력을 보일 것이며 visual recognition의 목표 역시 결국에는 인간의 인지능력을 최대한 가깝게 모방하는 알고리즘을 찾는데 있을 것이다.
그래서 찾게된 방법 중 하나가 다음의 data-driven approach이다.
Data-Driven Approach
data-driven approach는 하나의 이미지에서 픽셀값을 분석해 image classification을 진행하는 것이아니라 각 물체별로 굉장히 많은 양의 이미지들을 수집한 후 수집된 이미지 데이터를 컴퓨터에 학습시켜 분류 모델을 만드는 방법이다.
보통 학습을 위한 데이터를 train 데이터 라고하는데 이 train 데이터에는 이미지와 그 이미지가 무엇인지(비행기인지 새인지 고양이인지...)를 알 수 있는 label이 포함되어있다. 따라서 컴퓨터는 이미지와 정답을 의미하는 label을 학습한 후 그 결과로써 분류 모델을 만들고, 그 모델로 test 데이터라 불리는 새로운 이미지를 예측하는 것이 image classification의 전반적인 과정이라고 할 수 있다.
이러한 data-driven approach는 일반적인 deep learning에서 사용하는 분류기(classifier)를 위한 알고리즘이라고 할 수 있다.

Nearest Neighbor
그렇다면 가장 간단하게 만들 수 있는 분류기는 무엇이 있을까? 바로 nearest neighbor라는 방법이다. 이름에서 유추할 수 있듯이 train 데이터를 모두 학습한 후 새로운 이미지를 예측할 때 미리 학습한 데이터와 가장 유사한 이미지의 label을 정답이라고 본다. 알고리즘이 굉장히 간단하지만 역시 이런식의 예측으로는 성능은 좋다고 할 수 없을 것이다.
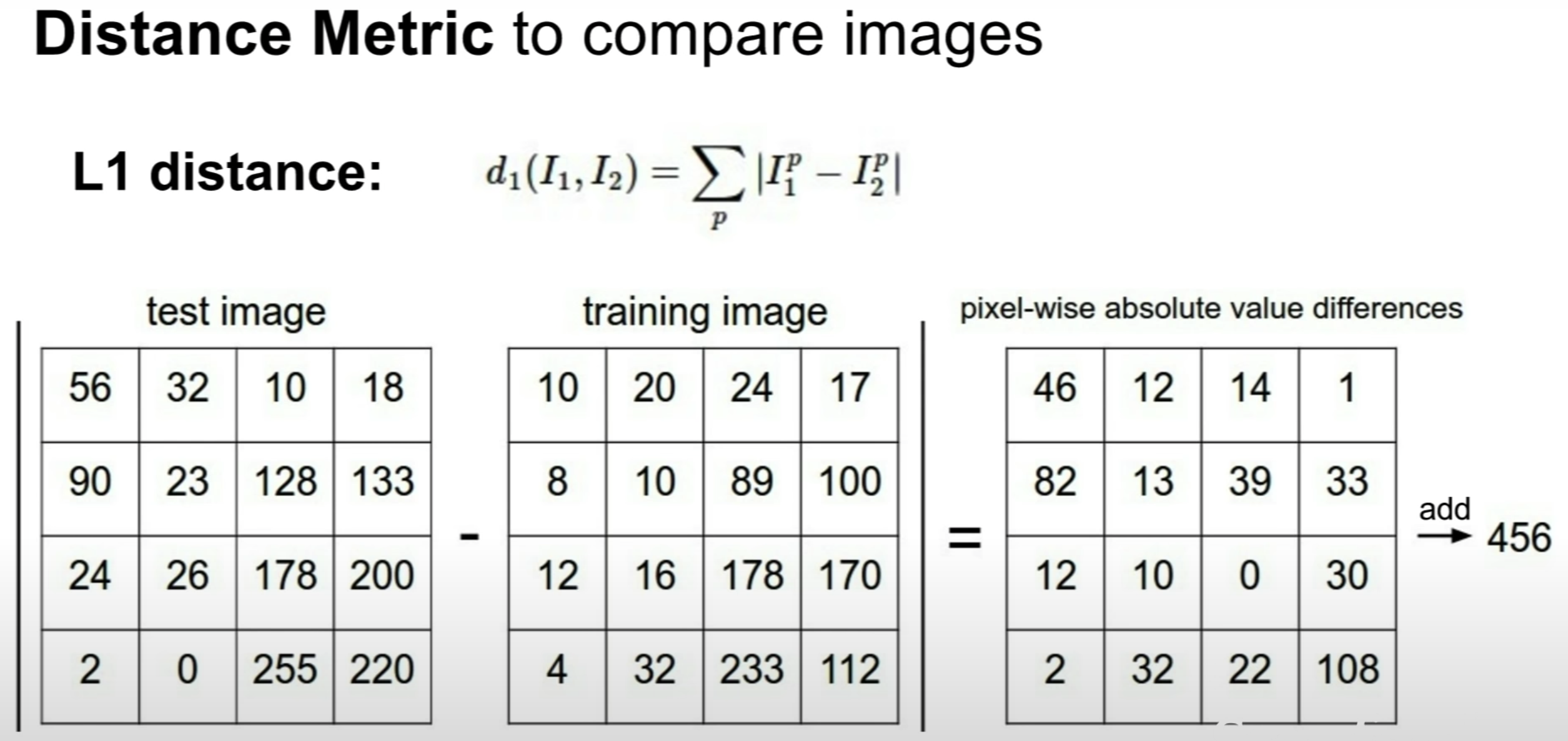
유사한 이미지를 선별하는 과정에서는 다음과 같은 거리(distance) 비교를 통한 알고리즘을 이용한다. 이미지는 픽셀이라는 숫자로 되어있기 때문에 비교하고자하는 각 픽셀값들의 차를 모두구해 그 합이 작을수록 유사하다고 간주하는 방법이다.
한가지 참고할 점은머신러닝이나 딥러닝에서 학습(training) 시간보다 예측(predict) 시간이 짧을수록 좋다. nearest neighbor 분류방법은 모든 데이터를 학습할 때 O(1)의 시간을, 예측할 때는 각 이미지 데이터의 모든 픽셀을 비교해야하므로 O(N)의 시간이 걸린다는 점에서 위의 목적과도 맞지않다.
K-Nearest Neighbors
nearest-neighbor의 개선된 알고리즘으로는 K-Nearest Neighbors가 있다. 아래 그림에서 색깔로 구분되는 영역은 class(category of training samples)에 해당하며 그 색은 안에 포함된 각 점들이 가장 가까운 K개의 점으로 부터 참조를 받아 일종의 투표를 진행하는 방식으로 색이 분류된다.
이러한 K는 학습으로부터 얻어지는 값이 아니며 최선의 결과를 낼 수있도록 우리가 설정해주는 값으로 Hyperparamer라고 부른다.

K-Nearest Neighbor를 이용한 분류기는 이미지 분류에서는 다음과 같은 이유로 사용하지않는다.
1. test time 이 느리다.
2. 픽셀의 거리를 비교하는 방법으로는 정확한 비교가 불가하다.
3. 차원의 저주(curse of dimensionality)
차원의 저주는 차원이 늘어나면 데이터 수가 상대적으로 공간에비해 작아져 모델의 성능이 저하되는 것을 말한다. 이 이론에 따르면 데이터는 차원이 증가함에따라 지수적으로 증가해주어야 모델의 성능이 잘 유지된다.
Linear Calssification
Linear Classification은 나중에 다루게될 CNN이나 RNN과 같은 깊은 신경망(Neural Network)의 기본이 되므로 굉장히 중요하다.
그 기본 컨셉은 다음과 같다.
1. 이미지의 픽셀값들을 1열로 만들면 벡터가 되고 이는 x에 해당한다.
2. 이 벡터 x와 가중치에 해당하는 W 행렬을 곱(내적)해 class 개수에 해당하는 10개의 원소를 가진 벡터값을 결과로 얻는다.(bias term은 여기서 무시하겠다)
3. 10개의 원소 중 가장 큰 값에 해당하는 class로 이미지를 예측한다.

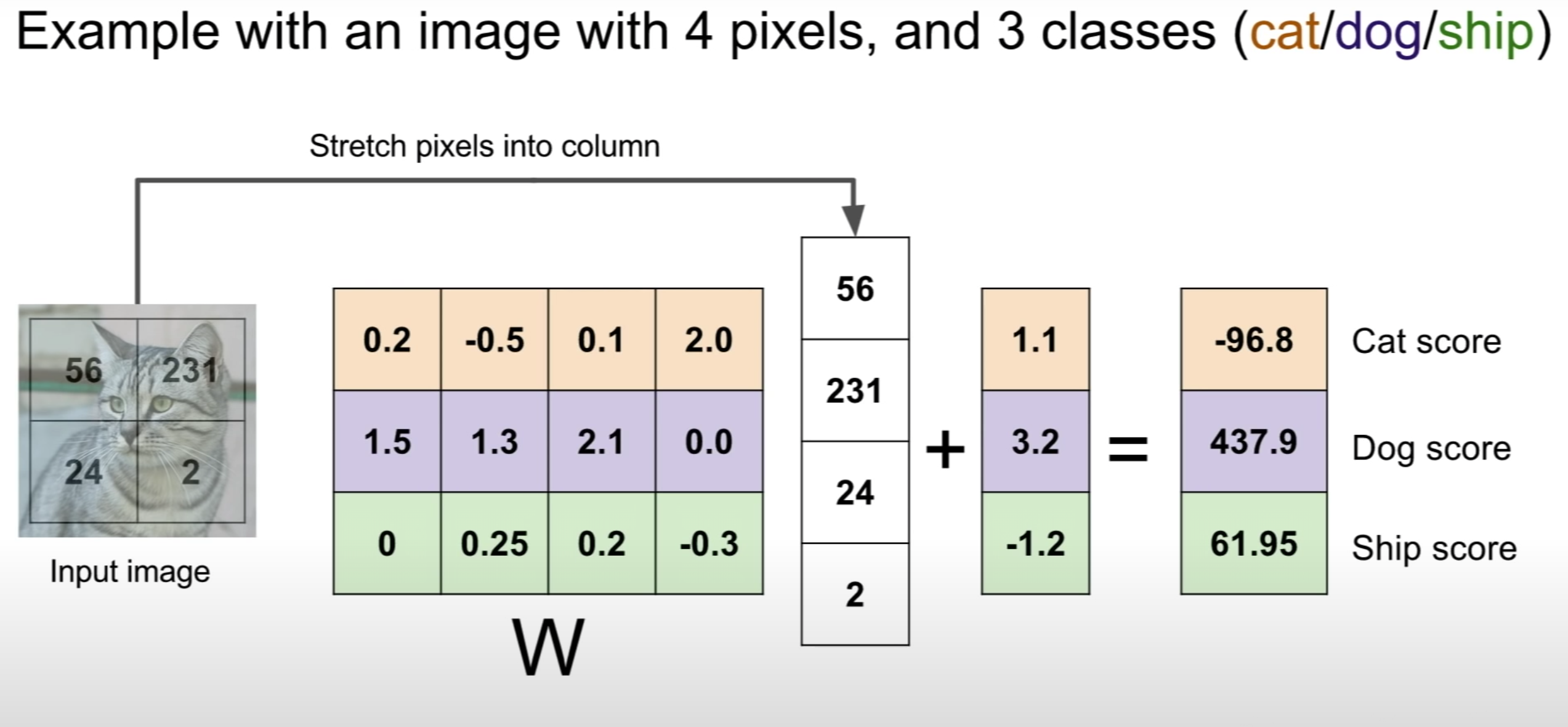
결국 Linear Classification은 각 class에 해당하는 무수히 많은 이미지를 학습해 각 class에 해당하는 가중치 행렬 W와 그 W를 포함하는 함수 f(x,W)를 구하는 것이 목적이라고 할 수 있다.
이 때 함수 f(x,W)가 Linear Calssifier가 된다.


