
맛집 정보 플랫폼에서 크롤링한 review들을 토큰화한 후 임베딩까지 진행해보았다.
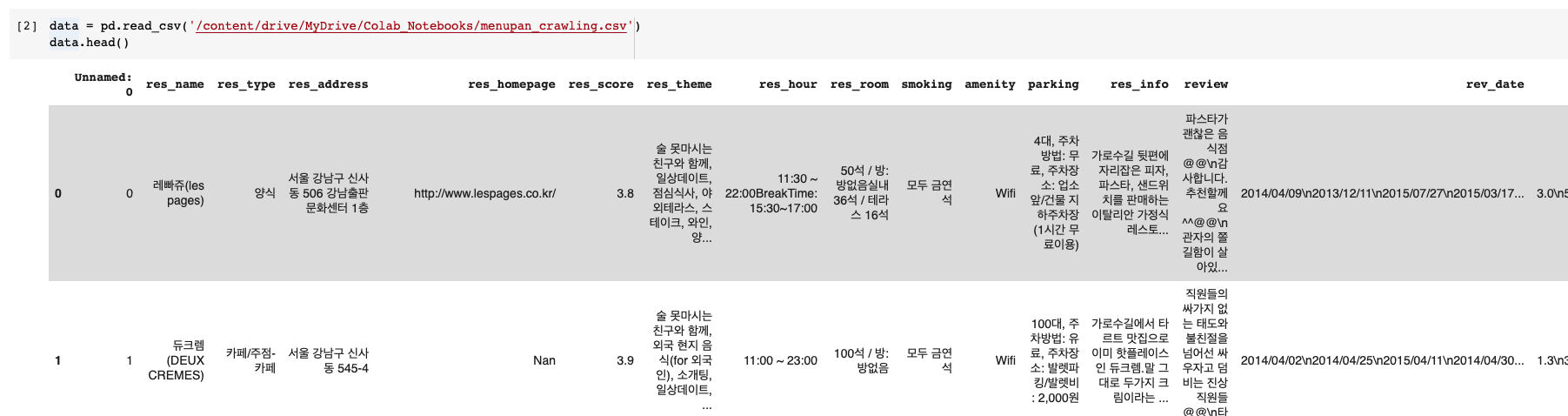
데이터 불러오기
우선 필요한 모듈을 import 하고 크롤링한 csv 데이터를 불러온다.

Preprocessing
특정 컬럼 추출
여기서 내가 사용할 것은 레스토랑 이름과 리뷰인 res_name, review 컬럼이므로 해당 컬럼만 추출한다.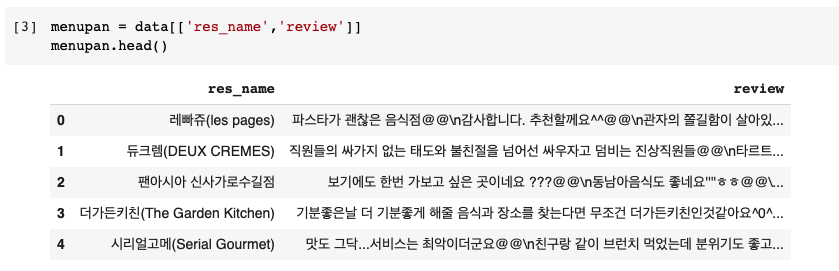
정규식(한글, 숫자만 추출)
리뷰를 보면 특수기호나 이모지(emoji)들이 보인다. 따라서 정규식을 이용해 한글과 숫자만 추출해주었다.

정규식 처리 결과
특수기호와 이모지가 없는 것을 확인할 수 있다.

결측치 처리(행 삭제)
리뷰가 없는 행을 삭제해주었다. 보통 결측치가 있는 행은 df.dropna(axis=0) 함수를 이용해 삭제해주는데 나같은 경우는 크롤링 단계에서 리뷰가 없으면 영어문자로 별도 처리해주었고 위에 정규식에서 영어는 추출이안되므로 공백만 남아있다. 따라서 아래와 같이 삭제해주었다.

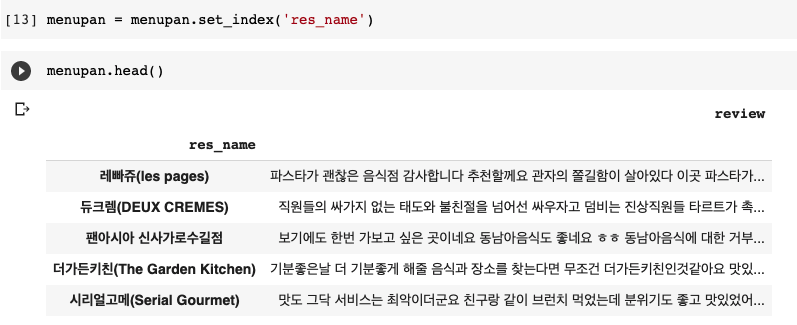
특정 컬럼을 인덱스로 지정
res_name열을 index로 지정해주었다. 리뷰를 벡터로 임베딩한 후 corrMatrix로 만들어주기위함인데
뒤에서 보면 알겠지만 gensim 모듈을 이용해 유사도를 확인하므로 해당 과정은 진행해주지 않아도 되었다.
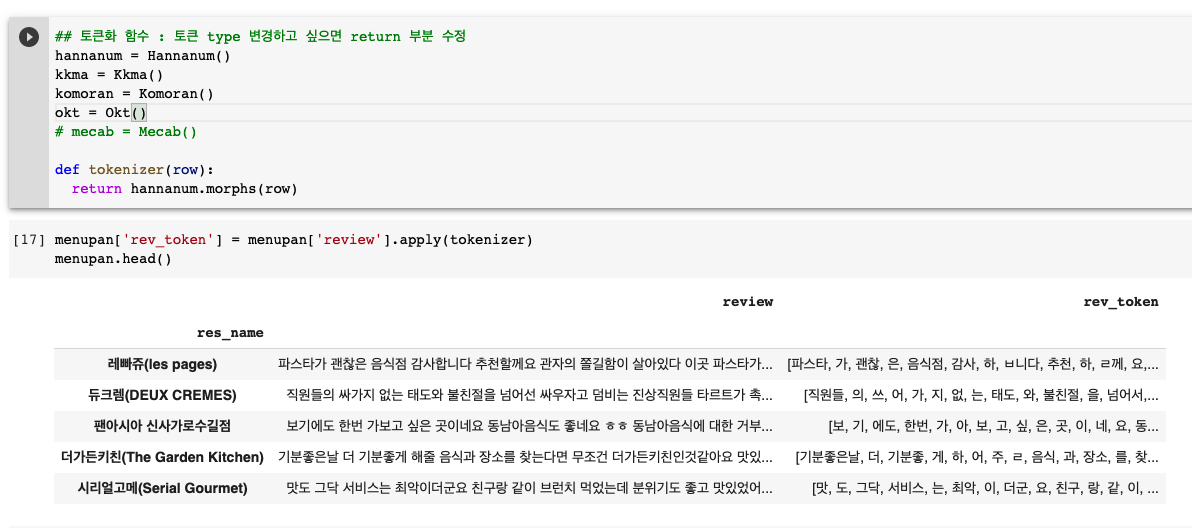
토큰화(tokenization)
한국어 형태소 분석을위해 KoNLPy 패키지로부터 아래 형태소 분석 모듈들을 import한다.

리뷰 컬럼에대해 토큰화를 진행하였다. 나는 hannanum로 적용해보았다.
참고로 mecab은 윈도우에서 지원이 안되고 나는 맥을 사용중인데 colab에서 사용하려니 에러가 발생했다. 찾아보니 별도의 파일들 설치가 필요한데 편하게하려면 로컬에서 진행해야하므로 나는 mecab은 제외하고 진행하였다.
mecab 에러 발생시 참고
토큰화 모듈별 사용방법, 속도, 성능 비교는 여기를 참고
리뷰들의 최대/평균 토큰 개수를 출력

단어 임베딩(word embedding)
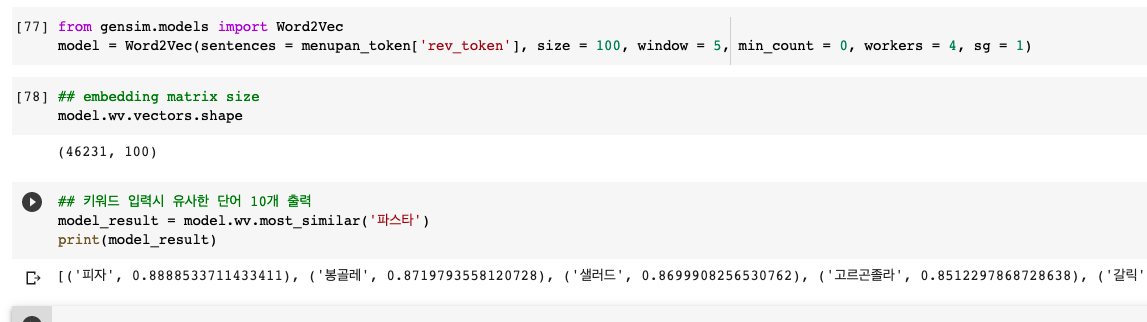
gensim이라는 모듈을 이용해 손쉽게 Word2vec 임베딩을 진행할 수 있었다.
option중에 size : 출력 차원, min_count : 지정한 수보다 빈도가 작으면 무시, sg : 1이면 skip-gram / 0이면 CBOW 알고리즘 사용
마지막 결과와 같이 키워드를 입력하면 유사한 텍스트를 10개 출력해준다.
gensim 참고 사이트
