생성형 AI
- 콘텐츠를 생성할 수 있는 능력을 갖춘 인공 지능 모델
- 기존 데이터를 학습해, 새로운 조합이나 형태로 창의적인 결과물을 만들어냄
- 텍스트, 코드, 이미지, 영상, 음악 등을 생성할 수 있다
- 유저와 대화를 통해 정보를 학습하고 문맥을 파악해 다양한 정보를 제공
인공 신경망 (Artificial Neural Network, ANN)
- 딥러닝: 머신러닝의 기법중 하나로 사람의 도움 없이 스스로 학습하고 판단하여 결정을 내리는 기술
- 딥러닝은 인공 신경망을 기초로 하고 있다
- Input Data를 받고 그 값이 가중치와 활성화 함수를 통과하여 만들어지는 Output Data를 전달하는 과정이다
- 신경망은 다수의 입력 데이터를 받는 입력층(Input), 데이터의 출력을 담당하는 출력층(Output), 입력층과 출력층 사이에 존재하는 레이어들(은닉층)이 존재한다
- 은닉층의 갯수와 노드의 개수를 구성하는 것이 모델을 구성한다
- 은닉층에서는 활성화함수를 사용하여 최적의 Weight와 Bias(학습 가능한 파라미터. 모델이 더 유연하게 학습할 수 있도록 도와주는 역할)를 찾아내는 역할을 한다
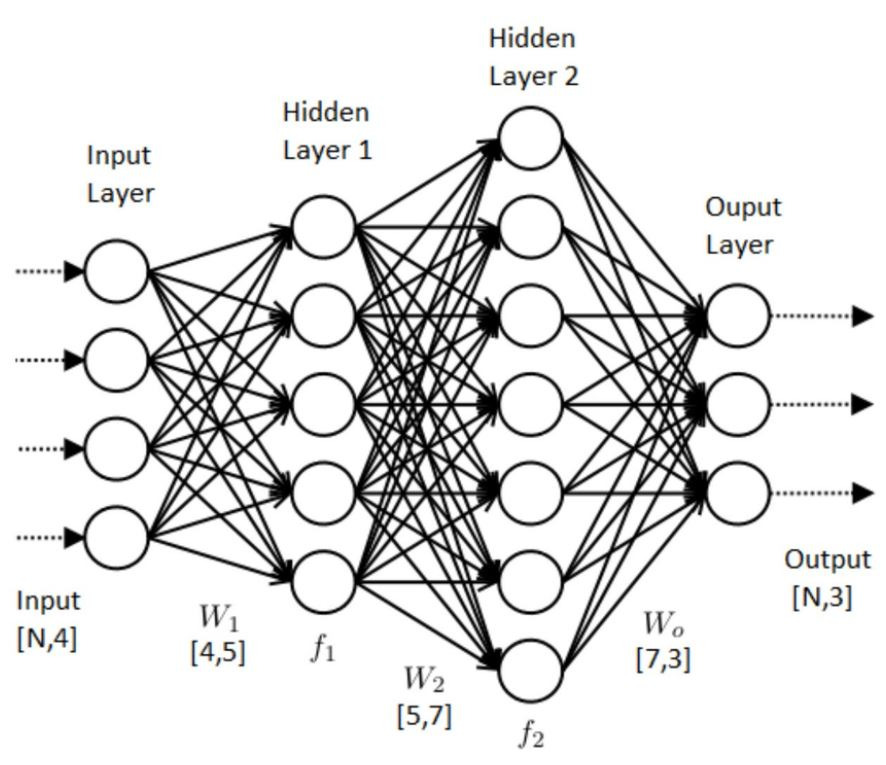
- 이 외에 은닉층을 늘려서 학습의 결과를 향상하는 DNN, 데이터의 특징을 추출하여 특징들의 패턴을 파악하는 CNN(합성곱신경망), 반복적이고 순차적인 데이터(Sequential data)학습에 특화된 RNN이 있다
파운데이션 모델(FM)
- 원시 데이터에서 대개 비지도 학습(unsupervised learning)을 통해 훈련된 AI 신경망으로, 광범위한 작업에 응용이 가능
- LLM을 포함하여 다양한 태스크와 도메인에서 활용할 수 있도록 사전 학습(Pretraining) 된 대규모 모델
- 특정한 목적 없이 많은 데이터로 학습을 함
- 데이터 이해와 생성 능력을 학습
- LLM을 포함하고 NLP뿐만 아니라 다양한 데이터 형태에서도 동작한다
- 트랜스포머를 기반으로 멀티모달 학습 및 범용적인 태스크 수행
- ex) GPT-4
LLM(Large Language Models)
- 대규모 언어 모델
- 파운데이션 모델의 기반
- 방대한 양의 데이터로부터 인간의 언어와 유사한 글을 이해하고 만든다
- NLP(자연어 처리) Task를 사용, NLP의 한 분야
- 방대한 양을 학습, 많은 리소스 사용
- 주로 인터넷에 있는 소스를 사용
- 트랜스포머를 기반으로 한다
LLM의 종류
-
일반 또는 원시 언어 모델(Generic or raw language model): 학습 데이터의 언어를 기반으로 다음 단어를 예측.
정보 검색 작업을 수행 -
지시 학습 언어 모델(Instruction-tuned language model): 입력에 제공된 지시에 대한 응답을 예측.
정서 분석을 수행하거나 텍스트 또는 코드를 생성할 수 있다정서 분석: 대량의 텍스트를 분석하여 긍정적인 감정을 표현하는지, 부정적인 감정을 표현하는지 또는 중립적인 감정을 표현하는지 판단하는 프로세스
-
대화 조정 언어 모델(Dialog-tuned language model): 다음 응답을 예측하여 대화가 가능 ex) 챗봇, 대화형AI
LLM의 구성요소
- 토큰화 (Tokenizattion)
- 입력 텍스트를 토큰(단위)으로 분할
- 모델이 텍스트를 처리할 수 있는 형태로 변환하는 첫 번째 단계
- 임베딩 (Embedding)
- 토큰화된 입력을 연속적인 벡터 표현으로 변환
- 이 과정은 입력의 의미론적 및 구문적 정보를 캡처하여 모델이 문맥을 이해할 수 있도록 함
- 셀프 어텐션 (Self-Attention)
- 입력 시퀀스 내의 모든 토큰 간의 관계를 분석하여 장기적 의존성을 포착
- 이를 통해 모델은 문맥에 맞는 정보를 강조할 수 있다
- 대규모 모델에서 이 어텐션 메커니즘은 병렬화 가능하여 광범위한 시퀀스를 효율적으로 처리할 수 있다
- 사전 훈련 (Pre-training)
- 일반적인 언어 패턴, 세계 지식 및 문맥적 이해를 학습
- 사전 훈련된 모델은 언어 전문 지식의 저장소가 된다
- 대규모의 일반적인 데이터로 모델을 미리 학습시켜, 다양한 태스크를 수행할 수 있는 기본적인 언어/지식 능력을 갖추게 하는 과정
- 파인튜닝의 기초가 됨
- 전이 학습 (Transfer Learning)
- 생성 용량 (Generation Capacity)
- 인코더-디코더 계층 (Encoder-Decoder Layers)
- 트랜스포머 아키텍처의 핵심 구성 요소
- 인코더는 입력 텍스트를 분석하여 숨겨진 상태를 생성, 디코더는 이를 기반으로 출력을 생성
- 위치 인코딩 (Positional Encoding)
- 트랜스포머 모델은 자연적으로 토큰의 순서를 인식하지 않기 때문에 위치 인코딩을 추가하여 각 토큰의 위치 정보를 제공
트랜스포머 모델
- 자연어 처리 작업에 적용되는 방법
- 특정 문장의 단어 및 구조를 추적해 맥락과 의미를 학습
- LLM의 핵심 기반 아키텍쳐
- 인코더(입력 임베딩), 디코더(출력 임베딩) 레이어로 나눠져있다
- 임베딩 레이어
- 멀티헤드 어텐션 레이어
- 합&정규화 레이어
- 피드 포워드 레이어
- self-attention 메커니즘
- 데이터 셋이 기본 재료임
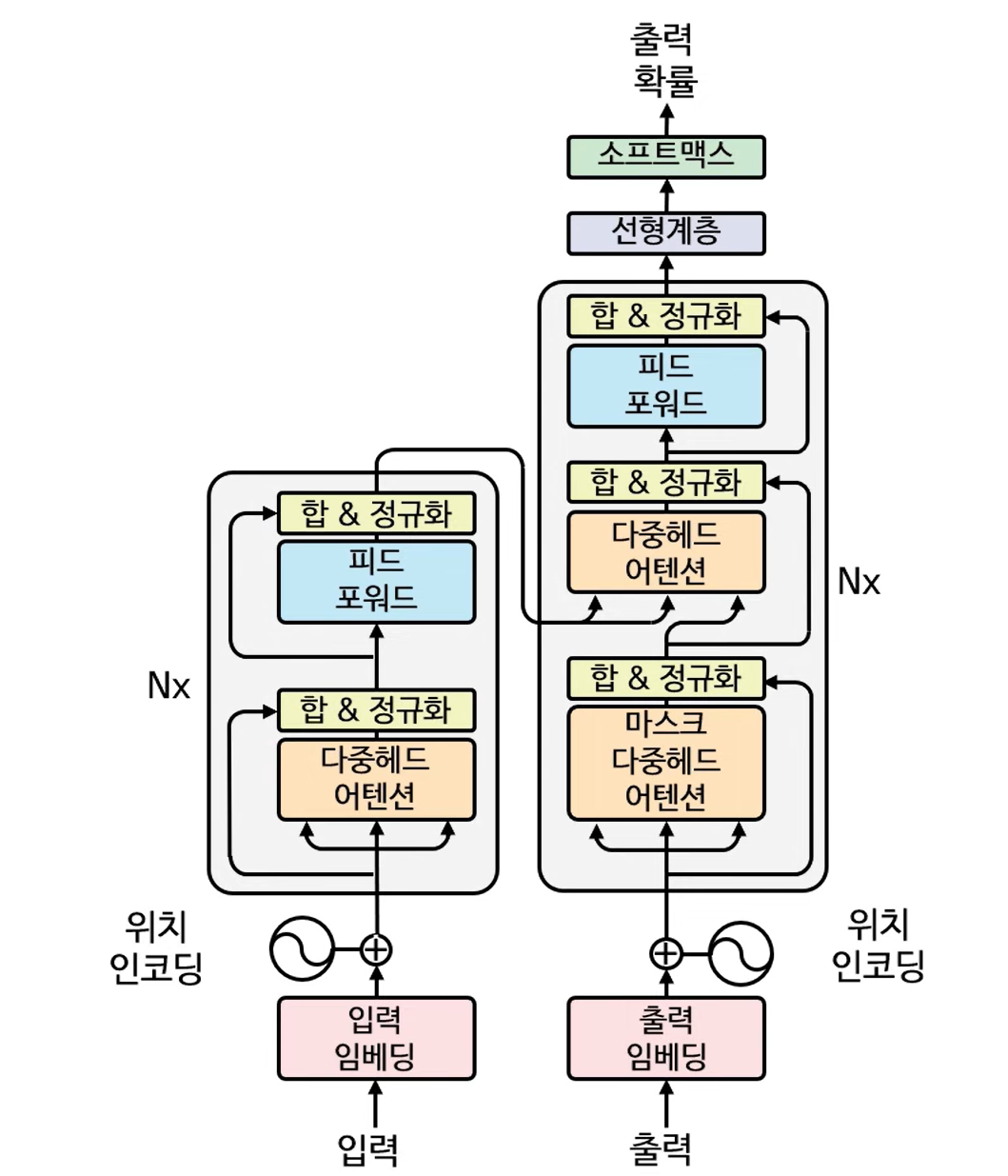
트랜스포머 모델 학습 과정
- 데이터 셋 만들기
- 데이터 셋에서 단어 추출
- 각 단어(토큰)에 고유숫자(인덱스) 배정해서 모델이 처리할 수 있는 데이터로 변환
- 임베딩
- 위치 인코딩
self-attention
- 입력 시퀀스의 각 요소가 다른 모든 요소와 상호작용하여 중요한 정보를 학습할 수 있게 하는 메커니즘
- 단어와 단어 사이의 관계를 동적으로 찾는것
- 언어의 구조(문맥)에 대한 이해
- 순차적이지 않기 때문에 병렬 처리가 가능(학습 속도 향상)
self-attention 동작 순서
- 쿼리(Query), 키(Key), 밸류(Value) 생성
-입력 벡터 XXX에서 쿼리 QQQ, 키 KKK, 밸류 VVV를 생성 - 어텐션 스코어(Attention Score) 계산
-쿼리와 키의 내적(dot product)을 통해 어텐션 스코어 계산 - 어텐션 가중치(Attention Weight) 계산
-소프트맥스(softmax) 함수를 통해 어텐션 스코어를 정규화하여 가중치 계산 - 출력
-가중치와 밸류의 가중합을 통해 최종 출력 생성ㄴ
Word Embedding
- 연관성이 높은 단어들을 숫자로 하나의 묶음으로 묶는다
전이학습(Transfer Learning)
- 기존에 학습된 모델을 다른 유사한 작업에 재사용하는 방법
- 대량의 데이터를 사용하여 학습된 모델의 지식을 새로운 태스크에 적용
Pre-training(사전 학습)
- 대규모 데이터셋을 사용하여 모델을 처음 학습하는 과정
- 보통 많은 양의 비지도 학습 데이터로 진행되며, 이후 특정 태스크에 맞춰 미세 조정
파인튜닝
- 기존에 훈련된 AI 모델을 특정한 작업 및 목적에 맞게 재훈련하여 성능을 향상시키는 과정
- 특정 태스크에 맞춰 추가 학습
- 기존 모델의 학습된 Word Embedding과 self-attention 구조를 재사용
아키텍처
- 인공지능 모델의 설계 구조
태스크
- 모델을 통해 해결하려는 구체적인 문제(목적)
