파인튜닝
- 언어모델을 재학습/미세조정
- Open AI는 입력 토큰(프롬프트)과 출력 토큰(응답)의 개수에 따라 금액이 결정
- 파라미터가 많을수록 모델은 더 복잡하고 정교한 패턴, 더 비쌈
* 그래프에서 엣지가 파라미터
고려사항
1. 파라미터당 메모리
2. 성능
3. 가격 (로컬환경에서 파인튜닝 할 시 토큰가격을 반영하지 않음)
4. 오픈소스
5. context windows(모델이 예측을 위해 참조할 수 있는 최대 텍스트 양)
데이터 라벨링 형식
- 일반적인 Instruction-Tuning
- 챗봇 데이터(대화형 AI)
- NLP 태깅
프롬프트와 파인튜닝
- 프롬프트 엔지니어링은 기존의 모델을 변화시키지 않고, 모델의 입력에 특정한 문장을 추가하여 원하는 출력을 얻는 방식이고, 파인튜닝은 미리 학습된 모델을 새로운 작업에 맞게 다시 학습시키는 방식이다.
파인튜닝이 RAG보다 좋은 점
- 파인튜닝은 내장된 데이터로 도출하기 때문에 RAG보다 속도가 빠름
- 파인튜닝이 더 정확하고 신뢰성 있게 결과 도출
파인튜닝 + RAG로 기본적인 질문은 파인튜닝, 데이터에 없는 질문은 RAG를 이용한 검색으로
오픈소스 LLM
- LLaMA3-B (2024년 4월18일)
- 멀티모달 지원: 텍스트만
- 학습 데이터셋 크기: 15조 개 토큰
- 컨텍스트 길이: 8192
- 단점: 멀티모달이 아니어서 텍스트만 이해가능
- 라마2에 GQA (Grouped Query Attention) 적용(추론 효율성 개선)
- Gemma2-9B (Gemini는 오픈소스 아님) - Google (2024년05월14일)
- 멀티모달 지원: 텍스트, 이미지, 오디오, 동영상, 코드등
- 학습 데이터셋 크기: 8조 개 토큰
컨텍스트 윈도우 길이: 8k개 - 장점: 많은 컨텍스트 윈도우를 넣을수 있다, llama-3보다 에러율이 적다
- 27B이 경우 LLaMA3-70B보다 절반도 안되는 크기지만 비슷한 성능을 제공한다.
9B의 경우 LLaMA3-8B및 다른 모델보다 뛰어난 성능을 보여준다. - 어텐션 매커니즘: Global Attention, GQA
- Gemma1은 한국어 지원이 잘 안되지만, Gemma2는 한국어에 높은 정확도를 보여준다
- Mistral Large2
- 컨텍스트 원도우: 8k
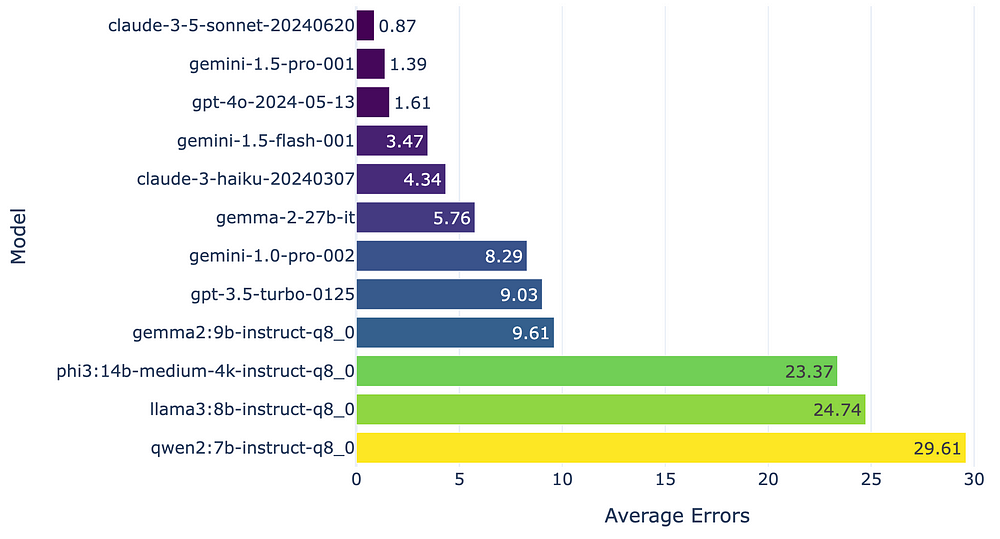
오류율
gemma2-9b가 llama3-8b보다 적은 오류율을 보여준다
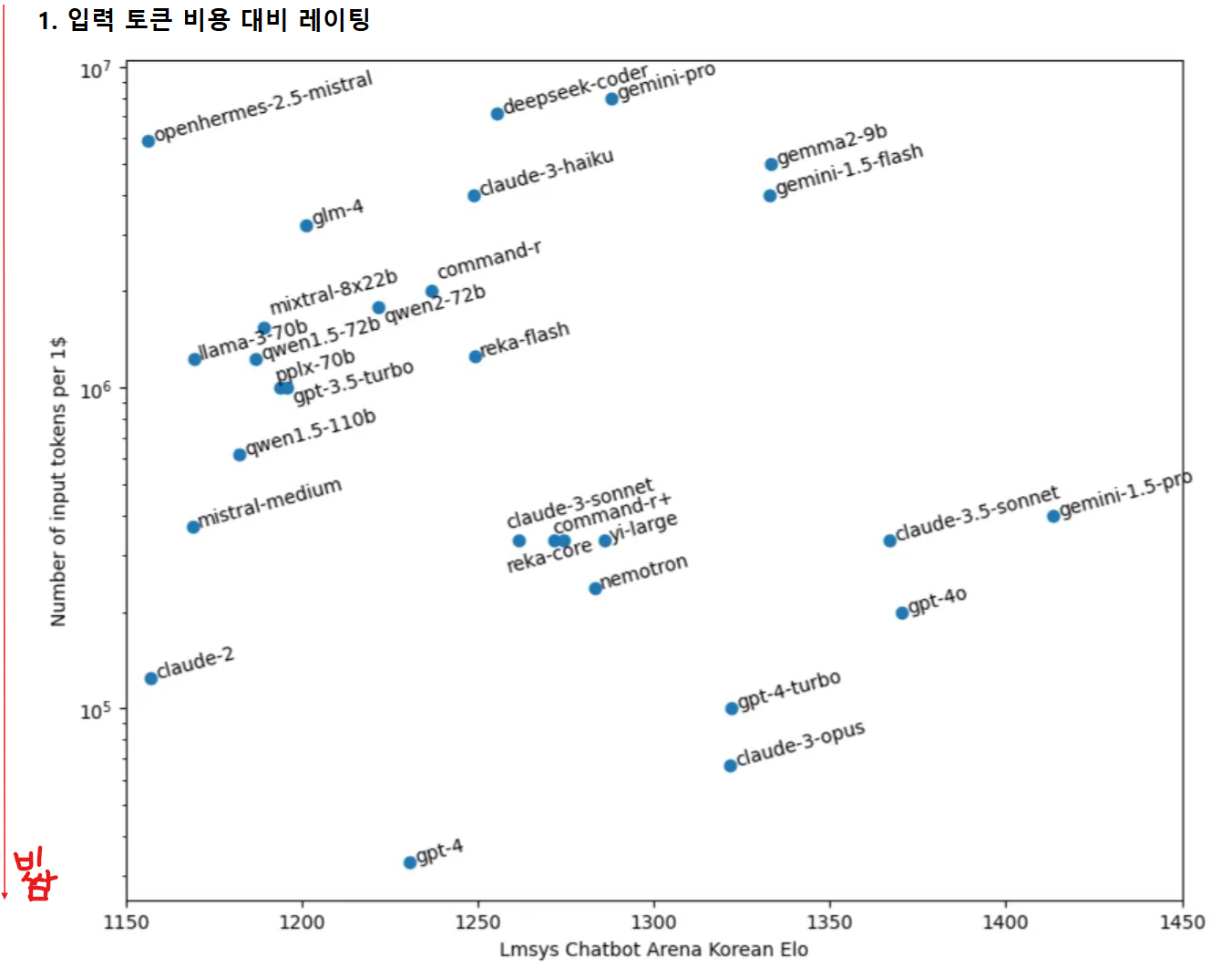
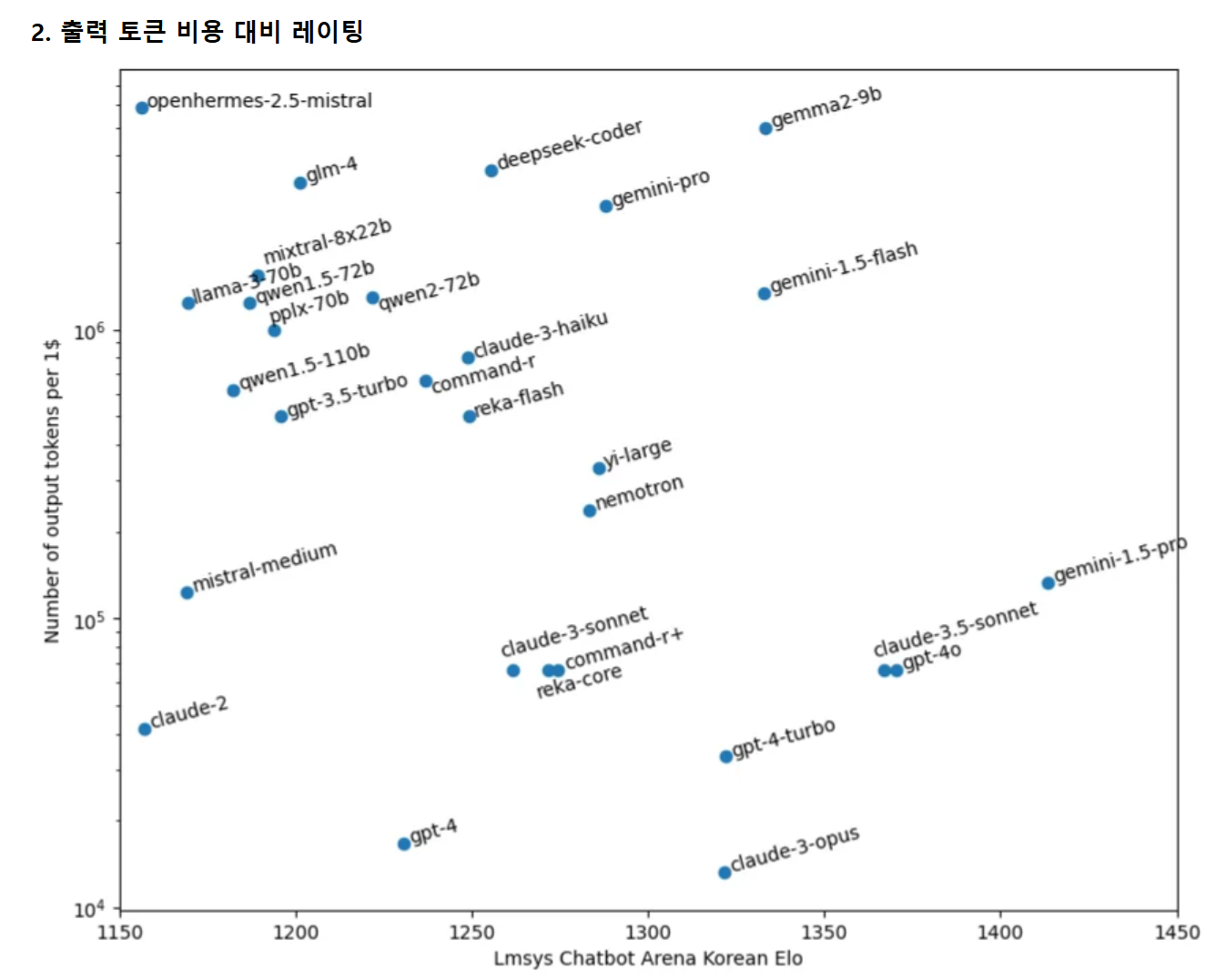
gemma2-9B가 LLaMA3보다 토큰 비용이 더 싸다
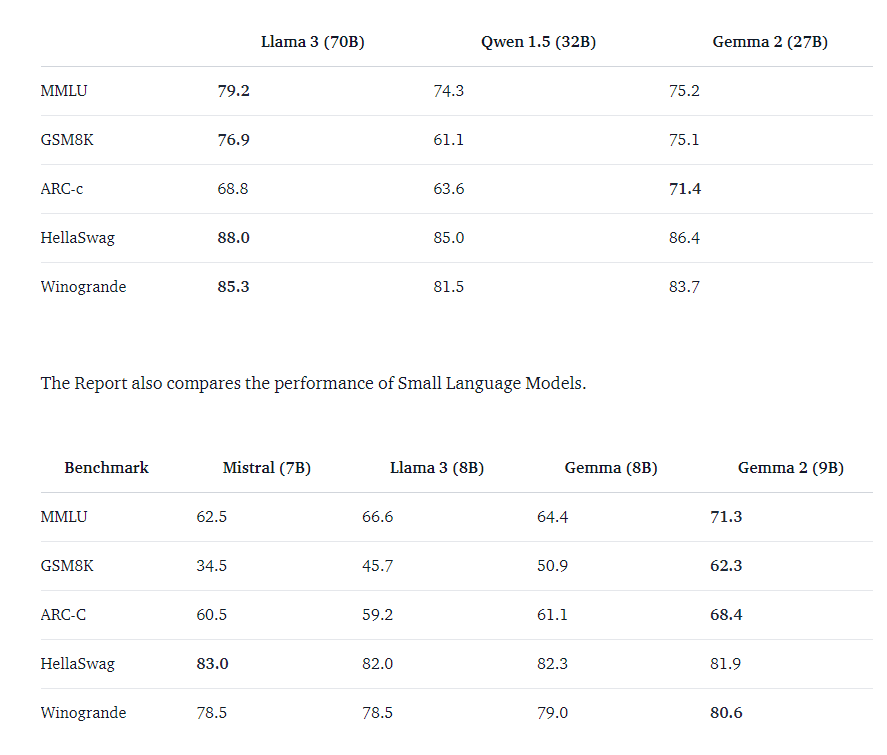
다른 모델에 비교해서 비슷하거나 높은 성능을 보여준다
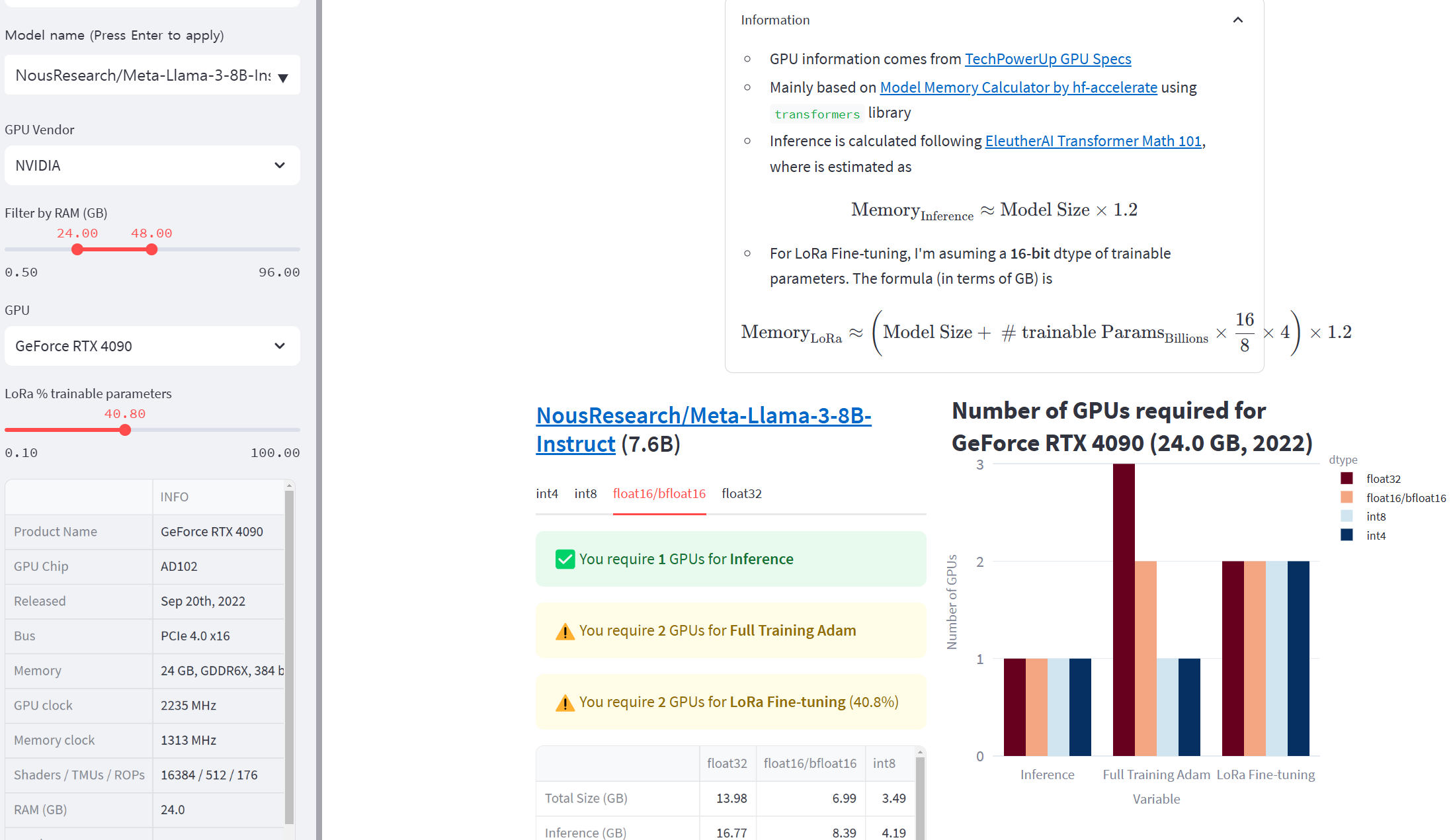
Llama3-8B기준 RTX4090 24GB 2개 필요
결과
Gemma2가 llama3보다 크기도 비슷하고 성능과 가격대비 효율이 높기 때문에 Gemma2 선택
