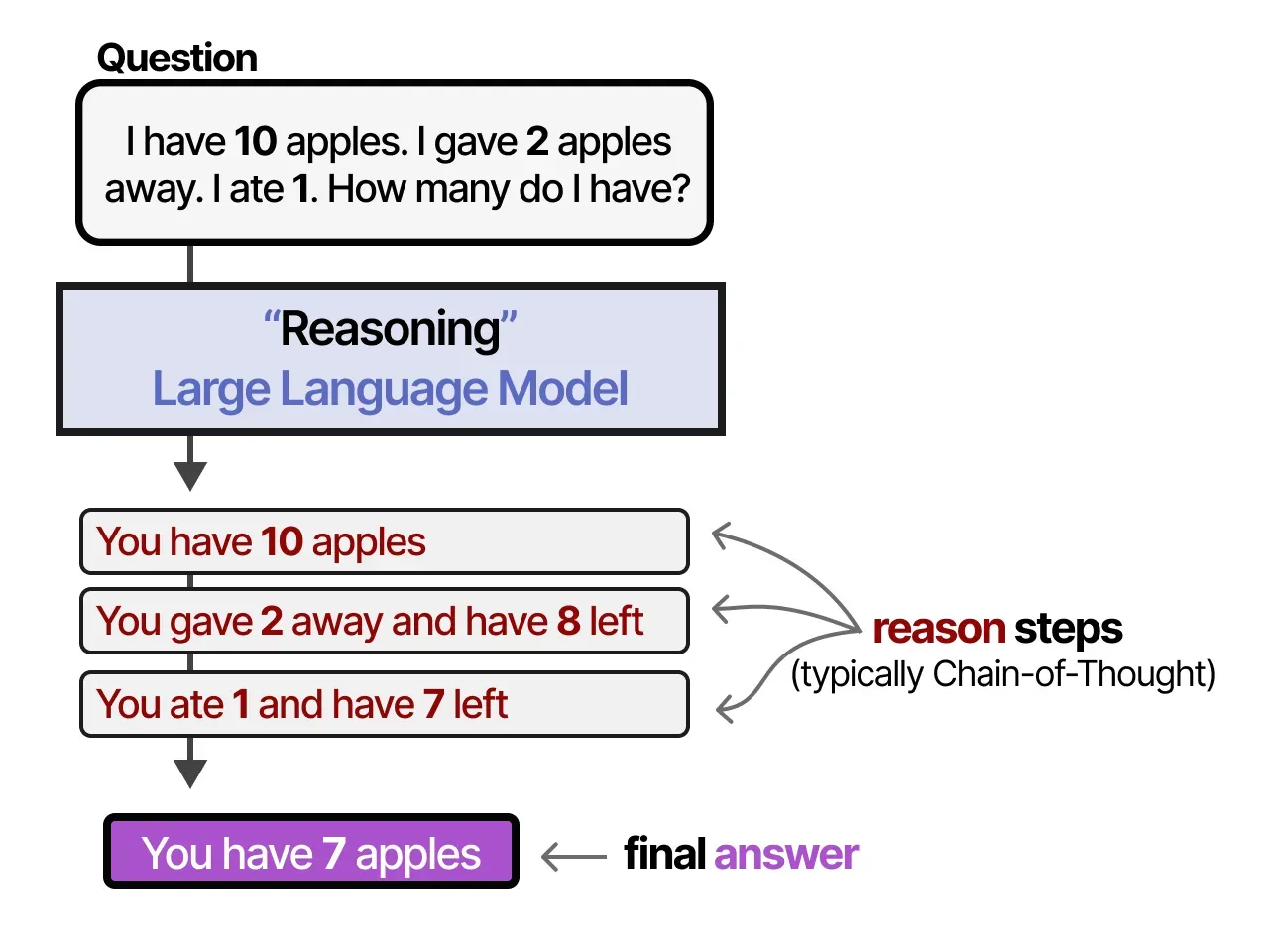
reasoning LLMs
일반적인 LLM과 달리 주어진 질문에 답하기 전에 문제를 더 작은 단계(reasoning steps/thought processes)로 나눈다 -> reasoning(추론) 단계는 과정을 더 작은, 구조화된 추론(inference)으로 분해한다
train-time compute
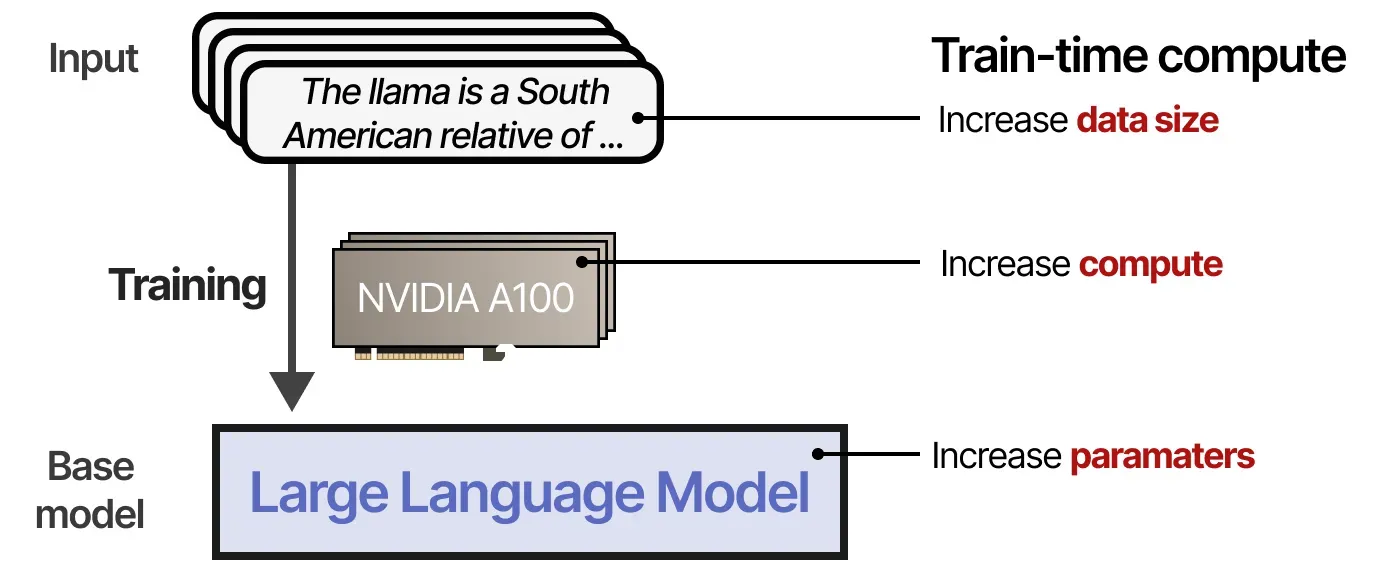
pre-training(사전 학습)동안 LLMs의 성능을 높이기 위해서는
-Model(parameters)
-Dataset(tokens)
-Compute(FLOPS)(연산량)
의 크기를 늘렸다.
이 모든걸 train-time compute라 한다(AI의 연료)
이
scaling Laws
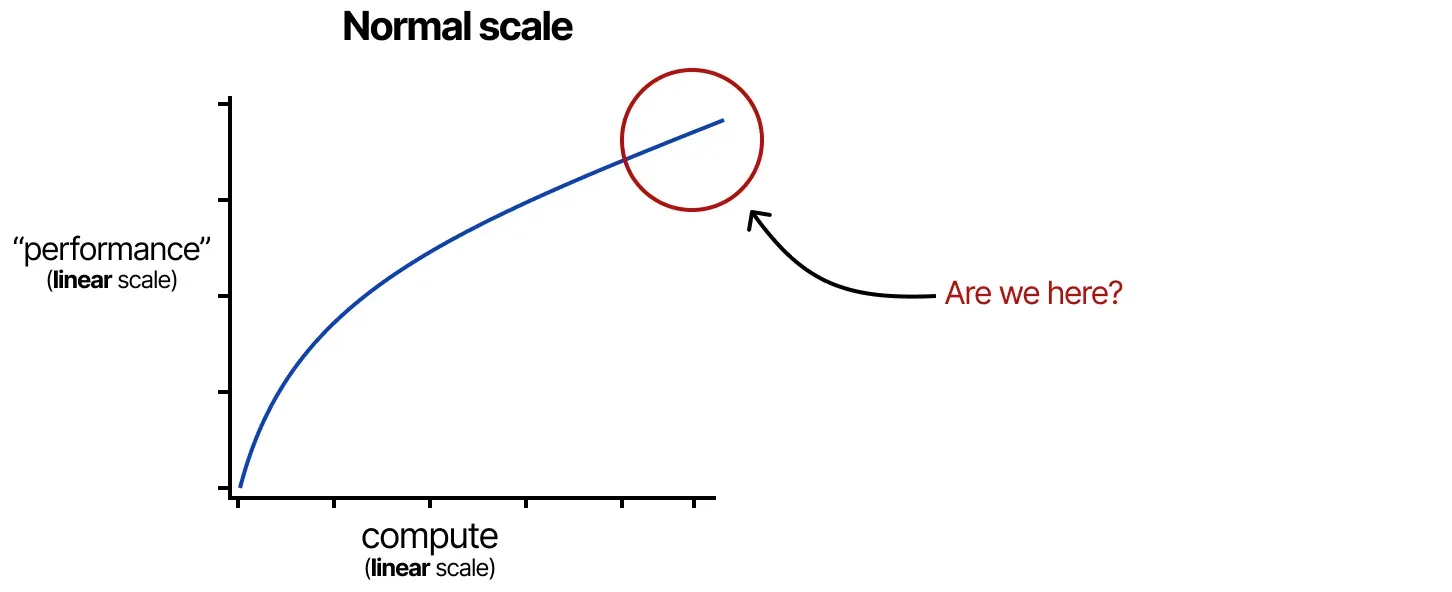
scaling laws: 모델의 규모(연산, 데이터셋 크기, 모델 크기)가 모델 성능과 어떤 상관관계를 갖는지에 대한 분야.
한 요소가 증가하면 다른 요소도 비례적으로 변환한다(log-log 스케일 형태. 그래프가 직선형태) = power laws
- Kaplan의 Scaling Law: 고정된 compute에서 모델 크기를 키우는 것이 일반적으로 데이터를 확장하는 것보다 더 효과적
- Chinchilla의 Scaling Law: 모델 크기와 데이터가 동등하게 중요
하지만 시간이 갈수록 compute, dataset, model parameters가 꾸준히 증가해도 이득이 서서히 감소하는 diminishing returns 현상이 나타남
test-time Compute
사전 학습 예산을 계속 늘리는 대신, 모델이 추론 시점에 더 오래 생각할 수 있도록
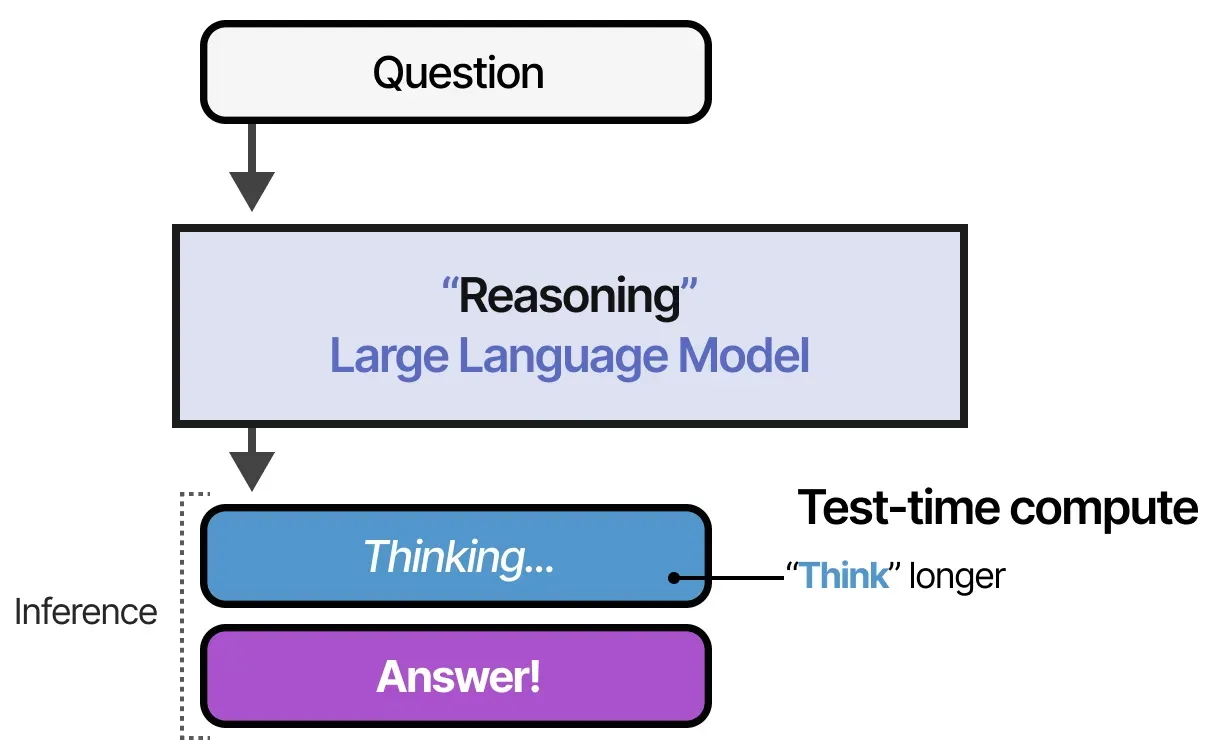
- 비-reasoning 모델의 경우 인풋 후 답만 도출하지만, reasoning 모델은 체계적인 thinking 과정을 통해 답을 도출하기 위해 더 많은 compute -> 더 많은 토큰을 소모한다
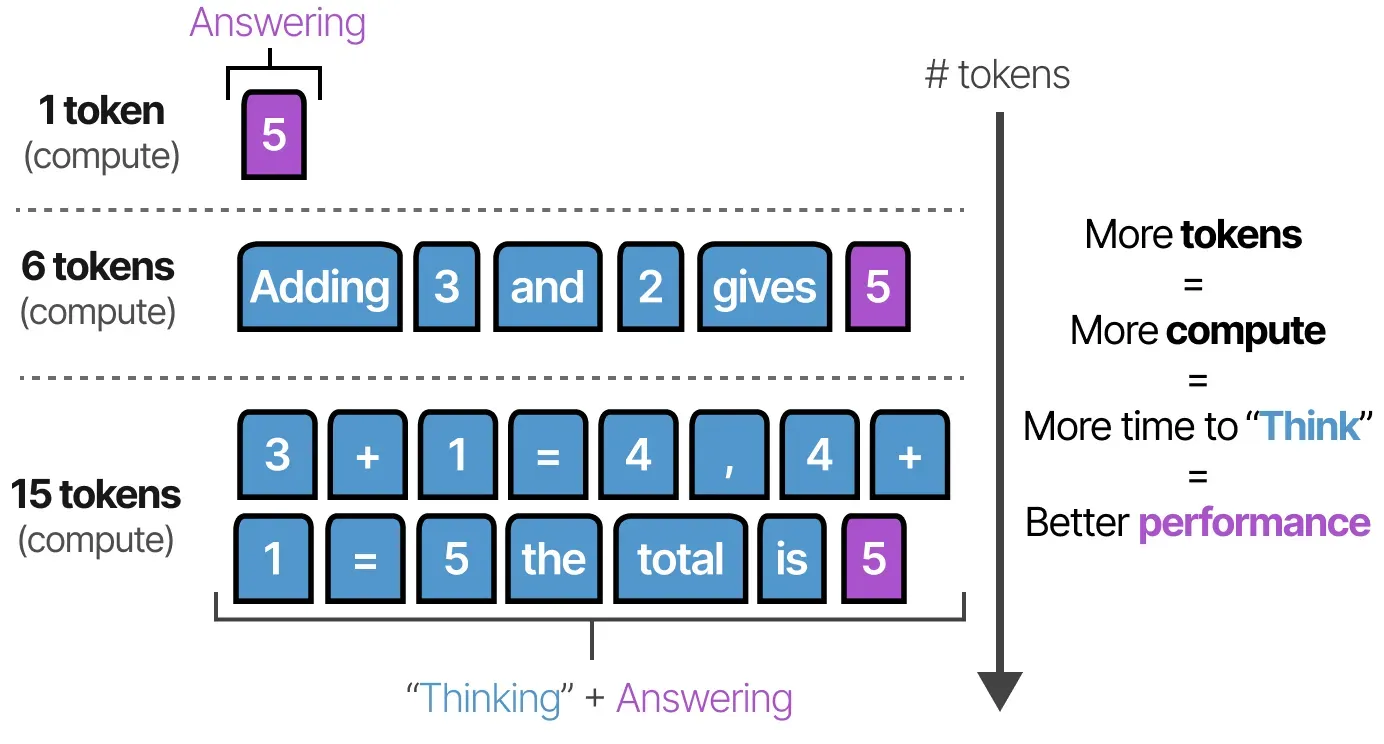
reasoning 모델은 점점 더 많은 test-time compute를 활용
