
💬 윤성우 님의 <열혈 C++ 프로그래밍> 책을 혼자 공부하며 배운 내용을 정리합니다. 글의 모든 내용은 책에서 발췌하였습니다.
대입 연산자의 오버로딩
복사 생성자에 대해서 다시 한번 상기하고 넘어가자
- 정의하지 않으면 디폴트 복사 생성자가 생성된다.
- 디폴트 복사 생성자는 멤버 대 멤버의 얕은 복사를 진행한다.
- 생성자 내에서 동적 할당을 하거나 깊은 복사를 하기 위해서는 반드시 직접 정의해야 한다.
그리고 대입 연산자의 대표적인 특징으로는 아래와 같은 것들이 있다.
- 정의하지 않으면 디폴트 대입 연산자가 생성된다.
- 디폴트 대입 연산자는 멤버 대 멤버의 얕은 복사를 진행한다.
- 연산자 내에서 동적 할당을 하거나 깊은 복사를 하기 위해서는 반드시 직접 정의해야 한다.
정말 유사한 점이 많다. 하지만 호출되는 시점이 다르다.
복사 생성자가 호출되는 상황은 다음과 같다.
int main()
{
Point pos1(3, 4);
Point pos2 = pos1;
}여기서 중요한 사실은 새로 생성하는 객체 pos2의 초기화에 기존에 생성된 객체 pos1이 사용되었다는 점이다.
다음은 대입 연산자가 호출되는 상황은 다음과 같다.
int main()
{
Point pos1(3, 4);
Point pos2(5, 6);
pos2 = pos1;
}여기서 중요한 사실은 pos2, pos1 모두 이미 생성 및 초기화가 진행된 객체라는 점이다.
그리고 앞서 살펴본 연산자 오버로딩 내용에 따라, pos2 = pos1; 의 문장은 다음의 형태로 해석됨을 알 수 있다.
pos2.operator=(pos1);
이제 대입 연산자의 특성을 확인할 수 있는 예제를 살펴보자.
두 개의 클래스를 정의하고 한 클래스에는 대입 연산자를 정의하고 한 클래스에는 정의하지 않았다.
class First
{
private:
int num1, num2;
public:
First(int n1 = 0, int n2 = 0): num1(n1), num2(n2)
{}
void showData()
{
cout << num1 << ", " << num2 << "\n";
}
};
class Second
{
private:
int num3, num4;
public:
Second(int n3 = 0, int n4 = 0): num3(n3), num4(n4)
{}
void showData()
{
cout << num3 << ", " << num4 << "\n";
}
Second& operator= (const Second& ref)
{
cout << "Second& operator=()\n";
num3 = ref.num3;
num4 = ref.num4;
return *this;
}
};
int main()
{
First fsrc(111, 222);
First fcpy;
Second ssrc(333, 444);
Second scpy;
fcpy = fsrc;
scpy = ssrc;
fcpy.showData();
scpy.showData();
cout << "\n";
First fob1, fob2;
Second sob1, sob2;
fob1 = fob2 = fsrc;
sob1 = sob2 = ssrc;
fob1.showData();
sob1.showData();
}111, 222
333, 444
Second& operator=()
Second& operator=()
111, 222
333, 444First 클래스도 잘 대입이 되는걸 보니 디폴트 대입 연산자가 삽입되어 멤버 대 멤버의 복사가 일어났음을 알 수 있다.
그리고 멤버 대 멤버의 복사가 이루어지는 것을 보면서, C언어의 구조체 변수간 대입 연산의 결과와 비슷하다고 생각하기 쉽다.
객체 간의 대입 연산은 C언어의 구조체 대입 연산과 본질적으로 다르다. 이는 단순한 대입 연산이 아닌 대입 연산자를 오버로딩한 함수의 호출이기 때문이다.
디폴트 대입 연산자의 문제점
이전에 복사 생성자의 문제점에서도 같은 문제점을 다루었는데 한번 살펴보자.
class Person
{
private:
char* name;
int age;
public:
Person(char* myname, int myage)
{
int len = strlen(myname) + 1;
name = new char[len];
strcpy(myname, name);
age = myage;
}
void showInfo()
{
cout << "이름 : " << name << "\n";
cout << "나이 : " << age << "\n";
}
~Person()
{
delete []name;
cout << "called destructor\n";
}
};
int main()
{
Person man1("Lee", 25);
Person man2("Park", 30);
man2 = man1;
man1.showInfo();
man2.showInfo();
}위 코드를 실행하면 소멸자가 한 번만 출력된다. 앞서 복사 생성자에서 다루었듯 man2 = man1 에서의 얕은 복사가 문제이다.
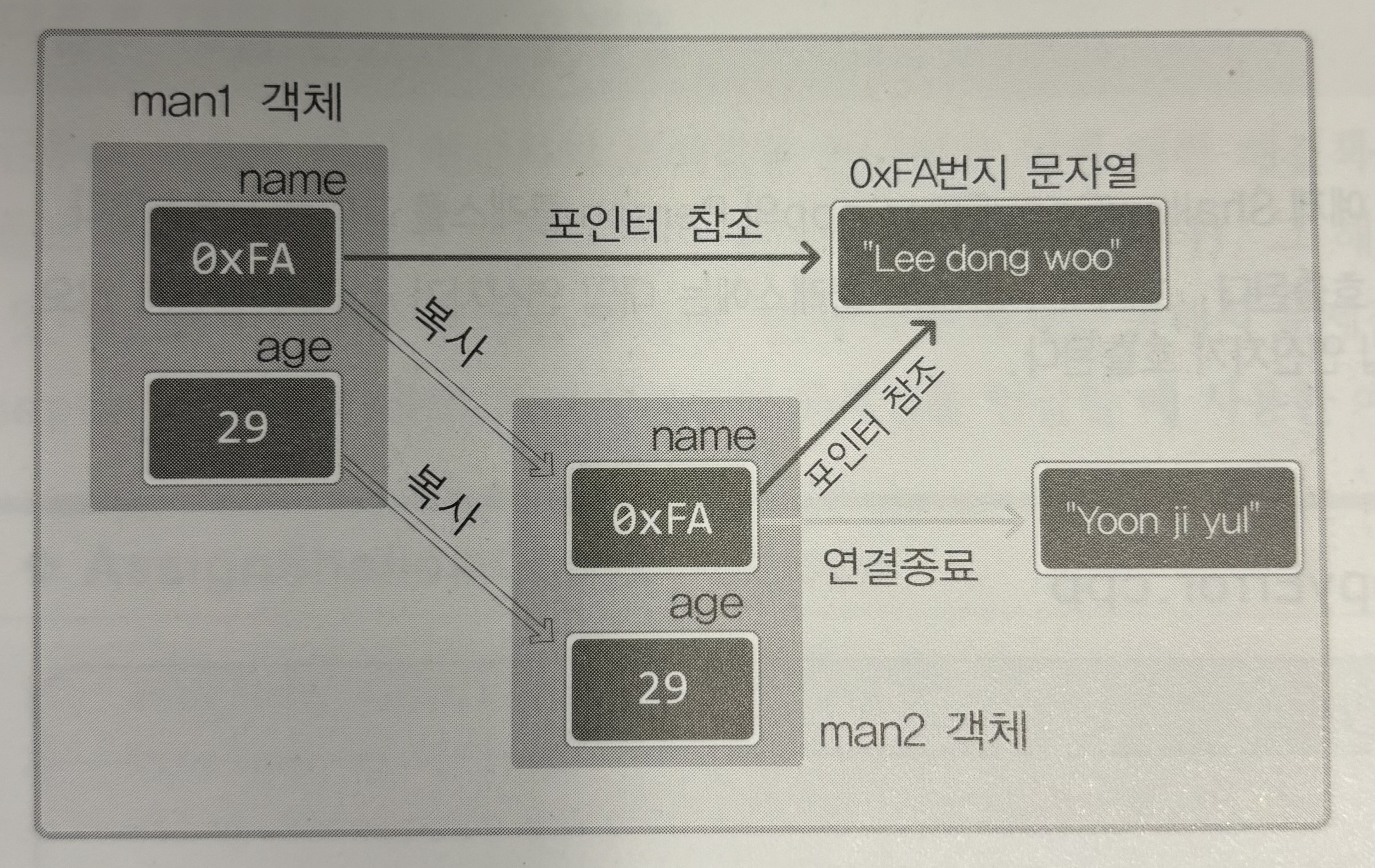
하나의 문자열을 두 객체가 동시에 참조하는 상황이 만들어지며, 두 가지 문제가 발생하게 된다.
- 문자열 'Yoon ji yul' 을 가리키던 문자열의 주소 값을 잃게 됨
- 얕은 복사로 인해 객체 소멸과정에서 이미 지워진 문자열을 중복 소멸하는 문제
생성자 내에서 동적 할당을 진행하는 경우, 디폴트 대입 연산자는 문제가 발생하므로 직접 대입 연산자를 정의하여 깊은 복사를 진행하고 메모리 누수가 발생하지 않도록 깊은 복사에 앞서 메모리 해제 과정을 거치게 해야 한다.
두 문제를 해결한 대입 연산자 오버로딩 함수는 다음과 같다.
Person& operator= (Person &ref)
{
delete []name;
name = new char[strlen(ref.name) + 1];
strcpy(name, ref.name);
age = ref.age;
return *this;
}상속 구조의 대입 연산자 호출
유도 클래스의 생성자에 아무 명시를 하지 않아도 기초 클래스 생성자가 호출되지만, 대입 연산자에서는 그렇지 않다.
유도 클래스의 대입 연산자에 아무 명시를 하지 않으면 기초 클래스의 대입 연산자가 호출되지 않는다.
다음의 예제로 직접 확인할 수 있다.
class First
{
private:
int num1, num2;
public:
First(int n1=0, int n2=0) : num1(n1), num2(n2)
{}
void showData()
{
cout << num1 << num2 << "\n";
}
First& operator= (First& ref)
{
cout << "First operator=\n";
num1 = ref.num1;
num2 = ref.num2;
return *this;
}
};
class Second : public First
{
private:
int num3, num4;
public:
Second(int n1, int n2, int n3, int n4) : First(n1, n2), num3(n3), num4(n4)
{}
void showData()
{
First::showData();
cout << num3 << num4 << "\n";
}
/* 일단 이 부분을 주석처리 하고 실행
Second& operator= (Second& ref)
{
cout << "Second operator=\n";
num3 = ref.num3;
num4 = ref.num4;
return *this;
}
*/
};
int main()
{
Second ssrc(11, 22, 33, 44);
Second scpy(0, 0, 0, 0);
scpy = ssrc;
scpy.showData();
}First operator=
11 22
33 44위 결과를 보면, 유도 클래스에 삽입된 디폴트 대입 연산자가 기초 클래스의 대입 연산자를 호출하는 것을 볼 수 있다.
이제 주석을 해제하고 실행하면 다음과 같은 결과를 볼 수 있다.
Second operator=
0 0
33 44First 클래스의 멤버 변수는 복사가 다 되지 않는 것을 볼 수 있다.
유도 클래스의 대입 연산자 정의에서 명시적으로 기초 클래스의 대입 연산자 호출을 삽입하지 않으면 기초 클래스 대입 연산자는 호출되지 않아서 기초 클래스의 멤버 변수는 복사가 되지 않는다.
따라서 First 클래스의 멤버까지 복사하려고 하면 Second 클래스의 대입 연산자 오버로딩 함수에서 First::operator=(ref);를 넣어주어야 한다.
상속과 관련하여 이런 궁금증이 생길 수 있다.
ref는 Second형 참조자인데 이를 First형 참조자로 매개변수를 선언한 operator= 함수의 인자로 전달이 가능할까?
정답은 '가능' 이다. First 형 참조자를 매개변수로 선언했다는 것은, First 객체뿐만 아니라 First 객체를 직/간접적으로 상속하는 모든 클래스 객체들을 참조할 수 있다는 것이다.
이니셜라이저의 성능적 장점
다음 예제를 보자.
class AAA
{
private:
int num;
public:
AAA(int n = 0) : num(n)
{
cout << "AAA(int n = 0)\n";
}
AAA(const AAA& ref) : num(ref.num)
{
cout << "AAA(int const AAA& ref)\n";
}
AAA& operator=(const AAA& ref)
{
cout << "AAA operator=\n";
num = ref.num;
return *this;
}
};
class BBB
{
private:
AAA mem;
public:
BBB(const AAA& ref) : mem(ref)
{}
};
class CCC
{
private:
AAA mem;
public:
CCC(const AAA& ref)
{
mem = ref;
}
};
int main()
{
AAA obj1(12);
cout << "====================\n";
BBB obj2(obj1);
cout << "====================\n";
CCC obj3(obj1);
}AAA(int n = 0)
====================
AAA(int const AAA& ref)
====================
AAA(int n = 0)
AAA operator=BBB 클래스는 AAA 멤버를 이니셜라이저로 초기화 하고 있고, 반면 CCC 클래스는 AAA 멤버를 함수의 몸체에서 대입함으로써 초기화하고 있다.
그런데 출력의 결과를 보면 BBB 클래스는 AAA 클래스의 생성자만 호출한 반면 CCC 클래스는 AAA 클래스의 대입 연산자와 생성자를 모두 호출하고 있다.
그 이유는 이니셜라이저를 처음 다룰 때 언급했지만 한번 더 상기하자면 이니셜라이저를 이용하면 선언과 동시에 초기화가 이루어지고, 생성자의 몸체부분에서 대입연산자를 이용한 초기화를 하면 선언과 초기화가 각각 따로따로 진행되기 때문이다.
배열의 인덱스 연산자
C/C++의 기본 배열은 범위 검사를 하지 않는다 는 단점이 있다.
배열의 바운더리를 벗어나는 인덱스를 참조하려고 해도 컴파일도 잘 되고 실행도 잘 되기 때문에, 좋은 현상은 아니다.
이러한 단점의 해결을 위해 배열의 역할을 수행할 수 있는 클래스를 만들어보고자 한다.
배열 연산자도 오버로딩이 가능하다는 사실을 알고 나면, arr[2] 은 곧 arr.operator[](2) 라는 사실을 이제는 어렵지 않게 생각해낼 수 있다.
간단히 클래스를 정의해보자.
class BoundaryCheckIntArray
{
private:
int* arr;
int arrlen;
BoundaryCheckIntArray(const BoundaryCheckIntArray& arr) {};
BoundaryCheckIntArray& operator= (const BoundaryCheckIntArray& arr) {};
public:
BoundaryCheckIntArray(int len) : arrlen(len)
{
arr = new int[len];
}
int getArrlen() const
{
return arrlen;
}
int& operator[] (int idx)
{
if (idx < 0 || idx >= arrlen)
{
cout << "Array out of bound execption\n";
exit(1);
}
return arr[idx];
}
~BoundaryCheckIntArray()
{
delete []arr;
}
};
int main()
{
BoundaryCheckIntArray arr(5);
for(int i=0;i<5;i++)
{
arr[i] = (i + 1) * 11;
}
for (int i=0;i<6;i++)
{
cout << arr[i] <<"\n";
}
}11
22
33
44
55
Array out of bound execption[] 연산자 오버로딩 함수에서는 인덱스 범위를 먼저 확인하고 인덱스에 접근하도록 하여 범위 바깥으로 벗어나지 않도록 막아주는 역할을 하고 있다. 이렇게 클래스를 정의하면 배열 접근의 안전성을 보장받을 수 있다.
안전성을 더 높이고자 한다면 배열의 복사 생성자, 대입 연산자를 private 처리해서 접근 불가능하게 막을 수도 있다.
class BoundaryCheckIntArray
{
private:
int* arr;
int arrlen;
BoundaryCheckIntArray(const BoundaryCheckIntArray& arr) {};
BoundaryCheckIntArray& operator= (const BoundaryCheckIntArray& arr) {};
...
}배열은 저장소의 개념이다. 굳이 메모리 공간 안에 같은 내용을 담고 있는 저장소가 여러 개일 필요는 없을 것이다. 따라서, 대부분의 경우 저장소의 복사는 잘못된 것으로 간주한다.
따라서 깊은 복사가 되도록 클래스를 정의할 것이 아닌, 복사와 대입을 원천적으로 막아주는 것이 좋은 선택이 되기도 한다.
이제 배열의 모든 요소들을 출력하는 함수를 만들고자 한다. 따라서 다음과 같이 함수를 정의했다.
void showAllData(const BoundaryCheckIntArray& ref)
{
for(int i=0;i<ref.getArrlen(); i++)
{
cout << ref[i] << " ";
}
cout << "\n";
}함수 실행 간 ref 배열의 값을 변경하지 못하게 하기 위해 const 로 선언하였다. 그런데 컴파일 에러가 발생한다.
그 이유는 인덱스 연산에 있는데, ref[i]란 ref.operator[](i) 로 해석이 되는데 이 때 호출하는 operator[] 함수는 const 함수가 아니기 때문이다.
그런데 우리는 오버로딩 조건 중 const 키워드의 유무도 있다는 것을 알고 있기 때문에, 같은 함수를 const 키워드를 붙여 하나 더 만들 수 있다.
int& operator[] (int idx) const
{
if (idx < 0 || idx >= arrlen)
{
cout << "Array out of bound execption\n";
exit(1);
}
return arr[idx];
}객체의 저장을 위한 배열 클래스
기본 자료형 이외에도 객체를 대상으로 하는 배열 클래스를 제시하고자 한다.
저장의 대상이 되는 클래스는 다음과 같다.
class Point
{
private:
int xpos, ypos;
public:
Point(int x = 0, int y = 0) : xpos(x), ypos(y)
{}
friend ostream& operator<<(ostream& os, const Point& pos);
};
ostream& operator<< (ostream& os, const Point& pos)
{
os << '[' << pos.xpos << ", " << pos.ypos << "]\n";
return os;
}✔︎
ostream& operator<<에 대해서 언급은 하지 않았는데 출력에 사용되는cout <<형태의<<연산자를 오버로딩하여 원하는 포맷대로 출력을 할 수 있게 해준 것이다.
이제 Point 객체의 주소값을 저장하는 배열 클래스, 그리고 Point 객체 자체의 주소값을 저장하는 배열 클래스를 정의할 것이다.
먼저 Point 객체 자체를 저장하는 배열 기반의 클래스이다.
class BoundaryCheckPointArray
{
private:
Point* arr;
int arrlen;
BoundaryCheckPointArray(const BoundaryCheckPointArray& arr) {};
BoundaryCheckPointArray& operator= (const BoundaryCheckPointArray& arr) {};
public:
BoundaryCheckPointArray(int len) : arrlen(len)
{
arr = new Point[len];
}
int getArrlen() const
{
return arrlen;
}
Point& operator[] (int idx)
{
if (idx < 0 || idx >= arrlen)
{
cout << "Array out of bound execption\n";
exit(1);
}
return arr[idx];
}
Point& operator[] (int idx) const
{
if (idx < 0 || idx >= arrlen)
{
cout << "Array out of bound execption\n";
exit(1);
}
return arr[idx];
}
~BoundaryCheckPointArray()
{
delete []arr;
}
};
int main()
{
BoundaryCheckPointArray arr(3);
arr[0] = Point(3, 4);
arr[1] = Point(5, 6);
arr[2] = Point(7, 8);
for (int i=0;i<arr.getArrlen();i++)
{
cout << arr[i];
}
}[3, 4]
[7, 8]
[0, 0]아까 보았던 BoundaryCheckIntArray와 크게 다를 바가 없다.
위의 예제에서 보이듯 객체의 저장은 객체 간의 대입 연산을 기반으로 한다.
따라서 다음 예제처럼 주소 값을 저장하는 방식이 보다 많이 사용된다.
class BoundaryCheckPointArray
{
private:
POINT_PTR* arr;
int arrlen;
BoundaryCheckPointArray(const BoundaryCheckPointArray& arr) {};
BoundaryCheckPointArray& operator= (const BoundaryCheckPointArray& arr) {};
public:
BoundaryCheckPointArray(int len) : arrlen(len)
{
arr = new POINT_PTR[len];
}
int getArrlen() const
{
return arrlen;
}
POINT_PTR& operator[] (int idx)
{
if (idx < 0 || idx >= arrlen)
{
cout << "Array out of bound execption\n";
exit(1);
}
return arr[idx];
}
POINT_PTR& operator[] (int idx) const
{
if (idx < 0 || idx >= arrlen)
{
cout << "Array out of bound execption\n";
exit(1);
}
return arr[idx];
}
~BoundaryCheckPointArray()
{
delete []arr;
}
};
int main()
{
BoundaryCheckPointArray arr(3);
arr[0] = new Point(3, 4);
arr[1] = new Point(5, 6);
arr[2] = new Point(7, 8);
for (int i=0;i<arr.getArrlen();i++)
{
cout << *(arr[i]);
}
}[3, 4]
[5, 6]
[7, 8]주소 값을 저장하고 있을 경우, 깊은 복사 / 얕은 복사 문제를 신경쓰지 않아도 되기 때문에 이 방법이 더 많이 사용된다.
그 이외의 연산자 오버로딩
new 연산자 오버로딩
new와 delete의 오버로딩은 앞서 보았던 연산자 오버로딩과 많이 다르다.
new, delete를 오버로딩할 대상 클래스는 다음과 같다.
class Point
{
private:
int xpos, ypos;
public:
Point(int x = 0, int y = 0) : xpos(x), ypos(y)
{}
friend ostream& operator<<(ostream& os, const Point& pos);
};
ostream& operator<< (ostream& os, const Point& pos)
{
os << '[' << pos.xpos << ", " << pos.ypos << "]\n";
return os;
}이전에 사용했던 간단한 Point 클래스이다.
기본적으로 제공되는 new 연산자의 하는 일은 다음과 같다.
1. 메모리 공간의 할당
2. 생성자의 호출
3. 할당하고자 하는 자료형에 맞게 반환된 주소 값의 형변환
3번째 내용은 C언어에서 사용하던 malloc 함수와는 달리 new 연산자가 반환하는 주소 값을 형변환할 필요가 없음을 의미한다.
여기서, 객체의 생성은 다소 복잡하기 때문에 생성자 호출와 반환 주소값의 형변환은 C++ 컴파일러가 여전히 도맡아서 진행하고, 우리는 1번에 해당하는 '메모리 공간의 할당' 만 오버로딩 가능하다.
new 연산자는 다음과 같이 오버로딩하도록 이미 약속되어 있다.
void* operator new (size_t) size {}
반환형은 반드시 void 포인터, 매개변수형은 size_t여야 한다.
Point* ptr = new Point(3, 4);이제 이런 문장을 만나면, 먼저 필요한 공간을 계산하고, 계산이 완료되면 operator new 함수를 호출해 계산된 값을 인자로 전달한다. 여기서 중요한 것은 '크기 정보는 바이트 단위로 계산된다는 것' 이다.
우리는 다음과 같은 operator new 함수를 만들 수 있다.
void* operator new (size_t size) {
void* adr = new char[size];
return adr;
}크기가 1바이트인 char 단위로 메모리 공간을 할당해서 반환했다.
이렇게 해서 operator new 함수가 메모리 공간의 주소값을 반환하면 컴파일러는 생성자를 호출해서 메모리 공간을 대상으로 초기화를 진행하고, 완성된 객체의 주소 값을 Point 포인터 형으로 형변환하여 반환한다.
여기서, operator new 함수가 한 일은 메모리 공간의 주소값을 반환한 것 뿐, 생성자의 호출정보와는 관련이 없다.
delete 연산자
delete는 new를 이해했다면 쉽게 이해할 수 있다.
Point* ptr = new Point(3, 4);
delete ptr;먼저 컴파일러는 ptr이 가리키는 객체의 소멸자를 호출하고, 다음의 형태로 정의된 함수에 ptr에 저장된 주소 값을 전달한다.
void operator delete (void* addr)
{
delete []addr;
}소멸자는 오버로딩된 함수가 호출되기 전에 호출되므로 오버로딩된 함수에서는 메모리 공간의 소멸을 책임져야 한다.
이제 new, delete 연산자를 직접 오버로딩해 보자.
class Point
{
private:
int xpos, ypos;
public:
Point(int x = 0, int y = 0) : xpos(x), ypos(y)
{}
friend ostream& operator<<(ostream& os, const Point& pos);
void* operator new (size_t size)
{
cout << "Operator new" << size << "\n";
void* adr = new char[size];
return adr;
}
void operator delete (void* addr)
{
cout << "Operator delete\n";
delete []addr;
}
};
ostream& operator<< (ostream& os, const Point& pos)
{
os << '[' << pos.xpos << ", " << pos.ypos << "]\n";
return os;
}
int main()
{
Point* ptr = new Point(3, 4);
cout << *ptr;
delete ptr;
}Operator new 8
[3, 4]
Operator delete출력 결과는 위와 같다.
Point* ptr = new Point(3, 4);이제 여기서 한 가지 궁금증이 든다. 아직 객체 생성이 완성된 상태가 아닌데 어떻게 멤버함수인 operator new 오버로딩 함수를 호출할 수 있었을까?
여기서 기억을 더듬어 보면 객체가 생성되기 전에도 접근할 수 있었던 멤버의 속성이 있었다.
operator new함수와operator delete함수가static함수라면 말이 된다.
그렇다. 사실 operator new 함수와 delete 함수는 모두 static 함수이다.
우리가 오버로딩할 때에 따로 명시해주지 않아도 자동으로 static 함수로 간주된다. 따라서 객체생성이 완료되지 않아도 호출이 가능했던 것이다.
operator new, operator new[]
new 연산자는 다음의 두 가지 형태로 오버로딩이 가능하다.
void* operator new (size_t size) {}
void* operator new[] (size_t size) {}첫 번째는 이미 보았고, 두 번째 함수는 new 연산자를 이용해서 배열 할당 시에 호출되는 함수이다.
즉 다음의 문장을 만나면,
Point* arr = new Point[3];컴파일러는 3개의 Point 객체를 할당하는 데 필요한 메모리를 계산하여 (바이트 단위로) 인자로 전달하면서 함수를 호출한다.
void* operator new[] (size_t size) {}즉 배열 할당 시에 호출되는 함수라는 점 말고는 operator new 함수와 동일하다.
delete도 동일하게, 다음과 같은 두 가지 형태로 오버로딩이 가능하다.
void* operator delete (void* addr) {}
void* operator delete[] (void* addr) {}간단한 예제로 이를 확인해 보면 :
class Point
{
private:
int xpos, ypos;
public:
Point(int x = 0, int y = 0) : xpos(x), ypos(y)
{}
friend ostream& operator<<(ostream& os, const Point& pos);
void* operator new (size_t size)
{
cout << "Operator new" << size << "\n";
void* adr = new char[size];
return adr;
}
void* operator new[] (size_t size)
{
cout << "Operator new []" << size << "\n";
void* adr = new char[size];
return adr;
}
void operator delete (void* addr)
{
cout << "Operator delete\n";
delete []addr;
}
void operator delete[] (void* addr)
{
cout << "Operator delete []\n";
delete []addr;
}
};
ostream& operator<< (ostream& os, const Point& pos)
{
os << '[' << pos.xpos << ", " << pos.ypos << "]\n";
return os;
}
int main()
{
Point* ptr = new Point(3, 4);
Point* arr = new Point[3];
cout << *ptr;
delete ptr;
delete []arr;
}Operator new 8
Operator new [] 24
[3, 4]
Operator delete
Operator delete []포인터 연산자 오버로딩
포인터를 기반으로 하는 모든 연산자를 포인터 연산자라고 한다. 그 중에서도 대표적으로 포인터가 가리키는 객체의 멤버에 접근하는 -> 연산자와 포인터가 가리키는 객체에 접근하는 * 연산자가 있다.
이 두 연산자의 오버로딩은 일반 연산자의 오버로딩과 큰 차이가 없다.
다만 둘 다 피연산자가 하나인 단항 연산자의 형태로 오버로딩된다는 특징만 기억하면 된다.
class Point
{
private:
int xpos, ypos;
public:
Point(int x = 0, int y = 0) : xpos(x), ypos(y)
{}
friend ostream& operator<<(ostream& os, const Point& pos);
};
class Number
{
private:
int num;
public:
Number(int n) : num(n) {}
void showData()
{
cout << num << "\n";
}
Number* operator->()
{
return this;
}
Number& operator*()
{
return *this;
}
};
int main()
{
Number num(10);
num.showData();
(*num) = 30;
num->showData();
(*num).showData();
return 0;
}-> : 객체 자신의 주소값을 반환하도록 하고 있다.
* : 객체 자신을 참조 형태로 반환하도록 하고 있다.
(*num) = 30, (*num).showData() 문법의 경우 (num.operator*()) = 30, (num.operator*()).showData()로 해석할 수 있는데, num->showData() 는 조금 까다롭다.
똑같이 해석하면 num.operator-> showData() 인데 operator 함수가 반환하는 것은 주소값이기 때문에 이런 문법은 맞지 않다. 따라서 반환되는 주소값을 대상으로 적절한 연산이 가능하도록 -> 연산자를 하나 더 붙여 num.operator->()->Showdata() 로 해석을 진행한다.
스마트 포인터
우리가 알고 있는 포인터는 스스로 하는 일이 아무것도 없지만 스마트 포인터는 스스로 하는 일이 존재한다.
스마트 포인터는 객체이다. 포인터의 역할을 하는 객체이다.
이 책에서는 스마트 포인터에 대한 개념을 설명하면서 라이브러리에서 제공하는 스마트 포인터의 사용 방법을 설명하지 않고 간단하고 덜 똑똑한 스마트 포인터를 직접 구현해 보기로 한다.
먼저 예제를 살펴보자
class Point
{
private:
int xpos, ypos;
public:
Point(int x = 0, int y = 0) : xpos(x), ypos(y)
{
cout << "객체 생성\n";
}
~Point()
{
cout << "객체 소멸\n";
}
void setPos(int x, int y)
{
xpos = x;
ypos = y;
}
friend ostream& operator<<(ostream& os, const Point& pos);
};
ostream& operator<< (ostream& os, const Point& pos)
{
os << '[' << pos.xpos << ", " << pos.ypos << "]\n";
return os;
}
class SmartPtr
{
private:
Point* posptr;
public:
SmartPtr(Point* ptr): posptr(ptr)
{}
Point& operator*() const
{
return *posptr;
}
Point* operator->() const
{
return posptr;
}
~SmartPtr()
{
delete posptr;
}
};
int main()
{
SmartPtr sptr1(new Point(1, 2));
SmartPtr sptr2(new Point(3, 4));
SmartPtr sptr3(new Point(5, 6));
cout << *sptr1;
cout << *sptr2;
cout << *sptr3;
sptr1->setPos(10, 20);
sptr2->setPos(30, 40);
sptr3->setPos(50, 60);
cout << *sptr1;
cout << *sptr2;
cout << *sptr3;
return 0;
}객체 생성
객체 생성
객체 생성
[1, 2]
[3, 4]
[5, 6]
[10, 20]
[30, 40]
[50, 60]
객체 소멸
객체 소멸
객체 소멸이 예제에서 가장 중요한 사실은 Point 객체의 소멸을 위한 delete 연산이 자동으로 이루어졌다는 것이다.
() 연산자의 오버로딩과 펑터(functor)
함수의 호출과 인자의 전달에 사용되는 () 도 연산자이고, 오버로딩이 가능하다.
이 연산자를 오버로딩하면 객체를 함수처럼 사용할 수 있다.
간단한 내용이기 때문에 예제를 보면 바로 이해할 수 있다.
class Point
{
private:
int xpos, ypos;
public:
Point(int x = 0, int y = 0) : xpos(x), ypos(y)
{}
Point operator+(const Point& pos) const
{
return Point(xpos + pos.xpos, ypos+pos.ypos);
}
friend ostream& operator<<(ostream& os, const Point& pos);
};
ostream& operator<< (ostream& os, const Point& pos)
{
os << '[' << pos.xpos << ", " << pos.ypos << "]\n";
return os;
}
class Adder
{
public:
int operator() (const int& n1, const int& n2)
{
return n1 + n2;
}
double operator() (const double& n1, const double& n2)
{
return n1 + n2;
}
Point operator() (const Point& p1, const Point p2)
{
return p1 + p2;
}
};
int main()
{
Adder adder;
cout << adder(1, 3) << "\n";
cout << adder(1.2, 3.4) << "\n";
cout << adder(Point(3, 4), Point(7, 9)) << "\n";
return 0;
}4
4.6
[10, 13]다양한 타입의 객체를 연산할 수 있는 함수처럼 사용할 수 있다.
이렇게 함수처럼 동작하는 클래스를 가리켜 펑터(Functor) 라고 한다.
또는 함수 오브젝트라고 한다.
임시객체로의 자동 형변환과 형변환 연산자
객체 간의 자료형이 같으면 대입 연산이 가능하다. 이는 대입 연산자를 배울 때 다루었다.
int main()
{
Number num(0);
num = 30;
num.showNumber();
}그럼 위와 같은 객체-정수 간 덧셈도 가능할까?
코드만 보면 안 될 것 같지만 이 역시 컴파일 및 실행에 문제가 없다. 그럼 어떠한 과정을 거쳐서 대입 연산이 가능했는지 출력하면서 알아보자.
class Number
{
private:
int num;
public:
Number(int n=0) : num(n)
{
cout << "number(int n=0)\n";
}
Number& operator=(const Number& ref)
{
cout << "operator()\n";
num = ref.num;
return *this;
}
void showNum()
{
cout << num << "\n";
}
};
int main()
{
Number num;
num = 30;
num.showNum();
return 0;
}number(int n=0)
number(int n=0)
operator()
30출력 결과를 보니 조금 알 것 같다.
Number num;에서 호출된 생성자num = 30;에서 만들어진 임시 객체의 생성으로 호출된 생성자- 임시 객체의 대입으로 인한 대입 연산자
A형 객체가 와야 할 위치에 B형 데이터(혹은 객체)가 왔을 경우 B형 데이터를 인자로 전달받는 A형 클래스의 생성자 호출을 통해 A형 ㅇ미시 객체를 생성한다.
만약 B형 데이터를 인자로 전달받을 수 있는 생성자가 없으면 컴파일 에러가 발생한다.
그리고 반대로 객체를 기본 자료형 데이터로 형변환 하는것도 가능하다.
int main(void)
{
Number num1;
num1 = 30;
Number num2 = num1 + 20;
num2.ShowNumber();
}Number 클래스를 대상으로 위와 같은 덧셈 연산이 가능하기 위해서는
- Number 클래스가 + 연산자를 오버로딩 하고 있거나,
- num1이 int형 데이터로 변환되어야 한다.
연산자 오버로딩을 통한 방법은 이미 다루었으니 Number형인 num1을 int로 형변환 해 보자.
class Number
{
private:
int num;
public:
Number(int n=0) : num(n)
{
cout << "number()\n";
}
Number& operator=(const Number& ref)
{
cout << "operator()\n";
num = ref.num;
return *this;
}
operator int ()
{
return num;
}
void showNum()
{
cout << num << "\n";
}
};
int main()
{
Number num;
num = 30;
Number num2 = num + 30;
num2.showNum();
return 0;
}number()
number()
operator()
number()
60마찬가지로 차근차근 따라가 보면,
Number num;에 의한 생성자30에 의한 임시 객체 생성자- num2의 형변환 연산자
- num2 객체의 생성으로 인한 생성자
