⚠️ 이 글은 경북대학교 컴퓨터학부 이시형 교수님의 '알고리즘2' 수업을 수강하고 배운 점들을 복습하며 기록한 글입니다. 본문 내용을 비롯하여 사진 자료와 코드 또한 이시형 교수님의 수업자료에서 발췌하였습니다. 또한 모든 코드는 python을 사용합니다.
Symbol Table??
심볼 테이블(Symbol Table)은 (key, value)의 쌍을 저장하는 데이터 구조이며, 특히 key를 검색어로 주었을 때, 이에 대응하는 value를 빠르게 찾아주는 구조이다.
다양한 어플리케이션에서 심볼 테이블을 필요로 하므로, 대부분의 프로그래밍 언어에서 심볼 테이블 클래스를 기본으로 제공하고 있고, 언어에 따라 이를 dictionary 또는 map 이라고 한다.
심볼 테이블에서의 key는 유일unique 해야 한다. 그래야만 찾고자 하는 value 데이터를 특정할 수 있기 때문이다.
※ 이 글에서는 python을 사용하므로 기본적인 dictionary 함수를 사용함
Symbol table의 구현
unordered list
원소를 정렬하지 않은 상태로 저장하는 unordered list 방법이 있다.
이 경우, 테이블에 원소를 추가/수정하거나 찾는 작업을 알아보자.
추가/수정
우선, 찾는 key 값이 심볼 테이블에 존재하는지 여부를 알아야 추가할지, 수정할지를 알 수 있다.
정렬하지 않은 상태이므로 평균적으로는 테이블 리스트의 절반을, worst case의 경우 모든 테이블을 뒤져야 할 것이다.
즉 추가/수정 기능의 성능은 N에 비례한다.
찾기
추가/수정과 마찬가지로, 찾는 key 값이 심볼 테이블에 존재하는지 여부를 알아야 한다.
존재한다면 value 값을 리턴, 존재하지 않는다면 예외를 발생시키거나 None 등을 반환한다.
즉, 평균적으로 테이블의 절반을, worst case의 경우 모든 테이블을 뒤져야 한다.
찾기 기능의 성능 또한 N에 비례한다.
ordered list
원소를 정렬한 상태로 저장하는 ordered list 방법에서의 추가/수정 및 찾기 작업을 살펴보면 다음과 같다.
추가/수정
이진 탐색으로 추가 및 수정할 위치를 찾는 것은 logN 만에 가능하지만,그 위치 이후 원소를 한 칸씩 뒤로 옮겨 담아야 하므로 비용은 N이다.
찾기
key값 기준으로 정렬되어 있으므로, 이진 탐색을 통해 logN 만에 찾을 수 있다.
BST(Binary Search Tree)
지금까지 본 심볼 테이블 구현 방식의 단점을 극복하고자 나온 구조가 Binary Search Tree이다.
BST는 다음과 같은 두 가지 성질을 만족한다.
- 이진 트리(Binary Tree) : 모든 노드의 자식 노드는 0~2개이다.
- Symmetric Order : 노드 N의 key는 왼쪽 자식 트리에 있는 모든 key보다 크고, 오른쪽 자식 트리에 있는 모든 key보다 작다.
따라서 더 작은 값을 찾으려면 왼쪽 자식 노드 쪽으로 탐색해 내려가면 되고 더 큰 값을 찾으려면 오른쪽 자식 노드 쪽으로 탐색해 내려가면 된다.
앞서 살펴본 heap과 비교해보면 다음과 같다.
| 분류 | Heap | BST |
|---|---|---|
| 목표 | 효율적인 Priority Queue 구현 | 효율적인 Symbol Table 구현 |
| 기본 | 이진 트리 | 이진 트리 |
| 조건1 | Complete 트리 : 가장 아래 level을 제외하면 빈 곳 없이 가득 차 있고, 가장 아래 level은 왼쪽부터 채워진다 | 왼쪽, 오른쪽 어느 쪽이라도 먼저 자식이 추가될 수 있다 |
| 조건2 | Heap order : 자식 key <= 부모 key. 따라서 PQ에 필요한 최댓값 탐색이 편리 | Symmetric order : 왼쪽 key < 부모 key < 오른쪽 key. 따라서 임의의 key 탐색에 편리 |
| 구현 | 배열로 편리하게 구현 가능 | 배열로 구현 힘듦 |
BST를 통해 효율적으로 수행 가능한 작업
min, max
가장 크거나 작은 값을 빠르게 탐색할 수 있다. 가장 작은 값은 더 내려갈 곳이 없을 때까지 왼쪽 자식을 따라가면 되고, 가장 큰 값은 오른쪽 자식을 따라가면 된다.
floor, ceiling
floor(k)는 key <= k인 key 중 가장 큰 key를 말한다. 즉 k와 같은 key가 존재한다면 이를 반환, 그렇지 않다면 k 바로 전 값을 반환한다.
ceiling(k)는 이와 반대로 key >= k인 key 중 가장 작은 key를 말한다.
floor(k)를 찾는 경우는, 다음과 같은 3가지 경우로 나눌 수 있다.
- 만약
k == x.key라면x.key가 floor(k)이다. - 만약
k < x.key라면 floor(k)는 반드시 x의 왼쪽 sub tree에 있다. - 만약
k > x.key라면- x 오른쪽 sub tree에
<=k인 값이 있다면 그 중 가장 큰 값이 floor(k)이다. - 그렇지 않다면
x.key가 floor(k)이다.
- x 오른쪽 sub tree에
def floor(self, key):
def floorOnNode(x, key):
if x == None: return None
if key == x.key: return x
elif key < x.key: return floorOnNode(x.left, key)
t = floorOnNode(x.right, key)
if t != None: return t
else: return x
x = floorOnNode(self.root, key)
if x == None: return None
else: return x.keyceiling(k)를 찾는 과정도 이와 유사하게 나눌 수 있다.
rank
rank(k)는 k보다 작은 key의 개수를 말한다.
모든 노드는 자신을 포함한 아래 노드의 개수를 나타내는 변수 count를 가진다고 하자.
그리고 x를 root로 한 subtree에서의 k의 rank를 구하는 rankOnNode(x, k) 함수 또한 정의한다.
def sizeOnNode(self, x):
if x == None: return 0
else: return x.count
def size(self):
return self.sizeOnNode(self.root) 이제 rank(k)는 count와 rankOnNode를 이용해서 구할 수 있다. 다음과 같은 4가지 경우로 나눌 수 있다.
- x가
None이라면 비어 있는 트리이므로 rank는 0 k < x.key라면rank(k)는 왼쪽 subtree에서의 rank이다.rankOnNode(x.left, key)k > x.key라면 x 왼쪽 subtree의 모든 노드는 k보다 작고, x 자신의 key도 k보다 작으며, 이에 더해 x 오른쪽 subtree에서도 k보다 작은 노드가 있을 수 있다.x.left.count + 1 + rankOnNode(x.right, key)k == x.key라면 x 왼쪽 sub tree의 모든 노드가 k보다 작으며 그 외에는 k보다 작은 노드가 없다.x.left.count
def rank(self, key): # How many keys < key?
def rankOnNode(x, key): # rank(key) on the subtree rooted at x
if x == None: return 0
if key < x.key: return rankOnNode(x.left, key)
elif key > x.key: return self.sizeOnNode(x.left) + 1 + rankOnNode(x.right, key)
else: return self.sizeOnNode(x.left) # key == x.key
return rankOnNode(self.root, key)
select
select(i)는 크기가 i번째인 key를 나타낸다. rank의 역함수라고 볼 수 있다. rank와 비슷한 방식으로 구현할 수 있다.
BST의 성능
BST의 성능은 트리의 깊이에 비례한다.
원소의 추가/삭제 순서에 따라 깊이는 평균적으로 logN에서 worst case의 경우 N까지 갈 수 있다.
대부분의 경우, 원소 추가/삭제를 반복하다 보면 √N에 가까워져 성능이 떨어진다.
Hash Table
Symbol table의 또다른 구현 방식으로 hash table이 있다.
hash table에는 hash 함수가 존재하며, 키값을 hash 함수로 계산한 값을 index로 사용해 hash table의 저장 위치에 바로 접근 가능하다. 따라서 찾기 및 수정/추가가 상수 시간에 가능하다.
이렇듯 hash table은 key와 정확히 같은 값 탐색에는 매우 유리하지만, key와 근접한 값을 탐색하는 작업이나 원소의 순서를 파악해야 하는 작업에는 불리하다. 유사한 원소라고 하더라도 hash 함수에 넣었을 때의 결과값은 근처에 있지 않다.
그리고, 근접한 값 탐색은 자주 활용된다. 일정 구간이 주어지고 이 구간에 있는 원소들을 찾는다거나, 근삿값을 찾는 경우가 많다.
2-3 tree
2-3 Tree란 각 노드에 2개까지의 키를 저장할 수 있고, 3개까지의 자식을 허용할 수 있다. 이로써 트리의 깊이를 최소화할 수 있다.
2-3 Tree는 BST를 사용해 구현 가능하다.
x 왼쪽 자식 key < 노드 x의 key < x 오른쪽 자식 key 조건을 만족하며, BST에서 수행 가능한 여러 탐색 작업을 마찬가지로 수행 가능하다.
이 트리의 장점은 root에서 리프 노드까지 모든 경로가 같은 길이를 가지는 균형 잡힌 트리라는 점이다.
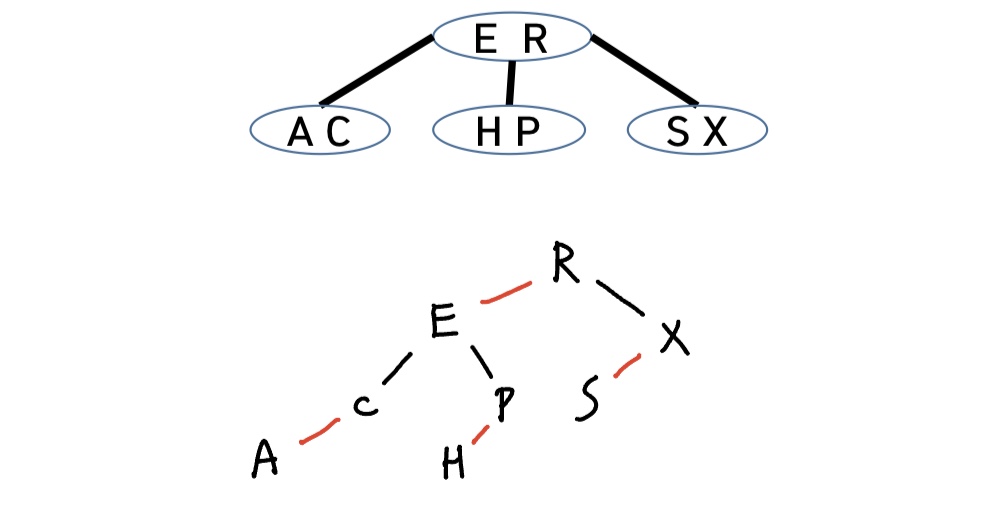
이를 위해 각 노드에 1~2개의 key를 저장하며, 1개의 key, 2개의 자식을 가진 노드를 2-node 라고 하고, 2개의 key, 3개의 자식을 가진 노드를 3-node 라고 한다.
3-node 에서는 왼쪽 자식 < key1 < 가운데 자식 < key2 < 오른쪽 자식 을 만족한다.
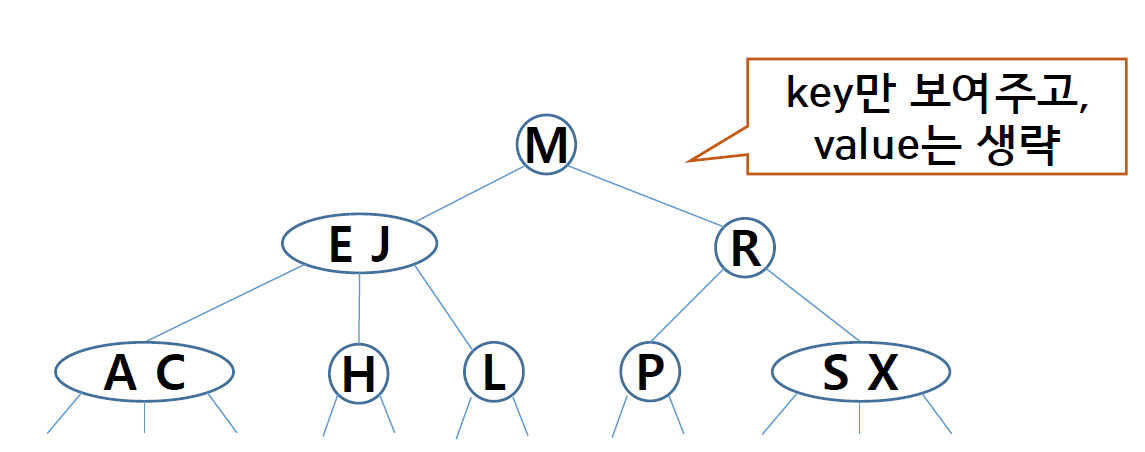
get (찾기)
이러한 3-node에서 값을 찾는 과정은 세 자식 중 하나로 이동한다.
- key < k1 : 왼쪽 자식으로 이동
- k1 < key < k2 : 가운데 자식으로 이동
- k2 < key : 오른쪽 자식으로 이동
만약 두 key 값 중 하나라면 해당 key의 value를 반환한다.
put (추가/삭제)
get처럼 추가할 위치를 찾고 k-node에서 (k+1)-node로 만든다.
get과 같은 방식으로 key가 있을 리프 위치까지 이동한다. 같은 key값이 존재하지 않는다면 노드 타입에 따라 아래와 같이 (key, value)를 추가한다.
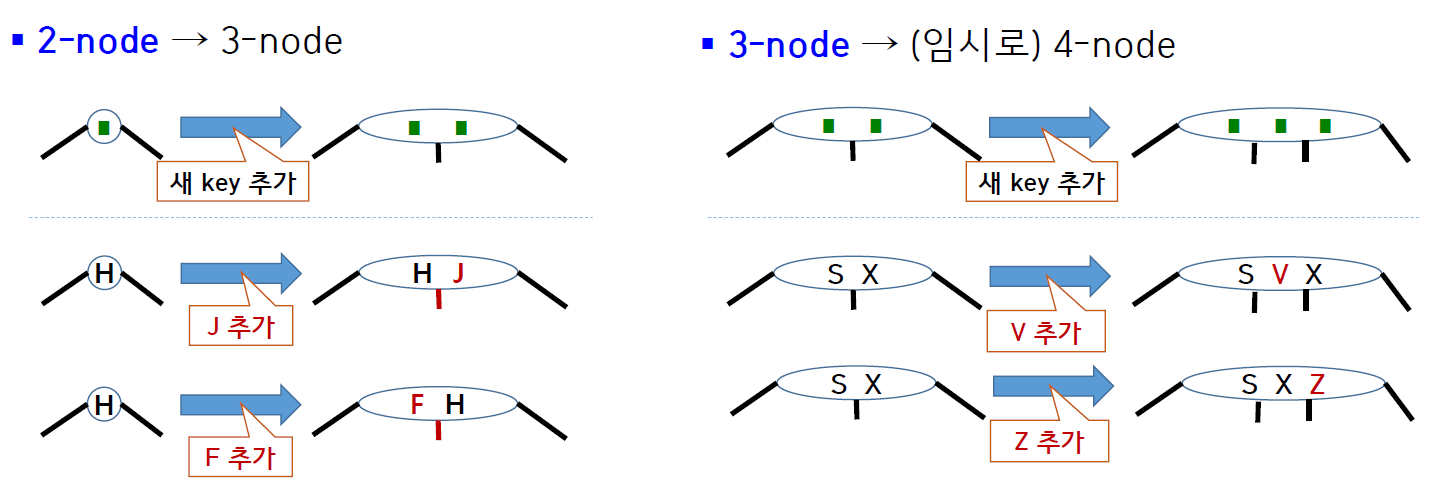
그리고 4-node는 다음과 같은 과정을 거쳐 2-node 두 개로 나뉘어진다.
- 4-node의 key
abc중 가운데 keyb를 부모 노드에 추가한다. - 2개의 2-node
a,c로 분할한다. - 이렇게 만든 부모 노드 역시
b가 올라감에 따라 4-node가 된다면 root 방향으로 분할을 계속한다. root가 4-node라면 가운데 key를 새로운 root로 만들면서 트리의 깊이가 1 증가한다.
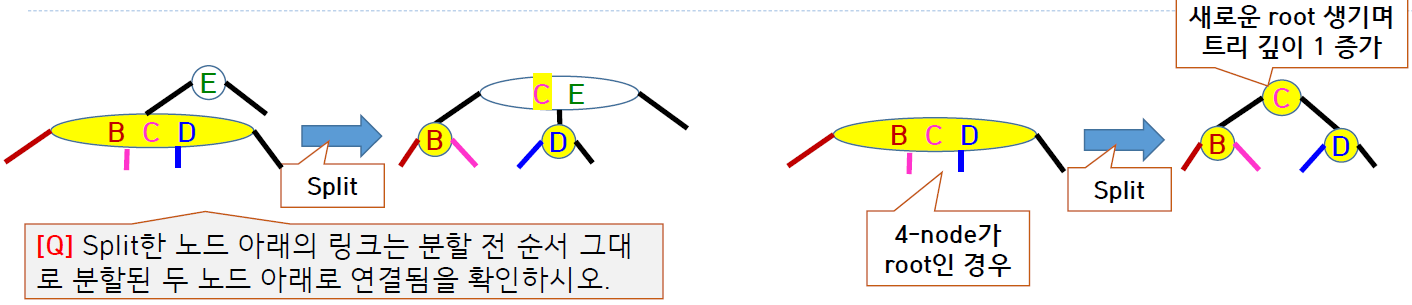
아래는 2-3 tree가 채워지는 과정을 그림으로 나타낸 것이다.
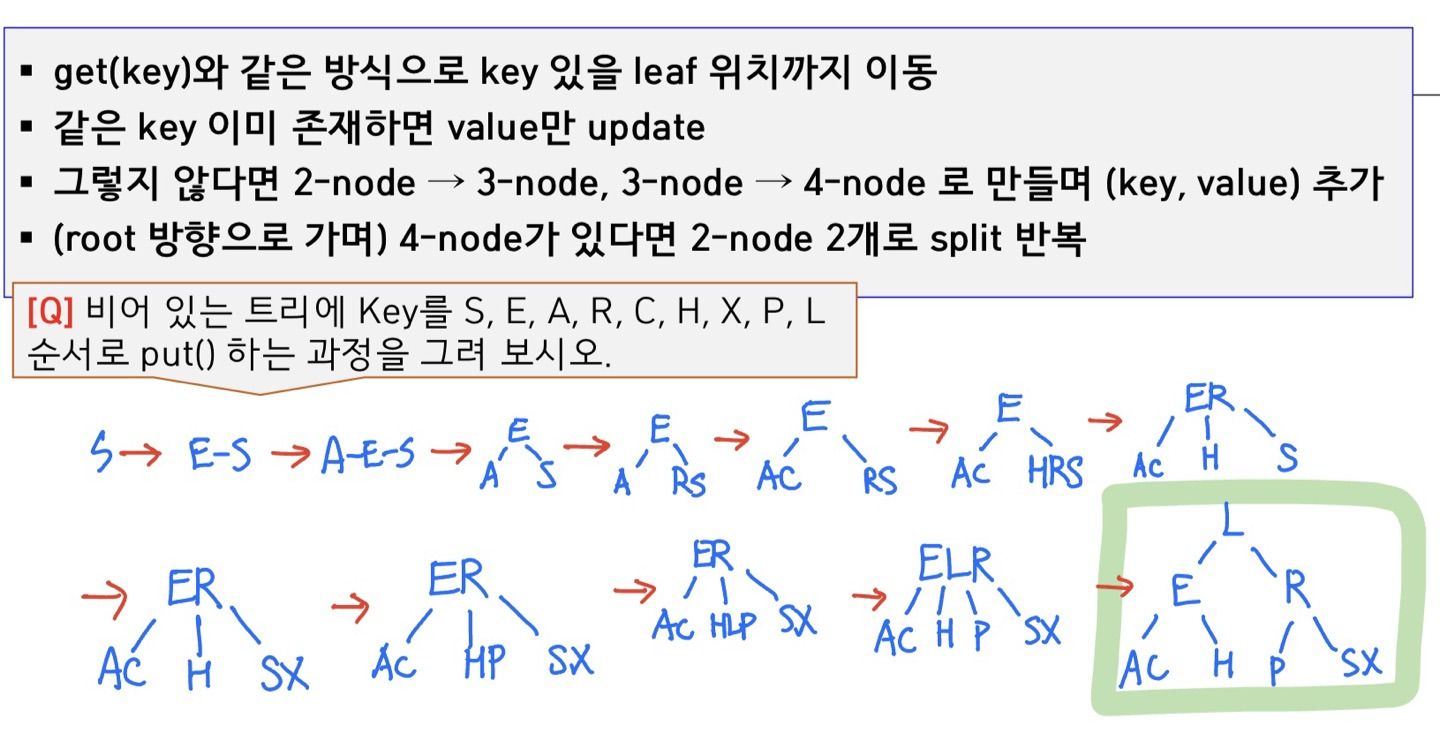
왼쪽, 오른쪽의 균형이 유지되고 root 노드부터 모든 리프 노드까지 깊이가 같은 것을 확인 가능하다.
LLRB (Left-Leaning Red-Black) BST
LLRB(
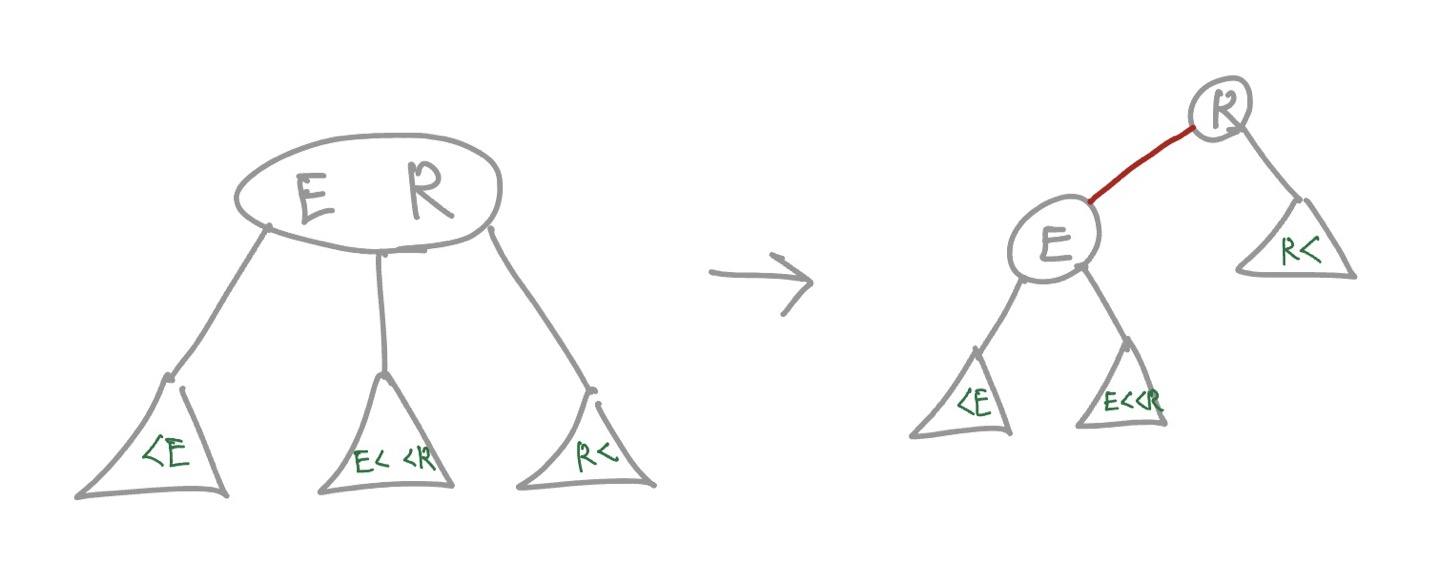
left leaning red black) BST란 기존 BST를 만드는 코드에 약간의 변형을 통해 2-3 tree를 만들기 위해 고안된 개념으로,내부 연결과외부 연결을 구분해 표현한다. 내부 연결은왼쪽으로 기울어지도록(left-leaning)표현한다.
기존의 3-node를 아래 그림과 같이 표현 가능하다. 내부 연결(빨간색)과 외부 연결을 구분하여 표현하고, 내부 연결의 경우 작은 값을 왼쪽에, 즉 왼쪽으로 기울어지도록 표현한다.
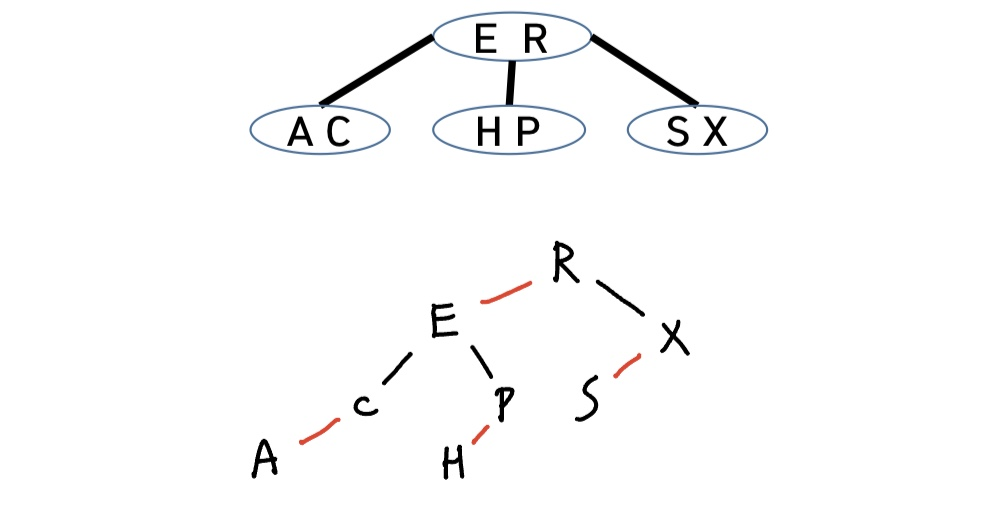
다음과 같은 2-3 tree를 LLRB 형식으로 표현하면 다음과 같다.
LLRB BST에서의 split
노드를 추가하는 과정에서 4-node가 됐을 때 부모-자식으로 분할(split) 하는 과정을 거쳤는데 red-black tree에서는 이를 색깔을 반전시킴으로써 쉽게 구현이 가능하다.
양쪽 자식이 모두 내부 연결(red) 라면 이들을 모두 black으로 만든다. 그리고 부모와의 연결을 내부 연결(red)로 바꾼다.
즉, 기존 red 연결이었던 노드들을 black 연결로 수정함으로써 자식으로 만들고, 기존 black 연결이었던 부모와의 연결을 red 연결, 즉 부모와 대등한 위치가 되었으므로 결과적으로 4-node의 중간 노드를 부모로 끌어올린 셈이 된다.

이런 식으로 red-black 개념을 도입하면 기존 BST를 만드는 코드를 이용해서 쉽게 2-3 tree를 만들 수 있다.
2-3 tree는 worst case에도 대부분의 작업에 대해 logN 성능을 유지한다.
